{kind=link}
This library is designed for extracting only the main content from HTML.
It was developed for obtaining information related to LLM and for data input to LangChain and LlamaIndex.
Since this library contains element information and hierarchy information of HTML, it is useful when utilizing them.
For example, it can be helpful in obtaining a list of links or headers from the main content.
While trafilatura is an excellent library for main content extraction, it has issues such as missing necessary data or inability to output HTML.
To address these problems, this library exists.
The sequence of main content extraction is as follows:
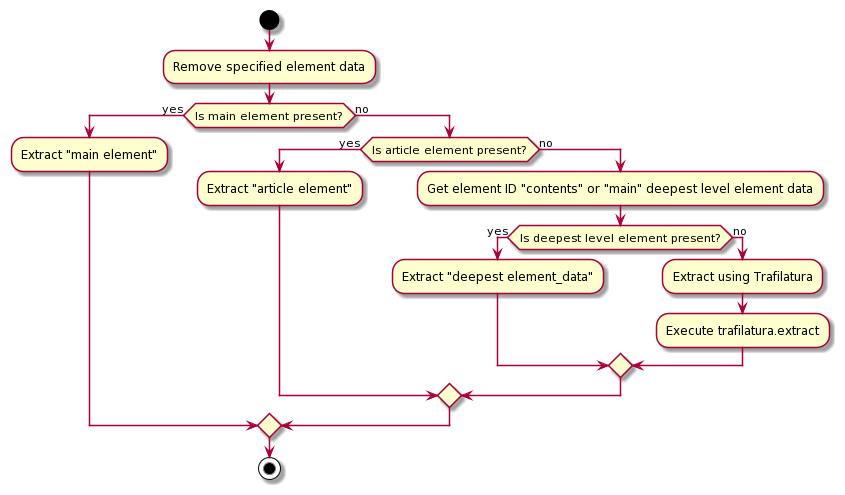
In addition to HTML format, output in Text format and Markdown format is also supported. This is to make it easier to output data in a format that is more convenient for LLM.
The extraction of main content uses trafilatura.
Since trafilatura cannot output in HTML format, it is output in XML format containing HTML information and then converted to HTML.
The conversion from XML to HTML is irreversible and does not perfectly match the original data.
pip install MainContentExtractor
import requests
from main_content_extractor import MainContentExtractor
# Get HTML using requests
url = "https://developer.mozilla.org/ja/docs/Web"
response = requests.get(url)
response.encoding = 'utf-8'
content = response.text
# Get HTML with main content extracted from HTML
extracted_html = MainContentExtractor.extract(content)
# Get HTML with main content extracted from Markdown
extracted_markdown = MainContentExtractor.extract(content, output_format="markdown")