目前 Zotero 中有许多抓取中文学术网站的插件,这些插件有些已经非常老旧,缺少及时的维护。希望能在这里召集一些志同道合的朋友,共同维护中文学术或其他类型网站的抓取插件。 如果 Github 下载速度慢,可以试试 Gitee
- 知网或知网海外 -> CNKI.js Update: 20200930
- 搜索页面PDF附件下载
- 期刊详细页面的信息收集
- 文章格式都为PDF,学位论文的CAJ链接已经替换为PDF,注意学位论文的PDF应该是没有目录信息的。如何设置拆分姓名,保留CAJ格式
- 修改旧版本将知网导出
refworks中CN字段保存为期刊条目中的call number,修改后CN字段不保留 - 修改了拉取知网
refworks格式引文的网址,新网址提供的摘要字数最多为500字 - 知网海外版PDF和CAJ附件下载支持
- 支持文献类型:期刊,学位论文,会议论文,报纸,修改知网refworks会议论文类型错误的问题
- 已同步到官方版本库中
- 万方数据 -> [WanFang.js](./translators/WanFang Data.js) Update: 20200930
- 抓取引文信息
- 支持文献类型:期刊,学位论文,专利,会议论文
- PDF附件下载
- 维普 -> WeiPu.js ❗
- 抓取引文信息
- 支持文献类型:期刊
- PDF附件下载
- 百度学术 -> Baidu Scholar.js
- 修复抓取图书时错误
- 修复中文作者姓,名问题
- Bilibili 视频网站 -> BiliBili.js Update: 20200703
- 视频页抓取信息,包括Up主,标签,上传日期,视频选集
- 搜索页面信息抓取,包括Up主,上传日期,标题,抓取信息比较少
- 谷粉学术-谷歌学术 -> GFSOSO.js
- 修改了网页匹配,识别抓取代码抄自Google Scholar。从搜索结果页识别搜索结果,引文信息正常
- 部分文献的PDF下载可能会有问题,谷粉搜搜上可能没有相应的下载链接
