1、openmv是一种硬件模块,opencv则是视觉库。
2、OpenCV主要操作对象是图像。而 OpenMV的主要操作对象是模块,其可以通过UART,I2C,SPI,AsyncSerial以及GPIO等控制其他的硬件。
OpenMV是一个开源,低成本,功能强大的机器视觉模块。以STM32F427CPU为核心,集成了OV7725摄像头芯片,在小巧的硬件模块上,用C语言高效地实现了核心机器视觉算法,提供Python编程接口。
OpenCV是一个基于BSD许可发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。动静分离是将网站静态资源(HTML,JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问。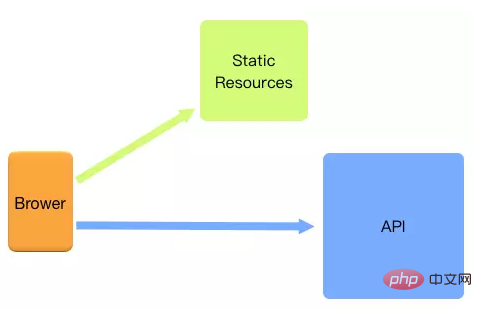
动静分离的一种做法是将静态资源部署在nginx上,后台项目部署到应用服务器上,根据一定规则静态资源的请求全部请求nginx服务器,达到动静分离的目标。-
nginx动静分离的好处
api接口服务化:动静分离之后,后端应用更为服务化,只需要通过提供api接口即可,可以为多个功能模块甚至是多个平台的功能使用,可以有效的节省后端人力,更便于功能维护。 前后端开发并行:前后端只需要关心接口协议即可,各自的开发相互不干扰,并行开发,并行自测,可以有效的提高开发时间,也可以有些的减少联调时间 减轻后端服务器压力,提高静态资源访问速度:后端不用再将模板渲染为html返回给用户端,且静态服务器可以采用更为专业的技术提高静态资源的访问速度。 -
反向代理是什么?
反向代理其实就类似你去找代购帮你买东西(浏览器或其他终端向nginx请求),你不用管他去哪里买,只要他帮你买到你想要的东西就行(浏览器或其他终端最终拿到了他想要的内容,但是具体从哪儿拿到的这个过程它并不知道)。 -
反向代理的作用
- 保障应用服务器的安全(增加一层代理,可以屏蔽危险攻击,更方便的控制权限) - 实现负载均衡(稍等~下面会讲) - 实现跨域(号称是最简单的跨域方式)
nginx 就是充当图中的 proxy。左边的3个 client 在请求时向 nginx 获取内容,是感受不到3台 server 存在的。
-
随着业务的不断增长和用户的不断增多,一台服务已经满足不了系统要求了。这个时候就出现了服务器 集群。
在服务器集群中,Nginx 可以将接收到的客户端请求“均匀地”(严格讲并不一定均匀,可以通过设置权重)分配到这个集群中所有的服务器上。这个就叫做负载均衡。
-
负载均衡的示意图如下:
-
- 分摊服务器集群压力
- 保证客户端访问的稳定性
前面也提到了,负载均衡可以解决分摊服务器集群压力的问题。除此之外,Nginx还带有健康检查(服务器心跳检查)功能,会定期轮询向集群里的所有服务器发送健康检查请求,来检查集群中是否有服务器处于异常状态。 一旦发现某台服务器异常,那么在这以后代理进来的客户端请求都不会被发送到该服务器上(直健康检查发现该服务器已恢复正常),从而保证客户端访问的稳定性。
-
正向代理跟反向道理正好相反。拿上文中的那个代购例子来讲,多个人找代购购买同一个商品,代购找到买这个的店后一次性给买了。这个过程中,该店主是不知道代购是帮别代买买东西的。那么代购对于多个想买商品的顾客来讲,他就充当了正向代理。
-
正向代理的示意图如下:
nginx 就是充当图中的 proxy。左边的3个 client 在请求时向 nginx 获取内容,server 是感受不到3台 client 存在的。
正向代理,意思是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。当你需要把你的服务器作为代理服务器的时候,可以用Nginx来实现正向代理。
科学上网vpn(俗称翻墙)其实就是一个正向代理工具。
该 vpn 会将想访问墙外服务器 server 的网页请求,代理到一个可以访问该网站的代理服务器 proxy 上。这个 proxy 把墙外服务器 server 上获取的网页内容,再转发给客户。
代理服务器 proxy 就是 Nginx 搭建的。
正向代理应用远没有反向代理广泛,frp就是一个反向代理软件,它体积轻量但功能很强大,可以使处于内网或防火墙后的设备对外界提供服务。- 内存比CPU重要
永远不会错的答案是:分用途和场景。然而根据本人多年的测试和实践,得出的答案是:**绝大部分情况下内存比较重要,尽量购买内存大/内存主频高的VPS**。
得出这样一个结论,有以下依据支持:
1. 本人之前跑科学计算程序,同样的编译参数,**2.2G CPU、1600MHz DDR3内存**的Mac笔记本竟然比**3.5G CPU、1333MHz DDR3内存**的服务器运行更快。该程序不涉及到硬盘读写,只用到CPU和内存,(大概率)说明快的内存可能比高主频的CPU更重要(程序为memory-bounded型);
2. 本人见过很多个人或小企业建网站,上来就买4核8G的服务器。然而大半年过去了,网站的日ip仅有寥寥几十不到百,白白浪费钱;本人也见过1核1G内存搭配swap的VPS,[配置好缓存后](https://ssrvps.org/archives/1088),稳稳承载日ip上万的网站;查看系统状态,除了内存紧张,cpu大多时间都比较空闲;
3. cpu性能不够,最多只是慢;内存(加swap)不够,那可是会让服务崩盘的。内存不够时,OOM killer大概率就先把数据库、Redis等重要服务杀死,然后服务就GG了。前几天很火的新闻:[Redis 官网昨日宕机,错误提示为无法连接 Redis](https://www.cnbeta.com/articles/tech/954817.htm),就说明内存有多重要;
4. 即使是很多密集计算型的场合,内存过小也会严重限制cpu发挥,从而影响整体性能。
总结起来就是:绝大部分场景,内存才是限制系统性能的主要因素,而cpu一般都是性能过剩。
因此,用来托管网站、后台程序的VPS,个人推荐cpu内存比至少是1:1,即1核1G,2核2G等;1:2是比较合适的,即1核2G,特殊情况可以考虑1:4或者1:8的VPS。
- CPU比内存更重要的场景
也有一些场景,CPU比内存更重要,需要配置性能强劲的CPU。本人能想到的场景有:
1. API网关、防火墙、路由器等流量入口的服务器,要对流量做密集计算、校验、转发,CPU不强那肯定是不行的;
2. 只用做流量转发、网络代理的服务器,其实和前一条类似,CPU必须要强,内存够用就行,至于硬盘,基本上用不到;
3. 密码爆破、挖坑等算力比拼的场景,CPU不给力那就没得玩了。
如果你出于这些需求买服务器,优先考虑CPU吧。例如很多 [NAT VPS](https://ssrvps.org/archives/1132),2核cpu配258m/384m内存,但做中转已经完全够用了。
- 总结
分场景买合适配置的VPS,这句话总是不会错。除了上面说的,还有不少特殊场景要单独考虑。例如对于下载服务器,[大带宽VPS](https://netfiles.pw/large-bandwith-traffic-vps-summary/) 就比内存和CPU更重要;而存储型服务器,硬盘容量就应该优先考虑。
至于本人,买VPS一般是做网站、应用程序后端等用途,考虑因素如下:内存大小、硬盘速度、带宽/流量,最后才是CPU。大内存的VPS,可以做搭建网站、[内网穿透](https://ssrvps.org/archives/2437)、[Gitlab托管](https://ssrvps.org/archives/4659) 等多种用途,同时花费更低。
- Git
Git 是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。Git 是为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。注:git相当于一个版本管理工具,用于管理你本地文件的版本,传统的版本控制都是新建一个文件夹,而git可以不联网(优点)将你的每次迭代版本放在一个类似于服务端的地方,如果你需要哪个版本则直接用git的指令获取,从而达到版本控制。
分布式说明:
每个中心都有所有版本,先提交到自己的本地(相当于备份)再提交到中心。
与分布式相反的是集中式:
所有版本都在服务器中心,不用提交至自己的本地,也就是本地没有所有的版本- GitHub
GitHub是一个面向开源及私有软件项目的托管平台,因为只支持git作为唯一的版本库格式进行托管,故名GitHub。可以说是一个”仓库“,可以用来存放你的源程序和你的所有版本,需要联网操作。github类似于一个百度云,或者阿里云之类的云服务器,用户可以将其文件存放在其中,但是其又可以像一个交流网站,将你分享的内容共享(开源)。其就是一个“托管所”,将你的代码放在上面就不用管,而且其可以实现版本控制,也就是说你可以提交一个文件夹多次,保留你提交的所有记录,你需要那个版本就直接下载哪个版本。
- GitLab
GitLab 是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的web服务。- Git、GitHub与GitLab的区别
- Git是一种版本控制系统,是一种工具,用于代码的存储和版本控制。
- GitHub是一个基于Git实现的在线代码仓库,是目前全球最大的代码托管平台,可以帮助程序员之间互相交流和学习。
- GitLab是一个基于Git实现的在线代码仓库软件,你可以用GitLab自己搭建一个类似于GitHub一样的仓库,但是GitLab有完善的管理界面和权限控制,一般用于在企业、学校等内部网络搭建Git私服。
- GitHub和GiLlab两个都是基于Web的Git远程仓库,它们都提供了分享开源项目的平台,为开发团队提供了存储、分享、发布和合作开发项目的中心化云存储的场所。从代码的私有性上来看,GitLab 是一个更好的选择。但是对于开源项目而言,GitHub 依然是代码托管的首选。
1.git无需联网,github需要联网
2.git是一个本地管理工具,而github是一个网站,可以用来存放源码,且开源。- 选择使用GitHub还是GitLab?
如果只单纯在这两个网站创建账号并创建项目,最大的区别是:github选择新建项目为私人时需要收费!而gitlab选择新建项目为私人时不需要收费!
目前,github只支持搭建本地服务器的个人github,只能供个人使用。 而gitlab提供开源代码,支持企业自己用企业买的服务器搭建企业gitlab,供公司所有人使用。
虽然两个公司都提供了私人仓库的功能供个人和企业用户使用,即使两个公司的数据库很安全,但是很多公司是采用内网进行办公和传输数据, 如果通过内网和外网这两个公司服务器进行代码和相关敏感数据的传输,传输途中容易被不法分子获取到数据,从而造成数据泄露。 因为很多公司都格外重视自己的代码成果,所以目前主流都是公司用自己买的服务器去搭建公司内部使用的gitlab,且gitlab支持一些插件写入自己的服务器脚本,从而可以设置公司每位成员的文件使用权限(具体是哪种插件忘了,之前有百度到但忘保存链接了),从而确保公司项目代码的最大程度的保密和安全!!
- 如果个人写的代码是不重要的,可以让所有人看看,选择开源,选哪一个都没差别;
- 如果个人写的代码比较有点水平,不想让别人看到,就使用gitlab。最主要原因gitlab免费支持私人仓库,而github需收费;
- 如果个人写的代码很厉害,有商业价值,不想让别人看到,又怕代码数据泄露,就务必得选择gitlab,因为gitlab可以搭建公司/个人的服务器,存储数据安全;
- 如果是公司团队开发的代码,务必只能选择gitlab,搭建公司个人的gitlab服务,才能确保数据安全。
综合以上四点:可以弃用github,直接使用gitlab即可!其他:https://blog.csdn.net/hellocsz/article/details/89785617
- 什么是Cookie?
我们知道HTTP协议是无状态的,一次请求完成,不会持久化请求与相应的信息。那么,在购物车、用户登录状态、页面个性化设置等场景下,就无法识别特定用户的信息。这时Cookie就出现了。
Cookie是客户端保存用户信息的一种机制,将服务器发送到浏览器的数据保存在本地,下次向同一服务器再发起请求时被携带发送。对于Cookie,可以设置过期时间。
通常,Cookie用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。这样就解决了HTTP无状态的问题。
Cookie主要用于以下方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
Cookie存储在客户端,这就意味着,可以通过一些方式进行修改,欺骗服务器。针对这个问题,怎么解决呢?那就引入了Session。-
- 判断注册用户是否已经登录网站:用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录流程。
- 根据用户的爱好定制内容:网站创建包含用户浏览内容的cookies,在用户下次访问时,网站根据用户的情况对显示的内容进行调整,将用户感兴趣的内容放在前列。
- 实现永久登录:如果用户是在自己家的电脑上上网,登录时就可以记住他的登录信息,下次访问时不需要再次登录,直接访问即可。
- 实现自动登录:当用户注册网站后,就会收到一个惟一用户ID的cookie。用户再次连接时,这个用户ID会自动返回,服务器对它进行检查,确定它是否是注册用户且选择了自动登录,从而使用户无需给出明确的用户名和密码,就可以访问服务器上的资源。
- 使用cookie记录各个用户的访问计数:获取cookie数组中专门用于统计用户访问次数的cookie的值,将值加1并将最新cookie输出。
- 使用cookie记住用户名与用户密码。用户勾选了“自动登录”,就把用户名和密码的信息放到cookie中。同时可设置有效期。
- 用cookie实现新手大礼包等弹窗功能。同理,将新手大礼包弹窗逻辑写入到cookie中,并设置相应的有效期。比如在有效期内只弹出一次该弹窗,超过有效期登录后再次弹出弹窗。
-
什么是Session?
