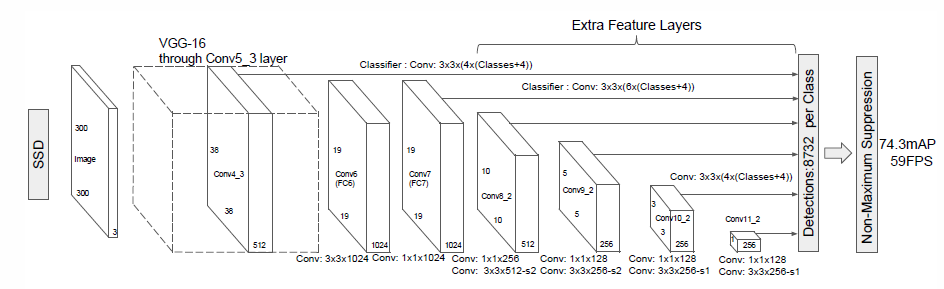
该框架和 Faster RCNN 最重要的两个区别在于:
1. 将 Faster RCNN 的卷积加全连接层的网络结构,转换为:全卷机结构。
这一改变,使得检测的速度,得到很大的提升。
2. 将 RPN 提取 proposal 的机制,
转移到各个 scale 的 feature map 上进行,使得检测的精度也非常高。
基于这两个改善的基础上,使得SSD在物体检测算法中脱颖而出
VGG/MobileNet/ShuffleNet SSD detection network
改进 DSSD : Deconvolutional Single Shot Detector 反卷积后再多尺度预测
输入图像 3*300*300
|
3*3*3*64 3*3卷积 步长1 填充1 64输出 卷积+relu conv1_1
3*3*3*64 3*3卷积 步长1 填充1 64输出 卷积+relu conv1_2
| 输出特征图大小 64*300*300
2*2最大值池化 步长2 pool1
| 输出特征图大小 64*150*150
3*3*64*128 3*3卷积 步长1 填充1 128输出 卷积+relu conv2_1
3*3*64*128 3*3卷积 步长1 填充1 128输出 卷积+relu conv2_2
| 输出特征图大小 128*150*150
2*2最大值池化 步长2 pool2
| 输出特征图大小 128*75*75
3*3*128*256 3*3卷积 步长1 填充1 256输出 卷积+relu conv3_1
3*3*128*256 3*3卷积 步长1 填充1 256输出 卷积+relu conv3_2
1*1*128*256 / 3*3*128*256 3*3/1*1卷积 步长1 填充1/0 256输出 卷积+relu conv3_3
| 输出特征图大小 256*75*75
2*2最大值池化 步长2 pool3
| 输出特征图大小 256*38*38
3*3*256*512 3*3卷积 步长1 填充1 512输出 卷积+relu conv4_1
3*3*256*512 3*3卷积 步长1 填充1 512输出 卷积+relu conv4_2
1*1*256*512 / 3*3*256*512 3*3/1*1卷积 步长1 填充1/0 512输出 卷积+relu conv4_3
| 输出特征图大小 512*38*38
2*2最大值池化 步长2 pool4
| 输出特征图大小 512*19*19
3*3*512*512 3*3卷积 步长1 填充1 512输出 空洞卷积+relu conv5_1
3*3*512*512 3*3卷积 步长1 填充1 512输出 空洞卷积+relu conv5_2
1*1*512*512 / 3*3*512*512 3*3/1*1卷积 步长1 填充1/0 512输出 空洞卷积+relu conv5_3
| 输出特征图大小 512*19*19
3*3最大值池化 步长1 pad: 1 pool5
| 输出特征图大小 512*19*19
全连接层FC6 1024输出 3*3卷积 填充6 空洞卷积间隔6 空洞卷积 + relu
| 输出特征图大小 1024*19*19
全连接层FC7 1024输出 1*1卷积 填充0 卷积 + relu
| 输出特征图大小 1024*19*19
----全连接层FC8 1000输出 没有了
somtmax 指数映射回归分类输入图像 3*300*300
|
3*3*3*64 3*3卷积 步长1 填充1 64输出 卷积+relu conv1_1
3*3*3*64 3*3卷积 步长1 填充1 64输出 卷积+relu conv1_2
| 输出特征图大小 64*300*300
2*2最大值池化 步长2 pool1
| 输出特征图大小 64*150*150
3*3*64*128 3*3卷积 步长1 填充1 128输出 卷积+relu conv2_1
3*3*64*128 3*3卷积 步长1 填充1 128输出 卷积+relu conv2_2
| 输出特征图大小 128*150*150
2*2最大值池化 步长2 pool2
| 输出特征图大小 128*75*75
3*3*128*256 3*3卷积 步长1 填充1 256输出 卷积+relu conv3_1
3*3*128*256 3*3卷积 步长1 填充1 256输出 卷积+relu conv3_2
1*1*128*256 / 3*3*128*256 3*3/1*1卷积 步长1 填充1/0 256输出 卷积+relu conv3_3
| 输出特征图大小 256*75*75
2*2最大值池化 步长2 pool3
| 输出特征图大小 256*38*38
3*3*256*512 3*3卷积 步长1 填充1 512输出 卷积+relu conv4_1
3*3*256*512 3*3卷积 步长1 填充1 512输出 卷积+relu conv4_2
1*1*256*512 / 3*3*256*512 3*3/1*1卷积 步长1 填充1/0 512输出 卷积+relu conv4_3
