sync2any可以借助腾讯云数据订阅(DTS)将腾讯云数据库(mysql、tdsql)中的数据实时同步到Elasticsearch(7.x)或mysql。
首先使用mysqldump同步原始数据,再读取CKAFKA中的队列消息实时同步到Elasticsearch或mysql中。
实时同步数据流为:TDSQL -> CKAFKA -> sync2any -> Elasticsearch
- 支持的数据源:TDSQL
- 支持的目标源:Mysql、ElasticSearch、Clickhouse
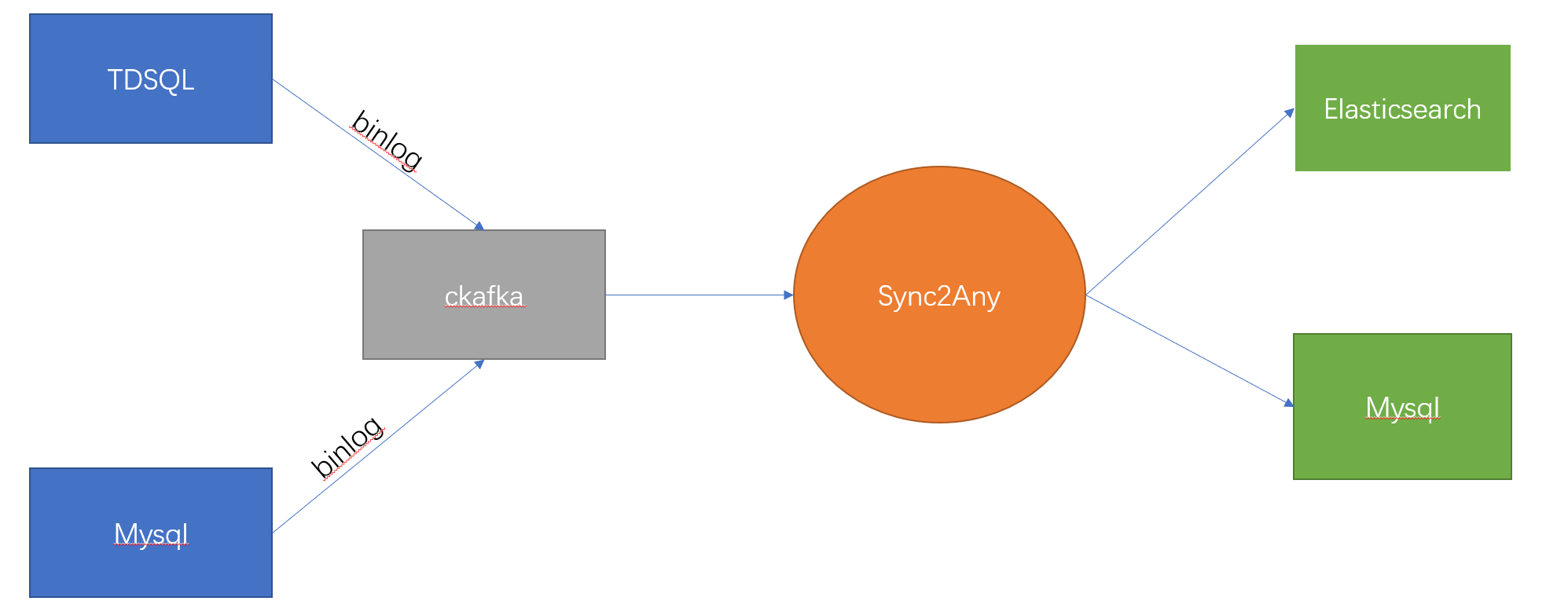
我们使用了腾讯云的TDSQL,但是腾讯云唯一提供可用的实时导出数据流只有CKAFKA这一个渠道(binlog不可用,因为有多台实例)。于是如果我们想将数据导入到ES或者其他数据源,必须得自己开发中间件,别无他法。
- 购买使用了腾讯云提供的TDSQL
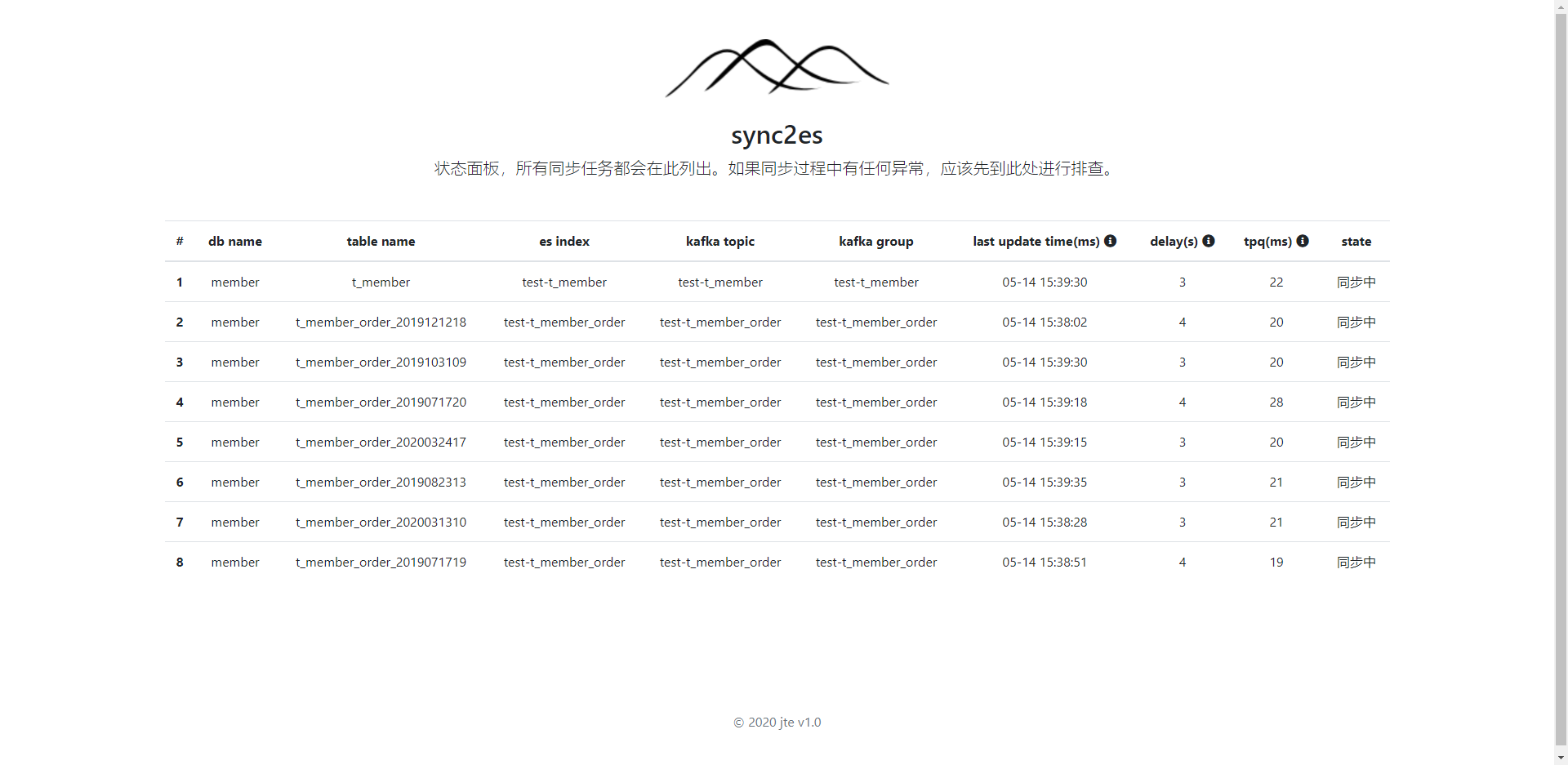
- 登录腾讯云->数据传输服务->数据订阅
- 新建数据订阅,选择好库表
- 新建消费组
- 安装好
mysqldump - 从Release中下载最新版的源码,或者编译好的jar包
- 将config文件夹复制到jar包同目录。
- 将
/config/application-test.yml下的配置文件修改成自己对应的配置文件 - 执行
java -jar sync2any.jar --spring.profiles.active = test运行程序 - 访问
http://127.0.0.1:9070查看同步状态
错误的配置可能会导致项目启动报错。配置文件采用yml格式,不熟悉的同学可以先学习一下。
#【必填】腾讯云CKAFKA配置
kafka:
address: 127.0.0.1:32768
#【必填】同步目标目标的基本配置(支持mysql、es、clickhouse)
target.datasources:
-
#【必填】标识数据源,每个必须不一样
db-id: 1
#目标数据源的类型(可以为es或mysql或clickhouse)
type: es
#当为es时可以填写多个地址,以逗号分割
url: 192.168.10.208:9200,192.168.10.209:9200
username: elastic
password: changeme
-
#【必填】标识数据源,每个必须不一样
db-id: 2
#目标数据源的类型(可以为es或mysql或clickhouse)
type: mysql
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&useSSL=false&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&useOldAliasMetadataBehavior=true&allowMultiQueries=true&serverTimezone=Hongkong