Session代表服务器和客户端一次会话的过程。
维基百科这样解释道:在计算机科学领域来说,尤其是在网络领域,会话(session)是一种持久网络协议,在用户(或用户代理)端和服务器端之间创建关联,从而起到交换数据包的作用机制,session在网络协议(例如telnet或FTP)中是非常重要的部分。
对照Cookie,Session是一种在服务器端保存数据的机制,用来跟踪用户状态的数据结构,可以保存在文件、数据库或者集群中。
当在应用程序的Web页之间跳转时,存储在Session对象中的变量将不会丢失,而会在整个用户会话中一直存在下去。当客户端关闭会话,或者Session超时失效时会话结束。
目前大多数的应用都是用Cookie实现Session跟踪的。第一次创建Session时,服务端会通过在HTTP协议中返回给客户端,在Cookie中记录SessionID,后续请求时传递SessionID给服务,以便后续每次请求时都可分辨你是谁。-
1.通过session累计用户数据。例如,一个未登录用户访问了京东网站,这个时候京东对其下发了一个 cookie,假设cookie的名字叫做abc,那这条记录就是 abc=001,同时京东的后台也生成了一个 session id, 它的值也为 001, 001 这个客户在 2 点、 3 点、 4 点分别添加了三件商品到购物车,这样后台也记录了 session id 为 001的用户的购物车里面已经有三件商品,并且只要每次客户端 cookie 带上来的值里面包含session id,后台都能够展示相应的数据,如果这个时候,在浏览器里面清空 cookie,cookie 数据消失之后,后台和客户端无法建立对应关系,购物车的数据就会失效了。
2.通过session实现单点登录。一个用户帐号成功登录后,在该次session还未失效之前,不能在其他机器上登录同一个帐号。登录后将用户信息保存到session中,如果此时在另外一台机器上一个相同的帐号请求登录,通过遍历(遍历的意思就是将所有session都查看一遍)Web服务器中所有session并判断其中是否包含同样的用户信息,如果有,在另一台机器上是不能登录该帐号的。
-
Cookie与Session的区别
- 作用范围不同,Cookie 保存在客户端(浏览器),Session 保存在服务器端。
- 存取方式的不同,Cookie只能保存 ASCII,Session可以存任意数据类型,比如UserId等。
- 有效期不同,Cookie可设置为长时间保持,比如默认登录功能功能,Session一般有效时间较短,客户端关闭或者Session超时都会失效。
- 隐私策略不同,Cookie存储在客户端,信息容易被窃取;Session存储在服务端,相对安全一些。
- 存储大小不同, 单个Cookie 保存的数据不能超过 4K,Session可存储数据远高于Cookie。- 禁用Cookie会怎样?
如果客户在浏览器禁用了Cookie,该怎么办呢?
方案一:拼接SessionId参数。在GET或POST请求中拼接SessionID,GET请求通常通过URL后面拼接参数来实现,POST请求可以放在Body中。无论哪种形式都需要与服务器获取保持一致。
这种方案比较常见,比如老外的网站,经常会提示是否开启Cookie。如果未点同意或授权,会发现浏览器的URL路径中往往有"?sessionId=123abc"这样的参数。URL地址重写的原理是将该用户session的id信息重写到URL地址中,服务器能够解析重写后的URL获取session的id。这样即使客户端不支持cookie,也可以使用session来记录用户状态。
方案二:基于Token(令牌)。在APP应用中经常会用到Token来与服务器进行交互。Token本质上就是一个唯一的字符串,登录成功后由服务器返回,标识客户的临时授权,客户端对其进行存储,在后续请求时,通常会将其放在HTTP的Header中传递给服务器,用于服务器验证请求用户的身份。- 分布式系统中Session如何处理?
在分布式系统中,往往会有多台服务器来处理同一业务。如果用户在A服务器登录,Session位于A服务器,那么当下次请求被分配到B服务器,将会出现登录失效的问题。
针对类似的场景,有三种解决方案:
方案一:请求精确定位。也就是通过负载均衡器让来自同一IP的用户请求始终分配到同一服务上。比如,Nginx的ip_hash策略,就可以做到。
方案二:Session复制共享。该方案的目标就是确保所有的服务器的Session是一致的。像Tomcat等多数主流web服务器都采用了Session复制实现Session的共享.
方案三:基于共享缓存。该方案是通过将Session放在一个公共地方,各个服务器使用时去取即可。比如,存放在Redis、Memcached等缓存中间件中。
在Spring Boot项目中,如果集成了Redis,Session共享可以非常方便的实现。
- 同源策略与跨域请求
所谓的“同源”指的是“三个相同”:协议相同、域名相同、端口相同。只有这三个完全相同,才算是同源。
同源策略的目的:是为了保证用户信息的安全,防止恶意的网站窃取数据。
比如,用户访问了银行网站A,再去浏览其他网站,如果其他网站可以读取A的Cookie,隐私信息便会泄露。更可怕的是,通常Cookie还用来保存用户登录状态,会出现冒充用户行为。因此,"同源策略"是必需的,如果Cookie可以共享,互联网就毫无安全可言了。
同源策略保证了一定的安全性,但在某些场景下也带来了不便,比如常见的跨域请求问题。
在HTML中,<a>,<form>, <img>, <script>, <iframe>, <link> 等标签以及Ajax都可以指向一个资源地址,而所谓的跨域请求就是指:当前发起请求的域与该请求指向的资源所在的域不一样。同源即同域,三项有一项不同便会出现跨域请求。
浏览器会对跨域请求做出限制,因为跨域请求可能会被利用发动CSRF攻击。
CSRF(Cross-site request forgery),即“跨站请求伪造”,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。CSRF攻击者在用户已经登录目标网站之后,诱使用户访问一个攻击页面,利用目标网站对用户的信任,以用户身份在攻击页面对目标网站发起伪造用户操作的请求,达到攻击目的。
-
针对跨域请求通常有如下方法:
-
通过代理避开跨域请求;
-
通过Jsonp跨域;
-
通过跨域资源共享(CORS)
-
-
session的生命周期与有效期
为了获得更高的存取速度,服务器一般把session放在内存里。每个用户都会有一个独立的session。如果session内容过于复杂,当大量客户访问服务器时可能会导致内存溢出。**session的使用虽然比cookie方便,但是过多的session存储在服务器内存中,会对服务器造成压力。**因此,session里的信息应该尽量精简。
session在用户第一次访问服务器的时候自动创建。session生成后,只要用户继续访问,服务器就会更新Session的最后访问时间,并维护该session。
由于有越来越多的用户访问服务器,因此session也会越来越多。为防止内存溢出,服务器会把长时间内没有活跃的session从内存中删除。这个时间就是session的超时时间。如果超过了超时时间没访问过服务器,session就自动失效了。
- http和https的区别
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。-
https的原理
1. 客户端发起HTTPS请求
这个没什么好说的,就是用户在浏览器里输入一个https网址,然后连接到server的443端口。
2. 服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)。这套证书其实就是一对公钥和私钥。如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3. 传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4. 客户端解析证书
这部分工作是由客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值。然后用证书对该随机值进行加密。就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5. 传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6. 服务端解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥(随机值)通过某种算法混合在一起,这样除非知道私钥(随机值),不然无法获取内容,而正好客户端和服务端都知道这个私钥(随机值),所以只要加密算法够彪悍,私钥(随机值)够复杂,数据就够安全。
7. 传输加密后的信息
这部分信息是服务端用私钥(随机值)加密后的信息,可以在客户端被还原
8. 客户端解密信息
客户端用之前生成的私钥(随机值)解密服务端传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。-
HTTPS的通信流程
-
核心思想
- 客户端解析证书 这部分工作是由客户端的 TLS 来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个对称加密密钥,然后用公钥对该密钥进行非对称加密。 - 传送加密信息 这部分传送的是用公钥加密后的对称加密密钥,目的就是让服务端得到这个密钥,以后客户端和服务端的通信就可以通过这个密钥来进行加密解密了。 - 服务端解密信息 服务端用非对称加密算法里的私钥解密后,得到了客户端传过来的对称加密算法的私钥,然后把之后传输的内容通过该值进行对称加密。 - 为什么用非对称加密协商对称加密密钥 对称加密的特点:对称密码体制中只有一种密钥,并且是非公开的。如果要解密就得让对方知道密钥,所以想要保证其安全性就要保证密钥的安全。 非对称加密的特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,而使得加密解密速度没有对称加密解密的速度快。非对称密钥体制有两种密钥,其中一个是公开的,这样就可以不需要像对称密码那样传输对方的密钥了,这样安全性就大了很多。 - 非对称加密公钥和私钥的使用方法: (1) 公钥加密私钥解密。 (2) 私钥做数字签名,公钥验证。
我在局域网中有一台电脑,部署了web服务,现在希望所有人都能访问它。很显然,这台电脑只有一个局域网ip,没有公网ip。那么同一局域网内的设备可以通过局域网ip找到他。而其他设备则找不到你。最多只能找到你的路由器,却进不了你的局域网。那么就需要内网穿透了。
- 情况一:你家的路由器被分配了一个固定的公网ip这种情况非常容易,但是极其少见。只需要在路由器中将路由器的某些端口映射到局域网某电脑的某些端口上就ok了。然后就可以使用公网ip+端口号访问了。
- 情况二:你家的路由器被分配了一个临时的公网ip这种情况比情况一多见,但依然很少见。操作同上,但是因为公网ip会变,所以客户端每次也要跟着变。如果你有域名的话,可以使用ddns将你的域名解析到改公网ip上,并且在公网ip变化时自动更换解析。
- 情况三:你家的路由器被分配了一个内网ip这种情况才是最普遍的。此时必须借助一个有公网ip的云服务器。内网机器向云服务器建立一个长连接,然后云服务器就可以主动向内网机器传数据。云服务器将自己某端口的数据转发到内网机器上,然后客户端访问云服务器的那个端口就可以访问内网机器了。既然我已经有了云服务器,为什么还要多此一举使用内网的电脑?可能的的数据比较重要,不希望放在云服务器上。可能你的云服务器配置不够,而你的服务需要高cpu高内存高磁盘容量。如果你买了云服务器的话,可以使用frp来映射。没有云服务器的话,网上有免费的frp服务,可以去找一下,但是可能不稳定。- 例子
A在家上网,B也在家上网。 有一款局域网游戏,AB想要一起玩。由于是局域网游戏,那么就需要A或者B其中一位,穿透广域网,去到另外一位的家里的局域网,成为局域网的一员。我们称这种行为叫内网穿透。 具体实现方法,就是在双方,局域网访问外网的路由上,设置NAT,当访问路由虚拟的身份的时候,路由就会转发到外网,去到对方的路由,而对方的路由,也虚拟一个身份,进行信息的对接收发。
- 什么是token
token的意思是“令牌”,是服务端生成的一串字符串,作为客户端进行请求的一个标识。
当用户第一次登录后,服务器生成一个token并将此token返回给客户端,以后客户端只需带上这个token前来请求数据即可,无需再次带上用户名和密码。
简单token的组成;uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token的前几位以哈希算法压缩成的一定长度的十六进制字符串。为防止token泄露)。- 身份认证概述
由于HTTP是一种没有状态的协议,它并不知道是谁访问了我们的应用。这里把用户看成是客户端,客户端使用用户名还有密码通过了身份验证,不过下次这个客户端再发送请求时候,还得再验证一下。
通用的解决方法就是,当用户请求登录的时候,如果没有问题,在服务端生成一条记录,在这个记录里可以说明登录的用户是谁,然后把这条记录的id发送给客户端,客户端收到以后把这个id存储在cookie里,下次该用户再次向服务端发送请求的时候,可以带上这个cookie,这样服务端会验证一下cookie里的信息,看能不能在服务端这里找到对应的记录,如果可以,说明用户已经通过了身份验证,就把用户请求的数据返回给客户端。
以上所描述的过程就是利用session,那个id值就是sessionid。我们需要在服务端存储为用户生成的session,这些session会存储在内存,磁盘,或者数据库。-
基于token机制的身份认证
-
使用token机制的身份验证方法,在服务器端不需要存储用户的登录记录。大概的流程:
客户端使用用户名和密码请求登录。 服务端收到请求,验证用户名和密码。 验证成功后,服务端会生成一个token,然后把这个token发送给客户端。 客户端收到token后把它存储起来,可以放在cookie或者Local Storage(本地存储)里。 客户端每次向服务端发送请求的时候都需要带上服务端发给的token。 服务端收到请求,然后去验证客户端请求里面带着token,如果验证成功,就向客户端返回请求的数据。
-
用设备mac地址作为token
客户端:客户端在登录时获取设备的mac地址,将其作为参数传递到服务端 服务端:服务端接收到该参数后,便用一个变量来接收,同时将其作为token保存在数据库,并将该token设置到session中。客户端每次请求的时候都要统一拦截,将客户端传递的token和服务器端session中的token进行对比,相同则登录成功,不同则拒绝。 此方式客户端和服务端统一了唯一的标识,并且保证每一个设备拥有唯一的标识。缺点是服务器端需要保存mac地址;优点是客户端无需重新登录,只要登录一次以后一直可以使用,对于超时的问题由服务端进行处理。
-
用sessionid作为token
客户端:客户端携带用户名和密码登录 服务端:接收到用户名和密码后进行校验,正确就将本地获取的sessionid作为token返回给客户端,客户端以后只需带上请求的数据即可。 此方式的优点是方便,不用存储数据,缺点就是当session过期时,客户端必须重新登录才能请求数据。 当然,对于一些保密性较高的应用,可以采取两种方式结合的方式,将设备mac地址与用户名密码同时作为token进行认证。
-
-
APP利用token机制进行身份认证
用户在登录APP时,APP端会发送加密的用户名和密码到服务器,服务器验证用户名和密码,如果验证成功,就会生成相应位数的字符产作为token存储到服务器中,并且将该token返回给APP端。
以后APP再次请求时,凡是需要验证的地方都要带上该token,然后服务器端验证token,成功返回所需要的结果,失败返回错误信息,让用户重新登录。其中,服务器上会给token设置一个有效期,每次APP请求的时候都验证token和有效期。- token的存储
token可以存到数据库中,但是有可能查询token的时间会过长导致token丢失(其实token丢失了再重新认证一个就好,但是别丢太频繁,别让用户没事儿就去认证)。
为了避免查询时间过长,可以将token放到内存中。这样查询速度绝对就不是问题了,也不用太担心占据内存,就算token是一个32位的字符串,应用的用户量在百万级或者千万级,也是占不了多少内存的。- token的加密
token是很容易泄露的,如果不进行加密处理,很容易被恶意拷贝并用来登录。加密的方式一般有:
1. 在存储的时候把token进行对称加密存储,用到的时候再解密。
2. 文章最开始提到的签名sign:将请求URL、时间戳、token三者合并,通过算法进行加密处理。最好是两种方式结合使用。
还有一点,在网络层面上token使用明文传输的话是非常危险的,所以一定要使用HTTPS协议。
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
在数据库系统中,一个事务是指:由一系列数据库操作组成的一个完整的逻辑过程。例如银行转帐,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和,构成一个完整的逻辑过程,不可拆分。这个过程被称为一个事务,具有ACID特性。
-
四大特性
- Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 - Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。 - Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。 - Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
CRUD,描述软件系统数据库或持久层的基本操作功能
crud是指在做计算处理时的增加(Create)、读取(Read)、更新(Update)和删除(Delete)几个单词的首字母简写。crud主要被用在描述软件系统中数据库或者持久层的基本操作功能。
C reate new records
R ead existing records
U pdate existing records
D elete existing records.
