- Instalar e preparar o ambiente para o treinamento Data Science com Python
- Introduction to Python
- Data Analysis With Pandas
- Data Visualization with Matplotlib and Seaborn
- Advanced Resources
- Machine Learning
- Projects
- Melhorias
Anaconda é uma ferramenta/plataforma para Data Science que permite gerir as distribuições de Python para os sistemas operacionais Windows, Linux e MAC. Então, por favor, instale o Anaconda. Neste tutorial, você vai encontrar os passos necessários para instalar o Anaconda no seu sistema operacional. Ao instalar o Anaconda, você estará instalando um ambiente para Data Science com todas as ferramentas necessárias como Python e suas principais bibliotecas, Jupyter Notebook e Spyder.
Os dataframes que serão utilizados no treinamento estão aqui. Faça o download dos dataframes para o seu computador (ou Github ou Google Drive).

Jupyter Notebook é um ambiente computacional web, interativo para criação de documentos “Jupyter Notebooks”. O documento é um documento JSON com um esquema e contém uma lista ordenada de células que podem conter código, texto, fórmulas matemáticas, plotagens e imagens. A extensão dos notebooks é “.ipynb”. Vamos criar nossos programas Python utilizando principalmente o Jupyter Notebook.
- Jupyter Notebook Tutorial: The Definitive Guide
- Jupyter Notebook for Beginners: A Tutorial;
- Supercharging Jupyter Notebooks;
- Getting Started With Jupyter Notebook for Python
- Bringing the best out of Jupyter Notebooks for Data Science
Eis aqui algumas razões:
- Because Python is a widely used high-level and general-purpose programming language;
- Open-source;
- Fácil de aprender;
- Ferramenta Analítica poderosa;
- Intuitiva;
- Alta demanda e popularidade;
- Aumento exponencial de usuários e comunidade Python;
- Aumento da produtividade.
- Pandas - Análise e transformação de dados. É uma das bibliotecas mais populares do Python;
- SciPy (Scientific Python) - Rica em funcionalidades para Álgebra Linear, Transformaçes de Fourier, Otimização e muitas outras funçes matemáticas;
- NumPy (Numerical Python) - Uma bibliotecas mais importantes do Python. Muito utilizada para Álgebra Linear, Transformadas de Fourier e geração de números aleatrios. Muitas outras bibliotecas do Python foram escritas em Numpy.
- Matplotlib;
- As referências a seguir apresentam uma vasta variedade de gráficos e exemplos usando Matplotlib:
- Matplotlib Examples;
- datavizproject - Vale a pena olhar rapidamente os tipos de gráficos possíveis de produzir com Matplotlib.
- As referências a seguir apresentam uma vasta variedade de gráficos e exemplos usando Matplotlib:
- Scikit-learn - Biblioteca para Machine Learning: clustering, Regressão (Linear, Logistic, Ridge, LASSO e outras), classificação, redução de dimensionalidade (Principal Components Analysis, Factor Analysis), Redes Neurais e etc;
- Seaborn - Outra biblioteca para data visualization. Veja aqui os tipos de gráficos que esta biblioteca é capaz de fazer.
Embora não seja escopo deste curso, gostaria de citar outras importanes bibliotecas para Data Science e Inteligência Artificial:
-
Keras - Keras é uma API de redes neurais de alto nível e fácil de usar, capaz de rodar sobre o Tensorflow. Para aqueles interessados em Redes Neurais, Deep Learning e Inteligência Artificial, sugiro ler este artigo onde o autor mostra como implementar modelos Deep Learning usando Keras.
-
Tensorflow - O Tensorflow é uma biblioteca de código aberto que ajuda os cientistas de dados a desenvolver e treinar modelos de aprendizado de máquina utilizando paralelismo computacional.

Se você tem uma conta do Google, você pode executar o Python usando o Google Colab. Esta é uma interessante alternativa para usar o Python on-lines sem qualquer instalação. Adicionalmente, você pode integrar o Google Colab com o GitHub ou Google Drive para guardar seus projetos de Data Science. Você pode usar o Jupyter Notebook no Google Colab , permitindo que você use a GPU Tesla K80, ou seja, 12 GB de memória RAM.
- Getting Started With Google Colab
- Getting the Most Out of Your Google Colab (Tutorial)
- How to use Google Colab
- Mastering the features of Google Colaboratory !!!
GitHub é uma plataforma de hospedagem de código para colaboração e controle de versão, permitindo que as equipes de desenvolvimento trabalhem juntos.

