Zhihui Xie*1, Jie Chen*2, Liyu Chen2, Weichao Mao2, Jingjing Xu2, Lingpeng Kong1
1The University of Hong Kong, 2Bytedance, Seed
📃 Paper • 🔭 Project Page • 🤗 Model
We propose CTRL, a framework that trains LLMs to critique without human supervision, enabling them to supervise stronger models and achieve test-time scaling through iterative critique-revisions.

-
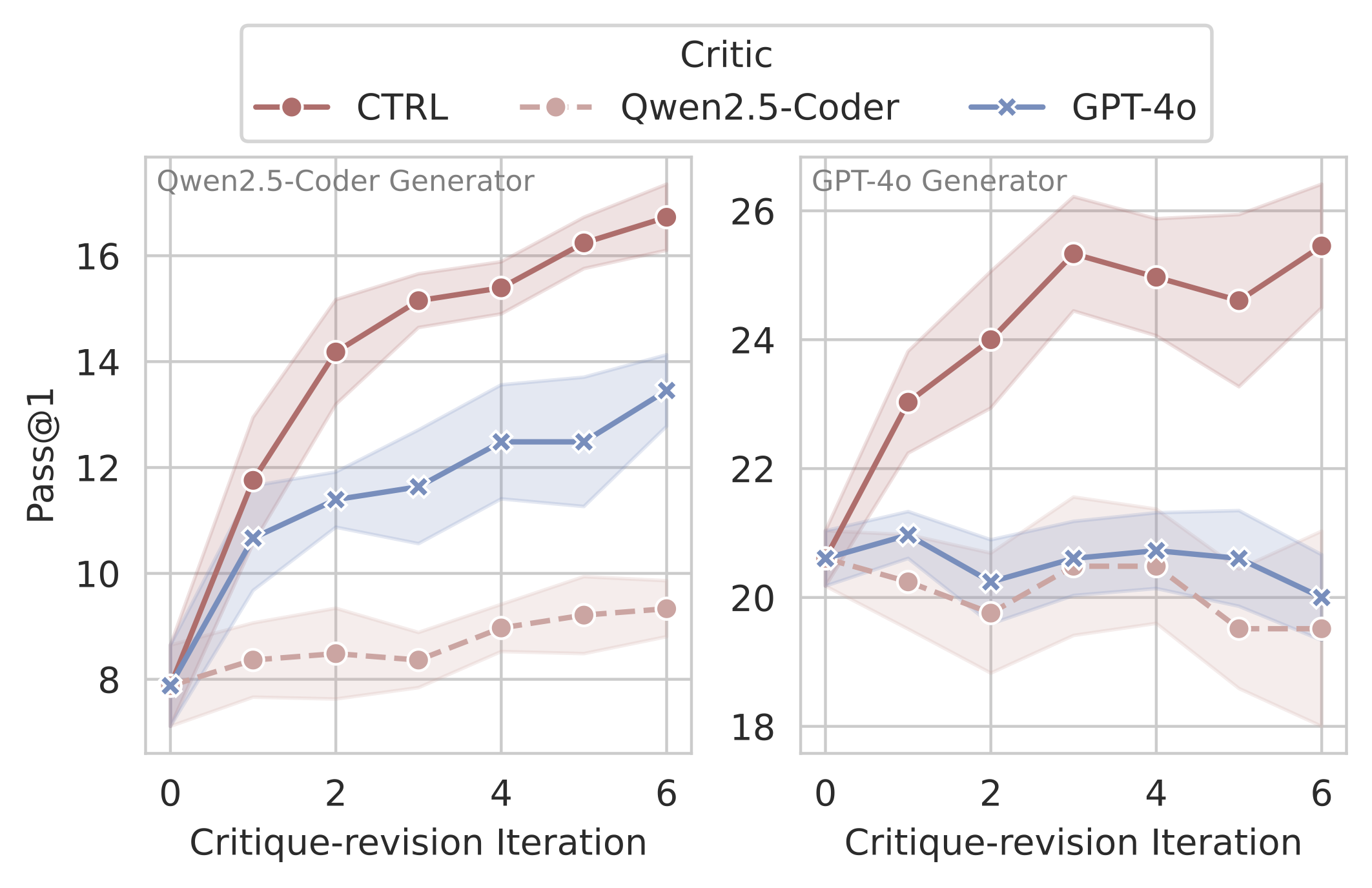
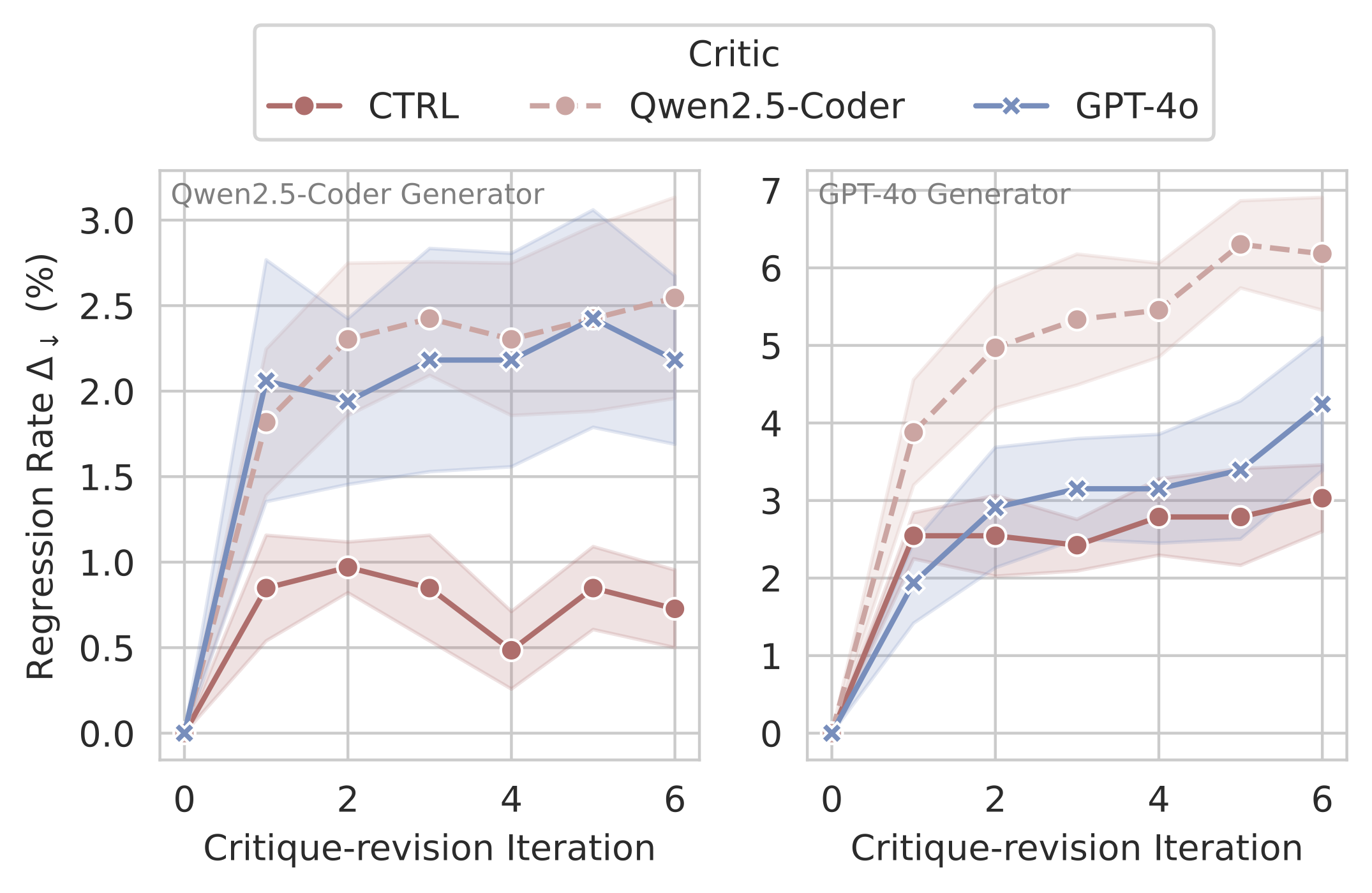
Test-time Scaling: Qwen2.5-Coder-32B-Ins with the CTRL critic achieves 106.1% relative improvement in Pass@1 on CodeContests through multi-turn critique-revision, while maintaining low error rates across iterations
-
Model-Agnostic: The CTRL critic improves performance across different models (23.5% improvement with GPT-4o) and tasks (CodeContests, LiveCodeBench, MBPP+)
-
Critics-as-RMs: The CTRL critic achieves 64.3% accuracy on JudgeBench as a generative reward model, competitive with stronger models like Claude-3.5-Sonnet
See our project page for detailed analysis and more results.
You can install the dependencies with the following command:
pip install -r requirements.txtFor evaluating code correctness, we use SandboxFusion to deploy the code sandbox.
docker run -it -p 8080:8080 vemlp-cn-beijing.cr.volces.com/preset-images/code-sandbox:server-20241204
export SANDBOX_FUSION_ENDPOINT="your_sandbox_endpoint"We use the TACO dataset for training. Preprocess the data using:
python scripts/data/preprocess_taco.pyOur training process consists of two stages: (1) SFT on synthetic data guided by execution feedback and (2) RL with verifiable rewards and GRPO.
We start with generating synthetic data with the following command:
bash examples/gen_taco.shThen, fine-tune the model using the following command:
bash examples/train_sft.shTrain with GRPO using verifiable rewards from sandbox execution:
bash examples/train_rl.shWe evaluate the model with the following command (e.g., for CodeContests):
bash examples/eval_codecontests.shIf you find this project useful, please consider citing:
@article{xie2025teaching,
title={Teaching Language Models to Critique via Reinforcement Learning},
author={Xie, Zhihui and Chen, Liyu and Mao, Weichao and Xu, Jingjing and Kong, Lingpeng and others},
journal={arXiv preprint arXiv:2502.03492},
year={2025}
}This project builds upon several amazing open-source projects:
- verl: RL training framework
- deepseek-coder: SFT training scripts
- SandboxFusion: Code execution environment
This project is licensed under the Apache 2.0 license.