-
赋值法
需借助上面的第3个临时变量temp.,进行调换。 -
相加法
将两个数据相加 a+b赋值给其中一个,然后将之后得出的变量再减去剩下那个变量并赋值给它,再用其减去剩下的变量赋值给自己。


-
异或法
相同为1 不同为0 由异或的运算法则之一**( a ^ b ) ^a = a**

主要是基于异或运算的如下性质:
1.任意一个变量X与其自身进行异或运算,结果为0,即X^X=0
2.任意一个变量X与0进行异或运算,结果不变,即X^0=X
3.异或运算具有可结合性,即a^b^c=(a^b)^c=a^(b^c)
4.异或运算具有可交换性,即a^b=b^a
-
python内置方法
python内置了了一个方法 可以直接使两个数互换

-
CSRF是什么?
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
-
CSRF可以做什么?
你这可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。CSRF能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账…造成的问题包括:个人隐私泄露以及财产安全。
-
CSRF漏洞现状
CSRF这种攻击方式在2000年已经被国外的安全人员提出,但在国内,直到06年才开始被关注,08年,国内外的多个大型社区和交互网站分别爆出CSRF漏洞,如:NYTimes.com(纽约时报)、Metafilter(一个大型的BLOG网站),YouTube和百度HI…而现在,互联网上的许多站点仍对此毫无防备,以至于安全业界称CSRF为“沉睡的巨人”。
-
CSRF的原理
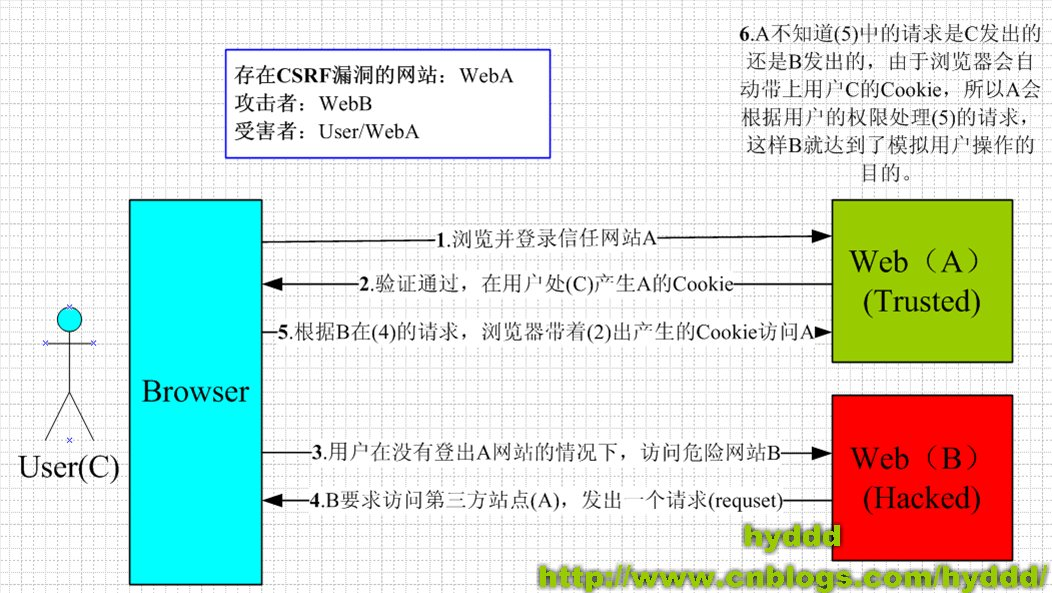
从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1.登录受信任网站A,并在本地生成Cookie。
2.在不登出A的情况下,访问危险网站B。
看到这里,你也许会说:“如果我不满足以上两个条件中的一个,我就不会受到CSRF的攻击”。是的,确实如此,但你不能保证以下情况不会发生:
1.你不能保证你登录了一个网站后,不再打开一个tab页面并访问另外的网站。
2.你不能保证你关闭浏览器了后,你本地的Cookie立刻过期,你上次的会话已经结束。(事实上,关闭浏览器不能结束一个会话,但大多数人都会错误的认为关闭浏览器就等于退出登录/结束会话了…)
3.上图中所谓的攻击网站,可能是一个存在其他漏洞的可信任的经常被人访问的网站。
上面大概地讲了一下CSRF攻击的思想,下面我将用几个例子详细说说具体的CSRF攻击,这里我以一个银行转账的操作作为例子* HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。 它是一个URI scheme(抽象标识符体系),句法类同http:体系。用于安全的HTTP数据传输。
* https:URL表明它使用了HTTP,但HTTPS存在不同于HTTP的默认端口及一个加密/身份验证层(在HTTP与TCP之间)。这个系统的最初研发由网景公司进行,提供了身份验证与加密通讯方法,现在它被广泛用于万维网上安全敏感的通讯。
* 超文本传输协议 (HTTP-Hypertext transfer protocol) 是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
- http与https的区别是什么呢?
- https协议需要到ca申请证书,一般免费证书很少,需要交费。
- http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议
- http和https使用的是完全不同的连接方式用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的
- HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议 要比http协议安全
python中的装饰器(decorator)是一种语法格式。比如:@classmethod,@staticmethod,@property,@xxx.setter,@wraps(),@func_name等都是python中的装饰器。
装饰器,装饰的对象是函数或者方法。各种装饰器的作用都是一样的:改变被装饰函数或者方法的功能,性质。
下面主要讲解@wraps(),@func_name,类装饰器这两种装饰器。装饰器本质上是一个Python函数(其实就是闭包),它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。装饰器用于有以下场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
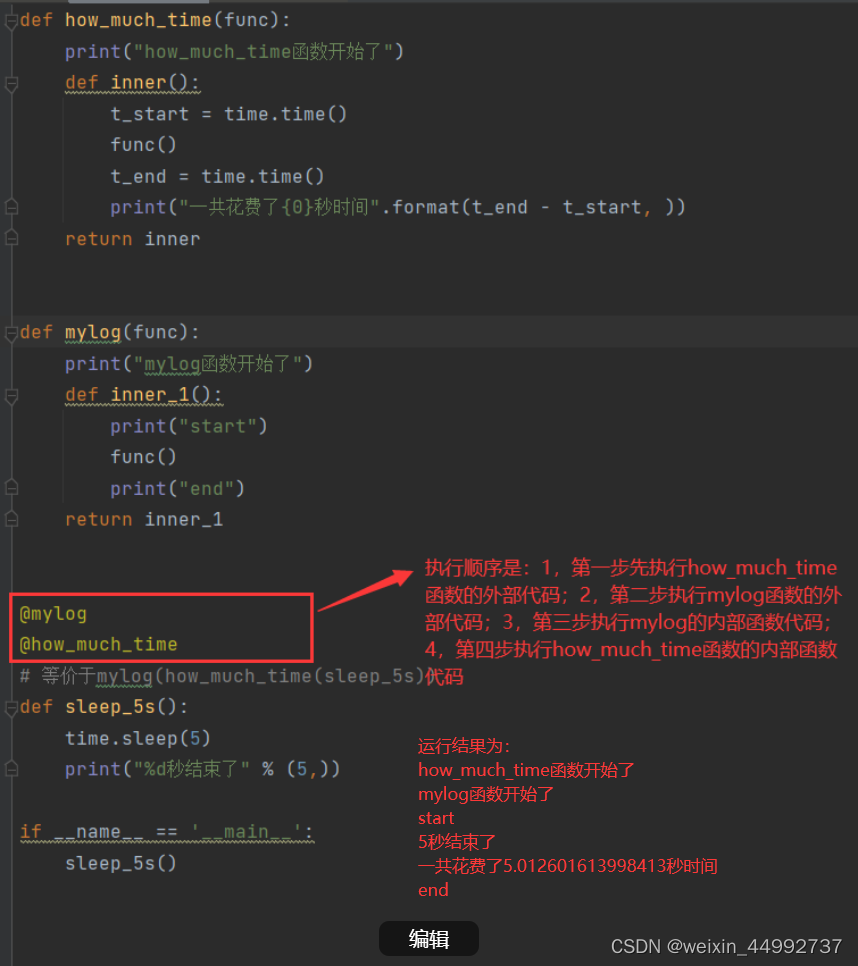
闭包的定义:
- 外函数嵌套内函数
- 内函数引用外函数里的变量
- 外函数返回内函数
糖衣语法。指的是在计算机语言中添加的某种语法,这种语法对语言的编译结果和功能并没有实际影响, 但是却能更方便程序员使用该语言。
用处
通常来说使用语法糖能够减少代码量、增加程序的可读性,从而减少程序代码出错的机会。举例
泛型的类型擦除
自动拆箱装箱
for each循环
断言语句
枚举类
内部类
switch对字符串、枚举的支持DNS,计算机域名系统的缩写,也就是域名解析服务器,它在网站中起到的作用就是把你要访问的网址找到然后把信息输送到你电脑上,它是由解析器和域名服务器组成的。
工作原理
客户机提出域名解析请求,并将该请求发送给本地的域名服务器。
当本地的域名服务器收到请求后,就先查询本地的缓存,如果有该纪录项,则本地的域名服务器就直接把查询的结果返回。
如果本地的缓存中没有该纪录,则本地域名服务器就直接把请求发给根域名服务器,然后根域名服务器再返回给本地域名服务器一个所查询域 (根的子域) 的主域名服务器的地址。
本地服务器再向上一步返回的域名服务器发送请求,然后接受请求的服务器查询自己的缓存,如果没有该纪录,则返回相关的下级的域名服务器的地址。
重复第四步,直到找到正确的纪录。
本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时还将结果返回给客户机。DNS 组成
1、DNS 域名空间
指定用于组织名称的域层次结构。 根域在顶部,根域下面有几个顶级域,每个顶级域可以进一步划分为不同的子域,子域可以进一步划分子域,子域下面可以是主机,也可以是划分的子域。
2、DNS 服务器
DNS 服务器是维护域名空间中颜色数据的程序。 因为域名服务很分散。 每台 DNS 服务器都包含域名空间自己的完整信息,并有七个控制区域 (Zone)。 ssdddd 本区内的要求由负责本区的 DNS 服务器解释,对于其他区的要求,由本区的 DNS 服务器联系负责该区的相应服务器。
其中,DNS 服务器在形式上分为主服务器、从属服务器和缓存服务器。
(1) 主服务器
如果为客户端提供了域名解析的主要区域,并且主 DNS 服务器故障,则来自 DNS 服务器的服务将生效。
(2) 从服务器
主服务器 DNS 长期没有响应,从服务器也停止提供服务。 主从地区治安同步采用周期性检查通知的机制。 从属服务器周期性检查主服务器上记录的情况,发现修改时同步。 另外,如果主服务器上的数据又发生了修改,服务器会立即通知您记录已更新。
(3) 高速缓存服务器
缓存服务器是不负责民法数据维护和域名解析的 DNS 服务类型。 在主机本地保存用户常用的域名和 IP 地址解析记录,以提高下次解析的效率。
3、解释器
解释器是一个简单的程序和子程序,它从服务中提取信息以响应对域名空间中主机的查询。局域网中,网络中实际传输的是“帧”,帧里面是有目标主机的mac地址的。所谓“地址解析”就是主机在发送帧前将目标ip地址转换成目标mac地址的过程。arp协议的基本功能就是通过目标设备的ip地址,查询目标设备的mac地址以保证通信的顺利进行。
注解:简单地说,arp协议主要负责将局域网中的32为ip地址转换为对应的48位物理地址,即网卡的mac地址,比如ip地址为192.168.0.1网卡mac地址为00-03-0f-fd-1d-2b。整个转换过程是一台主机先向目标主机发送包含ip地址信息的广播数据包,即arp请求,然后目标主机向该主机发送一个含有ip地址和mac地址数据包,通过mac地址两个主机就可以实现数据传输了。
应用:在安装了以太网网络适配器的计算机中都有专门的arp缓存,包含一个或多个表,用于保存ip地址以及经过解析的mac地址。在windows中要查看或者修改arp缓存中的信息,可以使用arp命令来完成,比如在windows xp的命令提示符窗口中键入“arp -a”或“arp -g”可以查看arp缓存中的内容;键入“arp -d ipaddress”表示删除指定的ip地址项(ipaddress表示ip地址)。arp命令的其他用法可以键入“arp /?”查看到。
我们首先要知道以太网内主机通信是靠mac地址来确定目标的.arp协议又称"地址解析协议",它负责通知电脑要连接的目标的地址,这里说的地址在以太网中就是mac地址,简单说来就是通过ip地址来查询目标主机的mac地址.一旦这个环节出错,我们就不能正常和目标主机进行通信,甚至使整个网络瘫痪.
arp的攻击主要有以下几种方式
一.简单的欺骗攻击
这是比较常见的攻击,通过发送伪造的'arp包来欺骗路由和目标主机,让目标主机认为这是一个合法的主机.便完成了欺骗.这种欺骗多发生在同一网段内,因为路由不会把本网段的包向外转发,当然实现不同网段的攻击也有方法,便要通过icmp协议来告诉路由器重新选择路由.
二.交换环境的嗅探
在最初的小型局域网中我们使用hub来进行互连,这是一种广播的方式,每个包都会经过网内的每台主机,通过使用软件,就可以嗅谈到整个局域网的数据.现在的网络多是交换环境,网络内数据的传输被锁定的特定目标.既已确定的目标通信主机.在arp欺骗的基础之上,可以把自己的主机伪造成一个中间转发站来监听两台主机之间的通信.