Docker é uma alternatia mais eficiente à virtualização que garante maior facilidade na criação e administração de ambientes isolados chamados de containers, tendo por objetivo disponibilizar software/soluções para o usuário final de forma mais rápida.
- AFINAL, O QUE É DOCKER?
- What is Docker and why is it so darn popular?
- Learn Enough Docker to be Useful
Machine Learning é a principal ferramenta para a Inteligência Artificial e é um dos campos científicos mais amplamente estudados atualmente. Uma quantidade considerável de literatura foi publicada sobre Machine Learning. Nosso objetivo neste treinamento é fornecer os aspectos mais importantes do Machine Learning usando o Python.
-
os princípios e técnicas fundamentais de Data Science através de exemplos e casos reais e práticos;
-
Formular uma solução plausível e estratégica para resolver probemas da Ciência de Dados usando o "Data Science Process" incluindo: formulação, EDA (Análise Exploratória de Dados incluindo Feature Engineering), Modelagem (incluindo hyperparameters de tunning e modelos de Machine Learning), Avaliação (incluindo Validação Cruzada), Implantação, Monitoramento e Feedback;
-
Usar EDA para avaliar e entender o impacto das anormalidades de dados (Missing Values e Outliers), bem como aplicar o tratamento apropriado;
-
Usar EDA para identificar variáveis/features redundantes. Nosso objetivo será selecionar as variáveis mais importantes para o modelo e tomada de decisão.
-
Entender o impacto das amostra desequilibradas (Imbalanced samples);
-
Preparar dataframes (conjunto de dados) para aplicação dos algoritmos mais apropriados, quer sejam algoritmos de aprendizado supervisionado e não supervisionado, incluindo a divisão apropriada do conjunto de dados para treinamento, validação e teste;
-
Entender e aplicar as principais transformações de dados;
-
Entender, identificar e aplicar o algoritmo apropriado para um determinado problema, bem como apresentar os prós e contras de cada algoritmo que poderia ser aplicado ao problema;
-
Entender, identificar e aplicar adequadamente a métrica de avaliação dos modelos de Machine Learning;
-
Entender, identificar, evitar e/ou tratar problemas relacionados à overfitting;
- As melhores plataformas de Competição para Cientistas de Dados
- The 5 Sampling Algorithms every Data Scientist need to know
- 150+ Business Data Science Application in Python
Afirma que 80% dos efeitos provêm de 20% das causas.
Surgiu da observação de Andrew e Jonathan depois de constatarem que os 20% mais talentosos entregavam 80% dos resultados em toda a indústria de vendas. Desta forma, Andrew e Jonathan viram a necessidade de um negócio que recruta de forma diferente, concentrando-se apenas nos 20% melhores da força de trabalho de vendas.
A seguir, outros exemplos da aplicação da Lei de Pareto:
- 80% da riqueza da Itália pertencia a apenas 20% da população;
- 20% dos melhores funcionários geram 80% dos resultados;
- 20% dos consumidores geram 80% das receitas/lucros;
Em nosso caso, estou interessado e focado em transmitir-lhes 20% dos conteúdos realmente relevantes de Data Science que lhe possibilite analisar dados e construir modelos de Machine Learning em 80% das vezes... O que você acha disso?
Python é uma linguagem muito versátil. Com isso quero dizer que há várias maneiras de fazer a mesma tarefa. Se tentarmos explorar todas as formas de fazer a tarefa XPTO, perderemos muito tempo. Portanto, vou me concentrar no que é mais importante.
- Todo o material será entregue digitalmente. Não se preocupe em copiar! Gostaria da sua total atenção, pois temos muito conteúdo. Além disso, seu foco é primordial para aprender os conceitos;
- Faça perguntas! Se alguma coisa (material, explicação e etc) não estiver claro, pergunte-me. Se o material não estiver claro, notifique-me para que eu possa melhorá-lo.
- Esse material é e sempre será um trabalho em andamento com melhoria contínua. Por favor, ajude-me a melhorá-lo porque ele estará disponível aos demais colegas que não tiveram a oportunidade de estar aqui conosco hoje;
- Dependendo do rumo que as coisas tomarem, pode ser que eu não consiga cobrir todo o conteúdo do curso, mas prometo me esforçar para cobrir pelo menos os pontos principais da Ciência de Dados;
- Se você identificar qualquer aplicação deste conhecimento/conteúdo em sua área/departamento, por favor, compartilhe comigo. Mapear as necessidades dos clientes faz parte do processo de melhoria contínua da formação, além de me ajudar a pensar e construir exemplos/estudos de caso/projetos cada vez mais associados à realidade dos clientes;
- Participe e compartilhe conhecimento, não importa quão tímido (a) ou reservada você seja!
- Sua contribuição é muito importante;
- Estou aqui para ajudá-lo, mesmo quando o curso acabar;
- Seu feedback honesto e sincero é um presente pra mim, não importa o quanto você o julgue difícil;
- Estou aqui para aprender também!
- Dados nunca estão limpos e é no tratamento e preparação dos dados que o Cientista de Dados gasta aproximadamente 80% do seu tempo. Considere que se "entra lixo --> sai lixo". Mais uma: o melhor algoritmo de ML do mundo não vai resolver o problema caso os dados não tenham qualidade.
- 95% dos problemas não requerem Deep Learning. Veremos alguns exemplos em que os modelos simples e tradicionais entregam ótimos resultados em comparação com modelos mais sofisticados;
- Em 90% dos casos, Generalized Linear Models (GLM) vai resolver o problema;
- Big Data é somente mais uma ferramenta;
- Sugiro fortemente você abrir a mente para o paradigma Bayesiano. Pelo menos para mim, faz mais sentido; Quer um exemplo?
- Na maioria das vezes, ninguém se importa com o que você fez. Só querem o resultado.
- Academia e Business são mundos totalmente diferentes;
- Apresentação é a chave - Aprenda a vender suas ideias e domine o Powerpoint;
- Todos os modelos são falsos, mas alguns são úteis. Quotations of George Box
- Não existe (pelo menos até agora) processo automático para ML, embora existam ferramentas que nos ajudarão a selecionar as melhores variáveis, na maioria das vezes você terá que sujar a mão.
"Information is the oil of the 21st century, and analytics is the combustion engine." - Peter Sondergaard, SVP, Garner Research;
Neste capítulo, vamos estudar as ferramentas, técnicas e algoritmos de Machine Learning que podem ser aplicados para resolver problemas de negócio. * No entanto, gostaria de frisar que Machine Learning é a parte mais sexy do trabalho! Gostaria de lembrar, mais uma vez, que 80% do trabalho está concentrada na parte mais difícil, que é o da preparação e tratamento dos dados. É esta parte do trabalho que realmente define se você é ou não um bom Cientista de Dados.
O foco deste capítulo será:
-
Linear, Logistic Regression, Decision Tree, Random Forest, Support Vector Machine and XGBoost algorithms for building Machine Learning models;
-
Understand how to solve Classification and Regression problems in Machine Learning;
-
Ensemble Modeling and techniques like Bagging and Boosting;
-
Learn how to reduce dimensions using Feature Engineering, Principal Component Analysis (PCA) and t-SNE;
-
Understand and use Preprocessing Methods from scikit-learn (To help with this chapter, follow: https://scikit-learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html#sphx-glr-auto-examples-preprocessing-plot-all-scaling-py);
-
How to evaluate your Machine Learning models and improve them through Feature Engineering;
-
Learn Unsupervised Machine Learning Techniques like k-means clustering and Hierarchical Clustering;

