Parser generator for Conditional Derivation Grammar
Conditional Derivation Grammar(CDG) is an extension for Context-Free Grammar(CFG).
The overall structure of CDG looks similar to CFG. The following shows a typical expression grammar written in CDG.
Expr = Term | Expr '+\-' Term
Term = Factor | Term '*/' Factor
Factor = Number | '(' Expr ')'
Number = '1-9' '0-9'*
A nonterminal name should be a string of English alphabet letters and digits, with the first letter being a letter. Note that all nonterminal names are treated equally, no matter whether the first letter is upper case or lower case, etc.
The equal symbol(=) is the delimiter between left-hand-side and right-hand-side and the vertical bar(|) is the delimiter between the derivation rules.
A single quote represents a single character. '*/' is matched to * or /. You can specify a range like '1-9', that means any character from 1 to 9. Ranges and characters may be in a single symbol, e.g. '_a-bA-B0-9'. Since the hyphen represents a range, \ must come before - to represent the hyphen letter, as in '+\-'.
In addition to the terminal and nonterminal symbols, CDG has 5 conditional nonterminals as follows:
A&Bis an intersection symbol. It matches to a string if the string is matched to bothAANDB.A-Bis an exclusion symbol. It matches to a string if the string is matched toA, but not toB.^Ais a followed-by symbol. It is matched to an empty string if there exists a following substring that is matched toA.!Ais a not-followed-by symbol. It is matched to an empty string if there exists NO following substring that is matched toA.<A>is a longest match symbol. It is matched to a string if the string is matched toA, and there is no longer match.
The following shows a CDG that imitates the lexical analyzers.
S = token*
token = keyword | operator | identifier
keyword = ("if" | "else") & name
operator = <op>
op = '+' | "++"
identifier = name - keyword
name = <['A-Za-z' '0-9A-Za-z'*]>
The conventional lexical analyzers such as lex and flex have the longest match policy and priorities among tokens. These policies cannot be modeled with CFG but can be described with CDG as shown in the above example.
Here is a selection of example strings for this grammar:
abcis anidentifier; it is anamebut notkeyword.ifis akeyword; it isnameand it is"if".ifxis anidentifier;ifxis anameand it is not akeywordeven thoughifxstarts withif.++is anoperator; it could have been two+ifoperatorwasop, not<op>.+++is twooperators of++and+.
CDG can describe the languages that cannot be described with CFG. The following example shows the CDG definition for the language
S = (AB 'c'+)&('a'+ BC) {str($0)}
AB = "ab" | 'a' AB 'b'
BC = "bc" | 'b' BC 'c'
You can describe the rules for constructing Abstract Syntax Trees, or ASTs in the CDG definition.
Expr: Expr
= Term WS '+' WS Expr {Add(lhs=$0, rhs=$4)}
| Term
Term: Term
= Factor WS '*' WS Term {Mul(lhs=$0, rhs=$4)}
| Factor
Factor: Factor
= '0-9'+ {Number(value=str($0))}
| '(' WS Expr WS ')' {Paren(body=$2)}
WS = ' '*
If you parse the input string 123 * (456 + 789), you will get Mul(Number(123), Paren(Add(Number(456), Number(789)))).
- An expression between a pair of curly brackets describes the rule for creating an AST node.
-
Add(...),Mul(...),Number(...),Paren(...)are the class initializer. -
$0and$4represents other symbols in the same sequence. The index is 0-based. - The created ASTs will not contain the information of the symbols that are not referred. For example,
Addclass does not have the information about the WS symbols between the operator and operands. -
Expr: Expr,Term: Term,Factor: Factordefines the type of the symbols, that means, Expr symbol is type of the class named Expr, and so on. - JParser's AST generator infers the type relations from the definition as much as possible.
- In the example above,
Exprclass should be the super class ofAddclass andTermclass.Termclass should be the super class ofMulandFactor, and so on.
- In the example above,
- You can generate the Kotlin codes defining the classes for the AST and the code that converts a parse tree to a generated AST class instance.
Here is a selection of CDG examples:
- json: The famous JSON grammar. The grammar of JSON can be described with CFG only.
- asdl: Abstract Syntax Description Language. This is used by Python's ast module.
- proto3: Protocol buffer version 3 schema definition language.
- metalang3: The grammar of CDG.
- bibix: The grammar of the build script of bibix build system.
- hexman: Hexman is a binary format definition language.
- sugarproto: SugarProto is an enhancement for the Protocol Buffer 3 grammar.
- jsontype: jsontype is a language for describing JSON object types.
-
JParser can be built and run using bibix.