| 输出特征图大小 512*38*38
2*2最大值池化 步长2 pool4
| 输出特征图大小 512*19*19
3*3*512*512 3*3卷积 步长1 填充1 512输出 空洞卷积+relu conv5_1
3*3*512*512 3*3卷积 步长1 填充1 512输出 空洞卷积+relu conv5_2
1*1*512*512 / 3*3*512*512 3*3/1*1卷积 步长1 填充1/0 512输出 空洞卷积+relu conv5_3
| 输出特征图大小 512*19*19
3*3最大值池化 步长1 pad: 1 pool5
| 输出特征图大小 512*19*19
全连接层FC6 1024输出 3*3卷积 填充6 空洞卷积间隔6 空洞卷积 + relu ---> 1024*19*19
全连接层FC7 1024输出 1*1卷积 填充0 卷积 + relu ---> 1024*19*19
--------------新添加-------------
| 输出特征图大小 1024*19*19
1*1*1024*256 1*1卷积 步长1 填充0 256输出 卷积+relu conv6_1
3*3*256*512 3*3卷积 步长2 填充1 512输出 卷积+relu conv6_2
| 输出特征图大小 512*10*10
1*1*512*128 1*1卷积 步长1 填充0 128输出 卷积+relu conv7_1
3*3*128*256 3*3卷积 步长2 填充1 256输出 卷积+relu conv7_2
| 输出特征图大小 256*5*5
1*1*256*128 1*1卷积 步长1 填充0 128输出 卷积+relu conv8_1
3*3*128*256 3*3卷积 步长1 填充0 256输出 卷积+relu conv8_2
5*5-----> 3*3卷积 无填充 ----> 3*3特征图
| 输出特征图大小 256*3*3
1*1*256*128 1*1卷积 步长1 填充0 128输出 卷积+relu conv9_1
3*3*128*256 3*3卷积 步长1 填充0 256输出 卷积+relu conv9_2
3*3-----> 3*3卷积 无填充 ---->1*1特征图
| 输出特征图大小 256*1*1
一下类似FPN 特征金字塔结构:
1. 本层 预测框数量 38*38*4
输入为 conv4_3层的输出: 512*38*38
---------------正则化层-------------------
conv4_3_norm Normalize scale_filler value: 20
conv4_3_norm_mbox_loc Convolution 输入 conv4_3_norm 512*38*38 边框坐标======
3*3*512*16 16通道输出 ---> 16*38*38 (4种边框 * 4个参数= 16)
conv4_3_norm_mbox_loc_perm Permute 0 2 3 1 交换caffe blob中的数据维======
N C H W ----> N H W C
0 1 2 3 ----> 0 2 3 1
conv4_3_norm_mbox_loc_flat Flatten axis: 1 摊平成一维======
conv4_3_norm_mbox_conf Convolution 输入 conv4_3_norm 512*38*38 置信度=====
3*3*512*84 84通道输出 ---> 84*38*38 (4种边框*21类=84)
conv4_3_norm_mbox_conf_perm Permute 0 2 3 1
conv4_3_norm_mbox_conf_flat Flatten axis: 1
conv4_3_norm_mbox_priorbox PriorBox 输入 conv4_3_norm 512*38*38 预设框===
输入 data
输出 [1, 2, 4*num_priorbox]大小的prior box blob,
其中2个channel分别存储prior box的4个点坐标 和 对应的4个variance,
是一种bounding regression中的权重。
min_size: 30.0
max_size: 60.0
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 8
offset: 0.5
2. 本层 预测框数量 19*19*6
输入为 fc7 输入 1024*19*19
fc7_mbox_loc Convolution 3*3*1024*24 24通道输出 ---> 24*19*19 (6种边框 * 4个参数= 24)
fc7_mbox_loc_perm Permute 0 2 3 1
fc7_mbox_loc_flat Flatten axis: 1
输入为 fc7 输入 1024*19*19
fc7_mbox_conf Convolution 3*3*24*126 126通道输出 ---> 126*19*19 (6种边框*21类=126)