CRISP-DM (Cross-Industry Process for Data Mining) é uma metodologia amplamente utilizada e estruturada para o planejamento e desenvolvimento de um projeto de Data Mining.
Esta fase é dedicada a entender o que se deseja alcançar a partir de uma perspectiva de negócios. O objetivo deste estágio do processo é descobrir fatores importantes que possam influenciar o resultado do projeto. Há várias metodologias que podem ajudá-lo nesta fase. Sugiro a utilização da metodologia SMART para ajudá-lo nesta fase.


- Estebelecer claramente os objetivos do Projeto;
- Produzir o Project Plan (Recursos, limitações, suposições, riscos e etc);
- Definir critérios de sucesso do Projeto;
O foco desta fase está na coleta e exploração dos dados. Lembre-se de que a precisão dos modelos de ML depende da quantidade e qualidade dos dados.
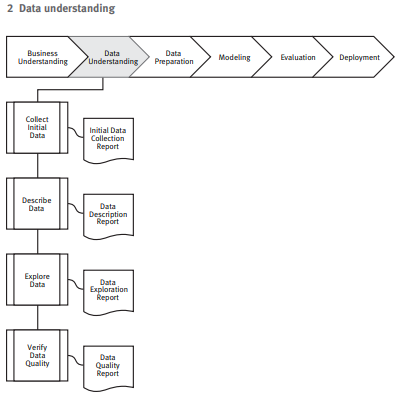
- Exploratory Data Analysis
Também conhecido por EDA, nesta fase nosso foco está na exploração do dataframe, descobrir relações e descrever os dados em geral. Utilize-se das técnicas de Data Visualization para detectar relações relevantes entre as variáveis, desequilíbrios de classes e identificar variáveis mais importantes.
Nesta fase o Cientista de Dados vai investir 80% do seu tempo, pois esta fase é dedicada a coletar, preparar, transformar e limpar dados: remover duplicatas, corrigir erros, lidar com Missing Values, normalização, conversões de tipo de dados e etc.