username: root
password: root
-
#【必填】标识数据源,每个必须不一样
db-id: 3
#目标数据源的类型(可以为es或mysql或clickhouse)
type: clickhouse
url: jdbc:clickhouse://127.0.0.1:8121/test
username: default
password: default
#【必填】源数据库【Tdsql】,可以配置多个数据库
source.mysql:
datasources:
-
#【必填】标识数据源,每个必须不一样
db-id: 1
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&useSSL=false&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&useOldAliasMetadataBehavior=true&allowMultiQueries=true&serverTimezone=Hongkong
username: test
password: test
#【必填】配置同步到elasticsearch的基本规则
sync2any:
#【选填】mysqldump工具的地址
mysqldump: D:\program\mysql-5.7.25-winx64\bin\mysqldump.exe
#【选填】监控告警,只有填写了此参数才能开启监控告警,具体配置参考下面章节。多个secret用逗号分隔。
alert:
secret: aaaa
# 规则比较灵活,可以配置多个
sync-config-list:
-
#【必填】待同步的源数据库ID
source-db-id: 1
#【必填】同步到的目标源数据库ID
target-db-id: 2
#【必填】要同步的表名,支持正则表达式,多个表名用逗号分隔
sync-tables: "t_member,t_member_order_[0-9]{10}"
#【选填】延迟超过60秒,将会触发告警
max-delay-in-second: 60
#【选填】超过120分钟没接收到同步消息,将会触发告警
max-idle-in-minute: 120
#【选填】告警发生180分钟后,如果未恢复,则再次告警
next-trigger-alert-in-minute: 180
#【选填】默认表名后缀(优先级比rules.index_table小)
target-table-suffix: _all
#【选填】是否载入原始数据(0否,1是;默认开启【1】)
dump-origin-data: 0
mq:
# 监听的CKAFKA的topic名称
topic-name: test-t_member
