frustum-pointnets 3d点云+2d检测框+pointnet3d标注框
object-3D目标检测算法调研(基于激光雷达、kitti数据集)
3d检测跟踪 利用光流+ransac 进行目标跟踪


OverFeat, 2013, MultiBox, 2014, DenseBox, 2015, YOLO, 2015, UnitBox, 2016, EAST, 2017 代码, SFace, 2018,
SSD, 2015, YOLOv2, 2016, DSSD, 2017, RON, 2017, RetinaNet, 2017, YOLOv3, 2018,
RCNN, 2014, Fast RCNN, 2015, Faster RCNN, 2015, RFCN, 2016, Light-Head RCNN, 2017, FPN, 2017, Mask RCNN, 2017, RFCN++, 2018, MegDet, 2018, DetNet, 2018,
YOLO-6D, ssd-6d, 3DVP 2015, Mono3D 2016, Deep MANTA 2017, Deep3DBox 2017 代码,
MV3D 2017, AVOD 2018 代码, LCOD 2018, Squeezeseg 2017 代码, HDNET: Exploiting HD Maps for 3D Object Detection, PIXOR, Vote3deep 2017, Complex-YOLO 2018, MaskFusion 2018,
Semantic3D 2017 代码, superpoint_graph 2018 代码, SnapNet 2017 代码, PointNet 2017 代码, PointNet++ 2017 代码, Dynamic Graph CNN GRAPH-CNN 代码, Deep Semantic Classification, RTSS
论文 MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects
本文提出的MaskFusion算法可以解决这两个问题,首先,可以从Object-level理解环境,
在准确分割运动目标的同时,可以识别、检测、跟踪以及重建目标。
分割算法由两部分组成:
1. 2d语义分割: Mask RCNN:提供多达80类的目标识别等
2. 利用Depth以及Surface Normal等信息向Mask RCNN提供更精确的目标边缘分割。
上述算法的结果输入到本文的Dynamic SLAM框架中。
使用Instance-aware semantic segmentation比使用pixel-level semantic segmentation更好。
目标Mask更精确,并且可以把不同的object instance分配到同一object category。
本文的作者又提到了现在SLAM所面临的另一个大问题:Dynamic的问题。
作者提到,本文提出的算法在两个方面具有优势:
相比于这些算法,本文的算法可以解决Dynamic Scene的问题。
本文提出的算法具有Object-level Semantic的能力。
所以总的来说,作者就是与那些Semantic Mapping的方法比Dynamic Scene的处理能力,
与那些Dynamic Scene SLAM的方法比Semantic能力,在或者就是比速度。
确实,前面的作者都只关注Static Scene, 现在看来,
实际的SLAM中还需要解决Dynamic Scene(Moving Objects存在)的问题。}

每新来一帧数据,整个算法包括以下几个流程:
1. 跟踪 Tracking
每一个Object的6 DoF通过最小化一个能量函数来确定,这个能量函数由两部分组成:
a. 几何的ICP Error;
b. Photometric cost。
此外,作者仅对那些Non-static Model进行Track。
最后,作者比较了两种确定Object是否运动的方法:
a. Based on Motioin Incosistency
b. Treating objects which are being touched by a person as dynamic
2. 分割 Segmentation
使用了Mask RCNN和一个基于Depth Discontinuities and surface normals 的分割算法。
前者有两个缺点:物体边界不精确、运行不实时。
后者可以弥补这两个缺点, 但可能会Oversegment objects。
3. 融合 Fusion
就是把Object的几何结构与labels结合起来。
Computer-vision dataset tools that I am using or working on 轨迹处理 误差分析
KinectFusion在世界坐标系中定义了一个立方体,并把该立方体按照一定的分辨率切割成小立方体(voxel)。
定义了一个3x3x3米的立方体,并把立方体分为不同分辨率的小立方体网格。
也就是说,这个大立方体限制了经过扫描重建的模型的体积。
然后,KinectFusion使用了一种称为“截断有符号距离函数”(truncated signed distance function,简称TSDF)
的方法来更新每个小网格中的一个数值,该数值代表了该网格到模型表面的最近距离,
也称为TSDF值。对于每个网格,在每一帧都会更新并记录TSDF的值,
然后再通过TSDF值还原出重建模型。
TSDF数值分布,我们可以很快还原出模型表面的形状和位置。
这种方法通常被称为基于体数据的方法(Volumetric-based method)。
该方法的核心思想是,通过不断更新并“融合”(fusion)TSDF这种类型的测量值,
我们能够 越来越接近所需要的真实值。
KinectFusion是微软研究院的一个项目,研究用Kinect来实时地重构3D表面,最终用于人机交互。
首次实现基于 RGB-D 的实时三位重建
步骤:
1. 2D深度图(双边滤波+三角变换(需要相机内参数))转换成3D点云,并计算 没一个3D点的法向量
2. ICP算法迭代求当前帧2相机位姿
a. 对每个像素点用投影算法计算匹配点。
b. 最小化匹配点重投影点坐标误差到 平面的距离
迭代
3. 根据相机位姿将点云融合到全局三维模型(TSDF模型,3d网格)中
网格中的数值代表距离重建场景表面的距离,网格中从正值到负值的穿越点连接线表示重建的表面
4. 光线投影算法求当前视角下能够看到的场景表面
2017年斯坦福大学提出的BundleFusion算法,可以说是目前基于RGB-D相机进行稠密三维重建效果最好的方法了。
它通过slam获取相机的位置信息,关键帧等等,如果是稠密的,那就是每一帧图像都参与融合,
要是基于关键帧就直接融合关键帧,融合的方式采用bundlefuison 的 integrate 和 deintegrate.
其中对于实时三维重构要想能在slam获得回环后把位置经过修正的帧重新融合必须有deintegrate功能。
笔者真心认为bundlefusion是三维实时重构的里程碑,是最完善的
用 加操作(integration) 和 减操作(de-integration) 的方式解决位姿优化后重建场景更新的问题。
在2D图像物体检测任务中,RCNN、Fast RCNN、Faster RCNN以及刚发布的mask-RCNN等算法,
对于单张图像物体检测均取得了较好的效果,对自动驾驶场景分析有着重要的作用,
但是对于3D真实世界场景依然描述不够。
在自动驾驶中,除了能够检测车辆、行人、障碍物以外,对于其物体速度、方向的检测与定位也是非常重要的。
在这篇论文中,作者实现了仅通过单张图像进行:
(1)精确的车辆区域检测;
(2)车辆部件(如车轮、车灯、车顶等)定位;
(3)车辆部件可见性检测(车辆部件在图像中是否可见);
(4)车辆3D模板匹配及3D定位。
为了实现上述多重任务,作者充分利用了车辆几何特征,将几何特征与语义特征(卷积神经网络中多层次特征)进行结合.
