Zuyan Liu*,1,2
Yuhao Dong*,2,3
Jiahui Wang1
Ziwei Liu3
Winston Hu2
Jiwen Lu1,✉
Yongming Rao2,1,✉
1Tsinghua University 2Tencent Hunyuan Research 3S-Lab, NTU
* Equal Contribution ✉ Corresponding Author
Project Page:
Weights in Huggingface:
arXiv Paper:
Demo by Gradio:
Training Data:
中文解读:
Contact: Leave issue or contact [email protected] . We are on call to respond.
-
🚀[19/2/2025] We release the huggingface demo of Ola, try the advanced omni-modal model on your own!
-
🔥[18/2/2025] The training data, training script for Ola-7b is released!
-
🎉[07/2/2025] The Ola is released! Check our project page, model weights, arXiv paper for the strong omni-modal understanding model!
-
🔥[06/2/2025] Ola-7b achieves Rank #1 on the OpenCompass Multi-modal Leaderboard among all the models under 30B parameters with average score of 72.6. Check the impressive results here!
- Evaluation code on omni-modal benchmarks
- Gradio Demo
- Training Data (Video, Audio, Cross-Modality)
Ola is an Omni-modal language model that achieves competitive performance across image, video, and audio understanding compared to specialized counterparts. Ola pushes the frontiers of the omni-modal language mode with the design of progressive modality alignment strategy, omni-modal architecture, and the well-designed cross-modality training data.

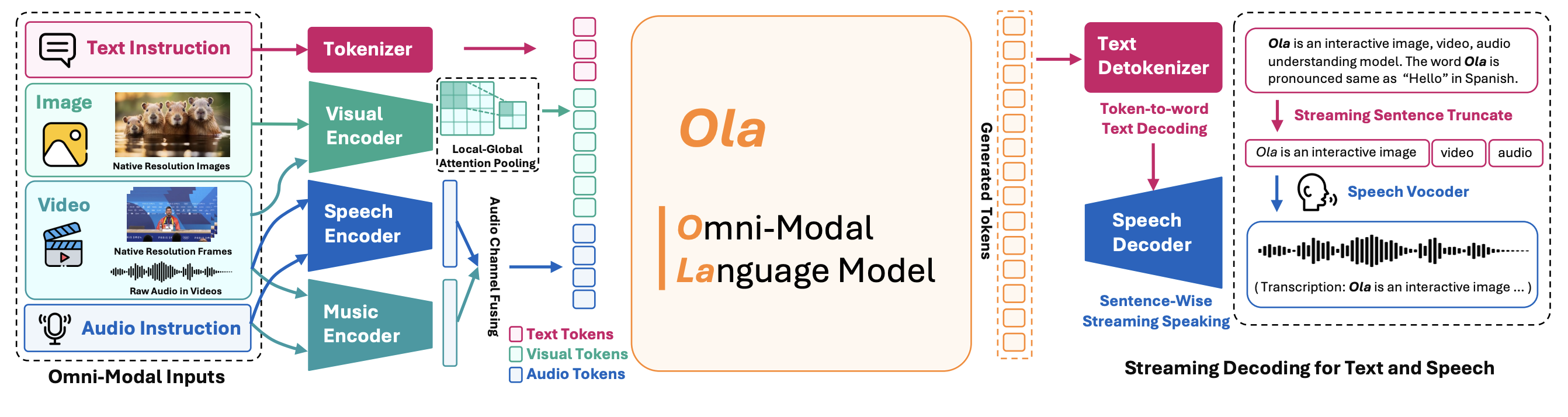
Ola supports omni-modal inputs including text, image, video, and audio, capable of processing the inputs simultaneously with competitive performance on understanding tasks for all these modalities. Meanwhile, Ola supports user-friendly real-time streaming decoding for texts and speeches thanks to the text detokenizer and the speech decoder.
