例子
String s1 = new String("1")+new String("1");
// s1.intern(); 打开true
String s2="11";
//false
System.out.println(s1==s2);
String s3 = new String("11");
String intern = s3.intern();
//false
System.out.println(s3==s2);
//true
System.out.println(intern==s2);
对于字符串常量,在类加载时,会将字符串放入方法区中的静态常量池,包括字符串的字面量和字符引用。而在初始化或运行时,会将字符引用转为直接引用,存放在运行时常量池。
如果是运行时动态生成的字符串对象调用intern方法,如果字符串的引用在运行时常量池不存在,则会在常量池中创建一个引用。
所以第一个通过加动态生成的“11”字符串由于在运行时常量中没有该字符串的引用,所以会在调用s1.intern时,在运行时常量池中生成一个s1的引用,当s2再次引用该字符串时,发现运行时常量池中存在相同值的字符串的引用,就直接返回s1的引用。所以s1==s2是返回的true。这也仅限于JDK1.7之后的版本。
而第二种,用于"11"在类加载时,已经存在静态常量池中,在new string(“11”)时,会在运行时常量池中创建一个“11”字符串的直接引用。而s1指向的并不是该引用,而是new string这个对象的引用。当s2=“11”时,返回的是运行时常量池中的引用。所以s1==s2返回false
这里有个 char[] 地址复用是当常量池发现一样的常量对象是就会直接引用了不会在创建。但是并不代表他们的引用地址是一样的。如上面 第二种情况 s2 和s3 的char[]地址是一样的但是 他们引用地址并不相等
1. 贪婪模式(Greedy)
顾名思义,就是在数量匹配中,如果单独使用 +、 ? 、* 或{min,max} 等量词,正则表达式会匹配尽可能多的内容。
2. 懒惰模式(Reluctant)
在该模式下,正则表达式会尽可能少地重复匹配字符。如果匹配成功,它会继续匹配剩余的字符串。例如加 ?
3. 独占模式(Possessive)
同贪婪模式一样,独占模式一样会最大限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发生回溯问题。例如加个 +
所以 正则表达式 多用 独占模式
1 增删方面 arraryList 如果是在头部地方 增加和删除性能比linkList 差 ,如果是在尾部添加元素没有扩容的话 性能比linkList好 但是扩容的就不一样了 中间的都差不多
2 查询的话 都可以通过索引来查 遍历的话 linklist 使用 iteator 遍历比for 循环效率高
中间件 sharing-jdbc(嵌入式) mycat(proxy)性能差点
分页 将每个分表的数据查询出来 通过归并排序计算出来 stream api
paralle 并行流 在处理集合时 如果时线程不安全的集合 就会有线程不安全的问题
stream api 在处理大数据量集合比较好 对机器的cpu 要求时 多核 并行处理的效率比较高
基于 数组加链表的数据结构来实现,通过将 Key 的 hash 值与 length-1 进行 & 运算,实现了当前 Key 的定位(存储位置),2 的幂次方可以减少冲突(碰撞)的次数,提高 HashMap 查询效率;如果相同node 超过8个 就会生成红黑树来存储 查询时间复杂度O(log(n))
重写 key 值的 hashCode() 方法,降低哈希冲突,从而减少链表的产生,高效利用哈希表,达到提高性能的效果。
扩容 达到hashMap 的 负载因子(0.75)倍的长度 就会两倍扩容 而在 JDK 1.8 中,HashMap 对扩容操作做了优化。由于扩容数组的长度是 2 倍关系,所以对于假设初始 tableSize = 4 要扩容到 8 来说就是 0100 到 1000 的变化(左移一位就是 2 倍),在扩容中只用判断原来的 hash 值和左移动的一位(newtable 的值)按位与操作是 0 或 1 就行,0 的话索引不变,1 话是 扩容前索引位置加上扩容前数组长度的数值索引(原来是 4 之前是16 扩容后数组长度32 那么 新的索引是 20)
假设链表中有4、8、12,他们的二进制位00000100、00001000、00001100,而原来数组容量为4,则是 00000100,以下与运算:
00000100 & 00000100 = 0 保持原位
00001000 & 00000100 = 1 移动到高位
00001100 & 00000100 = 1 移动到高位
相关文档
https://istio.tech/2019/07/28/HashMap1-8%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/
1 传统 I/O 的性能问题(以字节为单位 效率低)
多次内存复制 数据先从外部设备复制到内核空间,再从内核空间复制到用户空间,这就发生了两次内存复制操作。这种操作会导致不必要的数据拷贝和上下文切换,从而降低 I/O 的性能.