fc7_mbox_conf_perm Permute 0 2 3 1
fc7_mbox_conf_flat Flatten axis: 1
fc7_mbox_priorbox PriorBox 输入 fc7 1024*19*19
输入 data
min_size: 60.0
max_size: 111.0
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 16
offset: 0.5
3. 本层 预测框数量 10*10*6
输入 conv6_2 512*10*10
conv6_2_mbox_loc Convolution 3*3*512*24 24通道输出 ---> 24*10*10 (6种边框 * 4个参数= 24)
conv6_2_mbox_loc_perm Permute 0 2 3 1
conv6_2_mbox_loc_flat Flatten axis: 1
conv6_2_mbox_conf Convolution 3*3*24*126 126通道输出 ---> 126*10*10 (6种边框*21类=126)
conv6_2_mbox_conf_perm Permute 0 2 3 1
conv6_2_mbox_conf_flat Flatten axis: 1
conv6_2_mbox_priorbox 输入 conv6_2 512*10*10
输入 data
min_size: 111.0
max_size: 162.0
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 32
offset: 0.5
4. 本层 预测框数量 5*5*6
输入 conv7_2 256*5*5
conv7_2_mbox_loc Convolution 3*3*256*24 24通道输出 ---> 24*5*5 (6种边框 * 4个参数= 24)
conv7_2_mbox_loc_perm Permute 0 2 3 1
conv7_2_mbox_loc_flat Flatten axis: 1
conv7_2_mbox_conf Convolution 3*3*24*126 126通道输出 ---> 126*5*5 (6种边框*21类=126)
conv7_2_mbox_conf_perm Permute 0 2 3 1
conv7_2_mbox_conf_flat Flatten axis: 1
conv7_2_mbox_priorbox 输入 conv7_2 256*5*5
输入 data
min_size: 162.0
max_size: 213.0
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 64
5. 本层 预测框数量 5*5*4
输入 conv8_2 256*3*3
conv8_2_mbox_loc Convolution 3*3*256*16 16通道输出 ---> 16*5*5 (4种边框 * 4个参数= 16)
conv8_2_mbox_loc_perm Permute 0 2 3 1
conv8_2_mbox_loc_flat Flatten axis: 1
输入 conv8_2 256*3*3
conv8_2_mbox_conf Convolution 3*3*16*84 84通道输出 ---> 84*5*5 (4种边框*21类=84)
conv8_2_mbox_conf_perm Permute 0 2 3 1
conv8_2_mbox_conf_flat Flatten axis: 1
conv8_2_mbox_priorbox 输入 conv8_2 256*5*5
输入 data
min_size: 213.0
max_size: 264.0
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 100
offset: 0.5
6. 本层 预测框数量 1*1*4
输入 conv9_2 256*1*1
conv9_2_mbox_loc Convolution 3*3*256*16 16通道输出 ---> 16*1*1 (4种边框 * 4个参数= 16)
conv9_2_mbox_loc_perm Permute 0 2 3 1
conv9_2_mbox_loc_flat Flatten axis: 1
conv9_2_mbox_conf Convolution 3*3*16*84 84通道输出 ---> 84*1*1 (4种边框*21类=84)
conv9_2_mbox_conf_perm Permute
conv9_2_mbox_conf_flat Flatten
conv9_2_mbox_priorbox 输入 conv9_2 256*1*1
输入 data
min_size: 264.0
max_size: 315.0
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 300
offset: 0.5
7. 预测结果结合concat层
mbox_loc type: Concat