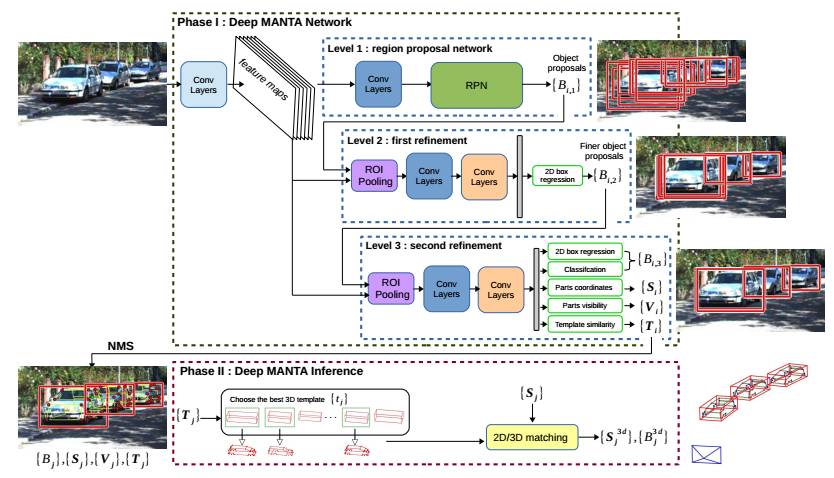
一个鲁棒的神经网络在这里被用来同时进行车辆检测,局部定位,视觉可视化和三维估计。
它的架构基于一个新的粗到精的物体检测网络以提升车辆检测的准确度。
与此同时,Deep MANTA网络可以在图像中定位车辆。即使车辆是不可见的。
在推断过程中,网络的输出作为一个鲁棒的实时位姿估计算法的输入,来进行姿态估计和三维车辆定位。
论文第一个阶段是DeepMANTA Network,目标输出是:B、S、V、T。由于这篇论文采用了创新的研究思路,
因此,有较多关于自定义变量的解释,如果不清晰界定各变量代表的物理含义,则无法理解网络的前后因果,
所以,第一步,应该把作者对于相关符号的定义理解清楚。
(1)B :B 是box的首字母,表示物体边界框,在论文中有两种表示:2D物体区域表示、3D物体区域表示。
对于2D车辆边界框,使用四个变量进行表示:中心位置坐标(cx,cy),及边界框宽高(w,h),
与Faster RCNN等物体检测方法定义边界框方式一致;
对于3D车辆边界框,使用五种变量(实际是7个)进行表示:车辆中心位置3D坐标(cx,cy,cz),
车辆方向θ,车辆实际长宽高t = (w,h,l)
(2)S :S 表示part coordinates,即物体关键部位(几何节点)的坐标。
同上,S也有两种形式,2D与3D,分别描述车辆关键部位在2D图像与3D真实坐标系中的坐标位置。
(3)V :V 表示车辆各部件的可见性,这里作者定义了4 classes of visibility,分别是:
a. 可见:visible if the part is observed in the image
b.被其他物体遮挡:occluded if the part is occluded by another object
c.被自身遮挡:self-occluded if the part is occluded by the vehicle
d. 截断:truncated if the part is out of the image
我们可有效利用V,确定摄像机拍摄位置及车辆的3D坐标,因为只有在特定的位置观测,才能与V相符合。
(4)T:T表示模板相似性向量,3D template similarity vector,用以衡量图像中车辆与每个车辆模板的相似性,
用rm = (rx, ry, rz)表示,分别对应着三个坐标轴对应的缩放因子。
首先,输入单张RGB图像,经过卷积层,得到Feature Maps,这个Feature Maps在Level 1、Level 2、Level 3阶段中共享。
在Level 1阶段,将Feature Maps送入卷积层+RPN(使用Faster-RCNN论文中的方法),
可生成系列物体区域坐标集,用B1表示,原理与Faster-RCNN方法一致。
将ROI对应区域的特征图,经过ROI Pooling(Fast-Rcnn),
生成固定大小的regions,经过两步卷积(Levell卷积层+level2卷积层),
再经过re-fined by offset transformations,生成系列物体区域坐标集,用B2表示。
重复Level2,生成系列物体区域坐标集,用B3表示。
论文作者分析了采用这种三层网络的原因:
(1)克服大的物体大小变化,提供更高的准确度;
(2)保持高分辨率,用于检测难以检测的车辆;
对于B3中的每一个bounding box,同时输出其对应的:S,V,T,各符号含义在文章开头已经介绍。
这个环节比较神奇,作者也没有进行过多的描述,更是整篇论文的精髓所在。
我在最初阅读论文的时候,无法理解网络为什么具有这么强大的功能,
能够同时输出2D bounding box坐标B、2D 车辆部件坐标S、部件可见性V、车辆模型缩放因子T,
那么它是如何实现的?这里给出我自己的初步理解,由于我缺乏网络训练实践,因此更多的形象感性的理解。
这部分实现了由2D坐标到3D空间确定的转换,用到了perspective-n-point-problem方面的计算机视觉基础知识。