在传统 I/O 中,InputStream 的 read() 是一个 while 循环操作,它会一直等待数据读取,直到数据就绪才会返回。这就意味着如果没有数据就绪,这个读取操作将会一直被挂起,用户线程将会处于阻塞状态。
2 NIO(以 block 块 为单位)
使用缓冲区优化读写流操作 传统 I/O 和 NIO 的最大区别就是传统 I/O 是面向流,NIO 是面向 Buffer。Buffer 可以将文件一次性读入内存再做后续处理,而传统的方式是边读文件边处理数据。虽然传统 I/O 后面也使用了缓冲块,例如 BufferedInputStream,但仍然不能和 NIO 相媲美。使用 NIO 替代传统 I/O 操作,可以提升系统的整体性能。
使用 DirectBuffer 减少内存复制 是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝
3. 避免阻塞,优化 I/O 操作
管道(channel)Channel 有自己的处理器,可以完成内核空间和磁盘之间的 I/O 操作。在 NIO 中,我们读取和写入数据都要通过 Channel,由于 Channel 是双向的,所以读、写可以同时进行。
多路复用器(Selector)Selector 是基于事件驱动实现的,我们可以在 Selector 中注册 accpet、read 监听事件,Selector 会不断轮询注册在其上的 Channel,如果某个 Channel 上面发生监听事件,这个 Channel 就处于就绪状态,然后进行 I/O 操作。 避免阻塞
看一下 dubbo 采用protobuf 序列化协议
这里是dubbo 序列化扩展 目前没有扩展 protobuf协议 但是扩展了Kryo 可以参考KryoSerialization 实现方式实现 但是这个序列化方式在分布式环境下存在坑
官方文档 http://dubbo.apache.org/zh-cn/docs/dev/impls/serialize.html
最后,需要手动在 classpath 下创建 META-INF/dubbo/internel/org.apache.dubbo.common.serialize.Serialization 路径。 文件名称为:
org.apache.dubbo.common.serialize.Serialization。在该文件中写入自己的实现类,及该实现的 schema。例如:
protobuf=org.apache.dubbo.common.serialize.protocol.ProtobufSerialization
将自己的实现打包,注意打包的时候,一定要将 /META-INF 文件夹下的所有内容都打包进去。否则,将不会被 classloader 加载到,进而报错!
引入
<dubbo:protocol serialization="xxx" />
补充一下 duboo 2.7 版本已经实现了这个接口 可以直接用了 https://github.com/apache/dubbo
查看命宁 sysctl -a | grep net.xxx (sysctl -a | grep net.ipv4.tcp_keepalive_time)
修改某项配置,可以通过编辑 vim/etc/sysctl.conf,加入需要修改的配置项, 并通过 sysctl -p 命令运行生效修改后的配置项设置。
下面配置提高网络吞吐量和降低延时
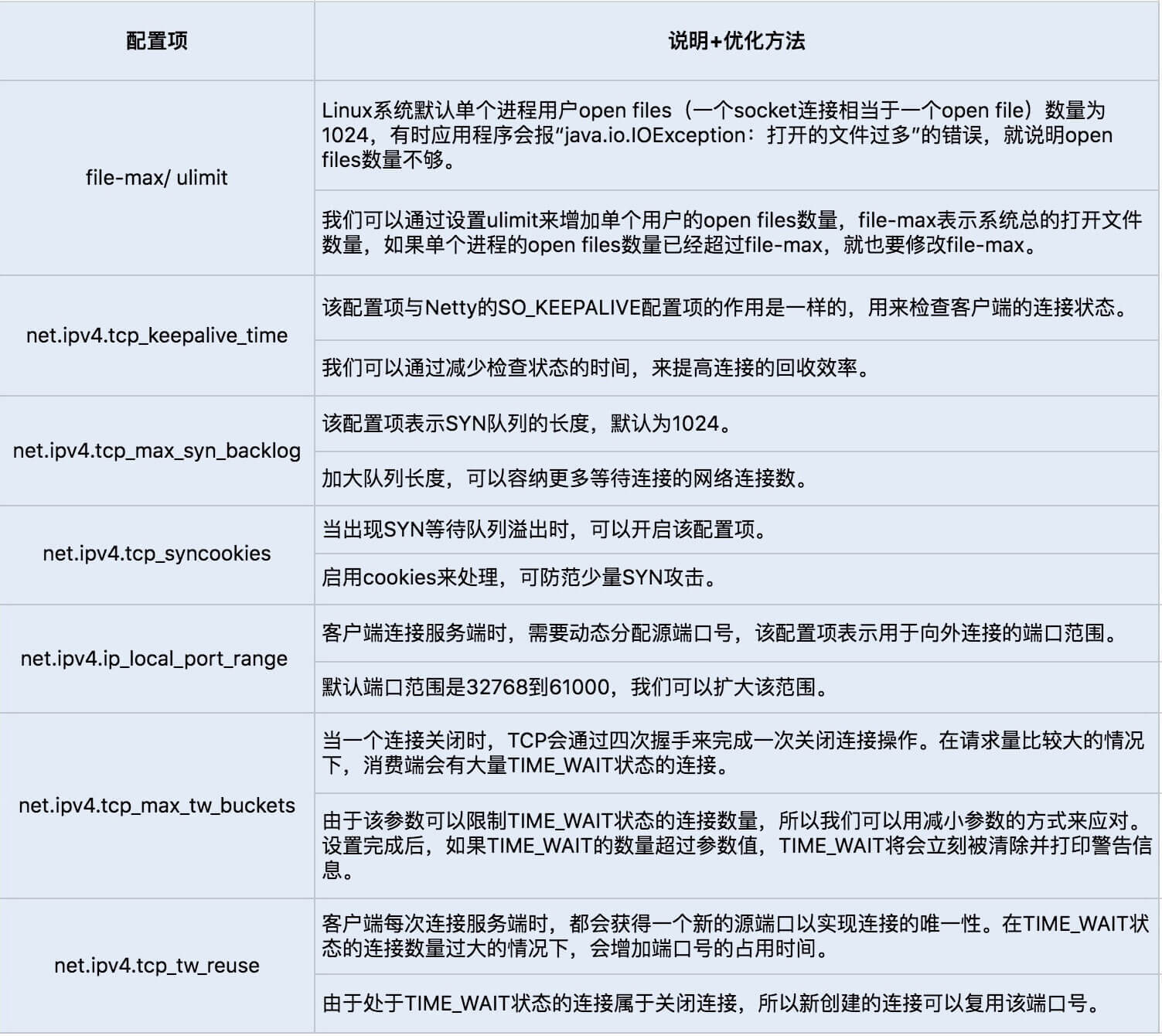
1. 检测Mark Word里面是不是当前线程ID,如果是,表示当前线程处于偏向锁
2. 如果不是,则使用CAS将当前线程ID替换到Mark Word,如果成功则表示当前线程获得偏向锁,设置偏向标志位1
3. 如果失败,则说明发生了竞争,撤销偏向锁,升级为轻量级锁
4. 当前线程使用CAS将对象头的mark Word锁标记位替换为锁记录指针,如果成功,当前线程获得锁
5. 如果失败,表示其他线程竞争锁,当前线程尝试通过自旋获取锁 for(;;)
6. 如果自旋成功则依然处于轻量级状态
7. 如果自旋失败,升级为重量级锁
- 索指针:在当前线程的栈帧中划出一块空间,作为该锁的锁记录,并且将锁对象的标记字段复制到改锁记录中!