三.mac flooding
这是一个比较危险的攻击,可以溢出交换机的arp表,使整个网络不能正常通信
四.基于arp的dos
这是新出现的一种攻击方式,d.o.s又称拒绝服务攻击,当大量的连接请求被发送到一台主机时,由于主机的处理能力有限,不能为正常用户提供服务,便出现拒绝服务.这个过程中如果使用arp来隐藏自己,在被攻击主机的日志上就不会出现真实的ip.攻击的同时,也不会影响到本机.
防护方法:
1.ip+mac访问控制.
单纯依靠ip或mac来建立信任关系是不安全,理想的安全关系建立在ip+mac的基础上.这也是我们校园网上网必须绑定ip和mac的原因之一.
2.静态arp缓存表.
每台主机都有一个临时存放ip-mac的对应表arp攻击就通过更改这个缓存来达到欺骗的目的,使用静态的arp来绑定正确的mac是一个有效的方法.在命令行下使用arp -a可以查看当前的arp缓存表.以下是本机的arp表ARP 欺骗的防范措施如下:
通过双向 IP-MAC 绑定防范 ARP 欺骗:在客户机绑定网关 IP-MAC,设置网关 IP 与 MAC 的静态映射。在网关上绑定客户机 IP-MAC,使用支持 IP/MAC 绑定的网关设备,在网关设备中设置客户机的静态 IP-MAC 列表。这种方案可以抵御 ARP 欺骗,保证网络正常运行,但不能定位及清除 ARP 攻击源。
定位 ARP 攻击源:ARP 欺骗发生时,在受到 ARP 欺骗的计算机命令提示符下输入 “arp -a”, ARP 缓存中网关 IP 对应的 MAC 地址如果不是真实的网关 MAC 地址,则为 ARP 攻击源的 MAC 地址,一个 MAC 地址对应多个 IP 地址的为 ARP 攻击源的 MAC 地址;在网关 ARP 缓存中一个 MAC 对应多个 IP 的为 ARP 攻击源的 MAC 地址。
使用 ARP 防火墙:实际应用中多使用 ARP 防火墙软件抵御 ARP 欺骗。ARP 防火墙通过在系统内核层拦截虚假 ARP 包以及主动通告网关本机正确的 MAC 地址,可以保障数据流向正确,不经过第三者,从而保证数据通信安全和网络畅通。比较常用的有彩影 ARP 防火墙(AntiARP)、风云防火墙、金山 ARP 防火墙等。
VLAN 和交换机端口绑定:通过划分 VLAN 和交换机端口绑定来防范 ARP,也是常用的防范方法。做法是细致地划分 VLAN,减小广播域的范围,使 ARP 在小范围内起作 用,而不至于发生大面积影响。同时,一些网管交换机具有 MAC 地址学习的功能,学习完成后,再关闭这个功能,就可以把对应的 MAC 和端口进行绑定,避免了病毒利用 ARP 攻击篡改自身地址。也就是说,把 ARP 攻击中被截获数据的风险解除了。
使用 VLAN:只要你的 PC 和 P2P 终结者软件不在同一个 VLAN 里就可以。Nginx是一款轻量级的Web服务器、反向代理服务器,由于它的内存占用少,启动极快,高并发能力强,在互联网项目中广泛应用。
SLB是Server Load Balancer(负载均衡)的简称,是阿里云计算提供的一种网络负载均衡服务。
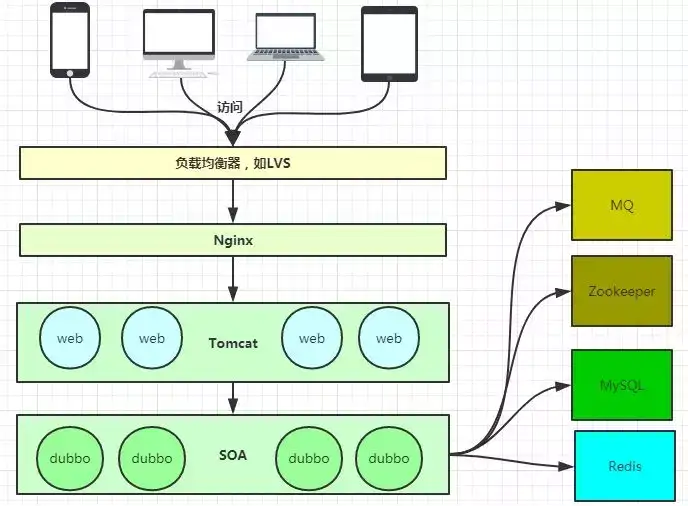
上图基本上说明了当下流行的技术架构,其中Nginx有点入口网关的味道。
正向代理:
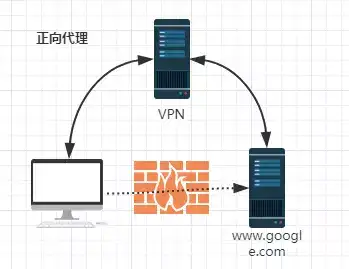
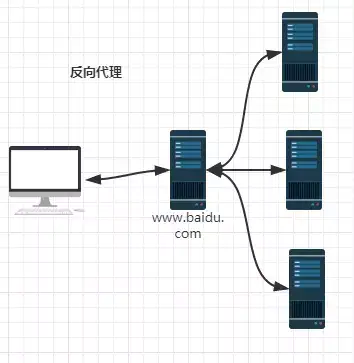
反向代理:
由于防火墙的原因,我们并不能直接访问谷歌,那么我们可以借助VPN来实现,这就是一个简单的正向代理的例子。这里你能够发现,正向代理“代理”的是客户端,而且客户端是知道目标的,而目标是不知道客户端是通过VPN访问的。
当我们在外网访问百度的时候,其实会进行一个转发,代理到内网去,这就是所谓的反向代理,即反向代理“代理”的是服务器端,而且这一个过程对于客户端而言是透明的。
网络分层体系结构
OSI七层模型:物、数、网、传、会、表、应
TCP/IP四层模式:链、网、传、应
1 )物理层)主要定义物理设备的标准,如网线接口类型、光纤接口类型、各种传输介质的传输速率等。 其主要作用是传输比特流。 也就是说,从1,0转换为电流强弱进行传输,到达目的地后再转换为1,0。 也就是说,人们常说数模转换和模数转换。 这一层的数据称为位。
2 )数据链路层)定义如何逐帧传输格式数据,以及如何控制对物理介质的访问。 此级别通常还提供错误检测和纠正,以确保数据的可靠传输。 例如,串行通信中使用115200、8、n、1
3 )网络层)提供地理位置较远的网络中两个主机系统之间的连接和路径选择。 随着互联网的发展,世界各网站访问信息的用户数量大幅增加。 网络层是管理这种连接的层。
4 )传输层) TCP )定义用于传输效率低、可靠性高、传输可靠性高、数据量大的数据的传输协议和端口号(WWW端口80等),与UDP ) TCP特性相反,传输可靠性高、传输可靠性高这一层的数据经常被称为段。
5 )通过会话层)传输层(端口号)传输端口接收端口)建立数据传输的路径。 主要在系统之间启动会话或接受会话请求。 设备之间必须相互识别,无论是IP、MAC还是主机名。
6 )表示层:保证一个系统的APP应用层发送的信息被另一个系统的APP应用层读取。 例如,PC程序与另一台计算机通信。 一台计算机使用扩展双转换交换机代码(ebcdic ),另一台使用美国信息交换标准代码(ASCII )表示同一字符。 如果需要,表示层使用一种通用格式在多种数据格式之间提供转换。
7 ) APP应用层:是离用户最近的OSI层。 此层为用户的APP应用程序(如电子邮件、文件传输和终端模拟)提供网络服务。
分层功能映像:
OSI七层模型结构体:物、数、网、传、会、表、应
TCP/IP四层模式:数、网、传、应
1.链路层速记:核心协议(ARP )
源mac ——目标mac
ARP协议的作用:通过IP获取mac地址。
2.IP :地址由管理员分配
网络层速记:核心协议(IP ) )
源IP ——目标IP
IP协议角色在网络环境中唯一标识主机。
IP和MAC角色:
网络地址(IP ) :有助于确定计算机所在的子网
MAC地址:将包发送到子网中的目的地网卡。
处理顺序:从逻辑上可以推测,必须先处理网络地址,然后再处理MAC地址
3.传输层:端口:决策过程
1 )同一端口在不同的系统上支持不同的进程
2 )在同一系统上,端口只能由一个进程拥有
传输层:核心协议(TCP/UDP )
port ——在主机上唯一标识进程。
应用关系:通过网络层IP确认交互端,通过MAC确认消息目标,最终指定通过端口发生消息交换的程序该APP应用层接收从传输层传递的数据并解析数据。
4.应用层速记: ftp、http、定制封装数据。 解除封装
TCP/IP:TCP/IP协议是一个大家庭,不仅包括TCP和IP协议,还包括其他协议
套接字:插座。
在网络通信中,套接字一定会成对出现。
1.在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通信中的进程。
2.IP地址端口号:对应于套接字。
3.如果尝试建立连接的两个进程分别由一个套接字标识,则由这两个套接字组成的套接字支付将被唯一标识一个连接。
4.插座描述网络连接的一对一关系。
5.常用的插座类型有流式传输插座(sock_stre )两种AM和数据报式Socket(SOCK_DGRAM)。
a)流式是一种面向连接的Socket,针对于面向连接的TCP服务应用;
b)据报式Socket是一种无连接的Socket,对应于无连接的UDP服务应用。
关于通信:
mac地址(不需要用户指定)(ARP 协议)Ip ——> macIP 地址 (需要用户指定) —— 确定主机port 端口号 (需要用户指定) —— 确定程序不能使用系统占用的默认端口。 5000+ 端口我们使(8080)65535为端口上限。
C/S架构设计的优缺点:
优点:
1,性能:客户端位于目标主机上可以保证性能,将数据缓存至客户端本地,从而提高数据传输效率。
2,协议灵活:客户端和服务器程序由一个开发团队创作
缺点:
1,成本高客户端服务端都需要独立开发
2,独立安装客户端对用户来说有安全隐患
TCP通信过程:
三次握手:
-
主动发起请求端, 发送 SYN
-
被动建立连接请求端 , 应答ACK 同时 发送 SYN
-
主动发起请求端,发送应答 ACK* 标志 TCP 三次握手建立完成。 —— server:Accept() 返回 。— client:Dial() 返回
四次挥手:
-
主动关闭连接请求端, 发送 FIN
-
被动关闭连接请求端 ,应答 ACK标志。半关闭完成。 —— close()
-
被动关闭连接请求端 ,发送 FIN
-
主动关闭连接请求端,应答 ACK标志。四次挥手建立完成
查看状态命令: windows:netstat -an | findstr 8001(端口号) Linux: netstat -apn | grep 8001
-
一: 区别
- 冒泡排序是比较相邻位置的两个数,而选择排序是按顺序比较,找最大值或者最小值;
- 冒泡排序每一轮比较后,位置不对都需要换位置,选择排序每一轮比较都只需要换一次位置;
- 冒泡排序是通过数去找位置,选择排序是给定位置去找数;
-
二: 冒泡排序优缺点
- 优点:比较简单,空间复杂度较低,是稳定的;
- 缺点:时间复杂度太高,效率慢;
-
三: 选择排序优缺点
- 优点:一轮比较只需要换一次位置;
- 缺点:效率慢,不稳定(举个例子5,8,5,2,9 我们知道第一遍选择第一个元素5会和2交换,那么原序列中2个5的相对位置前后顺序就破坏了)。
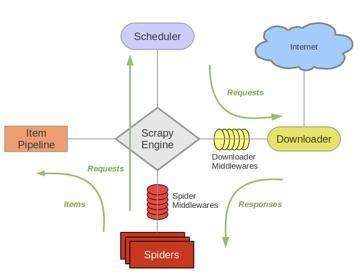
基本工作流程:
1、引擎向spiders要url
2、引擎将要爬取的url给调度器(schedule)
3、调度器(schedule)会将url生成请求对象放入到指定的队列中
4、从队列中抛出一个请求
5、引擎将请求交给下载器进行处理
6、下载器发送请求,获取互联网数据
7、下载器将数据返回给引擎进行处理
8、引擎将数据再次给spiders
9、spiders使用xpath解析该数据,得到数据或url
10、spiders将数据或者url给到引擎
11、引擎判断spiders发送的是url函数数据,将数据交给管道 Item Pipeline,是url交给调度器处理
注意:
scrapy结束工作流程的条件是spiders传给引擎的只剩下数据的时候是流程工作结束的时候

1. 在网站注册帐号,创建工程 test 进入工程,右下角会有一个项目仓库的地址。
https://github.com/braverior/test.git
2. Linux下 安装github
sudo apt -get install git git-core git-doc
3. 创建rsa公钥
ssh-keygen -t rsa -C "[email protected]"
整个过程中有一个需要填密码
然后后进入~/.ssh目录 找到公钥id_rsa.pub
记事本打开复制文字
进入github.com中的的设置,找到pubkey选项,填入公钥。
命题随便填
4. 设置账户信息
git config --global user.name "lukeyan"
git config --global user.email [email protected]
5. 测试链接:
上传:
git init
git add . #如果是.表示上传全部目录下的文件,可以是某个文件
git commit -m 'version 1.0'
git remote add origin https://github.com/用户名/test.git
git push origin master -f- 生成本地公钥
1.首先你应该安装本地git 了吧,打开gitbash.
2.输入:”ssh-keygen -t rsa”(输入双引号里的内容),enter。根据提示找到生成公钥的文件,打开查 看。
- clone代码到本地
首先你应该建立自己的仓库
1在刚才打开的git中用:cd 盘符:/xx/yy 到yy文件下
2git init
3此时可以看到在yy文件下可以看到一个.git文件夹(此时支master已经建立好了),再建一个你想建的仓库,这里用dev,用:git checkout -b dev 去建立。
4怎么知道dev是否建立成功呢,用git checkout dev 指令查看是否成功并切换到dev。
5从本地clone远程代码:git clone [email protected]:XXXX/工程名.git -b dev (为什么要-b,这是获取分支dev的代码到本地的dev仓。XXXX指的是你要获取的对方的网络地址名)。
- 上传代码到创库
首先把你要上传的代码添加到本地仓,然后提交,最后发到网络端。
1.git add 你要添加的文件(若是,某个文件夹下的文件,比如A文件夹下的文件则可以写成(git add xx/xx/A.))
