记录点云SemanticKITTI论文阅读记录
纯图像分割方法:可以考虑用在投影图上面,也可以考虑用在多体素分割的上面,用来提升不同大小的物体的分割

# 注意力部分的相关代码
if pred is None:
pred = cls_out
aux = aux_out
elif s >= 1.0:
# downscale previous
pred = scale_as(pred, cls_out)
pred = attn_out * cls_out + (1 - attn_out) * pred
aux = scale_as(aux, cls_out)
aux = attn_out * aux_out + (1 - attn_out) * aux
else:
# s < 1.0: upscale current
cls_out = attn_out * cls_out
aux_out = attn_out * aux_out
cls_out = scale_as(cls_out, pred)
aux_out = scale_as(aux_out, pred)
attn_out = scale_as(attn_out, pred)
pred = cls_out + (1 - attn_out) * pred
aux = aux_out + (1 - attn_out) * aux
# ocrnet.py 产生logit_attn的代码
def _fwd(self, x):
x_size = x.size()[2:]
_, _, high_level_features = self.backbone(x)
cls_out, aux_out, ocr_mid_feats = self.ocr(high_level_features)
# 产生相关的注意力
attn = self.scale_attn(ocr_mid_feats)
aux_out = Upsample(aux_out, x_size)
cls_out = Upsample(cls_out, x_size)
attn = Upsample(attn, x_size)
return {'cls_out': cls_out,
'aux_out': aux_out,
'logit_attn': attn}
'''
self.scale_attn 来源
可以看到是conv+bn+relu+sigmoid的注意力操作
'''
def make_attn_head(in_ch, out_ch):
bot_ch = cfg.MODEL.SEGATTN_BOT_CH
if cfg.MODEL.MSCALE_OLDARCH:
return old_make_attn_head(in_ch, bot_ch, out_ch)
od = OrderedDict([('conv0', nn.Conv2d(in_ch, bot_ch, kernel_size=3,
padding=1, bias=False)),
('bn0', Norm2d(bot_ch)),
('re0', nn.ReLU(inplace=True))])
if cfg.MODEL.MSCALE_INNER_3x3:
od['conv1'] = nn.Conv2d(bot_ch, bot_ch, kernel_size=3, padding=1,
bias=False)
od['bn1'] = Norm2d(bot_ch)
od['re1'] = nn.ReLU(inplace=True)
if cfg.MODEL.MSCALE_DROPOUT:
od['drop'] = nn.Dropout(0.5)
od['conv2'] = nn.Conv2d(bot_ch, out_ch, kernel_size=1, bias=False)
od['sig'] = nn.Sigmoid()
attn_head = nn.Sequential(od)
# init_attn(attn_head)
return attn_head输入两个不同分辨率的图像,网络学习不同物体在相应分支上的权重
- 多尺度分割,目前分割的效果是Cityscapes Dataset SOTA层次的模型
- 模型计算量、参数量都十分巨大,很难迁移

class PSA_p(nn.Module):
def __init__(self, inplanes, planes, kernel_size=1, stride=1):
super(PSA_p, self).__init__()
self.inplanes = inplanes
self.inter_planes = planes // 2
self.planes = planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = (kernel_size-1)//2
self.conv_q_right = nn.Conv2d(self.inplanes, 1, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_v_right = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_up = nn.Conv2d(self.inter_planes, self.planes, kernel_size=1, stride=1, padding=0, bias=False)
self.softmax_right = nn.Softmax(dim=2)
self.sigmoid = nn.Sigmoid()
self.conv_q_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False) #g
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_v_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False) #theta
self.softmax_left = nn.Softmax(dim=2)
self.reset_parameters()
'''
具体请见github代码
'''- 极化滤波( Polarized filtering):在通道和空间维度保持比较高的resolution(在通道上保持C/2的维度,在空间上保持[H,W]的维度 ),这一步能够减少降维度造成的信息损失;
- 增强(Enhancement):组合非线性直接拟合典型细粒度回归的输出分布。
- 代码比较简单易懂
主要思路+解读1
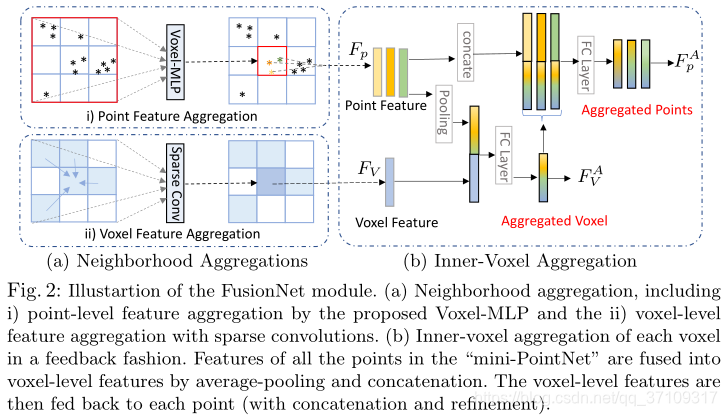
左边刻画的是Neighborhood aggregation
右边刻画的是Inner-voxel aggregation
主要是体素融合(依靠稀疏3D卷积spconv)和点云级别的邻点特征聚合(这里是否可以考虑单个体素的梯度信息,用来刻画物体表面的一个信息,感觉可以比较好的来刻画一个物体)