这里注意 锁状态只能升级不能降级。
// 修饰普通方法
public synchronized void method1() {
// code
}
// 修饰静态方法
public synchronized static void method2() {
// code
}
这里 锁普通方法和锁静态方法的区别是 普通方法中的锁是锁对象,而修饰静态方法是类锁 粒度更大
1-1:乐观锁的实现核心——CAS,它包含了 3 个参数:V(需要更新的变量)、E(预期值)和 N(最新值)。
只有当需要更新的变量等于预期值时,需要更新的变量才会被设置为最新值,如果更新值和预期值不同,则说明已经有其它线程更新了需要更新的变量
,此时当前线程不做操作,返回 V 的真实值。
1-2:通常情况下乐观锁的性能由于悲观锁,不过乐观锁有一定的使用场景,比如:它只能保证单个变量操作的原子性,当涉及到多个变量时,CAS 就无能为力
,适用竞争不激烈的场景
ABA问题是指一个线程修改数据时,获取的最新值是A,在修改之前又有其他的线程将此值做了修改,比如:先改成了B后来又有线程将B改成了A,
但是最早的那个线程是不知道的,还会修改成功的。CAS 没有记录更新时间戳,只是对比更新值和预期值 的值,就会出现ABA 问题
ABA问题的解决思路
1:StampdLock通过获取锁时返回一个时间戳可以解决
2:通过添加版本号,版本号每次修改都增加一个版本,这样也能解决
1:线程上下文切换指啥?
线程上下文切换指一个线程被暂停剥夺对CPU的使用权,另外一个线程被选中开始或者继续在CPU中运行的过程。(简单就是多线程中线程的竞争锁导致阻塞 会导致上下文切换严重)
2:线程上文切换的问题?
上下文切换会导致额外的性能开销,因为一个线程正在CPU上执行需要停下来换另外一个线程来执行,需要做许多的事情
3:上下文切换的性能开销花费在哪里?
操作系统保存和恢复上下文;
调度器进行线程调度;
处理器高速缓存重新加载;
上下文切换也可能导致整个高速缓存区被冲刷,从而带来时间开销。
4:在多线程中使用 Synchronized 会发生进程间的上下文切换 具体体现环节?
当升级到重量级锁后,线程竞争锁资源,将会进入等待队列中,并在等待队列中不断尝试获取锁资源。每次去获取锁资源,都需要通过系统调底层操作系统申请获取Mutex Lock,这个过程就是一次用户态和内核态的切换。
5:什么是进程的上下文切换?什么是线程的上下文切换?
进程间的上下文切换因为是用户态和内核态之间的切换,需要消耗更多的资源,例如,寄存器中的内容切换出,缓存的刷新等,而线程间的上下文切换是用户态的线程切换,由于是同一个虚拟内存,消耗资源相对较少。
6:在 Linux 系统下,可以使用 Linux 内核提供的 vmstat, pidstat ,JDK 工具之 jstack 命令,来监视 Java 程序运行过程中系统的上下文切换频率
例子
vmstat 1 3 命令行代表每秒收集一次性能指标,总共获取 3 次。
pidstat -w -p pid 命令行,我们可以查看到进程的上下文切换
pidstat -w -p pid -t 命令行,我们可以查看到具体线程的上下文切换:
jstack pid 命令查看线程堆栈信息,通常是结合 pidstat -p pid -t 一起查看具体线程的状态,也经常用来排查一些死锁的异常。
1:竞争锁、线程间的通信以及过多地创建线程等多线程编程操作,都会给系统带来上下文切换。除此之外,I/O 阻塞以及 JVM 的垃圾回收也会增加上下文切换。
2:优化
1. 减少锁的持有时间(缩小锁范围)
2. 降低锁的粒度 (锁分离 锁分段)
3. 非阻塞乐观锁替代竞争锁(volitile 和cas )
4. 合理地设置线程池大小,避免创建过多线程 使用协程实现非阻塞等待(这个是go里面用的很出色的东西)
5. 减少 Java 虚拟机的垃圾回收
补充
volatile主要是用来保证共享变量额可见性,以及防止指令重排序,保证执行的有序性。通过生成.class文件之后,反编译文件我们可以看到通过volatile修饰的共享变量,在写入操作的时候会多一个Lock前缀这样的指令,当操作系统执行时会由于这个指令,将当前处理器缓存的数据写回系统内存中,并通知其他处理器中的缓存失效。
所以volatile不会带来线程的挂起操作,不会导致上下文切换。
1 抢购系统中的排队等待如果要你来选择或者设计一个队列,你会怎么考虑呢?