2.git commit -m “本次上传内容的描述”
3.提交到网络将本地仓与github关联:git remote add origin 你的github地址/工程m名
4.git pull origin dev(注意本例提交到的是dev分支)总结: 其实只需要进行下面几步就能把本地项目上传到Github
1、在本地创建一个版本库(即文件夹),通过git init把它变成Git仓库;
2、把项目复制到这个文件夹里面,再通过git add .把项目添加到仓库;
3、再通过git commit -m "注释内容"把项目提交到仓库;
4、在Github上设置好SSH密钥后,新建一个远程仓库,通过git remote add origin https://github.com/guyibang/TEST2.git将本地仓库和远程仓库进行关联;
5、最后通过git push -u origin master把本地仓库的项目推送到远程仓库(也就是Github)上;(若新建远程仓库的时候自动创建了README文件会报错,解决办法看上面)。
fork是一个概念,而clone是在存储库上操作的过程
| Fork | Clone | |
|---|---|---|
| 分叉是在GitHub帐户上完成的 | 克隆是使用Git完成的 | |
| fork一个存储库会在我们的GitHub账户上创建一个原始存储库的副本 | 克隆存储库将在本地机器上创建原始存储库的副本 | |
| 对分叉存储库所做的更改可以通过一个pull请求与原始存储库合并 | 对克隆存储库所做的更改不能与原始存储库合并,除非您是该存储库的协作者或所有者 | |
| 分叉是一个概念 | 克隆是一个过程 | |
| fork只包含存储库的一个单独副本,不涉及命令 | 克隆是通过以下命令完成的: git clone ,这是一个接收所有代码文件到本地机器的过程 |
1、什么是接口
前后端数据传输的通道。
2、http请求的接口
协议+域名(ip)+接口地址+请求参数
3、http请求的要素
请求地址+请求方法+请求数据reduce() 函数会对参数序列中元素进行累积。
函数语法:
reduce(function, iterable[,initializer])
函数参数含义如下:
1、function 需要带两个参数,1个是用于保存操作的结果,另一个是每次迭代的元素。
2、iterable 待迭代处理的集合
3、initializer 初始值,可以没有。
reduce函数的运作过程是,当调用reduce方法时:
1、如果存在initializer参数,会先从iterable中取出第一个元素值,然后initializer和元素值会传给function处理;
接着再从iterable中取出第二个元素值,与function函数的返回值 再一起传给function处理,以此迭代处理完所有元素。最后一次处理的function返回值就是reduce函数的返回值。
2、如果不存在initializer参数,会先从iterable中取出第一个元素值作为initializer值,然后以此从iterable取第二个元素及以后的元素进行处理。特殊情况下,如果集合只有一个元素,则无论function如何处理,reduce返回的都是第一个元素的值。
lambd表达式是一种精简函数的表达方法,省略了函数的定义,命名等问题。
lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
用lambda表达式求n的阶乘:
n = 5
print reduce(lambda x,y:x*y,range(1,n+1))
>>>> 120lambda表达式也可以用在def函数中:
def action(x):
return lambda y:x+y
a = action(2)
print a(22)
>>>> 24
这里也可以把def直接写成lambda形式。如下:
b = lambda x:lambda y:x+y
a = b(2)
print a(22)#print (b(2))(22)
>>>> 24
1.传输层中的协议:TCP UDP
TCP协议:在双方程序连接的前提下,保证通信需要三次握手。在此期间需要保证通信双方连接正常。在通信的过程中有任何一方断开了连接,那么这个通信的通道就被破坏了,由于TCP是面向有连接的,因此它的效率比较低,但是比较可靠和安全。因此在网络中如果要传输高机密的信息,或传输大数据信息,一般都会采用TCP协议。
UDP协议:面向无连接的协议,通信双方不需要建立任何的通信通道,就可以直接发送数据。发送端不关心接收端是否存在或者打开设备,就直接发送,如果接收端不在,这时发送端把数据发送出去之后,没有接收端,数据就被丢弃了。一般UDP通信不安全,但是效率高。即时通信工具就采用这个协议。2.IP地址
因为连接在网络上的设备比较多,所以需要与某一个进行通信就要明确这个设备的标识。每一个连接在网络上的设备都有自己的ip地址。 个人电脑在上网的时候不需要配ip地址,它是由宽带供应商来提供。 把网络中的每台机器都起一个名字,名字和ip地址绑定在一起,这样就可以通过名字来访问机器。3.域名
由于ip地址都是一连串数字构成,那么域名就是连接在网络上的设备的名字。 如:[www.baidu.com](https://link.jianshu.com?t=http://www.baidu.com)
域名解析分为:
本地解析:当在浏览器输入某一个域名时,浏览器首先会到本地windows中的hosts文件查找有没有当前域名对应的ip地址如果有就拿这个ip地址访问主机。
网络解析(DNS解析):如果本地hosts文件中不存在此域名,那么就去网络中DNS服务器中找有没有对应的ip地址,如果也没有就会提示错误。如果存在就拿这个ip去访问这个ip对应的设备。4.端口
找到设备后需要进行通信,我们通过qq,微信来聊天,由于一个电脑有多个程序,所以我们需要给每个程序进行标识,我们分配数字进行标识,在访问某个设备的资源时,需要明确ip地址和程序对应的数字标识。在一台电脑中1——1024这些数字已经被系统软件所占用,所以在分配数字的时候不要使用这些数字,不然系统软件就无法使用。定义在类中且在方法外的变量,称之为类属性。
class TestDemo:
# 此处的name这个变量就叫类属性
name = "老王"Linux一般相应的文件都会会放在相应的目录下。这样更有利于文件的查找 /home 用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示 /root 系统管理员的主目录 Linux下其他其他目录的用途如下: /bin 二进制可执行命令 /dev 设备特殊文件 /etc 系统管理和配置文件 /etc/rc.d 启动的配置文件和脚本 /lib 标准程序设计库,又叫动态链接共享库,作用类似windows里的.dll文件 /sbin 超级管理命令,这里存放的是系统管理员使用的管理程序 /tmp 公共的临时文件存储点 /mnt 系统提供这个目录是让用户临时挂载其他的文件系统 /lost+found这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里 /proc 虚拟的目录,是系统内存的映射。可直接访问这个目录来获取系统信息。 /var 某些大文件的溢出区,比方说各种服务的日志文件 /usr 最庞大的目录,要用到的应用程序和文件几乎都在这个目录
其实linux与windows分区是一样的,都有主分区、扩展分区、逻辑分区,只是他们的目录结构不一样,所以导致表现形式也不一样。 winodws是森林型目录结构,它有很多根,如C、D、E、F等都是它的根目录,然后在其实创建子目录 linux是树型目录结构,它只有一个根就是/目录,然后在/目录在有子目录如/root、/home、/etc/、/bin等。你可以将/root、/home这些子目录单独挂载到一个分区上,如扩展分区、逻辑分区上。而不是以C、D、E分区的形式表现出来。
linux 添加开机启动项的方法:
输入vim /etc/rc.local后
- /etc/init.d/mysqld start #mysql开机启动
- /etc/init.d/nginx start #nginx开机启动
- /etc/init.d/php-fpm start #php-fpm开机启动
在/etc/init.d目录下添加自启动脚本
1.python解释器锁(GIL锁)
Python全局解释器锁或GIL是一种互斥锁(或锁),仅允许一个线程持有Python解释器的控制权。
这意味着在任何时间点只能有一个线程处于执行状态。对于执行单线程程序的开发人员而言,GIL的影响并不明显,但它可能是CPU绑定和多线程代码的性能瓶颈。
首先让我们来看看python的内存管理,Python使用引用计数进行内存管理。这意味着用Python创建的对象具有引用计数变量,该变量跟踪指向该对象的引用数。当此计数达到零时,将释放对象占用的内存。多个线程同时对一个值进行增加/减少的操作。如果发生这种情况,显然会导致非常严重的内存泄漏等问题。
一般来说我们都是通过锁来解决内存方面的问题的,而python就是通过GIL锁来做这件事情。但是既然有了锁,一个对象需要一个锁,那多个锁带来的死锁问题如何解决呢?重复获取或者释放锁带来的切换效率低的问题如何解决?因此,为了保证单线程情况下python的正常执行和效率,GIL锁(单一锁)由此产生了,由于只有一个,不会产生死锁且不用切换。IO密集情况下,使用协程进行异步IO可以进一步提升效率。因此,我们可以得到一个结论,在一般程序中(主要是IO密集型),GIL锁并不会带来太大的影响,除非进行包括进行数学计算的程序,例如矩阵乘法,搜索,图像处理或者超大数据量的运算等。目前最好的方法就是使用多进程的方式(multiprocessing)来替代多线程(注意!!前提是需要进行受CPU运算速度限制的程序)对于IO密集型应用,多线程的应用和多进程应用区别不大。即便有GIL存在,由于IO操作会导致GIL释放,其他线程能够获得执行权限。由于多线程的通讯成本低于多进程,因此偏向使用多线程。对于计算密集型应用,多线程处于绝对劣势,可以采用多进程或协程。
同时只可以执行一个线程
对于同一个变量的多个引用,同时只可以有一个线程对变量进行操作
2.什么是进程什么,什么是线程
进程是独立的实体,拥有独立的地址,进程间无法直接访问。
线程是进程的实体,线程间可以相互访问。
3.什么时候用多线程
CPU并行操作少,IO并行操作多(IO等待期间会进行线程切换)
需要频繁创建销毁的优先使用线程
GIL 全局解释器 在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行。但是在python中,无论有多少个核同时只能执行一个线程。究其原因,这就是由于GIL的存在导致的。 GIL的全程是全局解释器,来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看做是“通行证”,并且在一个python进程之中,GIL只有一个。拿不到线程的通行证,并且在一个python进程中,GIL只有一个,拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操作cpu,而只能利用GIL保证同一时间只能有一个线程拿到数据。而在pypy和jpython中是没有GIL的python在使用多线程的时候,调用的是c语言的原生过程。
python针对不同类型的代码执行效率也是不同的 1、CPU密集型代码(各种循环处理、计算等),在这种情况下,由于计算工作多,ticks技术很快就会达到阀值,然后出发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。 2、IO密集型代码(文件处理、网络爬虫等设计文件读写操作),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序的执行效率)。所以python的多线程对IO密集型代码比较友好。
主要要看任务的类型,我们把任务分为I/O密集型和计算密集型,而多线程在切换中又分为I/O切换和时间切换。如果任务属于是I/O密集型, 若不采用多线程,我们在进行I/O操作时,势必要等待前面一个I/O任务完成后面的I/O任务才能进行,在这个等待的过程中,CPU处于等待状态,这时如果采用多线程的话,刚好可以切换到进行另一个I/O任务。这样就刚好可以充分利用CPU避免CPU处于闲置状态,提高效率。但是如果多线程任务都是计算型,CPU会一直在进行工作,直到一定的时间后采取多线程时间切换的方式进行切换线程,此时CPU一直处于工作状态,此种情况下并不能提高性能,相反在切换多线程任务时,可能还会造成时间和资源的浪费,导致效能下降。这就是造成上面两种多线程结果不能的解释。 结论:I/O密集型任务,建议采取多线程,还可以采用多进程+协程的方式(例如:爬虫多采用多线程处理爬取的数据);对于计算密集型任务,python此时就不适用了。
测试代码
import multiprocessing
import threading
import time
from multiprocessing import Pool,Process
from concurrent.futures import ThreadPoolExecutor
def cpu_bound_task(n):
"""计算密集型任务:计算平方和"""
return sum(i * i for i in range(n))
def test_single_thread(numbers):
"""测试单线程"""
start = time.time()
for n in numbers:
cpu_bound_task(n)
return time.time() - start
def test_multi_thread(numbers):
"""测试多线程"""
start = time.time()
threads = []
# 创建与CPU核心数相同的线程
for n in numbers:
thread = threading.Thread(target=cpu_bound_task, args=(n,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
return time.time() - start
def test_thread_pool(numbers):
"""测试线程池"""
start = time.time()
with ThreadPoolExecutor(max_workers=multiprocessing.cpu_count()) as executor:
executor.map(cpu_bound_task, numbers)
return time.time() - start
def test_multi_process(numbers):
"""测试多进程"""
start = time.time()
with Pool() as pool:
pool.map(cpu_bound_task, numbers)
return time.time() - start
def test_manual_process(numbers):
"""手动创建进程执行"""
start = time.time()
processes = []
# 手动创建与CPU核心数相同的进程
for n in numbers:
p = Process(target=cpu_bound_task, args=(n,))
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
return time.time() - start
def run_comparison():
# 准备测试数据:创建与CPU核心数相同的任务
cpu_count = multiprocessing.cpu_count()
numbers = [10 ** 7] * cpu_count # 每个任务计算10^7个数的平方和
print(f"CPU核心数: {cpu_count}")
print(f"任务数量: {len(numbers)}")
print("\n开始测试...\n")
# 1. 测试单线程
single_thread_time = test_single_thread(numbers)
print(f"1. 单线程耗时: {single_thread_time:.2f}秒")
# 2. 测试多线程(直接创建线程)
multi_thread_time = test_multi_thread(numbers)
print(f"2. 多线程耗时: {multi_thread_time:.2f}秒")
# 3. 测试线程池
thread_pool_time = test_thread_pool(numbers)
print(f"3. 线程池耗时: {thread_pool_time:.2f}秒")
# 4. 测试多进程池
multi_process_time = test_multi_process(numbers)
print(f"4. 多进程耗时: {multi_process_time:.2f}秒")
# 5. 测试自定义进程
manual_process_time = test_manual_process(numbers)
print(f"5. 自定义进程耗时: {manual_process_time:.2f}秒")
# 计算加速比
speedup = single_thread_time / multi_process_time
print(f"\n多进程相比单线程的加速比: {speedup:.2f}倍")
if __name__ == '__main__':
run_comparison()结果
CPU核心数: 16
任务数量: 16
开始测试...