- 安装Adblock插件的朋友请注意下将谷粉学术
*.glgoo.top添加到白名单,不然可能会出现问题
- 专利搜索网站Soopat -> Snnopat.js
- 搜索页面和单个专利页面信息抓取
- PDF附件下载(需要登录,网站验证码可能会导致PDF下载失败)
- 国家图书馆文津搜索 -> Wenjin.js
- 抓取引文信息
- 支持文献类型:图书,论文
- ProQuest 学位论文全文检索平台 -> ProQuestCN Thesis.js
- 抓取引文信息
- 支持文献类型:学位论文
- PDF附件下载(需要账号或者IP具有下载权限)
1 下载网页翻译器(web translator)文件
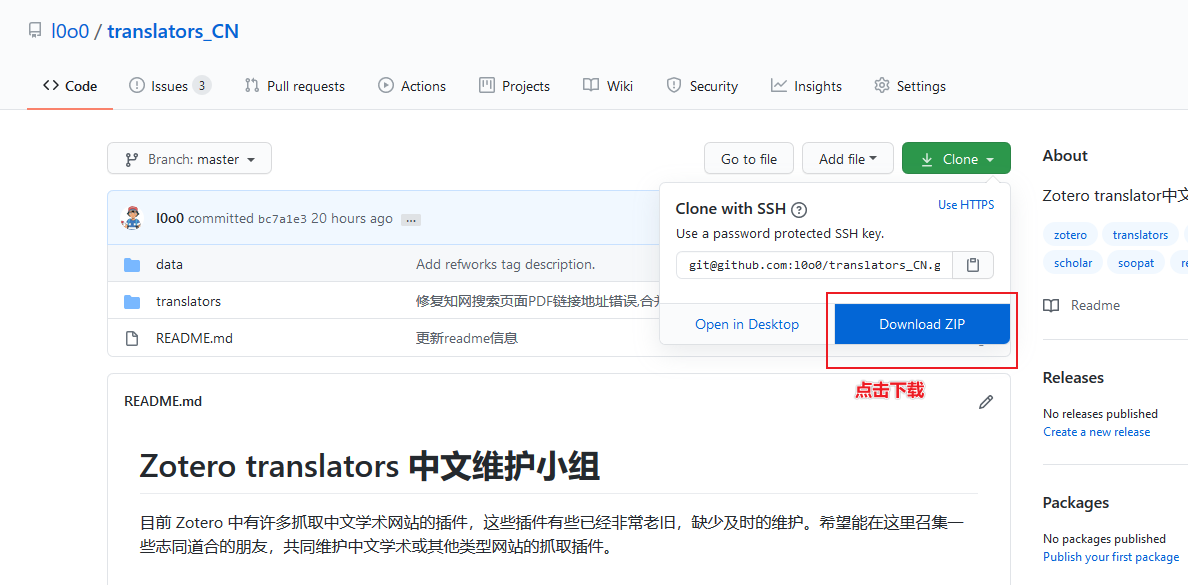
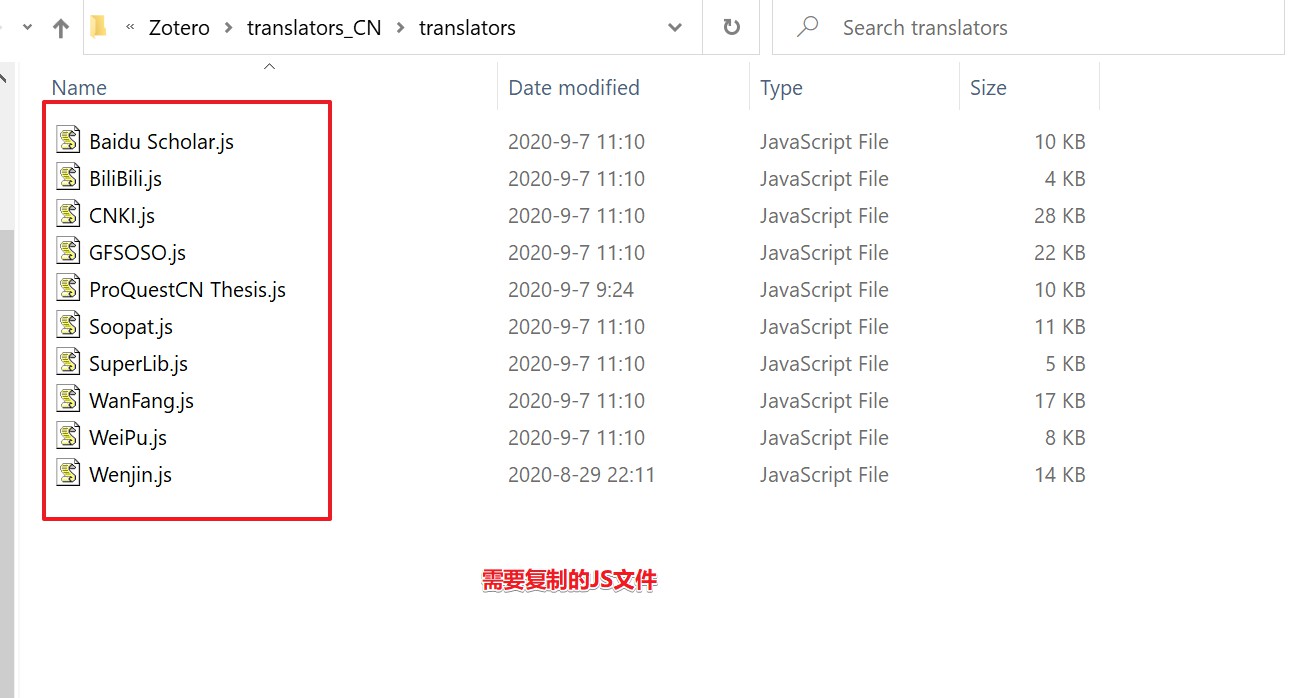
2 解压下载的压缩包,找到translators目录,将目录中的文件复制到 Zotero 的 translators 目录
