📢
pyllamais a hacked version ofLLaMAbased on original Facebook's implementation but more convenient to run in a Single consumer grade GPU.
🔥 In order to download the checkpoints and tokenizer, use this BitTorrent link: "magnet:?xt=urn:btih:ZXXDAUWYLRUXXBHUYEMS6Q5CE5WA3LVA&dn=LLaMA".
In a conda env with pytorch / cuda available, run
pip install pyllama
🐏 If you have installed llama library from other sources, please uninstall the previous llama library and use
pip install pyllama -Uto install the latest version.
Set the environment variables CKPT_DIR as your llamm model folder, for example /llama_data/7B, and TOKENIZER_PATH as your tokenizer's path, such as /llama_data/tokenizer.model.
And then run the following command:
python inference.py --ckpt_dir $CKPT_DIR --tokenizer_path $TOKENIZER_PATHThe following is an example of LLaMA running in a 8GB single GPU.

-
To load KV cache in CPU, run
export KV_CAHCHE_IN_GPU=0in the shell. -
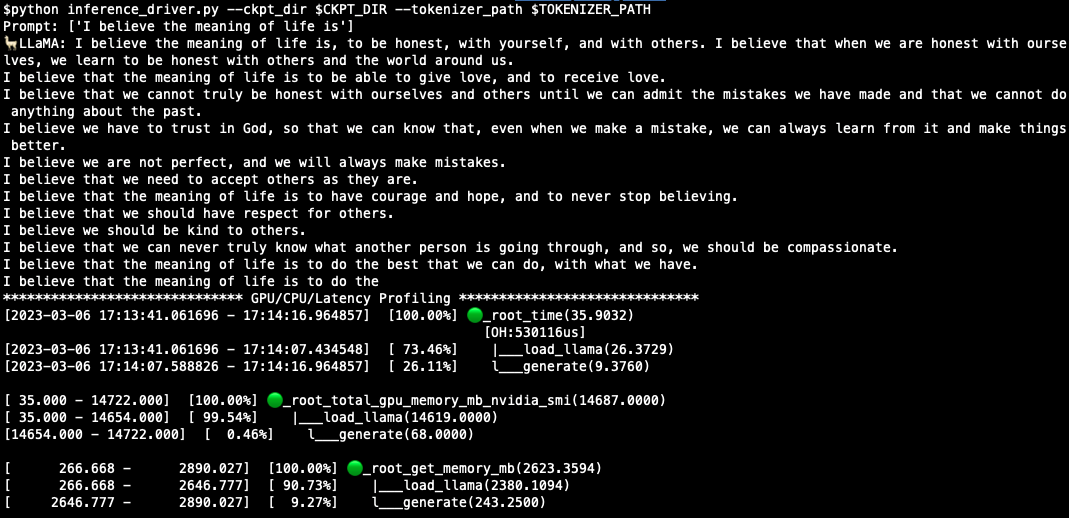
To profile CPU/GPU/Latency, run:
python inference_driver.py --ckpt_dir $CKPT_DIR --tokenizer_path $TOKENIZER_PATHA sample result is like:
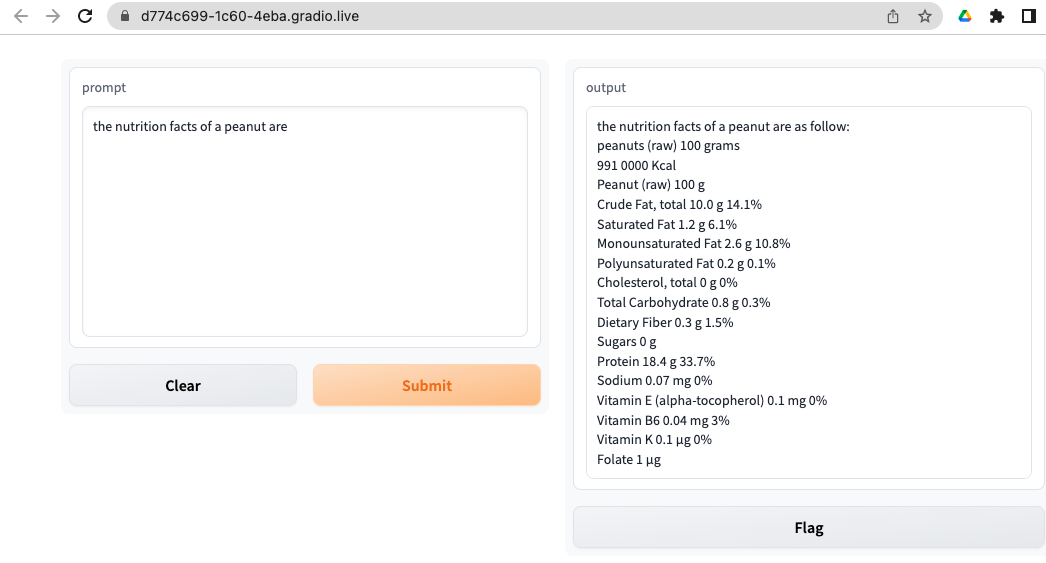
$ cd apps/gradio
$ python webapp_single.py --ckpt_dir $CKPT_DIR --tokenizer_path $TOKENIZER_PATHYou should see something like this in your browser:
The following command will start a flask web server:
$ cd apps/flask
$ python web_server_single.py --ckpt_dir $CKPT_DIR --tokenizer_path $TOKENIZER_PATHThe provided example.py can be run on a single or multi-gpu node with torchrun and will output completions for two pre-defined prompts. Using TARGET_FOLDER as defined in download.sh:
torchrun --nproc_per_node MP example.py --ckpt_dir $TARGET_FOLDER/model_size --tokenizer_path $TARGET_FOLDER/tokenizer.modelDifferent models require different MP values:
| Model | MP |
|---|---|
| 7B | 1 |
| 13B | 2 |
| 30B | 4 |
| 65B | 8 |
In order to download the checkpoints and tokenizer, fill this google form
Once your request is approved, you will receive links to download the tokenizer and model files.
Edit the download.sh script with the signed url provided in the email to download the model weights and tokenizer.
See MODEL_CARD.md
See the LICENSE file.