1. 单线程耗时: 7.92秒
2. 多线程耗时: 8.72秒
3. 线程池耗时: 9.42秒
4. 多进程耗时: 1.88秒
5. 自定义进程耗时: 1.89秒
多进程相比单线程的加速比: 4.22倍
可以将10 ** 7 调成 10 ** 8发现倍速明显变大用"接水"这个例子来解释不同的并发概念:
1. 单线程 vs 多线程 vs 多进程:
单线程:
- 一个人排队接16杯水
- 必须一杯一杯地接
- 相当于一个人完成所有工作
多线程(Python GIL限制):
- 16个人排队,但水龙头装了一个分配器
- 分配器每次只能让一个人接水
- 虽然看起来16个人都在"工作"
- 但因为分配器的限制,实际效率可能比一个人更低(因为切换人员也要时间)
多进程:
- 16个水龙头,16个人同时接水
- 每个人都能独立工作
- 效率最高,但需要更多资源(水龙头)
2. 不同任务类型:
CPU密集型(计算密集):
- 接水时需要仔细量水量,要算精确到毫升
- 主要瓶颈在于人的计算速度
- 这种情况多进程优势明显
IO密集型(输入输出密集):
- 接水时水龙头出水很慢,但不需要特别关注
- 主要瓶颈在于水龙头出水速度
- 这种情况用多线程就够了,因为大部分时间在等水
3. 其他概念:
死锁:
- A和B两个人都需要漱口杯和水壶
- A拿着漱口杯等水壶
- B拿着水壶等漱口杯
- 两人都在等对方,谁也接不了水
互斥锁:
- 水龙头装了一把锁
- 一个人用时会锁上
- 其他人必须等他用完解锁才能用
条件变量:
- 水箱需要达到一定水位才能接水
- 大家都在等"水箱满了"这个条件
- 水箱满了时,会通知等待的人
线程池/进程池:
- 准备了5个接水工具(比如水壶)
- 来了16个接水任务
- 这5个工具循环使用,直到完成所有任务
- 避免了创建过多工具带来的资源浪费
协程:
- 一个人同时负责多个水壶接水
- 当一个水壶在接水时,可以去看看其他水壶
- 看起来是"同时"在接多壶水,实际是在合理安排时间
- 特别适合IO密集型任务,因为等水的时间可以去做其他事
队列:
- 水龙头前放了个水桶
- 接水的人往水桶里加水
- 用水的人从水桶里取水
- 解耦了产水和用水的过程
这个例子的关键在于理解:
- 多线程像是一个水龙头多个人轮流用
- 多进程像是多个水龙头同时使用
- 选择哪种方式取决于你的瓶颈在哪里(计算还是IO)
- 以及可用的资源(水龙头数量)有多少
import threading
import time
import queue
from concurrent.futures import ThreadPoolExecutor
import requests
from pathlib import Path
class FileProcessor:
def __init__(self, num_threads=4):
self.num_threads = num_threads
self.download_queue = queue.Queue()
self.result_queue = queue.Queue()
def process_file(self, file_url):
"""处理单个文件的完整流程"""
try:
# 1. 下载文件(IO操作)
print(f"开始下载: {file_url}")
response = requests.get(file_url, stream=True)
# 模拟大文件下载耗时
time.sleep(1)
# 2. 读取文件内容(IO操作)
print(f"读取文件: {file_url}")
# 模拟文件读取耗时
time.sleep(0.5)
# 3. 处理文件(CPU操作,但很轻量)
print(f"处理文件: {file_url}")
# 模拟简单的处理操作
word_count = len(response.text.split())
# 4. 上传结果(IO操作)
print(f"上传结果: {file_url}")
# 模拟上传耗时
time.sleep(0.5)
return {"url": file_url, "word_count": word_count}
except Exception as e:
print(f"处理文件出错 {file_url}: {str(e)}")
return None
def process_files_with_threads(self, file_urls):
"""使用线程池处理多个文件"""
start_time = time.time()
with ThreadPoolExecutor(max_workers=self.num_threads) as executor:
# 提交所有任务到线程池
future_to_url = {
executor.submit(self.process_file, url): url
for url in file_urls
}
# 收集结果
results = []
for future in future_to_url:
try:
result = future.result()
if result:
results.append(result)
except Exception as e:
print(f"任务执行失败: {str(e)}")
total_time = time.time() - start_time
return results, total_time
def main():
# 模拟文件URL列表
file_urls = [
f"http://example.com/file_{i}.txt"
for i in range(200)
]
# 使用4个线程处理文件
processor = FileProcessor(num_threads=4)
results, total_time = processor.process_files_with_threads(file_urls)
print(f"\n处理完成:")
print(f"总耗时: {total_time:.2f}秒")
print(f"处理文件数: {len(results)}")
if __name__ == "__main__":
main()
Python 不使用异步编程时的 CPU 利用情况
- 主要使用单核 CPU
- 受 GIL (全局解释器锁) 限制
- 即使是多线程也难以充分利用多核
进程数量设置的经验法则:
- CPU 密集型任务:
- 进程数 = CPU 物理核心数
- 目的:最大化 CPU 利用率
- I/O 密集型任务:
- 进程数 = CPU 核心数 * 2
- 目的:充分利用等待时间
- 动态调整建议:
- 监控系统负载
- 根据实际情况灵活调整
- 避免过度创建进程
- Pool vs Process 的使用场景区别:
- Pool适合"批处理"型任务:比如你有1000个数需要计算,可以将它们分配给多个进程并行处理
- Process适合"服务"型任务:比如语音识别服务需要持续运行,等待新的请求进来,这种情况下用单独的进程更合适
Scrapy一个开源和协作的框架,其最初是为了页面抓取所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。

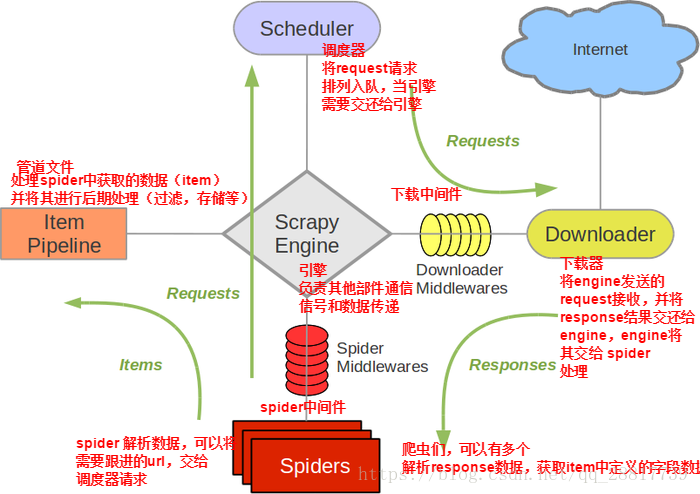
1.引擎从spider获取初始爬行请求。
2.引擎在调度程序中调度请求,并请求下一个要爬行的请求。
3.调度程序将下一个请求返回到引擎。
4.引擎将请求发送到下载器,并通过下载器中间件。
5.一旦页面完成下载,下载器将生成响应(使用该页面),并将其发送到引擎,并通过下载器中间软件。
6.引擎接收下载器的响应并将其发送给spider进行处理,并通过spider中间件进行处理。
7.spider处理响应,并通过spider中间件向引擎返回刮掉的项目和新请求(后续)。
8.引擎将已处理的项目发送到项目管道,然后将已处理的请求发送到计划程序,并请求可能的下一个请求进行爬网。
9.该过程重复(从步骤1开始),直到调度程序不再发出请求。
各组件以及作用:
引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response
爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests
组件
Scrapy Engine:引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler):调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader):下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders:Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline:Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
数据流(data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
1. 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
2. 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3. 引擎向调度器请求下一个要爬取的URL。
4. 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5. 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6. 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7. Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8. 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9. (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
最近工作中越来越认识到代码规范的重要性,会很大程度提高自己的代码质量和可读性,遂找到代码规范分享给大家
如何写出规范性强、可读性高的代码?
统一且设计良好的代码规范,是一种优良的编程习惯。PyCharm这一Python IDE使用的正是著名的PEP8代码规范,我们会看到,当有不符合规范的代码出现时,编译器会以灰色下划波浪线给出相关提示,本文即告诉你如何写出没有灰色警告线的至少看上去很美的代码样式。
1缩进(indentation)
使用四个空格表示每个缩进级别。
2最大行长度
所有行的最大长度均为79个字符。
3使用正确的换行位置。推荐的位置在二元操作符(binary operator,如下述代码中的and、or以及%)之后,而不是在它们之前:
4空行
顶级函数(当前文件中的第一个函数)或者顶级类(当前文件的第一个类)之前要有两个空行
定义在类内部的函数(成员函数)之间要留有一个空行
可以使用额外的空行(但要注意节制)以区分不同的函数组,
在一堆只有一行的函数之间不要使用空行(比如一些函数的空实现)
在函数内部使用空行,来标识不同的逻辑单元
5import
在独立的行中导入不同的包
但从一个包中添加不同的模块或者函数也是允许的:一个包中可添加多个模块或函数
import文件应当总是位于文件的首部,仅在模块备注和文档之后,在模块的全局变量和常量之前的位置
6import文件的顺序:
1. 标准库(如sys、os)
2. 相关的第三方的库(如numpy、pandas、matplotlib)
3. 自定义的.py文件或者自定义的库
以组的形式标识上述三种import文件,也即是用一个空行隔开
推荐使用绝对路径包含,因为可读性更好,并且不易出错。
7字符串
在python中,不对单引号和双引号作区分,PEP的代码规范也不对此有所推荐。任选其一,统一使用即可。然而,当一个字符串包含单引号或者双引号时,使用另外一种方式避免转义符(\)的使用,以提高可读性。
表达式中的空格
8切片中的冒号
在切片中冒号可视为一个二元操作符(binary operator),两边应用等数量的空格。
9其他的建议
总是在如下的二元操作符的两边使用单空格:
赋值:=
增量赋值:+=, -=
比较:==, <, >, !=, <>, in , is
布尔:and, or, not
不要使用空格,当被用来标识一个关键字参数(使用函数)或者一个默认参数赋值(定义函数)
10文档
为所有公共模块或者函数、类以及方法编写文档。不必为非公共方法编写doc文档,但应有一个注释描述算法的功能,这条注释应当出现在def之后
结尾的"""应当独占一行
基本定义:结构体,通俗讲就像是打包封装,把一些有共同特征(比如同属于某一类事物的属性,往往是某种业务相关属性的聚合)的变量封装在内部,通过一定方法访问修改内部变量。具体一点说,结构体是让一些很散的数据变得很整,不管是网络传输,还是函数传参,还是为了便于你肉眼管理。
一个函数,你想传入一个参数void func(),就需要改一下函数定义,加一个数据类型和数据名void func(int i);又想加一个参数,又改一遍void func(int i,double b);如此往复。但是用一个结构体(或者类对象)传入,这个函数定义就可以不改动了,只改结构体就好了,比如一个游戏,你的人物属性有成百上千,你只需要修改你的类与结构体成员就好了
**占用内存空间**
struct结构体,在**结构体**定义的时候不能申请内存空间,不过如果是**结构体变量**,声明的时候就可以分配
日常数据处理中,经常需要压缩数据文件,减小传输带宽,方便分享和存储,整理gz、tar.gz、zip三种格式,一般场景中的压缩解压使用记录。
zip是压缩格式的一种。
.tar.gz其实上是2个工具。tar是打包工具,把很多文件打包成一个文件,gz是压缩格式。
tar.gz
- tar.gz是linux下常用文件或文件夹打包和压缩方式,它既支持打包,也支持压缩,linux下应用广泛。
常用命令 打包文件,不压缩:tar -cvf 压缩文件名.tar 待压缩文件夹 带压缩文件 释放打包文件:tar -xvf 压缩文件名.tar 压缩文件:tar -czvf 压缩文件名.tar.gz 待压缩文件夹 带压缩文件 解压文件:tar -zxvf 压缩文件名.tar.gz 解压到指定目录:tar -zxvf 压缩文件 -C 目录 压缩指定目录下文件,并删除源文件:tar -C 目录 -czf 压缩文件名.tar.gz 路径下源文件名 --remove-files 不解压查看压缩包内容:tar -tvf 压缩包.tar.gz
gz gz是liunx常用文件压缩方式,仅支持压缩文件,无法无法文件夹,常tar配合使用,tar将多个文件或文件夹打包成文件,再使用gz进行压缩。 常用命令 压缩文件并删除源文件:gzip 文件名 输出压缩文件名为:文件名.gz 压缩文件保留源文件:gizp -c 文件路径文件 > 输出文件名.gz 可自定义输出压缩包名 解压文件并删除压缩文件:gunzip 文件名.gz 解压后文件名默认压缩文件名去除.gz部分 解压文件保留原文件:gunzip -c 文件名.gz > 文件路径 可自定义输出文件名 查看压缩包内容:zcat 文件名.gz
zip window常用压缩格式,兼容性好。 常用命令 压缩目录下文件和文件夹:zip -qr 文件名.zip 文件路径 解压后包含文件路径末尾文件夹 解压文件夹:unzip 文件名.zip 压缩文件不包含上层目录;zip -pj 压缩文件名 文件路径 总结 以上压缩命令介绍不够全面,主要是一些工作中实际应用,如不包含目录压缩,或删除原文件压缩。
python manage.py inspectdb > ./APP名称/models.py
-
ps(Process Status)看当前终端有哪些进程
常用:-f/-ef查看更多信息,-L显示进程中的线程ID
-
查找指定进程格式:
ps -ef | grep 进程关键字
pstree以树状图形式显示进程之间的关系
-
kill结束或挂起一个进程:
kill PID 结束进程 kill -9 PID强制结束 -stop 挂起进程 -
&后台执行命令(后台不会影响当前终端)
默认在前台执行,终端会等待当前进程结束
-
jobs显示当前终端任务
bg切换到后台 fg切换到前台 -
top查看cpu利用率
一秒刷新一次 q退出 -
创建用户(管理员权限)
useradd (用户名)添加一个新用户或更新默认新用户信息
用户信息:名字 uid 组信息:组信息 gid 密码:密文etc/passwd 分别存到三个文件中 -
userdel删除用户
不能登录需要删除的用户删除(自己不能删自己)
-
passwd修改密码
KVM虚拟机网络配置的两种方式:NAT方式和Bridge方式。
客户机安装完成后,需要为其设置网络接口,以便和主机网络,客户机之间的网络通信。事实上,如果要在安装时使用网络通信,需要提前设置客户机的网络连接。
KVM 客户机网络连接有两种方式:
用户网络(User Networking):让虚拟机访问主机、互联网或本地网络上的资源的简单方法,但是不能从网络或其他的客户机访问客户机,性能上也需要大的调整(NAT方式)
虚拟网桥(Virtual Bridge):这种方式要比用户网络复杂一些,但是设置好后客户机与互联网,客户机与主机之间的通信都很容易。(Bridge方式)
nat模式
NAT方式适用于桌面主机的虚拟化。
NAT模式中,就是让虚拟机借助NAT(网络地址转换)功能,通过宿主机器所在的网络来访问公网。
NAT模式中,虚拟机的网卡和物理网卡的网络,不在同一个网络,虚拟机的网卡,是提供的一个虚拟网络。
NAT和桥接的比较:
(1) NAT模式和桥接模式虚拟机都可以上外网。
(2) 由于NAT的网络在一个虚拟网络里,所以局域网其他主机是无法访问虚拟机的,而宿主机可以访问虚拟机,虚拟机可以访问局域网的所有主机,因为真实的局域网相对于NAT的虚拟网络,就是NAT的虚拟网络的外网,不懂的人可以查查NAT的相关知识。
(3) 桥接模式下,多个虚拟机之间可以互相访问;NAT模式下,多个虚拟机之间也可以相互访问。
如果你建一个虚拟机,只是给自己用,不需要给局域网其他人用,那么可以选择NAT,毕竟NAT模式下的虚拟系统的TCP/IP配置信息是由VMnet8(NAT)虚拟网络的DHCP服务器提供的,只要虚拟机的网路配置是DHCP,那么你不需要进行任何其他的配置,只需要宿主机器能访问互联网即可,就可以让虚拟机联网了。

bridge模式
Bridge方式适用于服务器主机的虚拟化。
Bridge方式原理
Bridge方式即虚拟网桥的网络连接方式,是客户机和子网里面的机器能够互相通信。可以使虚拟机成为网络中具有独立IP的主机。
桥接网络(也叫物理设备共享)被用作把一个物理设备复制到一台虚拟机。网桥多用作高级设置,特别是主机多个网络接口的情况。
关注Linux的系统状态,主要从两个角度出发:
一个角度是系统正在运行什么服务(ps命令);
另外一个就是有什么连接或服务可用(netstat命令)。
netstat还可以显示ps无法显示的、从inetd或xinetd中运行的服务,比如telnet等。
1.1、ps -ef | grep详解
ps命令将某个进程显示出来
grep命令是查找
中间的**|**是管道命令 是指ps命令与grep同时执行
PS是LINUX下最常用的也是非常强大的进程查看命令
ps -e 此参数的效果和指定"A"参数相同。
ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
grep命令是查找,是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
以下这条命令是检查java 进程是否存在:ps -ef |grep java
字段含义如下:
UID PID PPID C STIME TTY TIME CMD
zzw 14124 13991 0 00:38 pts/0 00:00:00 grep --color=auto dae
UID :程序被该 UID 所拥有
PID :就是这个程序的 ID
PPID :则是其上级父程序的ID
C :CPU使用的资源百分比
STIME :系统启动时间
TTY :登入者的终端机位置
TIME :使用掉的CPU时间。
CMD :所下达的是什么指令
1.2 ps -aux | grep命令
ps是显示当前状态处于running的进程,grep表示在这些里搜索,而ps aux是显示所有进程和其状态。
$ ps aux | grep amoeba 查到amoeba的进程
ps aux输出格式:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
格式说明:
USER: 行程拥有者
PID: pid
%CPU: 占用的 CPU 使用率
%MEM: 占用的记忆体使用率
VSZ: 占用的虚拟记忆体大小
RSS: 占用的记忆体大小
TTY: 终端的次要装置号码 (minor device number of tty)
STAT: 该行程的状态,linux的进程有5种状态:
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
注: 其它状态还包括W(无驻留页), <(高优先级进程), N(低优先级进程), L(内存锁页).