#消费者使用的topicGroup。每次重启本应用都会从kafka的"earliest"处开始读取。(多个同步任务不可以使用同一个topicGroup)
topic-group: local-test-consumer-group
#mq帐号
username: test
#mq密码
password: test
#【选填】此处可以配置TDSQL到elasticsearch的映射规则
rules:
-
# 匹配此rule的表名,支持正则表达式
table: t_member_order_[0-9]{10}
# 同步到目标数据源的表名或index(对es来说)
index_table: t_member_order
# 【可选,目标数据库只支持Mysql】分表计算器,填写在spring容器中的bean名称
dynamic_tablename_assigner: mysqlDynamicDataAssign
# 【可选,当使用分区计算器时必填】分区健
sharding_key: group_code
# 【目标数据库为es时】自定义同步到es的字段名称和字段类型(es的类型),字段类型请参考类:com.jte.sync2any.model.es.EsDateType
map: '{"user_img":"userImg","user_code":",integer","user_age":"userAge,integer"}'
# 字段过滤,多个字段用逗号分隔。如果有值,则只保留这里填写的字段。
field-filter: "user_id,user_name"当我们发现了一些数据错误,想要重新消费之前的消息时可以用到该接口。但是该功能只支持一个分区的情况。
- 登录腾讯云,进入数据订阅,找到消费管理中的“查询消费点”功能。
- 查询你要重置的时间当时的消费点。
- 以put方法调用
http://127.0.0.1:9070/offset?topicName=topic-subs-7a4bu6zz48-tdsqlshard-1dksu10j&sourceDbId=1&topicGroup=consumer-grp-subs-7a4bu6zz48-test&offset=0接口。
当我们源数据库的A表要按照一定规则同步到目标数据库的A_1,A_2,A_3等多个表时可以用到自定义目标数据分发规则。
- 配置文件中
rules下配置dynamic_tablename_assigner属性,该属性的值为Spring bean的名称。 - 该新增的自定义规则类只需要基础抽象类
com.jte.sync2any.load.DynamicDataAssign,并实现dynamicTableName方法即可。
- 当tdsql的表中存在数据,且es中index不存在或者index中无document时才会dump原始数据同步到es。
