Crowd-sourced training data for the development and testing of Rasa NLU models.
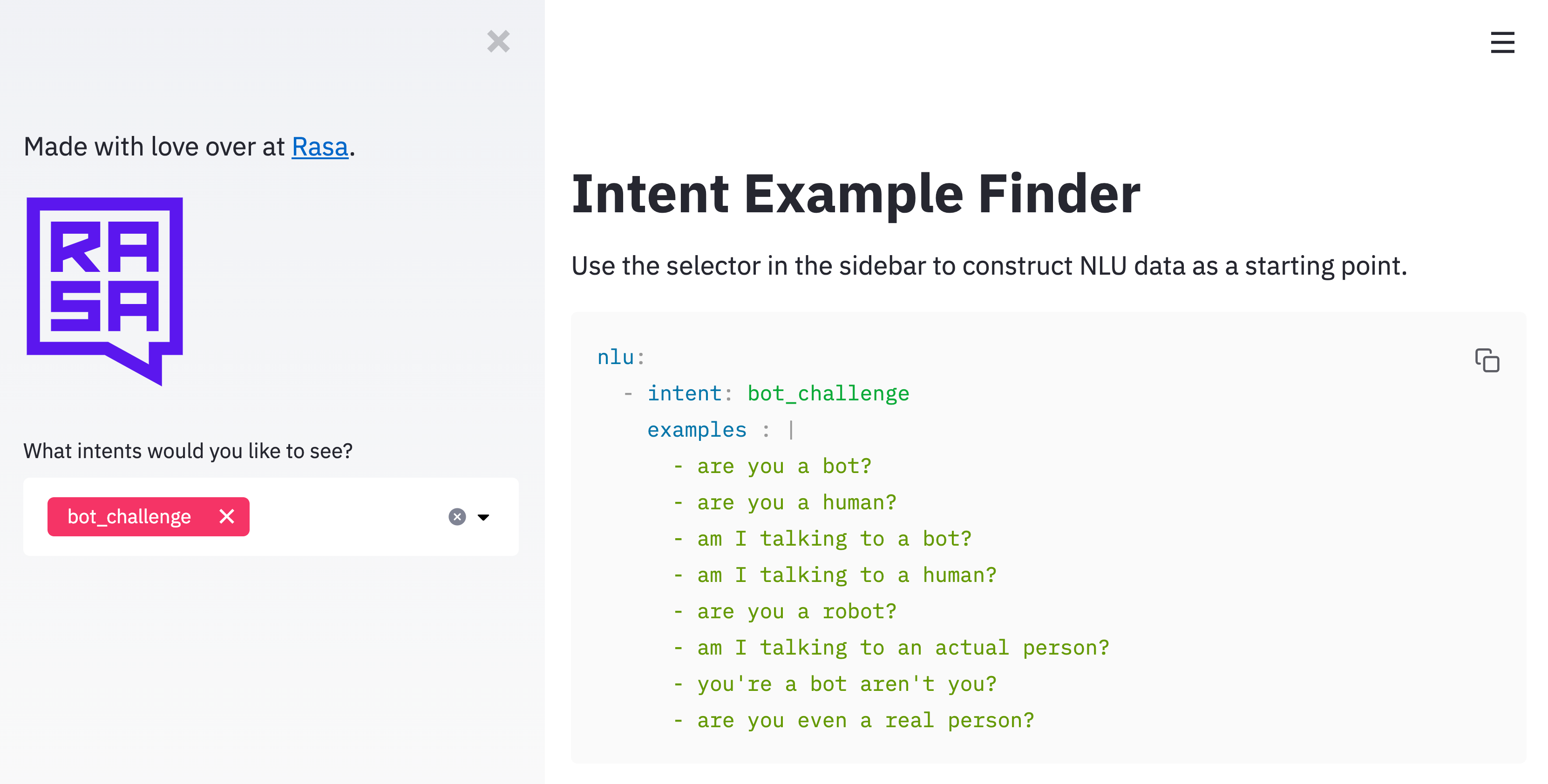
If you're interested in grabbing some data feel free to check out our live data fetching ui.

{kind=link}
This is an experiment with the goal of providing basic training data for developing chatbots, therefore, this repository is open for contributions!
We need your help to create an open source dataset to empower chatbot makers and conversational AI enthusiasts alike, and we very much appreciate your support in expanding the collection of data available to the community.
Each folder should contain a list of multiple intents, consider if the set of training data you're contributing could fit within an existing folder before creating a new one.
-
Create an issue describing the training data you would like to contribute.
-
Create a new file with a folder title and a
NLU.ymlfile, or contribute to an existing folder. -
In the
NLU.ymlfile, format your training data using YAML, remove all entities (see script), title each section with the intent types and add a short description e.g.intent:inform_rain <!--The user says that it is currently raining somewhere.--> -
Update the
README.mdfile, include a list of the intent types added. -
Create a pull request describing your changes.
Your pull request will be reviewed by a maintainer, who will get back to you about any necessary changes or questions. You will also be asked to sign a Contributor License Agreement.
Please always put the domain at the end of each intent. For example: ask_transport
If you would like to contribute multi-intent utterences, please add a + to indicate an additional intent, for example: affirm+ask_transport
Currently, we are unable to evaluate the quality of all language contributions, and therefore, during the initial phase we can only accept English training data to the repository. However, we understand that the Rasa community is a global one, and in the long-term we would like to find a solution for this in collaboration with the community.
We would like to make the training data as easy as possible to adopt to new training models and annotating entities highly dependent on your bot’s purpose. Therefore, we will first focus on collecting training data that only includes intents.
To help you remove the annotated entities from your training data, you can run this script.
-
What does Rasa do? 🤔 Check out our Website
-
I'm new to Rasa 😄 Get Started with Rasa
-
I'd like to read the detailed docs 🤓 Read The Docs
-
I'm ready to install Rasa 🚀 Installation
-
I want to learn how to use Rasa 🚀 Tutorial
-
I have a question ❓ Rasa Community Forum
-
I would like to contribute 🤗 How to Contribute