START: 行程开始时间
TIME: 执行的时间
COMMAND:所执行的指令
1)ps a 显示现行终端机下的所有程序,包括其他用户的程序。 2)ps -A 显示所有程序。 3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。 4)ps -e 此参数的效果和指定"A"参数相同。 5)ps e 列出程序时,显示每个程序所使用的环境变量。 6)ps f 用ASCII字符显示树状结构,表达程序间的相互关系。 7)ps -H 显示树状结构,表示程序间的相互关系。 8)ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。 9)ps s 采用程序信号的格式显示程序状况。 10)ps S 列出程序时,包括已中断的子程序资料。 11)ps -t 指定终端机编号,并列出属于该终端机的程序的状况。 12)ps u 以用户为主的格式来显示程序状况。 13)ps x 显示所有程序,不以终端机来区分。
netstat -apn命令
netstat -anp查看端口占用情况
-a,显示所有
-n,不用别名显示,只用数字显示
-p,显示进程号和进程名
行为式验证码(触发式,嵌入式,弹出式)
智能无感知(极致用户体验,多维度收集环境信息,用户只需轻点即可通过验证)
滑动拼图(创新行为式验证,轻松一滑完成拼图,体验极佳,秒速通过验证)
文字点选(顺序点击图中文字,全新行为验证,安全性极高,保障验证安全)
图标点选(顺序点击图中图标,保证高安全级别的同时,完美适配海外版)
推理拼图(拖动交换图块复原图片,完整性推理结合行为轨迹,保障验证安全)
短信上行(感知威胁的终极验证方式,发送随机数字至指定平台方可验证成功)
语序点选(根据中文语义,按顺序点击图中文字,适用高安全要求场景)
空间推理(逻辑解题能力结合3D立体元素识别能力,适用高安全要求场景)
语音验证(听一段音频,将听到的内容输入框中进行验证)
手势验证 (这里的变量主要指用户绘制手势相对于系统给定手势的变化率)
用途:注册环节|短信防刷|登录环节|提交环节|投票环节|垃圾邮件
触发式:鼠标移入验证条后显示验证拼图,轻松接入,不影响网页原有的排版和美观
嵌入式:拼图验证区域直接完整嵌入网页,清晰直观,便于用户使用和广告宣传
弹出式:绑定自有验证按钮效果,与自有业务样式完美融合
字符验证码的破解流程大致分为降噪、二值化和OCR识别三个步骤。降噪是尽可能了去除掉用于干扰识别的点、线等非字符。二值化是忽略了颜色的干扰,将任意色彩的验证字符图都转化成黑白两色。OCR环节则根据特征库对比验证图匹配出最合适的对应字符。手势验证的图像干扰方式采用了路径轨迹取色与部分背景色一致且不影响人类识别的原则。
Redis 一共支持 5 种基础数据结构:
- string:字符串
- list:列表
- hash:字典
- set:集合
- zset:有序集合
(1)Redis 默认会创建 16 个数据库:redisDb,每个数据库之间数据隔离。
(2)Redis 默认为每个客户端分配第 0 号索引的 redisDb,客户端可以调用 select 命令切换需要使用的数据库。
(3)redisDb 内部采用了 HashTable 结构存放数据。
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis的优点:
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
(1) 准备基准字形描述信息。
(2) 访问目标网页。
(3) 从目标网页中读取字体编码字符。
(4) 下载 WOFF 文件并用 Python 代码打开。
(5) 根据字体编码字符找到 WOFF 文件中的字形轮廓信息。
(6) 将该字形轮廓信息与基准字形轮廓信息进行对比。
(7) 得出对比结果。
1.先明确识别步骤:
首先,模拟点击验证按钮,然后识别活动缺口的位置,最后,模拟拖动滑块。
第一步,我们可以直接利用selienium模拟点击按钮。
第二步的话,需要用到图像的相关处理方法。实现一个边缘检测算法来找出缺口的位置,而对于这种极验验证码,我们可以利用和原图对比检测的方式来识别缺口的位置,因为在没有滑动滑块之前,缺口并没有呈现。我们可以同时获取两张图片。设定一个 对比阈值,然后遍历两张图片,找出相同位置像素RGB差距超过此阈值的像素点,那么此像素点的位置就是缺口的位置。
第三步,其中的坑比较多。极验验证码增加了机器轨迹识别,匀速运动,随机速度等方法都不能通过验证,只有完全模拟人的移动轨迹才可以通过验证。人的运动轨迹一般是先急加速再减速,我们需要模拟这个过程才能成功。
2.有了思路,我们就可以开始用程序来实现它了。大的方面,主要包括这几个步骤。
第一步,初始化,在这里我们先初始化 一些selenium的 配置及一些参数的配置。
第二步,就是模拟点击了,这里主要是利用selenium模块模拟浏览器对网页进行操作。
第三步,就该识别缺口的位置了。首先获取前后两张图片,得到其所在位置和宽高,然后获取整个网页的截图,图片裁切下来即可。最后一步,模拟拖动,经过多次试验,得出一个结论,那就是完全模拟加速减速的过程通过了验证。前段作匀加速,后段作匀减速运动,利用物理学的加速度公式即可完成验证。
因为极验做了行为验证,所以我们得尽量模拟生物行为,防止被识别。
所以这里我们的滑动轨迹和滑动速度等行为都进行了控制
滑动速度:加速公式:v = v0+at,到达重点控制让加速变慢
滑动轨迹:滑动过程中让鼠标上下轻微抖动,不是平稳的滑动。
加了一个纠错行为,就是滑动过去一点再滑回来,依然是为了防止极验识别。
滑动过程中鼠标是拖住不松手的,等动作结束之后才能释放鼠标。这些selenium都有。-
什么是版本控制?
版本控制(Revision control)是一种在开发的过程中用于管理我们对文件、目录或工程等内容的修改历史,方便查看更改历史记录,备份以便恢复以前的版本的软件工程技术。简单来说就是用于管理多人协同开发项目的技术。
-
为什么要有版本控制? 没有进行版本控制或者版本控制本身缺乏正确的流程管理,在软件开发过程中将会引入很多问题,如软件代码的一致性、软件内容的冗余、软件过程的事物性、软件开发过程中的并发性、软件源代码的安全性,以及软件的整合等问题。无论是工作还是学习,或者是自己做笔记,都经历过这样一个阶段!我们就迫切需要一个版本控制工具。(多人开发就必须要使用版本控制)
-
使用版本控制之后可以给你带来的一些便利:
● 实现跨区域多人协同开发 ● 追踪和记载一个或者多个文件的历史记录 ● 组织和保护你的源代码和文档 ● 统计工作量 ● 并行开发、提高开发效率 ● 跟踪记录整个软件的开发过程 ● 减轻开发人员的负担,节省时间,同时降低人为错误
-
版本控制分类
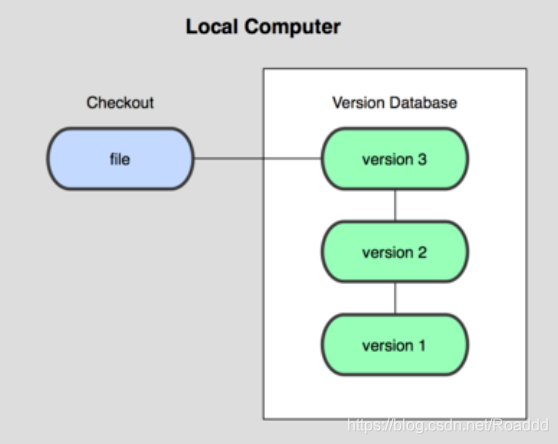
4.1. 本地版本控制 记录文件每次的更新,可以对每个版本做一个快照,或是记录补丁文件,适合个人用,如RCS。
4.2 集中版本控制 SVN 所有的版本数据都保存在服务器上,协同开发者从服务器上同步更新或上传自己的修改。
所有的版本数据都存在服务器上,用户的本地只有自己以前所同步的版本,如果不连网的话,用户就看不到历史版本,也无法切换版本验证问题,或在不同分支工作。而且,所有数据都保存在单一的服务器上,有很大的风险这个服务器会损坏,这样就会丢失所有的数据,当然可以定期备份。代表产品:SVN、CVS、VSS。4.3. 分布式版本控制 Git 所有版本信息仓库全部同步到本地的每个用户,这样就可以在本地查看所有版本历史,可以离线在本地提交,只需在连网时push到相应的服务器或其他用户那里。由于每个用户那里保存的都是所有的版本数据,只要有一个用户的设备没有问题就可以恢复所有的数据,但这增加了本地存储空间的占用。
Git的优势就是:每个人都拥有全部的代码,可以避免一些安全隐患。不会因为服务器孙环或者网络问题,造成不能工作的情况。
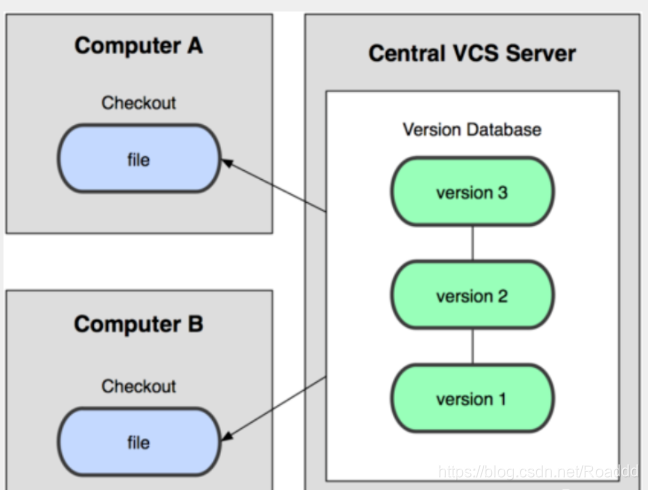
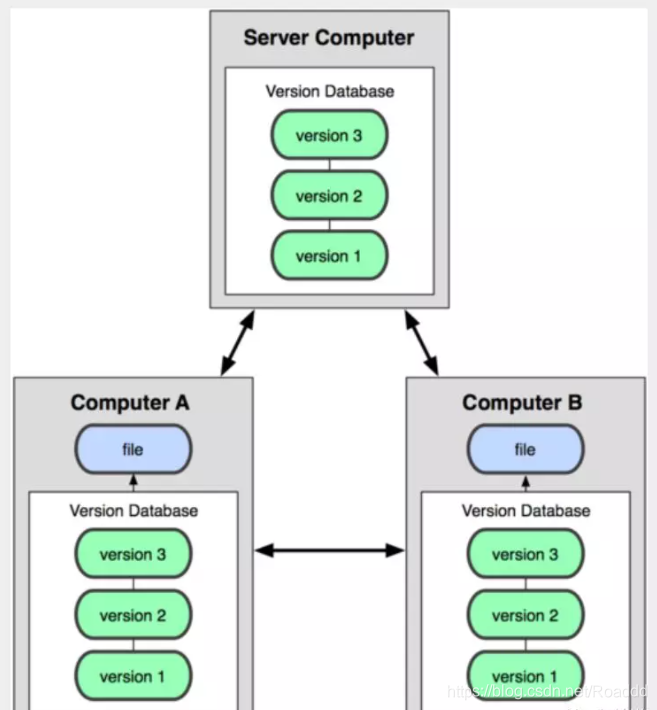
4.Git和SVN的主要区别 SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而工作的时候,用的都是自己的电脑,所以首先要从中央服务器得到最新的版本,然后工作,完成工作后,需要把自己做完的活推送到中央服务器。集中式版本控制系统是必须联网才能工作,对网络带宽要求较高。 Git是分布式版本控制系统,没有中央服务器,每个人的电脑就是一个完整的版本库,工作的时候不需要联网了,因为版本都在自己电脑上。协同的方法是这样的:比如说自己在电脑上改了文件A,其他人也在电脑上改了文件A,这时,你们两之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。Git可以直接看到更新了哪些代码和文件!