- 3DP_Feature Engineering
Nesta fase temos 2 objetivos: corrigir problemas nas variáveis e derivar novas variáveis.
-
É uma atividade que requer muita criatividade, intuição, conhecimento dos dados e do problema a ser resolvido;
-
Não há um guia ou livros para nos ajudar a projetar e selecionar bons atributos;
-
Muitas vezes o Data Scientist deve consultar o Business Analyst para fazer sentido com os dados;
-
O principal objetivo da Feature Engineering é reduzir a complexidade do modelo;
-
Geralmente aplicar transformaçes como "raiz quadrada", "elevar à 3 potência" ou "log" em certas colunas melhora a qualidade das predições uma vez que estas transformações corrigem a distribuição das variáveis.
-
Transfor e alterar tipos das variáveis;
-
Portanto, Feature Engineering tem 2 objetivos/fases:
- Fase 1: O foco desta fase é corrigr possveis problemas de preenchimento das variáveis. Por exemplo, considere a variável 'Sexo' com os seguintes preenchimentos: m, M, Male, Men, Man, mALE, MALE, tudo isso para designar o sexo masculino. Isto é um problema de preenchimento e nesta fase vamos corrigir esses problemas.
- Fase 2: Criar mais atributos a partir dos atributos disponíveis.
-
3DP_Missing Values Handling
Nosso foco nesta fase é identificar e tratar os Missing Values que neste curso são chamados de NaN (Not a Number). A tarefa de tratar os NaN são também chamados de Imputing Missing Values. Quando estamos diante de uma variável com grande número de NaN's (tanto numricas quanto categóricas) uma prática interessante é construir uma variável indicadora para indicar se aquele registro é ou não um NaN. Veremos isso mais tarde na prática.
- 3DP_Outliers Handling
Nosso foco aqui é identificar e tratar os Outlier. Tratar outliers significa, por exemplo, descartá-lo/deletá-lo ou imputá-lo usando Média/Mediana/Moda. Outra alternativa é aplicar o Máximo para os Outliers superiores e Mínimo para os outliers inferiores. O Gráfico de Boxplot pode ajudar nesta fase. Uma outra alternativa interessante é usar K-Means para agrupar as observaçes da variável. Neste caso, ter-se-à um cluster com os outliers, tanto superiores quanto inferiores.
- 3DP_Data Transformation
Significa colocar as variáveis numa mesma escala. Há várias transformações que podem ser aplicadas nesta fase. Principais transformações que podem ser aplicadas nas variáveis:
-
StandardScaler
-
MinMaxScaler
-
KBinsDiscretizer
-
MaxAbsScaler
-
RobustScaler
-
Normalizer
- Aplica as normas L1 ou L2. A norma L2 é default no scikit-learn.
Obs.: As funções matemáticas desta sessão foram escritas com a ajuda do site: https://www.codecogs.com/eqnedit.php?latex=\mathcal{W}(A,f)&space;=&space;(T,\bar{f}).
- 3DP_Feature Selection ou Dimensionality Reduction
Selecionar os melhores atributos/variáveis para o(s) modelo(s) de ML. Pode-se utilizar Random Forest para avaliar a importância de cada atributo/variável para o modelo.
Algoritmos diferentes podem ser aplicados ao mesmo problema. Sugiro aplicar o maior número de algoritmos possveis e escolher o que entregar melhor resultados.

[Incluir figura!!!]
[Incluir figura!!!]
 Source: Choosing the right estimator
Source: Choosing the right estimator
- Amostras de treinamento e teste
Nesta fase o Cientista de Dados deve selecionar aleatoriamente as amostras de treinamento e teste (ou validação) dos modelos de ML. Geralmente usamos 70% da amostra para treinamento e o restante, 30%, para teste/validação. Outras opções são usar os percentuais 80/20 ou 75/25.