1、通过ConcurrentLinkedQueue来设计 抢购场景一般都是写多读少,该队列基于链表实现,所以新增和删除元素性能较高
2、写数据时通过cas操作,性能较高。
但是LinkedQueue有一个普遍存在的问题,就是该队列是无界的,需要控制容量,否则可能引起内存溢出
2 怎么理解 弱一致性
主要是 get 方法没有加锁 从而获取的到的值不是 修改的值
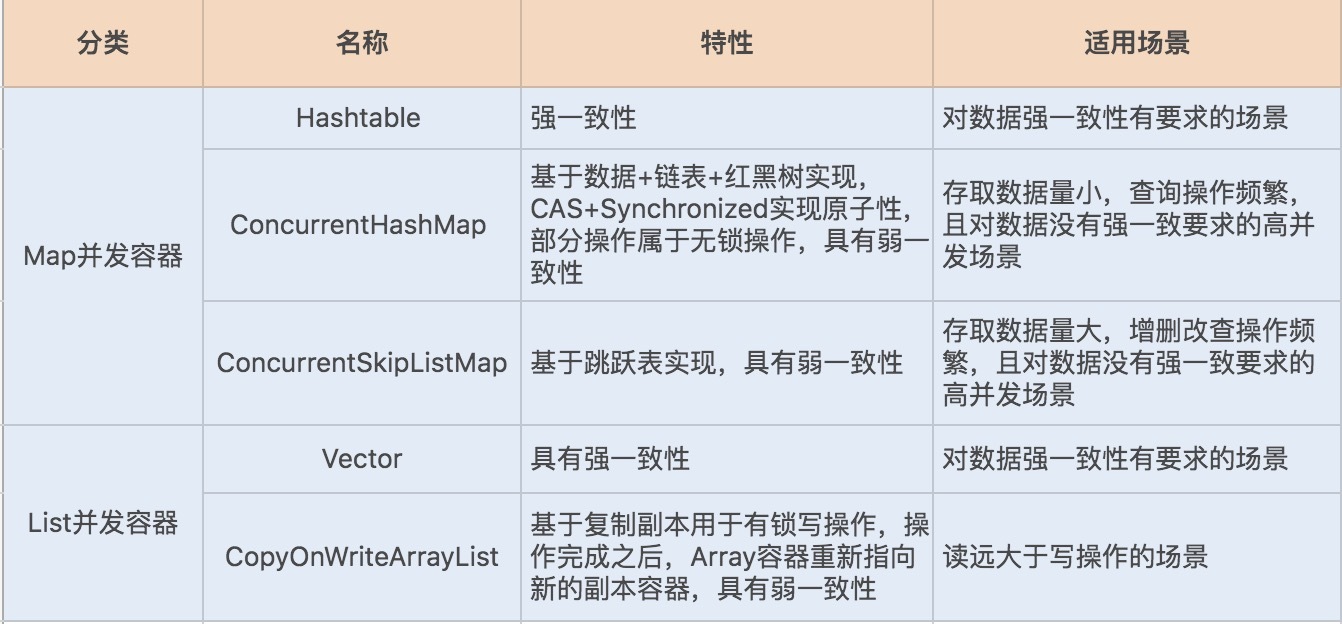
1 ThreadPoolExecutor 参数
int corePoolSize,// 线程池的核心线程数量 cpu 计算密集型为 n+1,io 密集型为2n+1 如果是4核的情况下就是4+1
int maximumPoolSize,// 线程池的最大线程数 超过这个数字 就会拒绝抛出异常
long keepAliveTime,// 当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,// 时间单位
BlockingQueue<Runnable> workQueue,// 任务队列,用来储存等待执行任务的队列 这个队列设置界限 不然会 oom
ThreadFactory threadFactory,// 线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler) // 拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
2 如果队列满了,就会新增线程来执行任务,如果已经是最大线程数量,则会执行拒绝策略。如果未到达最大线程和队列没有满 也是创建非核心线程分配任务
如下线程分配流程
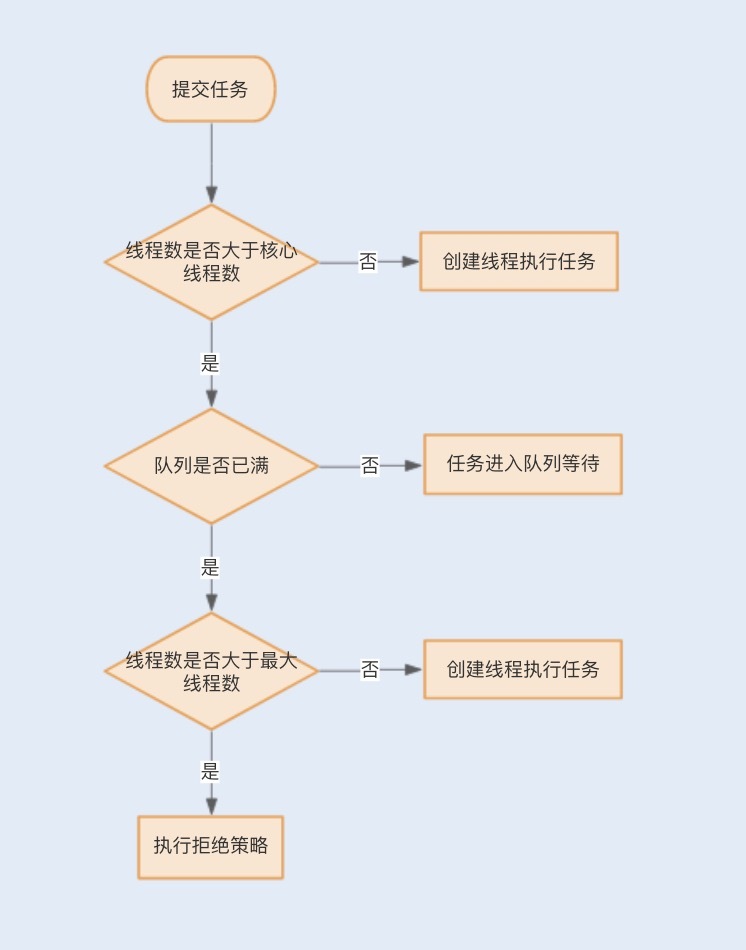
1 阻塞队列 blockQueue
ArrayBlockingQueue:数组结构阻塞队列,按 FIFO(先进先出)原则对元素进行排序,使用 ReentrantLock、Condition 来实现线程安全;