- es的index默认命名规则为“数据库名-表名”,es那边的字段名和tdsql保持一致。默认所有同步过去的名称都会转化为小写。
- mysql的table默认命名和源数据库一致。
- 一旦同步过程中发生任何错误,该任务会停止继续同步,防止数据错乱。其他正常的任务可继续执行,不影响。
- sync2any会将数据库中的主键当作es中document的主键。碰到复合主键时,多个主键使用“_”符号隔开。
- 在es中的更新和删除操作都是通过es的主键来定位document
- 因为在同步原始数据前队列中会堆积消息(binlog),这意味着我们会重复消费到以前的binlog。此时要求update不能修改主键值,否则重复消费binlog时可能导致消息错乱。
- 当目标数据库的表引擎为CollapsingMergeTree系列时会默认追加_sign列。
- 如果想要保证数据同步的正确性,创建数据订阅时,kafka的分区数填1。
- 延迟告警的设置最好大于10秒,因为本身就有3-4秒的延迟。
- 建议每个表都单独建立一个同步任务,并且用不同的topic。这样可以隔离故障,降低时同步延迟。目前腾讯云的数据订阅费用较高,如果只建立一个同步任务,就只能使用不同的topicGroup进行隔离。
- CKAFKA中每一条msg都对应数据库中一行被修改的记录,这意味着当你一次修改很多行记录时,同步延迟会加大。
- 不同的机器性能不一样,要算每个TOPIC的QPS,可以通过控制面板的tpq参数计算。也就是1000(ms)/tpq=QPS。
- 表中必须要有主键。
- 如何判断同步成功?
可以通过count来比较记录的数量,也可以用关键指标(如余额、订单金额)“求和”看两端是否一致。
- 如果同步途中要新增字段怎么办?
首先需要在目标端(ck或es)添加新的字段,再在源端添加新字段。最后重启sync2any来重新获取源端最新表结构。
- 其他版本的es能够使用吗?
目前只测试了7.x版本,其他版本可以自己试一试。
- 同步途中失败了,导致同步停止了该怎么办?
首先确定是否是sync2any的代码问题,如果是解析逻辑有问题,则需要修改bug。如果是es端发生问题,可以重启sync2any重新同步。怕消息有丢失的话,可以到CKAFKA控制台重新设置消费者的位置(可按时间)。如果是同步任务本身有问题,则需要新建同步任务,或工单联系腾讯云。
- clickhouse中的当表引擎使用
版本折叠树时,同步后数据不一致?
**如果目标库clickhouse使用版本折叠树,则初次全量同步和增量同步期间必须得让数据库停止写入数据。(相当于初次同步没有增量数据)**因为当sync2es同步完全量数据之后,再追加增量数据,此时增量数据中包含了一部分重复数据(全量数据的部分数据)。这样会造成版本折叠树无法正确的折叠数据。
本项目基于spring boot 2.x,充分利用了spring的生态。非常利于扩展和二次开发。如果感兴趣或者需要对接腾讯云其他数据源,可基于本项目进行扩展。