- Train the Model
Treinar o modelo com os dados significa encontrar o melhor (ou a melhor combinação de algoritmos de ML) que explica o fenômeno sob estudo. Vamos discutir esse tópico com mais detalhes mais tarde.
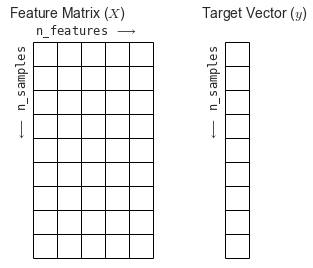
As informaçes do dataframe devem estar convenientemente organizadas da seguinte forma:
- Parameter Tuning
Esta fase tem por objetivo otimizar o melhor modelo de ML da fase anterior. Os hiperparâmetros de modelos podem incluir: número de etapas de treinamento, taxa de aprendizado, valores de inicialização e distribuição, etc.
- Ensemble Methods
Ensemble Methods envolve a utilização de mais de um algoritmo de ML são treinados para resolver o mesmo problema e combinados para obter melhores resultados.
 Source: Building an Ensemble Learning Model Using Scikit-learn
Source: Building an Ensemble Learning Model Using Scikit-learn
As figuras para Ensemble podem ser encontradas aqui: https://github.com/MathMachado/DSWP/blob/master/Material/Boosting%2C%20Bagging%2C%20and%20Stacking%20%E2%80%94%20Ensemble%20Methods%20with%20sklearn%20and%20mlens.7z ou aqui: https://medium.com/@rrfd/boosting-bagging-and-stacking-ensemble-methods-with-sklearn-and-mlens-a455c0c982de.
Os tipos de ensemble no scikit-learn são:
- Boosting
- Colocar a figura aqui
- Stacking
- Colocar a figura aqui
- Bagging
- Colocar a figura aqui
- Ensemble methods: bagging, boosting and stacking
- Ensemble Methods in Machine Learning: What are They and Why Use Them?
- Ensemble Learning Using Scikit-learn
- Let’s Talk About Machine Learning Ensemble Learning In Python
- Boosting, Bagging, and Stacking — Ensemble Methods with sklearn and mlens
- Tune: a library for fast hyperparameter tuning at any scale
Nesta fase identificamos e aplicamos as melhores métricas (Accuracy, Sensitivity, Specificity, F-Score, AUC, R-Sq, Adj R-SQ, RMSE (Root Mean Square Error)) para avaliar o desempenho/acurácia/performance dos modelos de ML. Treinamos os modelos de ML usando a amostra de treinamento e avaliamos o desempenho/acurácia/performance na amostra de teste/validação.

Eu comprei o curso: https://www.udemy.com/course/machine-learning-in-python-random-forest-adaboost/. Dá pra aproveitar alguma coisa?
Implementa o modelo (ou conjunto de modelos nos casos de Emsembles Methods).

- As variáveis no Python devem começar com letras (A-Z/a-z) ou underscore(_)
- As variáveis Python não devem conter símbolos especiais como, por exemplo, !, @, #, $, %, .
- Palavras reservadas do Python não podem ser usadas como nomes de variáveis.
A nomenclatura (sugerida e adotada neste treinamento) identifica o tipo de variável:

- Getting Started with Python
- Python Tuples
- Python Lists
- Python Sets
- Python Dictionaries
- Python Series
- NumPy
- Aggregations & Group Operations
- Functions
- Working With Dates and Times
- Data Analysis with Pandas
- Index & Selection
- Missing Values Handling
- Combining Dataframes: concat() and append()
- Combining Dataframes: merge & join()
- Aggregations & Grouping
- Pivot Tables
- [Sampling Strategies](Sampling Strategies.ipynb)
- [Python RegEx - Regular Expressions](Python RegEx - Regular Expressions.ipynb)
- Modules
- Fake Data
- [Classes and Methods](Classes and Methods.ipynb)
- [Statistics and Probability](https://github.com/MathMachado/DSWP/blob/master/Notebooks/Statistics and Probability.ipynb) - Finalizar!
- Introduction to Scilit-Learn
- Naive Bayes
- Linear regression
- Support Vector Machines
- Decision Trees & Random Forest
- Feature Engineering
- k-Means Clustering
- CRISP-DM as a Data Science Projecy
- 3DP - Data Preparation
- [4M - Modeling]
- [5MSE - Modeling Selection and Evaluation]
- [6D - Deployment]
- Pipelines usando Titanic Dataframe
- [Ensemble Models] --> Veja esse exemplo: https://github.com/MathMachado/DSWP/blob/master/Material/Building%20an%20Ensemble%20Learning%20Model%20Using%20Scikit-learn.pdf
A seguir, vos apresento os projetos/estudos de caso:.
-
Titanic - Problema da Classificação
- 3DP - Data Preparation
- [4M - Modeling]
- [5MSE - Modeling Selection and Evaluation]
- [6D - Deployment]
-
[Data Anonymization(Data Anonymization.ipynb)