LinkedBlockingQueue:链表结构阻塞队列,同样按 FIFO (先进先出) 原则对元素进行排序,使用 ReentrantLock、Condition 来实现线程安全,吞吐量通常 要高于 ArrayBlockingQueue;
PriorityBlockingQueue:一个具有优先级的无限阻塞队列,基于二叉堆结构实现的无界限(最大值 Integer.MAX_VALUE - 8)阻塞队列,队列没有实现排序,但每当有数据变更时,都会将最小或最大的数据放在堆最上面的节点上,该队列也是使用了 ReentrantLock、Condition 实现的线程安全;
DelayQueue:一个支持延时获取元素的无界阻塞队列,基于 PriorityBlockingQueue 扩展实现,与其不同的是实现了 Delay 延时接口;
SynchronousQueue:一个不存储多个元素的阻塞队列,每次进行放入数据时, 必须等待相应的消费者取走数据后,才可以再次放入数据,该队列使用了两种模式来管理元素,一种是使用先进先出的队列,一种是使用后进先出的栈,使用哪种模式可以通过构造函数来指定。
2 非阻塞队列
ConcurrentLinkedQueue,它是一种无界线程安全队列 (FIFO),基于链表结构实现,利用 CAS 乐观锁来保证线程安全。
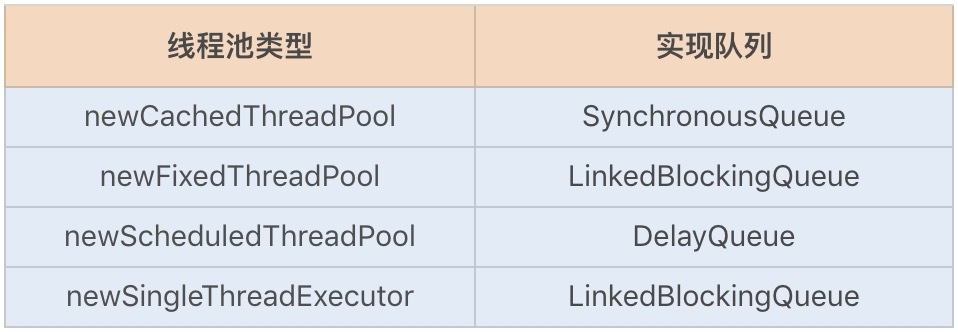
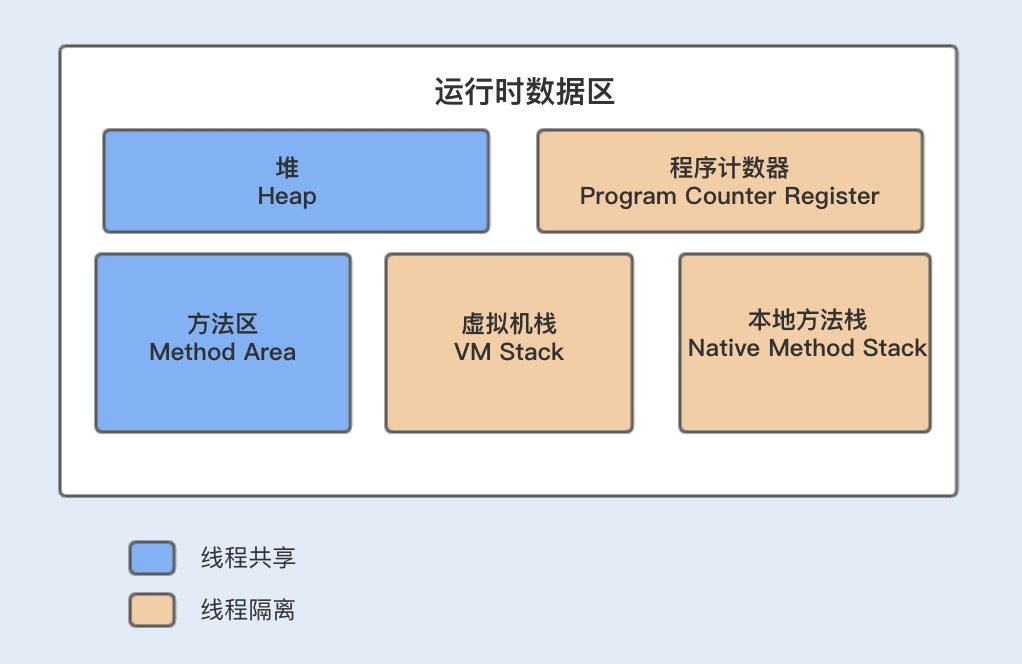
1 jdk 1.8 里主要是 分成了 堆(新生代【eden,s0,s1】,老年代,元空间),方法区,程序计数器,虚拟机栈,本地方法栈
2 对象和共享变量放到堆里,类信息,方法和字符串常量池放到方法区里,栈里面都是内存地址值和局部变量
3 本地方法栈——私有,存储线程的本地方法调用信息,也是主要是栈帧。是c 语言实现