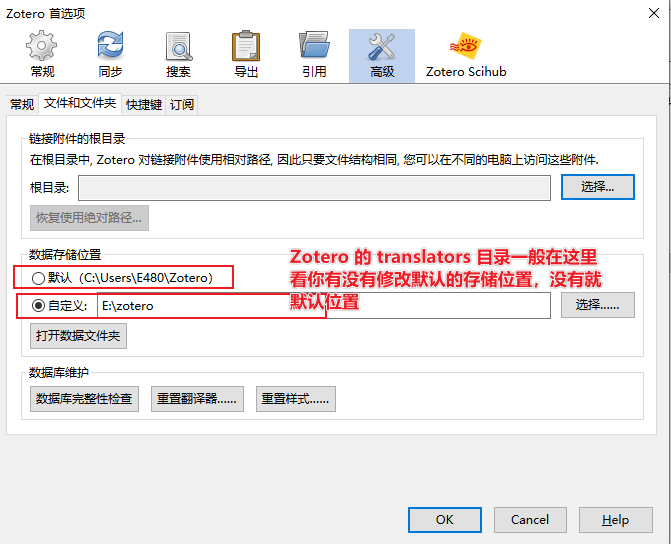
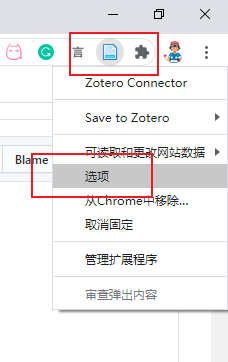
3 更新 translator 信息,Firefox 和 Chrome 浏览器操作类似。下面以 Firefox 为例
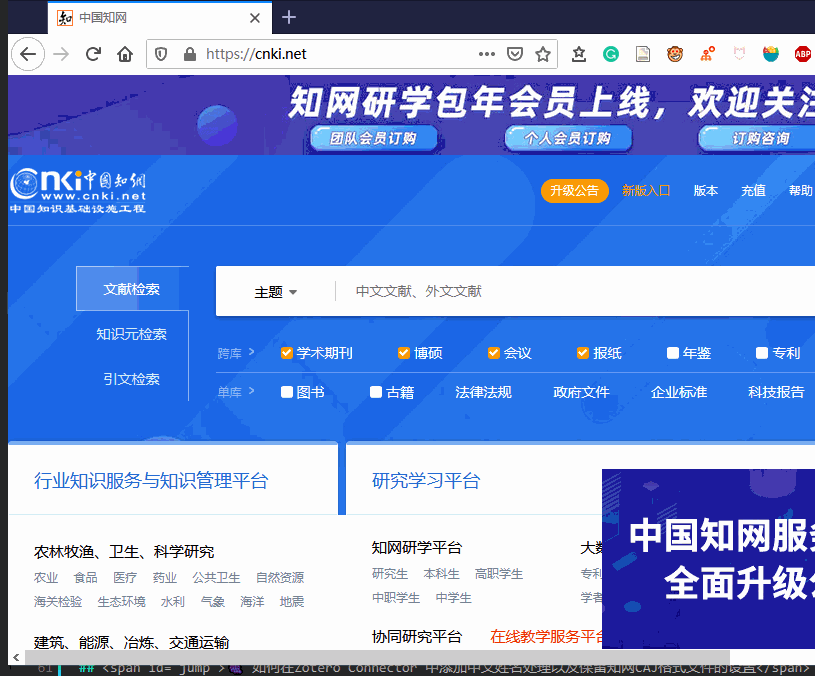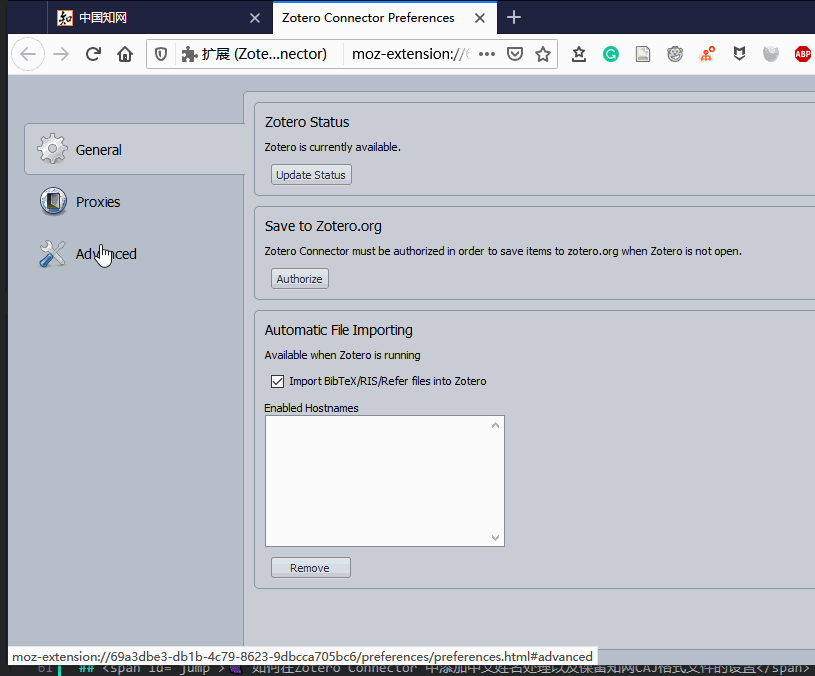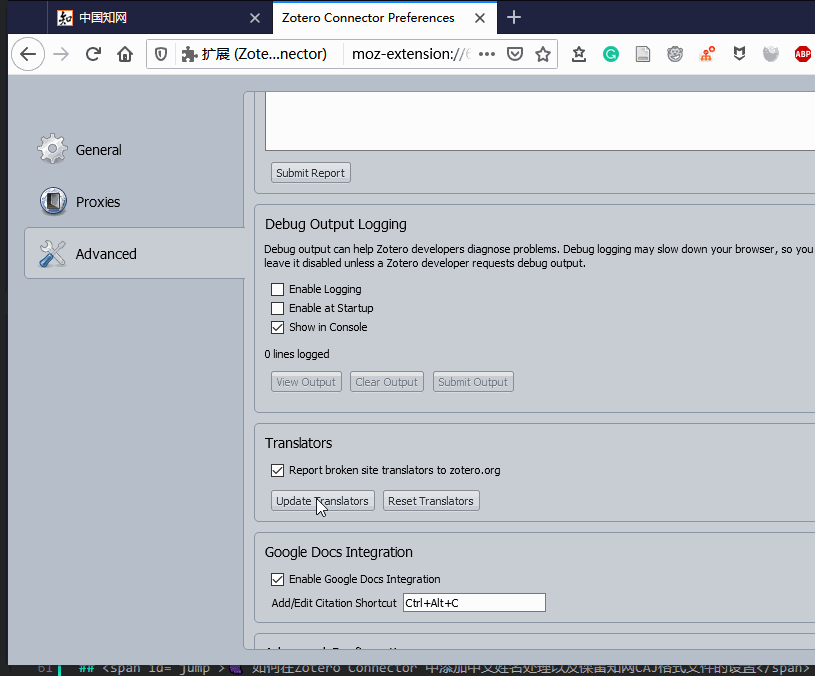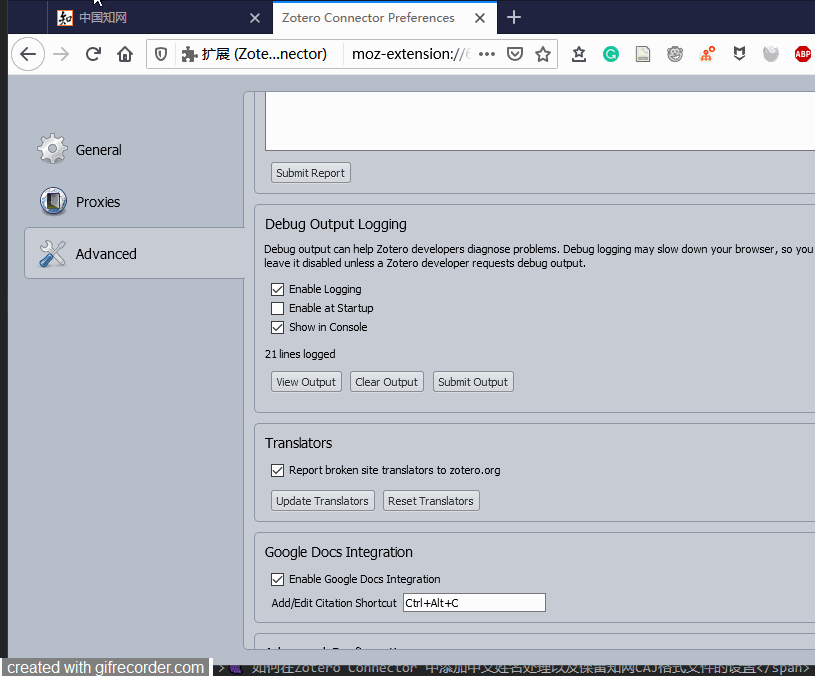
Chrome 浏览器按照下面信息找到更新按钮
更新时请多点几下,根据我的经验,Chrome 浏览器更新比较快,Firefox 会比较慢
如果你使用学校的 VPN 来登录知网,可以参考这个链接进行设置。设置过程不复杂,就是用特殊符号把网址中的字符替换掉。