bottom: "conv4_3_norm_mbox_loc_flat"
bottom: "fc7_mbox_loc_flat"
bottom: "conv6_2_mbox_loc_flat"
bottom: "conv7_2_mbox_loc_flat"
bottom: "conv8_2_mbox_loc_flat"
bottom: "conv9_2_mbox_loc_flat"
top: "mbox_loc"
mbox_conf type: Concat
bottom: "conv4_3_norm_mbox_conf_flat"
bottom: "fc7_mbox_conf_flat"
bottom: "conv6_2_mbox_conf_flat"
bottom: "conv7_2_mbox_conf_flat"
bottom: "conv8_2_mbox_conf_flat"
bottom: "conv9_2_mbox_conf_flat"
top: "mbox_conf"
mbox_priorbox type: Concat
bottom: "conv4_3_norm_mbox_priorbox"
bottom: "fc7_mbox_priorbox"
bottom: "conv6_2_mbox_priorbox"
bottom: "conv7_2_mbox_priorbox"
bottom: "conv8_2_mbox_priorbox"
bottom: "conv9_2_mbox_priorbox"
top: "mbox_priorbox"
mbox_conf_reshape type: Reshape 输入 mbox_conf
dim: 0
dim: -1
dim: 21
mbox_conf_softmax type: Softmax axis: 2 输入 mbox_conf_reshape
mbox_conf_flatten type: Flatten axis: 1 输入 mbox_conf_softmax
detection_out
type: "DetectionOutput"
bottom: "mbox_loc"
bottom: "mbox_conf_flatten"
bottom: "mbox_priorbox"
num_classes: 21
share_location: true
background_label_id: 0
nms_param {
nms_threshold: 0.45
top_k: 400
}
code_type: CENTER_SIZE
keep_top_k: 200
confidence_threshold: 0.01 改进FPN 特征金字塔检测结构
在每一个不同特征尺度层上都进行预测
最后通过NMS剔除重合度高的框
不像yolov3那样,会将地尺度特征图进过上采样和高尺度结合在做预测
结构总结:
300*300*3 图像输入
|
|
|
VGG conv_4_3 输出 38*38*512--> 正则化------> 卷积边框回归 + 类别分类 38*38*4 ----->
|
|
|
VGG fc7 输出 19*19*1024 -----> 卷积边框回归 + 类别分类 19*19*6 ----->
|
|
|
1*1 + 3*3卷积步长2 输出 10*10*512 -----> 卷积边框回归 + 类别分类 10*10*6 ----->
|
|
|
1*1 + 3*3卷积步长2 输出 5*5*256 -----> 卷积边框回归 + 类别分类 5*5*6 -----> NMS ---> 结果
|
|
|
1*1 + 3*3卷积0填充 输出 3*3*256 -----> 卷积边框回归 + 类别分类 3*3*4 ----->
|
|
|
1*1 + 3*3卷积0填充 输出 1*1*256 -----> 卷积边框回归 + 类别分类 1*1*4 ----->
38*38*4 + 19*19*6 + 10*10*6 + 5*5*6 + 3*3*4 + 1*1*4 = 8732个预测边框

以feature map上每个格子的中点为中心(offset=0.5),
生成一系列同心的Defalut box
(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
使用m(SSD300中m=6)个不同大小的feature map 来做预测,
最底层的 feature map 的 scale 值为 Smin=0.2,最高层的为Smax=0.95,
其他层通过下面的公式计算得到.

与常见的 Object Detection模型的目标函数相同,
SSD算法的目标函数分为两部分:
计算相应的default box 与 目标类别的confidence loss 以及 相应的位置回归。
L(x,c,l,g) = sum(Lconf(x,c) + Lloc(x,l,g))/N
位置回归:位置回归则是采用 Smooth L1 loss,
Lloc(x,l,g)
类别误差 confidence loss是典型的softmax loss:
Lconf(x,c)
