Instructions for Windows. Make sure you have python installed. Linux users: async_pubmed_scraper -h
- Open command prompt and change directory to the folder containing
async_pubmed_scraper.pyandkeywords.txt - Create a virtual environment:
python -m pip install --user virtualenv,python -m venv scraper_env,.\scraper_env\Scripts\activate - Install dependencies:
pip install -r requirements.txt - Enter list of keywords to scrape, one per line, in
keywords.txt - Enter
python async_pubmed_scraper -hfor usage instructions and you are good to go
Example: To scrape the first 10 pages of search results for your keywords from 2018 to 2020 and save the data to the filearticle_data.csv:python async_pubmed_scraper --pages 10 --start 2018 --stop 2020 --output article_data
Collects the following data at 13 articles/second: url, title, abstract, authors, affiliations, journal, keywords, date
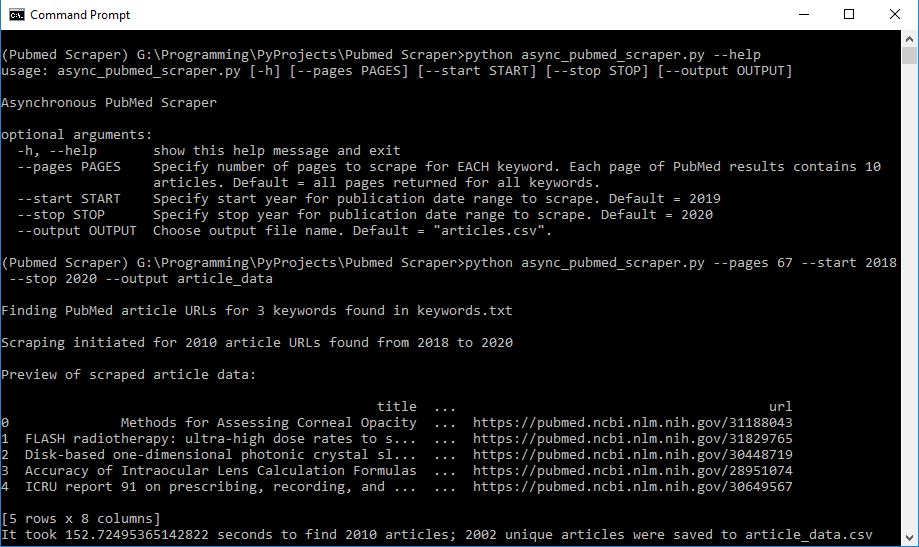

This script asynchronously scrapes PubMed - an open-access database of scholarly research articles - and saves the data to a PANDAS DataFrame which is then written to a CSV intended for further processing. This script scrapes a user-specified list of keywords for all results pages asynchronously.
PubMed provides an API - the NCBI Entrez API, also known as Entrez Programming Utilities or E-Utilities -
which can be used build datasets with their search engine - however, PubMed allows only 3 URL requests per second
through E-Utilities (10/second w/ API key).
We're doing potentially thousands of URL requests asynchronously - depending on the amount of articles returned by the command line options specified by the user.
It's much faster to download articles from all urls on all results pages in parallel compared to downloading articles page by page, article by article, waiting for the previous article request to complete before moving on to a new one. It's not unusual to see a 10x speedup with async scraping compared to regular scraping.
Simply put, we're going to make our client send requests to all search queries and all resulting article URLs at the same time.
Otherwise, our client will wait for the server to answer before sending the next request, so most of our script's execution time
will be spent waiting for a response from the (PubMed) server.