This repo contains code for Vamba, a hybrid Mamba-Transformer model that leverages cross-attention layers and Mamba-2 blocks for efficient hour-long video understanding.
🌐 Homepage | 📖 arXiv | 💻 GitHub | 🤗 Model
Please use the following commands to install the required packages:
conda env create -f environment.yaml
conda activate vamba
pip install flash-attn --no-build-isolation# git clone https://github.com/TIGER-AI-Lab/Vamba
# cd Vamba
# export PYTHONPATH=.
from tools.vamba_chat import Vamba
model = Vamba(model_path="TIGER-Lab/Vamba-Qwen2-VL-7B", device="cuda")
test_input = [
{
"type": "video",
"content": "assets/magic.mp4",
"metadata": {
"video_num_frames": 128,
"video_sample_type": "middle",
"img_longest_edge": 640,
"img_shortest_edge": 256,
}
},
{
"type": "text",
"content": "<video> Describe the magic trick."
}
]
print(model(test_input))
test_input = [
{
"type": "image",
"content": "assets/old_man.png",
"metadata": {}
},
{
"type": "text",
"content": "<image> Describe this image."
}
]
print(model(test_input))- Modify the data configuration files under
train/data_configs/to point to the correct paths of the datasets. You should refer to CC12M, PixelProse, LLaVA-OneVision-Data and LLaVA-Video-178K for preparing the training datasets. - Follow the commands below to train Vamba model:
# pretraining
bash scripts/pretrain_vamba.sh
# instruction-tuning
bash scripts/sft_vamba.shUse the scripts under eval/ to evaluate Vamba models. For example, to evaluate Video-MME, use the command:
cd Vamba
export PYTHONPATH=.
python eval/eval_videomme.py --model_type vamba --model_name_or_path TIGER-Lab/Vamba-Qwen2-VL-7B --num_frames 512 --data_dir <path_to_videomme_data>
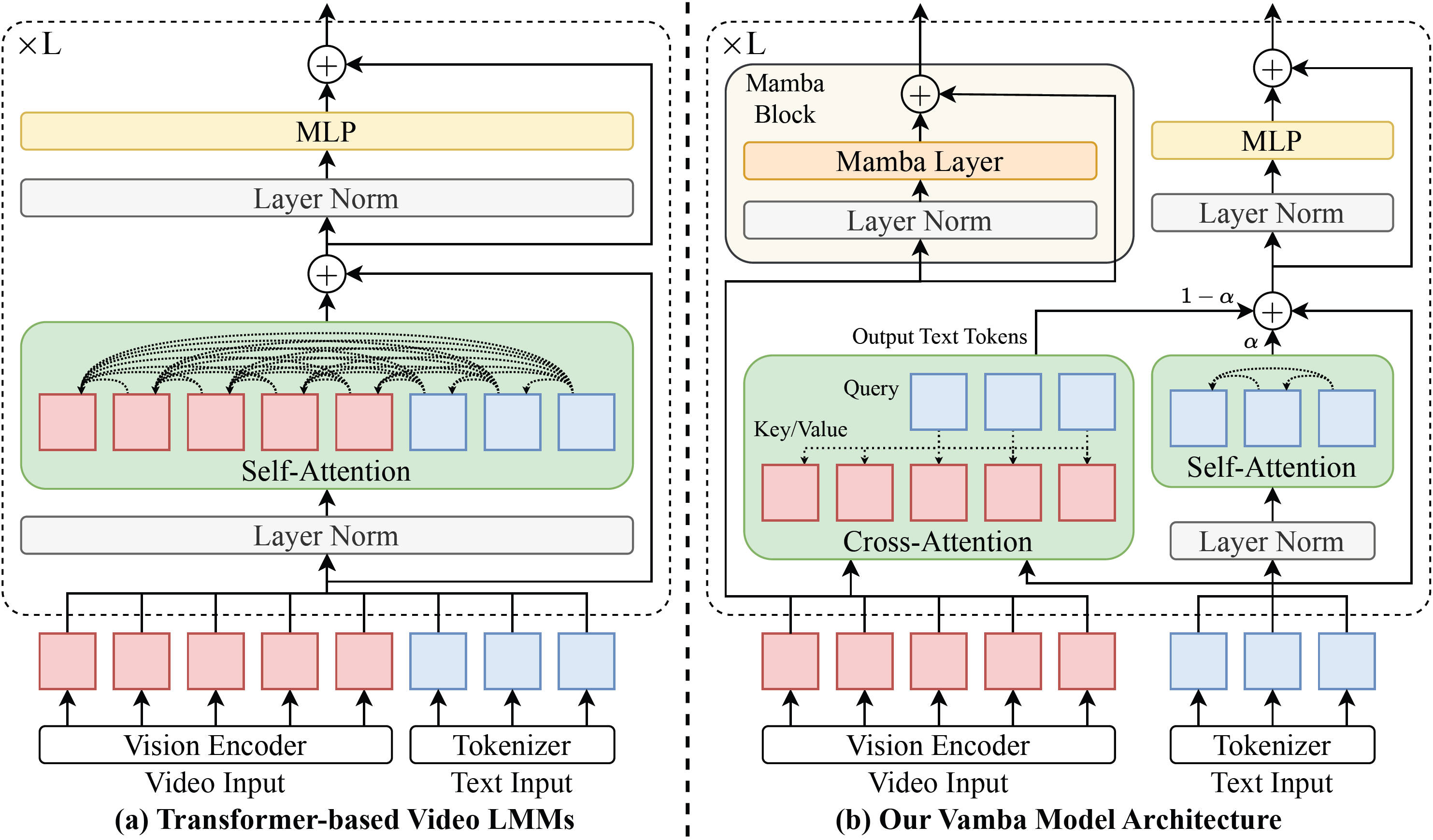
The main computation overhead in the transformer-based LMMs comes from the quadratic complexity of the self-attention in the video tokens. To overcome this issue, we design a hybrid Mamba Transformer architecture to process text and video tokens differently. The key idea of our method is to split the expensive self-attention operation over the entire video and text token sequence into two more efficient components. Since video tokens typically dominate the sequence while text tokens remain few, we maintain the self-attention mechanism exclusively for the text tokens and eliminate it for the video tokens. Instead, we add cross-attention layers that use text tokens as queries and video tokens as keys and values. In the meantime, we propose employing Mamba blocks to effectively process the video tokens.
If you find our paper useful, please cite us with
@misc{ren2025vambaunderstandinghourlongvideos,
title={Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers},
author={Weiming Ren and Wentao Ma and Huan Yang and Cong Wei and Ge Zhang and Wenhu Chen},
year={2025},
eprint={2503.11579},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.11579},
}