- 对于每一个体素,去用hash表索引这个点所在体素的身边的体素的点(针对特定的kernel_size,包括自己)
- 每个点去做空间偏移,即
$\triangle p=(x,y,z){point}-(x',y',z'){voxel}$
- Feature of Point(
$F_p$ ) concat with$\triangle p$ →Fc - MaxPooling
$F_{max}=max{F'_p, p{\in}N(V)}$ - $cat(F'p,F{max})$→$Fc$→$F^A_p$(更新单点的特征)
Point Interpolation(PointNet code) (上采样,by PointNet++ 解读 code)
论文中描述错误,插值方法应该引用自PointNet++,总而言之,论文PointNet和PointNet++很值得仔细看一看
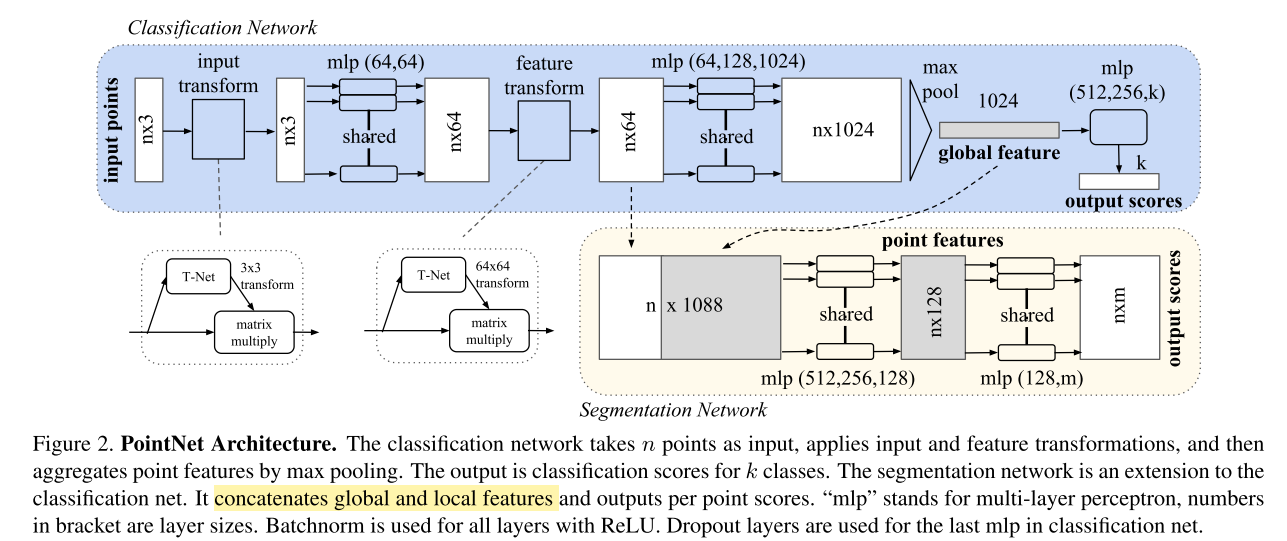

PointNet++的插值方法,使用CUDA自定义编写的插值,知乎上这么描述:如果将多个这样的处理模块级联组合起来,PointNet++就能像CNN一样从浅层特征得到深层语义特征。对于分割任务的网络,还需要将下采样后的特征进行上采样,使得原始点云中的每个点都有对应的特征。这个上采样的过程通过最近的k个临近点进行插值计算得到
Semantic KITTI: The Semantic KITTI dataset is a new large-scale LiDAR point cloud dataset in driving scenes. It has 22 sequences with 19 valid classes, and each scan contains 10–13k points in a large space of 160m×160m×20m. We use Sequences 0–7 and 9–10 as the training set (in total 19k frames), Sequence 8 (4k frames) as the validation set, and the remaining 11 sequences (20k frames) as the test set. Different from other point cloud datasets, LiDAR points are distributed irregularly in a large 3D space. There are many small objects with only a few points and the points are very sparse in the distance. All these make it challenging for semantic segmentation of the large-scale LiDAR point clouds.
- When compared to existing voxel networks, FusionNet can predict point-wise labels and avoid those ambiguous/wrong predictions when a voxel has points from different classes(可以区分更加细粒度的特征:由于点云的嵌入).
- When compared to the popular PointNets and point-based convolutions, FusionNet has more effective feature aggregation oper- ations (including the efficient neighborhood-voxel aggregations and the fine- grain inner-voxel point-level aggregations). These operations help produce better accuracy for large-scale point cloud segmentation(体素聚合依靠稀疏卷积 & 体素内部聚合??方法是什么).
- FusionNet takes full advantage of the sparsity property to reduce its memory footprint. For instance, it can take more than one million points in training and use only one GPU to achieve state-of-the-art accuracy(内存的高效).