A Sundai Club Project
This project is a work in progress
http://ai-news-hound.sundai.club/
From a "Journalism Hack" week. This project aims to visualize and compare topic data from various sources, including Reddit, Arxiv, Hacker News, and news articles. By scraping and processing data from these sources, the tool generates text embeddings using the SentenceTransformers library. These embeddings are then visualized using UMAP (Uniform Manifold Approximation and Projection - a way to make large embeddings just two-dimensions so they can be compared) to identify topic clusters and information 'deserts'—areas with sparse or minimal discussion.
The visualization shows color-coded dots to indicate the source of each topic and green hexagons to highlight topics that are not being actively reported on. This tool is designed to help users easily explore and identify gaps in information coverage across different media sources.
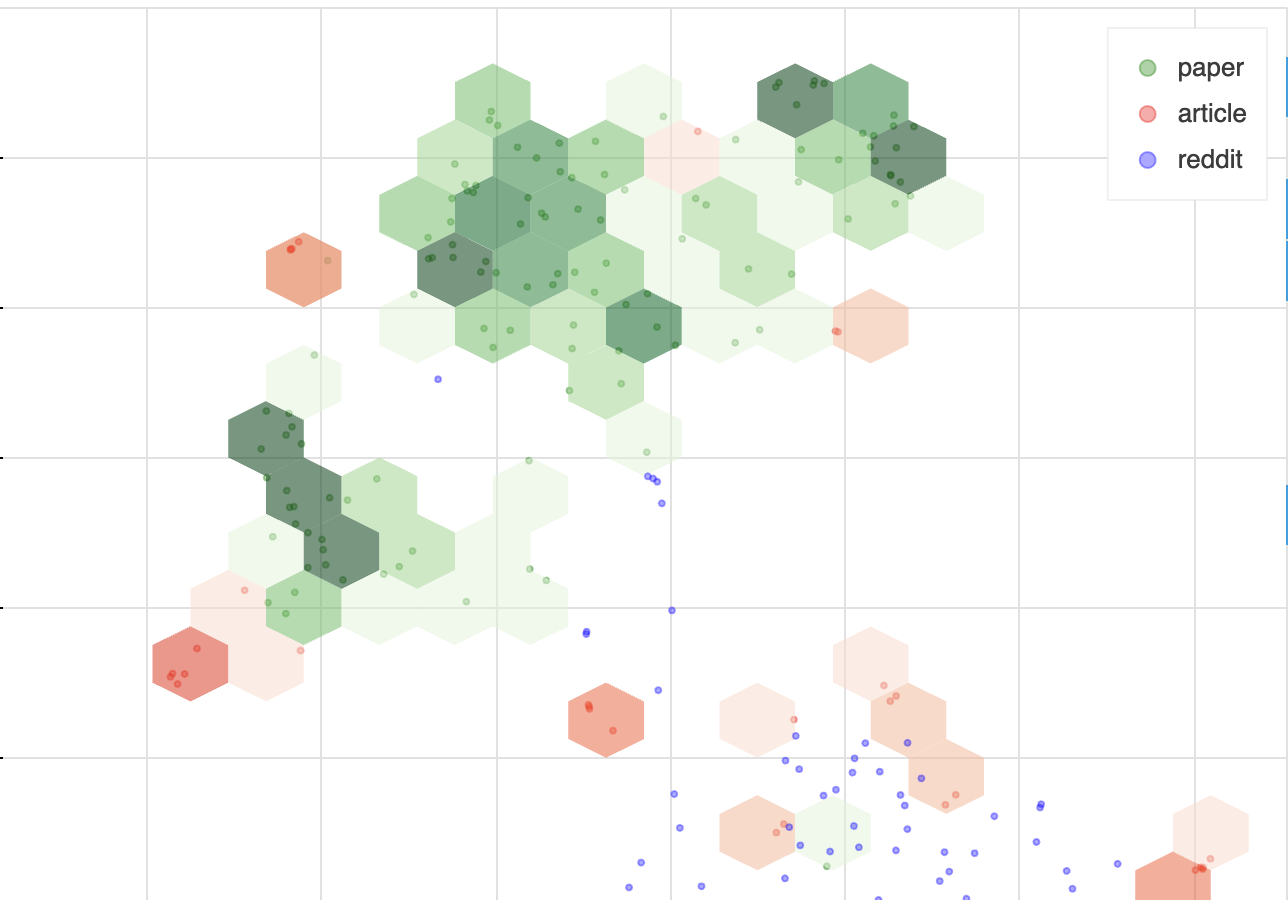
When looking at the visualization:
- Dot colors show the source (e.g., Reddit, Arxiv, news articles).
- Hexagon color indicates if something is being reported on (green means it's not).
We use SentenceTransformers (pip library documentation) to generate embeddings, specifically the all-MiniLM-L6-v2 model. These embeddings are created out of text for specific topics obtained from various APIs. The embeddings are then visualized in a UMAP using Bokeh and Streamlit.
To see the visualization, navigate to the streamlit folder and run:
streamlit run app.py
Make sure to install the necessary requirements first. It is recommended to use a Python virtual environment for this.
macOS/Linux:
python -m venv env
source env/bin/activate
Windows:
python -m venv env
.\env\Scripts\activate
pip install -r requirements.txt
The interface will load at http://localhost:8501/.
To load your own data, look under the data_source_apis folder. You can run topic_embeddings.py to use the Reddit, Mediastack, and Arxiv APIs (each in their own files).
Set up developer keys for:
- Reddit: Reddit Apps
- Mediastack: Mediastack Documentation
In addition to the above, there's a hacker-news.js file you'll need to run separately. Follow these steps:
npm install express axios
node index.js
Use the /search endpoint with a query parameter to search for articles. For example:
http://localhost:3000/search?q=agents
This will return 10 results, each containing the title of the post, the full body of comments as text, source, link, publication date, and type, formatted as a JSON response.
After generating new JSON files with the APIs, update the file names loaded into the visualization by replacing the inputs array in the get_embeddings_from_file function in app.py:
inputs = ["embeddings_AIAgents.json", "embeddings_AIAssistedHealthcare.json", "embeddings_AIDrivenPortfolioManagement.json", "embeddings_AIPublicPolicies.json"]
Replace with the appropriate file names.
In the notebooks folder, you will find our explorations in Jupyter notebooks for different models and UMAP settings.