4 程序计数器——私有,记录线程的当前执行的位置信息。
例如下图
1. 回收发生在哪里?主要是 堆和方法区中的对象和废弃常量和无用的类
2. 对象在什么时候可以被回收?引用计数和可达性分析算法
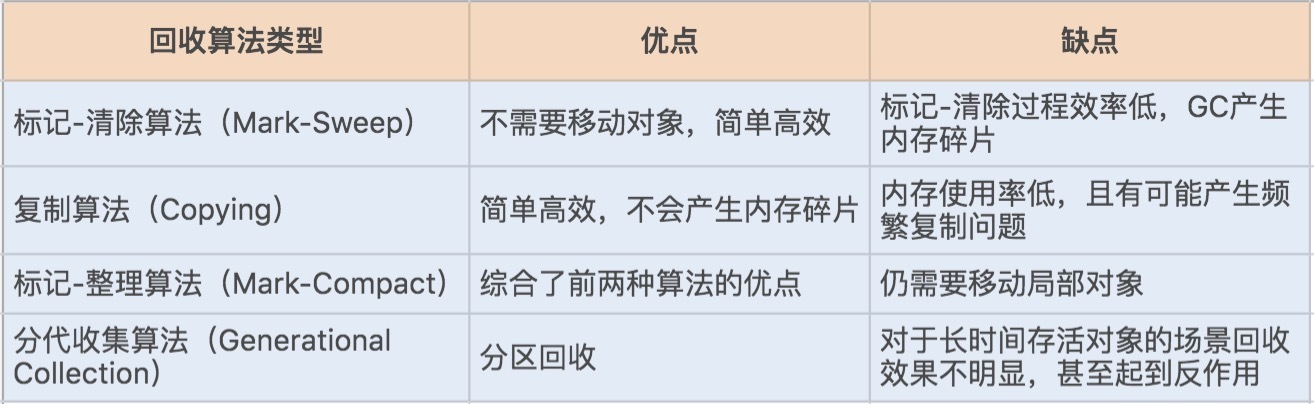
3. 如何回收?GC 算法 标记清楚,标记整理,复制算法,分代收集 具体看下图
4. jmap -heap pid 查看jvm 参数配置和使用情况
5. jvm 性能几个指标
吞吐量:系统总运行时间 = 应用程序耗时 +GC 耗时。如果系统运行了 100 分钟,GC 耗时 1 分钟,则系统吞吐量为 99%。
停顿时间:指垃圾收集器正在运行时,应用程序的暂停时间。对于串行回收器而言,停顿时间可能会比较长;并行时间停顿时间短但是吞吐量低
垃圾回收频率:通常垃圾回收的频率越低越好,增大堆内存空间可以有效降低垃圾回收发生的频率
6. 查看 & 分析 GC 日志
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:./gclogs //这里是以时间(日期形式)形式打出详细的GC的日志 输出到日志文件
日志分析工具 https://sourceforge.net/projects/gcviewer/ https://www.gceasy.io/index.jsp
7. GC 调优策略
1. 降低 Minor GC 频率
通常情况下,由于新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此我们可以通过增大新生代空间来降低 Minor GC 的频率。
2. 降低 Full GC 的频率 (堆内存空间不足或老年代对象太多,会触发 Full GC)
减少大对象的创建 增大堆内存空间 选择合适的GC回收器
8. 问题 minor gc是否会导致stop the world? major gc什么时候会发生,它和full gc的区别是什么?
