R-C3D-Resgion Convolutional 3D Network for Temporal Activity Detection
是基于Faster R-CNN和C3D网络思想。
对于任意的输入视频L,先进行Proposal,然后用3D-pooling,最后进行分类和回归操作。
文章主要贡献点有以下3个。
1、可以针对任意长度视频、任意长度行为进行端到端的检测
2、速度很快(是目前网络的5倍),通过共享Progposal generation 和Classification网络的C3D参数
3、作者测试了3个不同的数据集,效果都很好,显示了通用性。
1、特征提取网络:对于输入任意长度的视频使用C3D进行特征提取;
2、Temporal Proposal Subnet: 用来提取可能存在行为的时序片段(Proposal Segments);
3、Activity Classification Subnet: 行为分类子网络;
4、Loss Function。
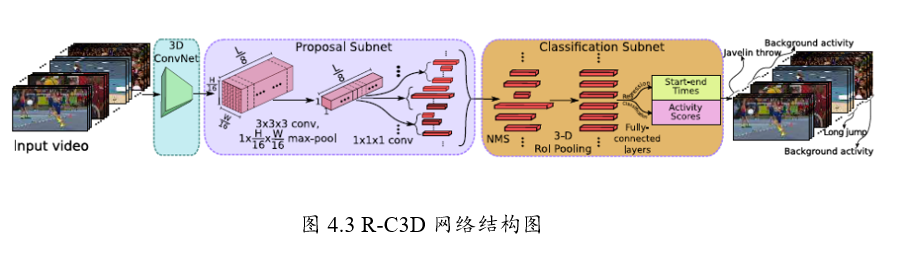
骨干网络作者选择了C3D网络,经过C3D网络的5层卷积后,
可以得到512 x L/8 x H/16 x W/16大小的特征图。
这里不同于C3D网络的是,R-C3D允许任意长度的视频L作为输入。
类似于Faster R-CNN中的RPN,用来提取一系列可能存在目标的候选框。
这里是提取一系列可能存在行为的候选时序。
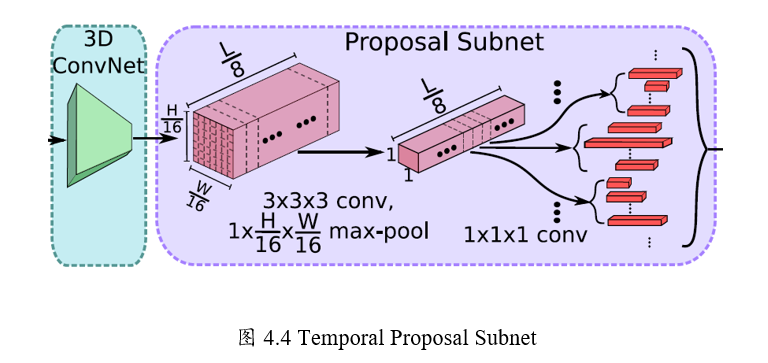
Step1:候选时序生成
输入视频经过上述C3D网络后得到了512 x L/8 x H/16 x W/16大小的特征图。
然后作者假设anchor均匀分布在L/8的时间域上,
也就是有L/8个anchors,
每个anchors生成K个不同scale的候选时序。
Step2: 3D Pooling
得到的 512xL/8xH/16xW/16的特征图后,
为了获得每个时序点(anchor)上每段候选时序的中心位置偏移和时序的长度,
作者将空间上H/16 x W/16的特征图经过一个3x3x3的卷积核
和一个3D pooling层下采样到 1x1。最后输出 512xL/8x1x1.
Step3: Training
类似于Faster R-CNN,这里也需要判定得到的候选时序是正样本还是负样本。\
文章中的判定如下。
正样本:IoU > 0.7,候选时序帧和ground truth的重叠数
负样本: IOU < 0.3
为了平衡正负样本,正/负样本比例为1:1.
行为分类子网络有如下几个功能:
1、从TPS(Temporal Proposal subnet)中选择出Proposal segment
2、对于上述的proposal,用3D RoI 提取固定大小特征
3、以上述特征为基础,将选择的Proposal做类别判断和时序边框回归。
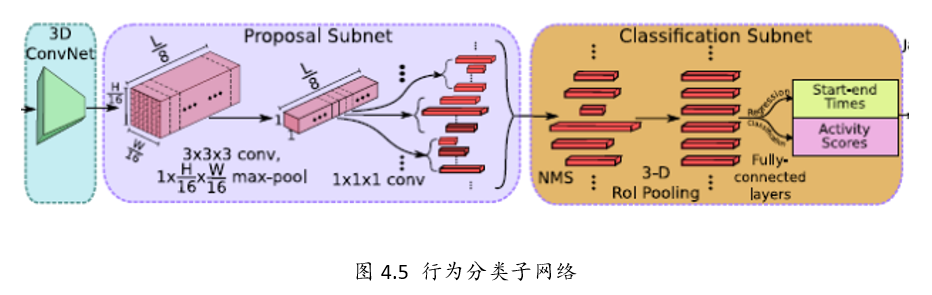
Step1: NMS
针对上述Temporal Proposal Subnet提取出的segment,
采用NMS(Non-maximum Suppression)非极大值抑制生成优质的proposal。
NMS 阈值为0.7.
Step2:3D RoI
RoI (Region of interest,兴趣区域).
这里,个人感觉作者的图有点问题,提取兴趣区域的特征图的输入应该是C3D的输出,
也就是512xL/8xH/16xW/16,可能作者遗忘了一个输入的箭头。
假设C3D输出的是 512xL/8x7x7大小的特征图,假设其中有一个proposal的长度(时序长度)为lp,
那么这个proposal的大小为512xlpx7x7,这里借鉴SPPnet中的池化层,
利用一个动态大小的池化核,ls x hs x ws。
最终得到 512x1x4x4大小的特征图
Step3: 全连接层
经过池化后,再输出到全连接层。
最后接一个边框回归(start-end time )和类别分类(Activity Scores)。
Step4: Traning
在训练的时候同样需要定义行为的类别,
如何给一个proposal定label?
同样采用IoU。
IoU > 0.5,那么定义这个proposal与ground truth相同
IoU 与所有的ground truth都小于0.5,那么定义为background
这里,训练的时候正/负样本比例为1:3。