Wei Ye†1 Jindong Wang2 Xing Xie2 Yue Zhang3 Shikun Zhang1
1 Peking University, 2 Microsoft Research, 3 Westlake University.
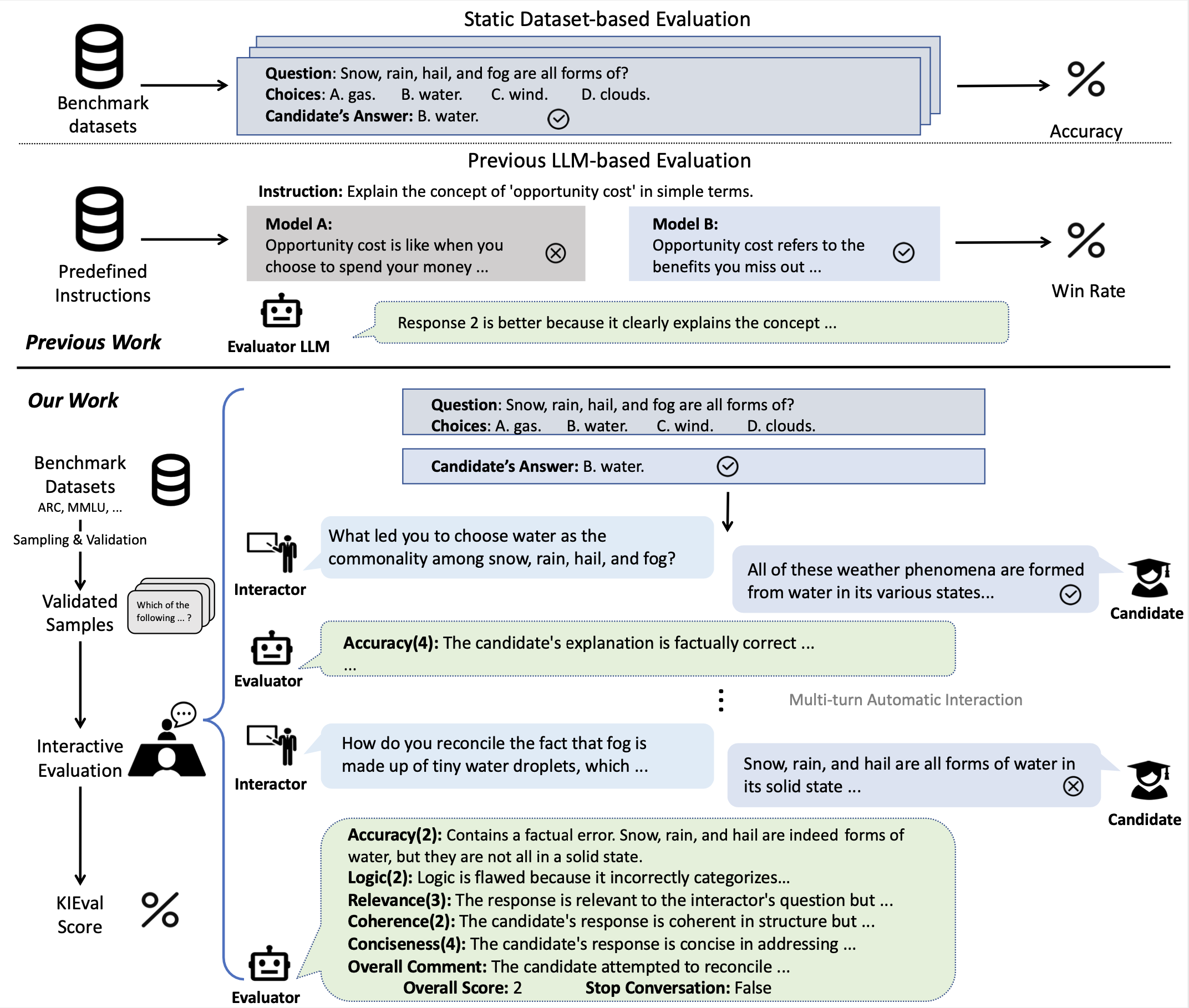
This is the official repository for KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models.
Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered "interactor" role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.
To get started, first clone the repository and setup the enviroment:
git clone https://github.com/zhuohaoyu/KIEval.git
cd KIEval
pip install -r requirements.txtWe provide a modular implementation of our method, currently we support evaluating models locally with Huggingface's Transformers, and remote models with text-generation-inference or other APIs.
To reproduce KIEval results, we recommend starting a text-generation-inference instance with your model:
model=meta-llama/Llama-2-7b-chat-hf
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $modelThen, generate an evaluation config file with our script:
python scripts/generate-basic.py \
--template ./config/template-basic.json \
--dataset arc_challenge \
--base_url http://your-host-url:8080 \
--model_name llama-2-7b-chat-hf \
--model_path meta-llama/Llama-2-7b-chat-hf \
--openai_api_base https://api.openai.com/v1/ \
--openai_key your_openai_key \
--openai_model gpt-4-1106-preview \
--output_path ./result \
--generate_path ./config/generated.jsonFinally, run the evaluation process:
python run.py -c ./config/generated.jsonThis repository provides all settings necessary for researchers to reproduce the results of KIEval, it also facilitates the reproduction of all metrics (from previous works) discussed in our paper. Please refer to config/templates for all supported evaluation methods.
@misc{yu2024kieval,
title={KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models},
author={Zhuohao Yu and Chang Gao and Wenjin Yao and Yidong Wang and Wei Ye and Jindong Wang and Xing Xie and Yue Zhang and Shikun Zhang},
year={2024},
eprint={2402.15043},
archivePrefix={arXiv},
primaryClass={cs.CL}
}