1、不管什么GC,都会发送stop the world,区别是发生的时间长短。而这个时间跟垃圾收集器又有关系,Serial、PartNew、Parallel Scavenge收集器无论是串行还是并行,都会挂起用户线程,而CMS和G1在并发标记时,是不会挂起用户线程,但其他时候一样会挂起用户线程,stop the world的时间相对来说小很多了。
2、major gc很多参考资料指的是等价于full gc,我们也可以发现很多性能监测工具中只有minor gc和full gc。
一般情况下,一次full gc将会对年轻代、老年代以及元空间、堆外内存进行垃圾回收。而触发Full GC的原因有很多:
a、当年轻代晋升到老年代的对象大小比目前老年代剩余的空间大小还要大时,此时会触发Full GC;
b、当老年代的空间使用率超过某阈值时,此时会触发Full GC;
c、当元空间不足时(JDK1.7永久代不足),也会触发Full GC;
d、当调用System.gc()也会安排一次Full GC;
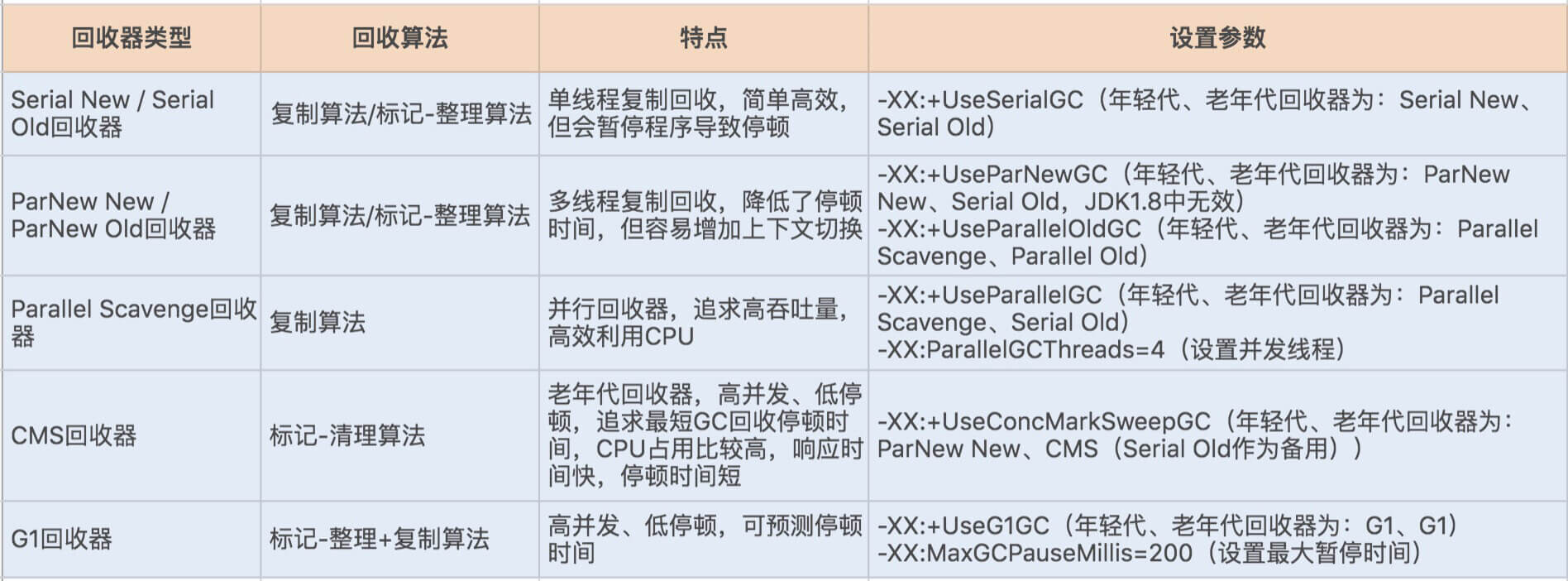
1 常用命令
top 命令 查看当前系统 cpu,内存和系统负载情况
top -Hp pid 查看具体线程使用系统资源情况
vmstat 命令 查看进程上下文切换次数
pidstat -p 1234 -r 1 3 -p 用于指定进程 ID,-r 表示监控内存的使用情况,1 表示每秒的意思,3 则表示采样次数。
jstat -gc pid -t 查看内存 使用情况
jstack pid 堆栈详细
jmap -histo:live pid 查看堆内存中的存活对象数目
2 排查问题的相关资料
https://mp.weixin.qq.com/s/ji_8NhN4NnEHrfAlA9X_ag
https://mp.weixin.qq.com/s/IPi3xiordGh-zcSSRie6nA
// 懒汉模式 + synchronized 同步锁 +volatile+ double-check
public final class Singleton {
private volatile static Singleton instance= null;// 不实例化
public List<String> list = null;//list 属性
private Singleton(){
list = new ArrayList<String>();
}// 构造函数
public static Singleton getInstance(){// 加同步锁,通过该函数向整个系统提供实例
if(null == instance){// 第一次判断,当 instance 为 null 时,则实例化对象,否则直接返回对象
synchronized (Singleton.class){// 同步锁
if(null == instance){// 第二次判断
instance = new Singleton();// 实例化对象
}
}
}
return instance;// 返回已存在的对象
}
}
1 static 修饰了成员变量 instance,在多线程的情况下能保证只实例化一次。
2 volatile 关键字可以保证线程间变量的可见性,和能阻止局部重排序的发生。
3 double-check 双重检查
// 懒汉模式 内部类实现
public final class Singleton {
public List<String> list = null;// list 属性
private Singleton() {// 构造函数
list = new ArrayList<String>();
}
// 内部类实现
public static class InnerSingleton {
private static Singleton instance=new Singleton();// 自行创建实例
}
public static Singleton getInstance() {
return InnerSingleton.instance;// 返回内部类中的静态变量
}
}
//枚举类
public class SinletonExample {
private static SinletonExample instance = null;
// 私有构造函数
private SinletonExample(){
}
public static SinletonExample getInstance(){
return Sinleton.SINLETON.getInstance();
}
private enum Sinleton{
SINLETON;
private SinletonExample singleton;
// JVM保证这个方法只调用一次
Sinleton(){
singleton = new SinletonExample();
}
public SinletonExample getInstance(){
return singleton;
}
}
}
1:原型模式——通过使用更高效的对象创建方式来创建大量重复对象,已提高创建对象的性能。
// 学生类实现 Cloneable 接口
class Student implements Cloneable{
private String name; // 姓名
public String getName() {
return name;
}
public void setName(String name) {
this.name= name;
}
// 重写 clone 方法
public Student clone() {
Student student = null;
try {
student = (Student) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return student;
}
}
//优化前
for(int i=0; i<list.size(); i++){
Student stu = new Student();
...
