KodCode is the largest fully-synthetic open-source dataset providing verifiable solutions and tests for coding tasks. It contains 12 distinct subsets spanning various domains (from algorithmic to package-specific knowledge) and difficulty levels (from basic coding exercises to interview and competitive programming challenges). KodCode is designed for both supervised fine-tuning (SFT) and RL tuning.
- 🕸️ Project Website - To discover the reasoning for the name of KodCode 🤨
- 📄 Technical Report - Discover the methodology and technical details behind KodCode
- 💾 Github Repo - Access the complete pipeline used to produce KodCode V1
- 🤗 HF Datasets: KodCode-V1 (For RL); KodCode-V1-SFT-R1 (for SFT)
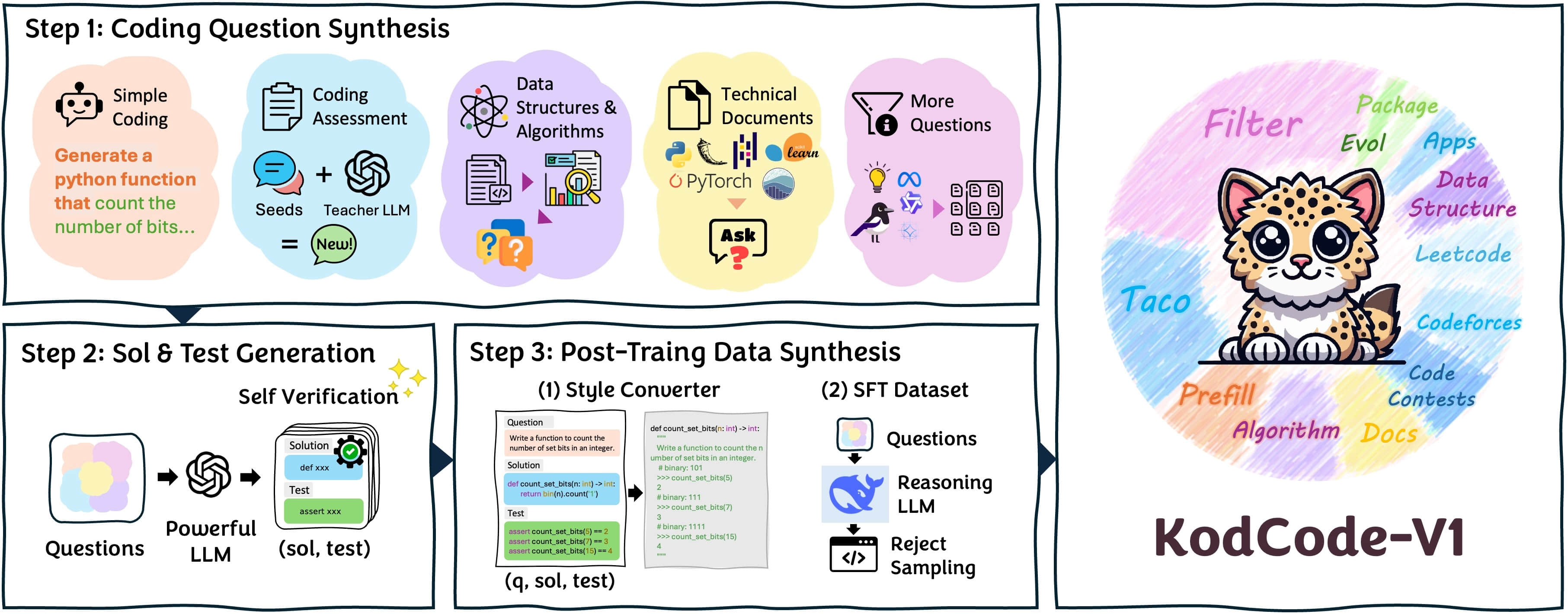
KodCode is a comprehensive pipeline designed to generate diverse, challenging, and verifiable synthetic datasets for coding tasks. Key features include:
- Diverse Sources: Generate high-quality coding questions from multiple sources including zero-shot generation, human-written assessment questions, code snippets, and technical documentation - all unified in a single framework!
- Self-Verification: Generate verifiable solutions and tests for each coding question. Support pytest and parallel execution.
- Style Converter: Easy to convert between different styles of coding questions.
Build environment
Conda Environment:
git clone https://github.com/KodCode-AI/kodcode.git
cd kodcode
conda create -n kodcode python=3.10 -y
conda activate kodcode
pip install -r requirements.txt
To run unit tests in parallel, you also need to install parallel. For example, if you are using Ubuntu, you can install parallel by:
sudo apt-get install parallel
Please refer to the pipeline for more details.
- One-line command to generate KodCode
- Integrate the test pipeline (i.e.,
pytest) into verl - Implement sandbox execution for unit tests
-
KodCode-Smallwith 50K samples -
KodCode-V1.1: Supportstdinformat with ~150K additional samples
License: Please follow CC BY-NC 4.0.
Contact: For questions, suggestions, or feedback, please reach out to Zhangchen Xu, or raise an issue. We welcome your input and are committed to continuously improving KodCode to better serve the community.
If you find the model, data, or code useful, please cite:
@article{xu2025kodcode,
title={KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding},
author={Zhangchen Xu and Yang Liu and Yueqin Yin and Mingyuan Zhou and Radha Poovendran},
year={2025},
eprint={2503.02951},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.02951},
}