-
JParser provides an UI to test grammars. In order to run the UI, run
bibix visualize.parserStudioon the jparser repository directory.- You can see the following screen, if the build was successful:
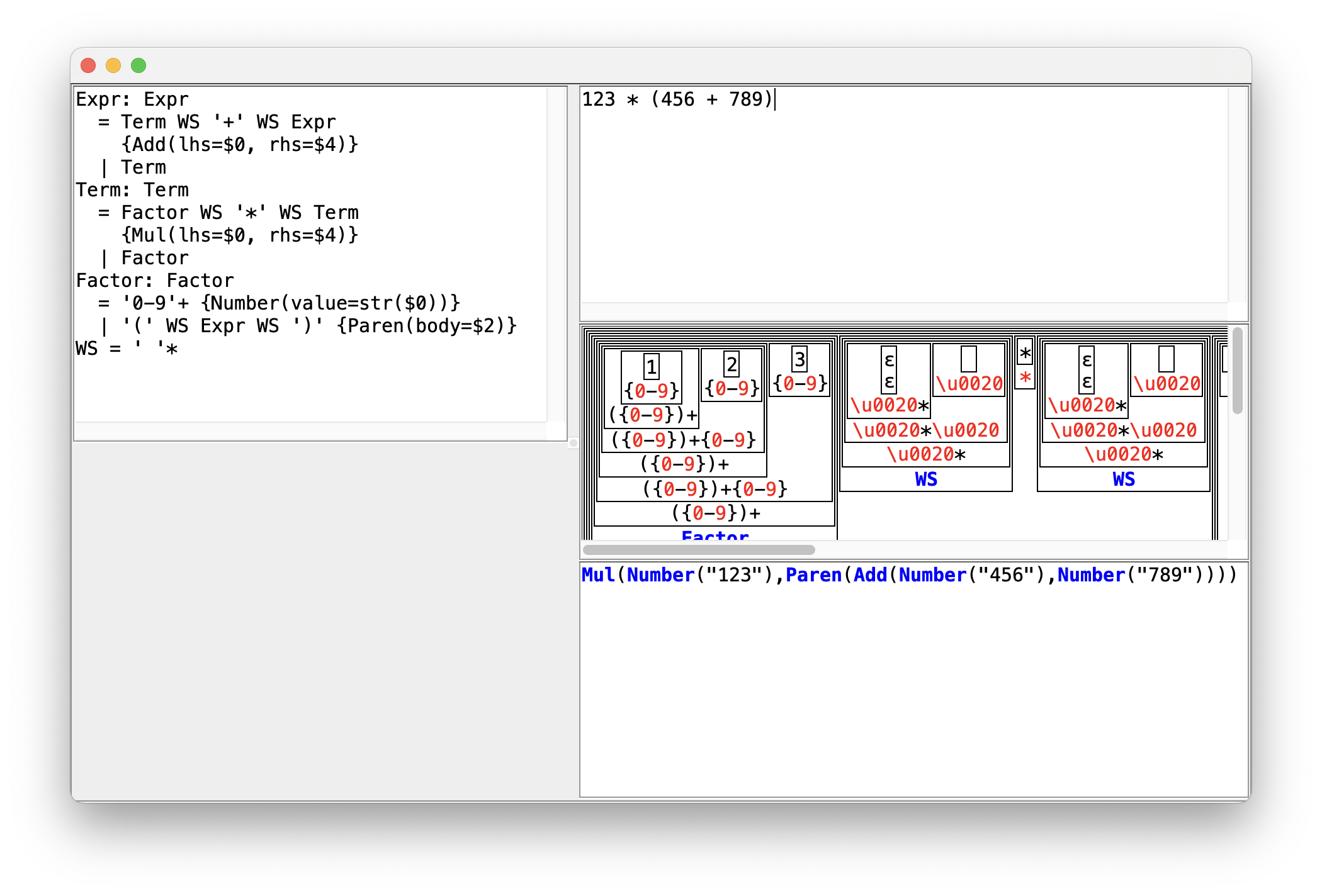
- You can enter your grammar definition to the panel on the left. The text editor on the right top is for the example strings. The parse tree will be shown on the panel below. The panel at the right bottom shows the AST.
-
You can generate the parser code using bibix rule
genKtAstMgroup2. The following shows a typical example of generating the parser using jparser and defining the parser module from the generated code and data.

from bibix.plugins import ktjvm
import git("https://github.com/Joonsoo/jparser.git") as jparser
parserGen = jparser.genKtAstMgroup2(
cdgFile = "grammar/hexman.cdg",
astifierClassName = "com.giyeok.hexman.HexManAst",
parserDataFileName = "hexman-mg2-parserdata.pb",
)
action generate {
file.clearDirectory("parser/generated/resources")
file.clearDirectory("parser/generated/kotlin")
file.copyDirectory(parserGen.srcsRoot, "parser/generated/kotlin")
file.copyFile(parserGen.parserData, "parser/generated/resources")
}
generated = ktjvm.library(
srcs = glob("parser/generated/kotlin/**.kt"),
deps = [jparser.ktparser.main],
resources = ["parser/generated/resources/hexman-mg2-parserdata.pb"]
)
main = ktjvm.library(
srcs = glob("parser/main/kotlin/**.kt"),
deps = [generated]
)
-
I have been writing a series of blog postings about jparser (in Korean).
- This series covers from the introduction to parsing, CDG, naive CDG parsing algorithm, accept condition, parse tree reconstruction algorithm, faster milestone algorithm, even faster milestone group algorithm, AST processors, and so on.
- I am still writing the series, and some of the uploaded postings are uncompleted.
-
You can find the examples of CDG under the examples/metalang3/resources directory.
- I have tried to define the grammars of practical programming languages such as Java, Kotlin, and Dart. I believe it should be possible to define the grammars of those languages in CDG. It was successful to some extent, but I am not actively working on finishing those grammars at the moment.
- JParser is implemented in Scala and Kotlin. I first started writing it in Java, but switched to Scala soon. Later, I started using Kotlin for some of the new modules. But most of the core code of JParser is still in Scala.
- JParser UI was first implemented using SWT and some sub projects of Eclipse including draw2d and zest. But due to the platform dependent nature of SWT, it was too painful to maintain the SWT-related codes. So I rewrote some of the UIs using Swing. The SWT version is still in the repository and they have more functionalities than the new one, but you may need to manually configure the SWT and other libraries in
visualize/libdirectory to run the old UI.