}
//优化后
Student stu = new Student();
for(int i=0; i<list.size(); i++){
Student stu1 = (Student)stu.clone();
...
}
2:享员模式——通过减少内部公享数据的创建来创建对象,以提高创建对象的性能。例如 String 字符串常量池 减少创建相同值的对象,线程池
3:new一个对象和clone一个对象,性能差在哪里呢?(这里主要是大对象和大数据量区创建对象的性能了)
一个对象通过new创建的过程为:
1、在内存中开辟一块空间;
2、在开辟的内存空间中创建对象;
3、调用对象的构造函数进行初始化对象。
而一个对象通过clone创建的过程为:
1、根据原对象内存大小开辟一块内存空间;
2、复制已有对象,克隆对象中所有属性值。
相对new来说,clone少了调用构造函数。如果构造函数中存在大量属性初始化或大对象,则使用clone的复制对象的方式性能会好一些。
https://github.com/nickliuchao/decorator
redis 实现分布式锁
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis 客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
lua 脚本 实现锁的设置和过期时间的原子性
// 加锁脚本
private static final String SCRIPT_LOCK = "if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then redis.call('pexpire', KEYS[1], ARGV[2]) return 1 else return 0 end";
// 解锁脚本
private static final String SCRIPT_UNLOCK = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
如果是在 Redis 集群环境下,依然存在问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Master 节点获取到锁后,在没有同步到其它节点时,Master 节点崩溃了,此时新的 Master 节点依然可以获取锁,所以多个应用服务可以同时获取到锁。
Redisson 实现 多个节点都上锁
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.8.2</version>
</dependency>
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
.addNodeAddress("redis://127.0.0.1:7000).setPassword("1")
.addNodeAddress("redis://127.0.0.1:7001").setPassword("1")
.addNodeAddress("redis://127.0.0.1:7002")
.setPassword("1");
return Redisson.create(config);
}
long waitTimeout = 10;
long leaseTime = 1;
RLock lock1 = redissonClient1.getLock("lock1");
RLock lock2 = redissonClient2.getLock("lock2");
RLock lock3 = redissonClient3.getLock("lock3");
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功,且设置总超时时间以及单个节点超时时间
redLock.trylock(waitTimeout,leaseTime,TimeUnit.SECONDS);
...
redLock.unlock();
问题 高并发 下当一个线程先缓存删除 而数据库中没有来得及删除时 另一个线程来请求数据 发现缓存没有了 而去读取了数据库的数据 然后又放到缓存中
最后原先的线程删除了数据库数据,就会产生数据不一致情况
把所有请求放到线程安全的队列中处理 ,删除缓存和更新数据库加锁
查询数据库时,使用排斥锁来实现有序地请求数据库(同步锁或Lock锁),减少数据库的并发压力
直接更新缓存中的数据,因为请求到达的顺序无法保证,有可能后请求的数据覆盖前请求的数据。直接将数据删除,就是一种幂等的操作,删除后,
再去数据库拉数据,就不会有覆写的问题。记得读取数据需要加锁或延时等待,防止读取脏数据。
大概流程
1. 商品详情页面 提前生成静态页面加入cdn 上
2. 抢购倒计时
3. 获取购买资格 让超过库存的人来购买商品 保证商品库存最少 通常我们可以通过 Redis 分布式锁来控制购买资格的发放
4. 提交订单 库存都是在redis 里的 我们同样可以通过分布式锁来优化扣除消耗库存的设计。
5. 支付回调业务操作 支付回调其他接口 走mq 异步通知
调优
1. 限流实现优化 nginx Zuul RateLimit 或 Guava RateLimiter
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location / {
limit_conn addr 1;
}
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location / {
limit_req zone=one burst=5 nodelay;
}
}
2. 流量削峰 使用 Redission 插件替换 Jedis 插件,Redission 底层是基于 Netty 框架实现的读写 I/O 是非阻塞 I/O 操作,且方法调用是基于异步实现
3. 数据丢失问题
重试机制是还原丢失消息的一种解决方案。在以上的回调案例中,我们可以在写入订单时,同时在数据库写入一条异步消息状态,之后再返回第三方支付操作成功结果。在异步业务处理请求成功之后,更新该数据库表中的异步消息状态。
其他问题
在提交了订单之后会进入到支付阶段,此时系统是冻结了库存的,一般我们会给用户一定的等待时间,这样就很容易出现一些用户恶意锁库存,导致抢到商品的用户没办法去支付购买该商品。你觉得该怎么优化设计这个业务操作呢?
我们可以通过间接的方案来减少这种恶意锁单的问题。建立信用以及黑名单机制,首先在获取购买资格时将黑名单用户过滤掉,其次在获取购买资格后,信用级别高的用户优先获取到库存。用户一旦恶意锁单就会被加入到黑名单
通过快速过期,或者出比较难的验证码问题,防止机器刷单。
父容器
Spring-app.xml component-scan
扫描包 @Component, @Repository, @Service,@Controller, @RestController, @ControllerAdvice, and @Configuration
Spring-mvc.xml component-scan
也是扫描相同的注解 就会造成重复扫描 可以使用 use-default-filters false 来关掉重复的扫描