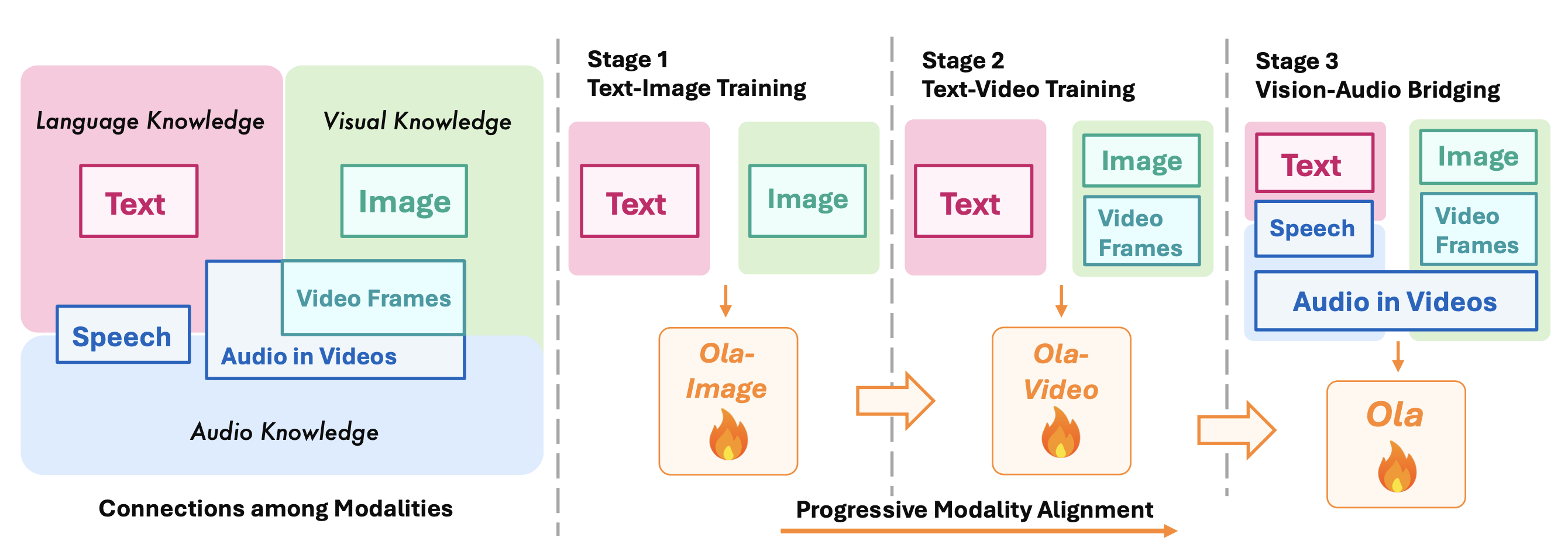
We visualize the relationships among modalities in the left part. Speech acts as the connection between language and audio knowledge, while video constructs the bridge with highly relevant visual and audio information. Therefore, we design the progressive alignment training strategy from primary to periphery. Furthermore, we design the cross-modality video-audio data to better capture the relationships among modalities.
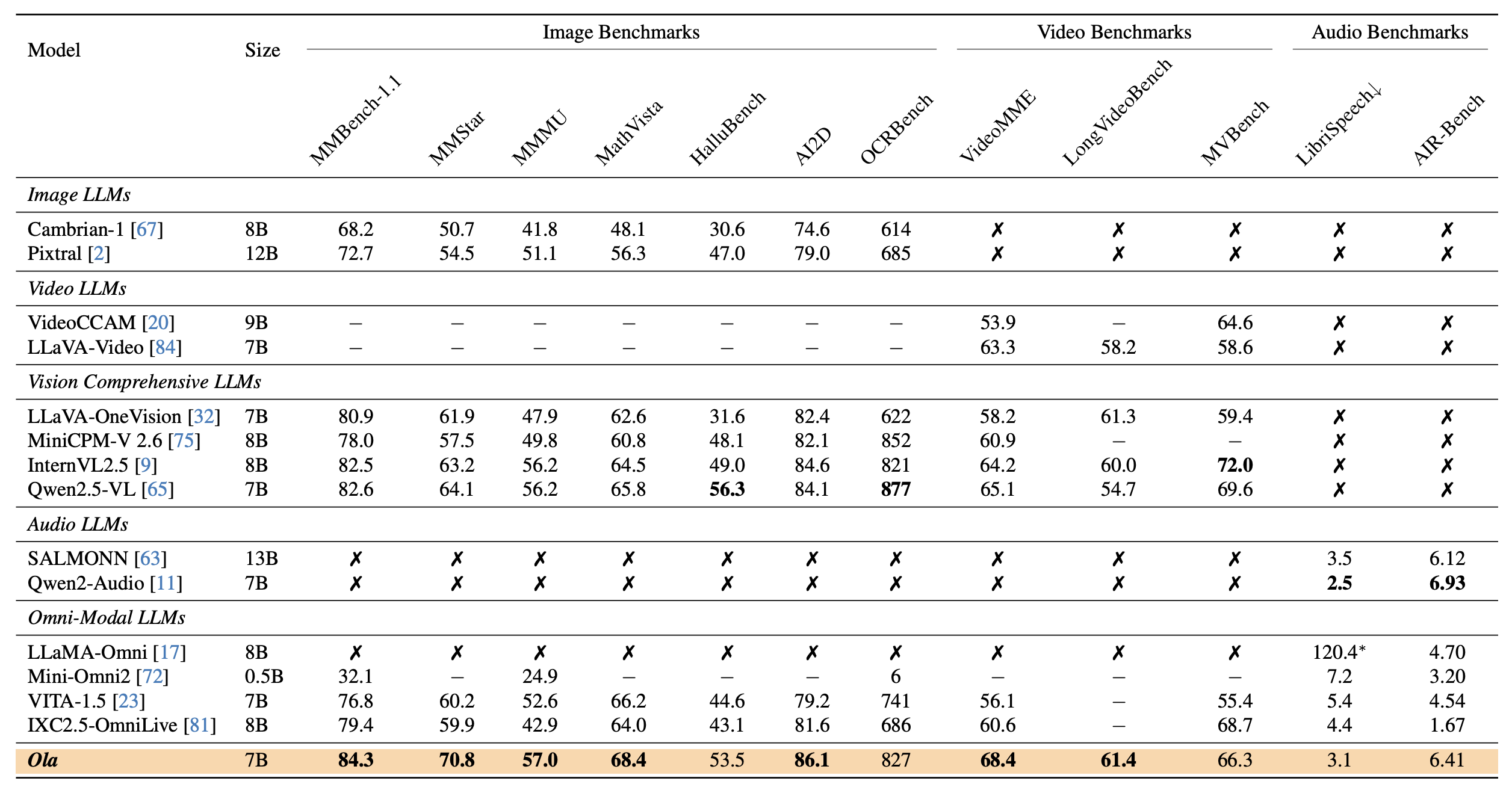
Ola Achieves competitive performance across major multi-modal benchmarks when compared to state-of-the-art specialist-modal LLMs.
git clone https://github.com/Ola-Omni/Ola
cd Olaconda create -n ola python=3.10 -y
conda activate ola
pip install --upgrade pip
pip install -e .pip install -e ".[train]"
pip install flash-attn --no-build-isolation-
Download
Ola-7bfrom Huggingface or skip the step to using the online weights directly. -
Download audio encoder from Huggingface and put the weights
large-v3.ptandBEATs_iter3_plus_AS2M_finetuned_on_AS2M_cpt2.ptunder repo directorypath/to/Ola/pretrained -
Run
inference/infer.py
- Text & Image Understanding
python3 inference/infer.py --image_path *.png,jpg --text user_instruction
- Text & Video Understanding
python3 inference/infer.py --video_path *.mp4 --text user_instruction
- Text & Audio Understanding
python3 inference/infer.py --audio_path *.wav,mp3 --text user_instruction
- Audio & Image Understanding
python3 inference/infer.py --audio_path *.png,jpg --audio_path *.wav,mp3
Coming Soon, Stay tuned!
Please refer to DATA.md for instructions of customized finetuning or using the provided datasets.
Please follow the script below to start training. Make sure you have created the correct datasets for fine-tuning.
bash ./scripts/train_ola.sh
If you find it useful for your research and applications, please cite our paper using this BibTeX:
@article{liu2025ola,
title={Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment},
author={Liu, Zuyan and Dong, Yuhao and Wang, Jiahui and Liu, Ziwei and Hu, Winston and Lu, Jiwen and Rao, Yongming},
journal={arXiv preprint arXiv:2502.04328},
year={2025}
}-
Our codebase is conducted on LLaVA
-
Thanks VLMEvalKit and lmms-eval team for the evaluation system!