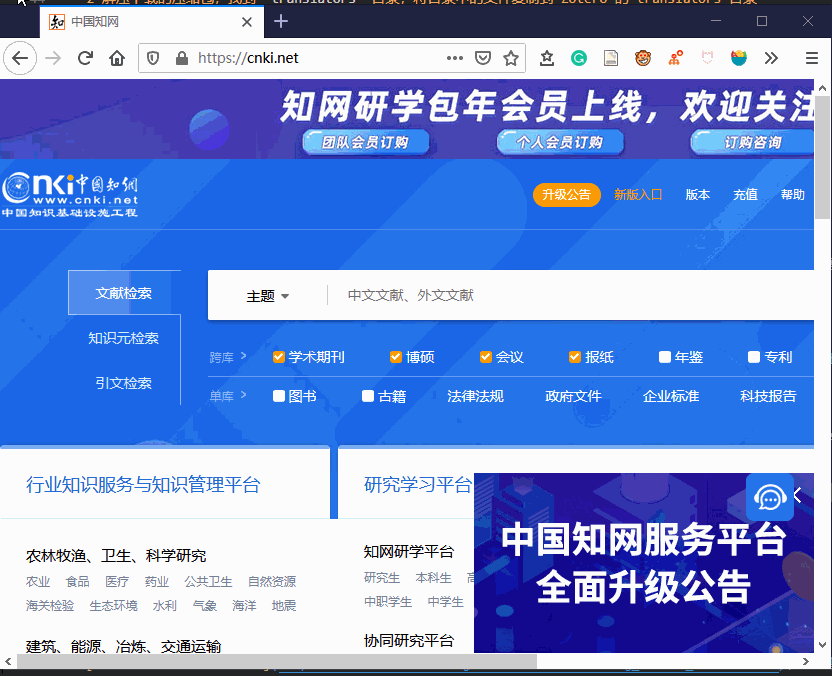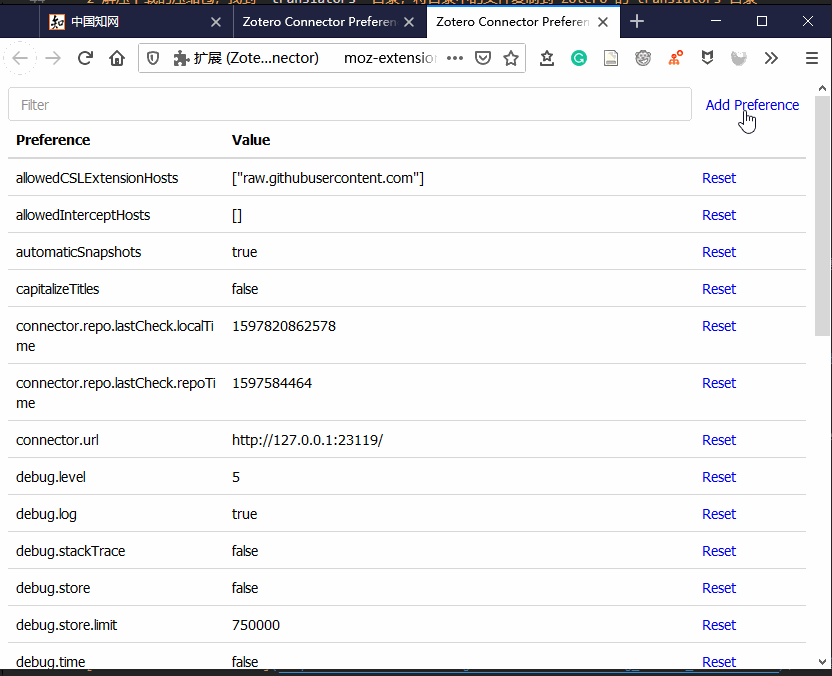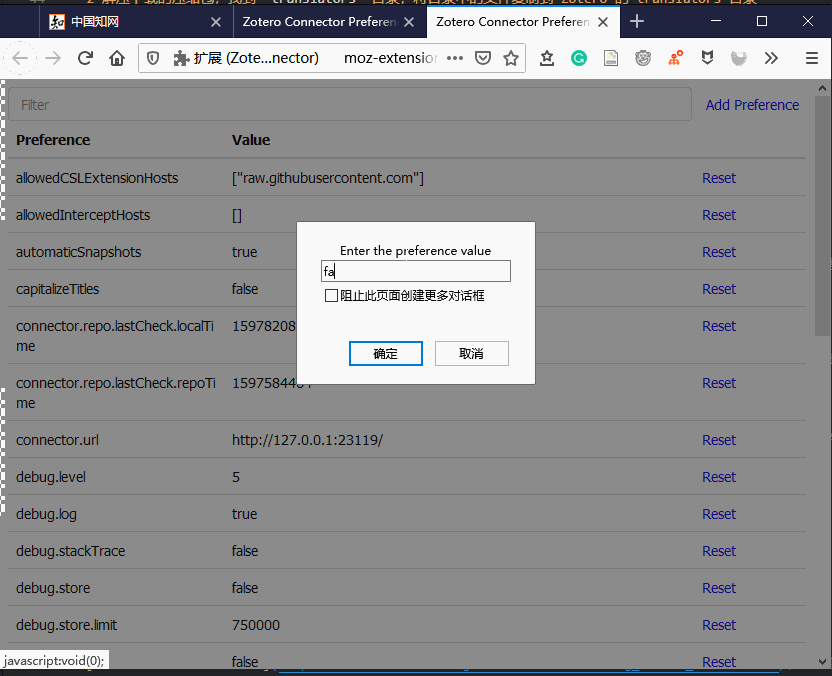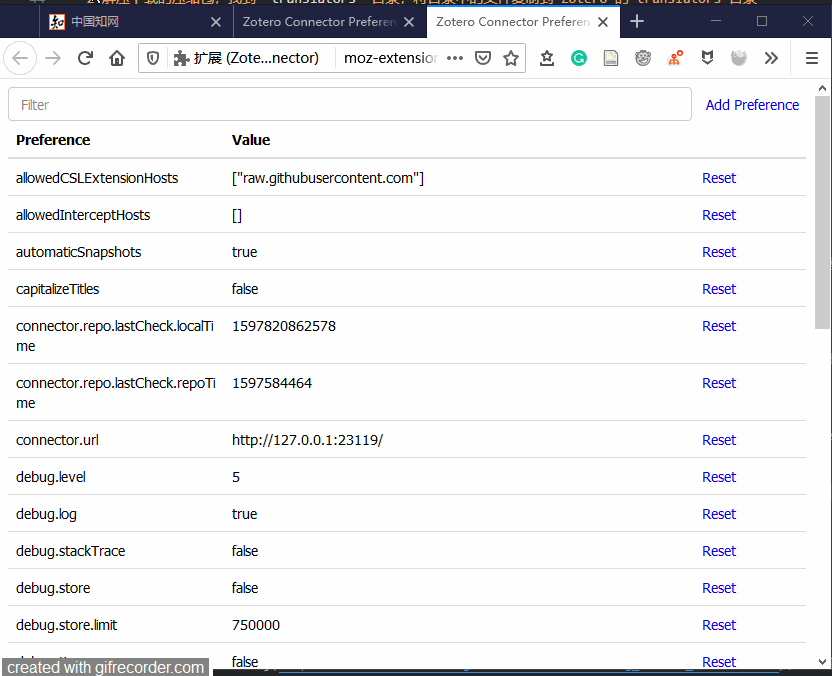
需要特别注意的是,这里在 Zotero Connector 中添加的参数,只是方便控制的网页翻译器的数据抓取行为,限本页面列出的一些翻译器中起作用,并不影响其他翻译器和Zotero的其他功能。 添加的参数有:
translators.zhnamesplit,默认为true,抓取过程会拆分姓和名,如果想全并姓名,请设置为falsetranslators.CNKIPDF,默认为true,下载知网上文章的PDF文件,如果想要下载学位论文的CAJ格式,请设置为false
设置方法请参考下面:
为防止设置错误,可以把参数名复制过去。设置完成后,请刷新网页,再重新抓取。如果你参数名写错了也没事,不会有什么问题,放着就好。
在开始创建前,浏览下面这些材料可以帮你了解一些创建 translator 的基本知识和开发的工具。
- Zotero 文档教你写 translator
- Zotero JavaScript API
- Translator 中可能用到的函数
- Wiki-Create translator,了解基本HTML结构,CSS选择器,javascript基本语法等
- refworks 引文格式,有些学术网站可以将引文导出为 refworks 格式
- Scaffold 使用说明,官方出品,便于创建 translator 的工具
- MDN Javascript 中文教程
- Zotero 条目类型说明
- How to write a Zotero translator
如果有问题的,可以加QQ群 913637964,一起交流。