生成器是什么 生成器继承于迭代器,故生成器有迭代器的特性,是一个可以通过循环获取数据的对象,但生成器保存的是生成数据的算法,不保存数据,迭代器是一组数据。python已有的列表生成器 list(range(1,11))无法解决内存限制的问题,所有产生的数据都在内存里,如果数据很大就会有内存溢出的问题,生成器是保存了生成数据的算法,不保存数据,同时也会保存游标的位置,记录当前取到哪个数据,下次继续从游标位置获取新数据,可以通过next()方法,一直通过生成器生成新数据,而不占用内存。
生成器用到的关键字yield yield用于给生成器函数返回数据,遇到yield后,函数暂停执行,将yield的值返回给调用方,下一次遇到next()时,再继续接着上一次执行的位置继续执行
三次握手
刚开始客户端处于 closed 的状态,服务端处于 listen 状态。然后 1、第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 SYN_Send 状态。
2、第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s),同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
3、第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 establised 状态。
4、服务器收到 ACK 报文之后,也处于 establised 状态,此时,双方以建立起了链接。

三次握手的作用 三次握手的作用也是有好多的,多记住几个,保证不亏。例如: 1、确认双方的接受能力、发送能力是否正常。 2、指定自己的初始化序列号,为后面的可靠传送做准备。 3、如果是 https 协议的话,三次握手这个过程,还会进行数字证书的验证以及加密密钥的生成到。
单单这样还不足以应付三次握手,面试官可能还会问一些其他的问题,例如:
1、(ISN)是固定的吗? 三次握手的一个重要功能是客户端和服务端交换ISN(Initial Sequence Number), 以便让对方知道接下来接收数据的时候如何按序列号组装数据。
如果ISN是固定的,攻击者很容易猜出后续的确认号,因此 ISN 是动态生成的。
2、什么是半连接队列 服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于SYN-ACK 重传次数的问题: 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传,如果重传次数超 过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s, 2s, 4s, 8s, …
3、三次握手过程中可以携带数据吗
很多人可能会认为三次握手都不能携带数据,其实第三次握手的时候,是可以携带数据的。也就是说,第一次、第二次握手不可以携带数据,而第三次握手是可以携带数据的。为什么这样呢?大家可以想一个问题,假如第一次握手可以携带数据的话,如果有人要恶意攻击服务器,那他每次都在第一次握手中的 SYN 报文中放入大量的数据,因为攻击者根本就不理服务器的接收、发送能力是否正常,然后疯狂着重复发 SYN 报文的话,这会让服务器花费很多时间、内存空间来接收这些报文。也就是说,第一次握手可以放数据的话,其中一个简单的原因就是会让服务器更加容易受到攻击了。而对于第三次的话,此时客户端已经处于 established 状态,也就是说,对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据页没啥毛病。
四次挥手
刚开始双方都处于 establised 状态,假如是客户端先发起关闭请求,则:
1、第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。
2、第二次握手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。
3、第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
4、第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态
5、服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。

这里特别需要主要的就是TIME_WAIT这个状态了,这个是面试的高频考点,就是要理解,为什么客户端发送 ACK 之后不直接关闭,而是要等一阵子才关闭。这其中的原因就是,要确保服务器是否已经收到了我们的 ACK 报文,如果没有收到的话,服务器会重新发 FIN 报文给客户端,客户端再次收到 ACK 报文之后,就知道之前的 ACK 报文丢失了,然后再次发送 ACK 报文。
至于 TIME_WAIT 持续的时间至少是一个报文的来回时间。一般会设置一个计时,如果过了这个计时没有再次收到 FIN 报文,则代表对方成功就是 ACK 报文,此时处于 CLOSED 状态。
LISTEN - 侦听来自远方TCP端口的连接请求;
SYN-SENT -在发送连接请求后等待匹配的连接请求;
SYN-RECEIVED - 在收到和发送一个连接请求后等待对连接请求的确认;
ESTABLISHED- 代表一个打开的连接,数据可以传送给用户;
FIN-WAIT-1 - 等待远程TCP的连接中断请求,或先前的连接中断请求的确认;
FIN-WAIT-2 - 从远程TCP等待连接中断请求;
CLOSE-WAIT - 等待从本地用户发来的连接中断请求;
CLOSING -等待远程TCP对连接中断的确认;
LAST-ACK - 等待原来发向远程TCP的连接中断请求的确认;
TIME-WAIT -等待足够的时间以确保远程TCP接收到连接中断请求的确认;
CLOSED - 没有任何连接状态;

为何要四次分手呢?
那四次分手又是为何呢?TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,这就意味着,当主机1发出`FIN`报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回`ACK`报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;当主机2也发送了`FIN`报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。如果要正确的理解四次分手的原理,就需要了解四次分手过程中的状态变化。
我国共有23个省、5个自治区、4个直辖市、2个特别行政区。
23个省及简称:
黑龙江省(黑)、吉林省(吉)、辽宁省(辽)、河北省(冀)、河南省(豫)、山东省(鲁)、山西省(晋)、陕西省(陕或秦)、甘肃省(甘或陇)、青海省(青)、四川省(川或蜀)、湖北省(鄂)、湖南省(湘)、江西省(赣)、安徽省(皖)、江苏省(苏)、浙江省(浙)、福建省(闽)、台湾省(台)、广东省(粤)、海南省(琼)、云南省(云或滇)、贵州省(贵或黔)。
4个直辖市及简称:北京市(京)、天津市(津)、上海市(沪)、重庆市(渝)。
5个自治区及简称:内蒙古自治区(内蒙古)、宁夏回族自治区(宁)、新疆维吾尔自治区(新)、西藏自治区(藏)、广西壮族自治区(桂)。
2个特别行政区及简称:香港特别行政区(港)、澳门特别行政区(澳)。

简言之,“/” 在超链接被点击后会被解析成当前服务器的主机地址
比如当前页面全路径为:http://localhost:8080/view/index.html, 此页面中有两个超链接
链接1:
<a href="monster/100/king">@PathVariable-路径变量 【monster/100/king】</a><hr/>绝对路径
链接2:
<a href="/monster/100/king">@PathVariable-路径变量 【/monster/100/king】</a><hr/>相对路径
上述两个链接在实际点击时会发送不同的 URL 请求,具体情况如下:
-
链接1,不加“/”,点击后访问的路径如下: http://localhost:8080/view/monster/100/king //相当于拼接了当前路径的前半段【http://localhost:8080/view/】
-
链接2,加“/”,点击后访问的路径如下: http://localhost:8080/monster/100/king //相当于只拼接了主机名【http://localhost:8080/】
浏览器向DNS服务器发出解析域名的请求;
DNS服务器将"www.baidu.com"域名解析为对应的IP地址,并返回给浏览器;
浏览器与百度服务器进行三次握手,建立TCP连接(默认端口80);
浏览器发出HTTP请求报文;
服务器回复HTTP响应报文;
浏览器解析响应报文,渲染HTML内容,并显示在页面上;
收发报文结束,释放TCP连接,执行四次挥手。
1、先找DNS服务器解析域名,DNS服务器解析www.baidu.com这个域名后返回一个ip地址,比如172.194.26.108,这就是告诉你,你要访问www.baidu.com这个域名你就直接访问这个172.194.26.108就可以了。
2、接着会判断我本地浏览器的192.168.31.158这个ip和这个返回的172.194.26.108这个ip是不是一个子网的,具体是这么做的,用子网掩码255.255.255.0对两个ip地址做与运算,看运算后的结果的二进制前几位是不是一样的,来判断是不是一个子网。发现不是一个子网的,这个时候本地电脑就要打包一个数据包走交换机通过以太网协议将数据包广播给网关,其实就是路由器192.168.31.1。而这个数据包,我们按下f12看下network其实是发出了一个get的Http请求。这个数据包是先按照应用层的http协议,封装一个应用层数据包,数据包里就放了Http请求报文,这个就是网络模型中应用层干的事了。
3、接着就是跑到传输层了,这个层是tcp协议,这个协议会让你设置端口,发送方的端口随机选一个,接收方的端口一般是默认的80端口,这个时候会把应用层数据包给封装到tcp数据包中去,会加一个tcp头,tcp头里放了端口号信息。
4、接着跑到网络层来了,走ip协议,这个时候会把tcp头和tcp数据包,放到ip数据包里去,然后再搞一个ip头,ip头里放本机和目标机器的Ip地址。这里本机是192.168.31.158,目标机器是172.194.26.108。
5、接着是数据链路层,这块走以太网协议,把ip头和ip数据包封道以太网数据包里去,然后再加一个以太网数据包的头,头里放了本季网卡mac地址,和网关的mac地址。但是以太网数据包的限制是1500个字节,假设这个时候数据包都5000个字节了,那么需要将ip数据包切割一下。这个时候一个以太网数据包要切割为4个数据包,每个数据包包含了以太网头、ip头和切割后的ip数据包,4个数据包的大小分别是1500、1500、1500、500。ip头里包含了每个数据包的序号。这4个以太网数据包都会通过交换机发到你的路由器上,然后你的路由器是可以联通别的子网的,这个时候你的路由器就会转发到别的子网,也可能是某个路由器里去,然后以此类推,N多个路由器转发之后,就会跑到百度的某台服务器,接收到4个以太网数据包。
6、百度服务器接收到4个以太网数据包以后,根据ip头的序号,把4个以太网数据包里的ip数据包给拼起来,就还原成一个完整的ip数据包了。接着就会从ip数据包里拿出来tcp数据包,再从tcp数据包里取出来http数据包,读取出来http数据包里的各种哦功能协议内容,接着就是做一些处理,然后再把响应结果封装成http响应报文,封装在http数据包里,再一样的过程,封装在tcp数据包,封装ip数据包,封装以太网数据包,接着通过网管给发回去。
1、应用层:HTTP(WWW访问协议),DNS(域名解析服务)
2、 传输层:TCP(为HTTP提供可靠的数据传输),UDP(DNS使用UDP传输)
3、网络层:IP(IP数据数据包传输和路由选择),ICMP(提供网络传输过程中的差错检测),ARP(将目的主机的IP地址映射成MAC地址)
HTTP请求报文在传输层被封装为TCP报文段——把HTTP会话请求分成报文段,添加源和目的端口;
TCP报文段在网络层被封装为IP数据包——然后使用IP层的IP地址查找目的主机;
客户端通过这个IP地址找到客户端到服务器的路径。
服务器使用80端口监听客户端的请求,客户端由系统随机选择一个端口如5000,与服务器进行交换数据。服务器把相应的请求返回给客户端的5000端口。
客户端的网络层不用关心应用层或者传输层的东西,其主要工作是:通过查找路由表,来确定通过哪个路径到达目的主机。
客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定IP地址的MAC地址,然后发送ARP请求查找目的地址,如果得到回应后就可以使用ARP的请求应答交换的IP数据包现在就可以传输了,然后发送IP数据包到达服务器的地址。
在上面所描述的访问网站的过程中,第一个环节就是DNS解析域名并返回IP,但实际上浏览器访问DNS服务器的过程还包含许多步骤:
首先DNS服务器通常与本地客户端(假设为图中192.168.1.1)不在同一个网络中,则需要通过网关转发客户端对DNS的请求数据
发送ARP数据包获取默认网关(192.168.1.254)的 mac 地址
然后将请求DNS的数据包发送给默认网关
默认网关拥有转发数据的能力,把数据转发给路由器
路由器根据自己的路由协议,来选择一个合适的较快的路径转发数据给目的网关(192.168.2.254)
目的网关,把数据转发给 DNS 服务器
DNS 服务器查询解析出 www.baidu.com 对应的 ip 地址,并原路返回请求这个域名的客户端,至此,客户端才获得了百度的IP地址

面试时回答此类问题,先介绍两者的概念,再阐述两者的区别
TCP和UDP是OSI模型中的运输层中的协议。TCP提供可靠的通信传输,而UDP则常被用于让广播和细节控制交给应用的通信传输。
1.TCP(Transmission Control Protocol)的概念
TCP是一种面向连接的,提供可靠交付服务和全双工通信的,基于字节流的端到端的传输层通信协议。
TCP在传输数据之前必须先建立连接(TCP连接过程参见:https://blog.csdn.net/qq_38950316/article/details/81087809),数据传输结束后要释放连接。
每一条TCP连接只能有2个端点,故TCP不提供广播或多播服务。
TCP提供可靠交付,通过TCP连接传输的数据,无差错、不丢失、不重复、并且按序到达。
TCP是面向字节流的。虽然应用进程和TCP的交互是一次一个数据块(大小不等),但TCP把英语程序交下来的数据看成仅仅是一连串的无结构的字节流。TCP并不知道所传输的字节流的含义。
2 . UDP(User Data Protocol,用户数据报协议)
(1)UDP是一个非连接的协议,传输数据之前源端和终端不建立连接,当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。在发送端,UDP传送数据的速度仅仅是受应用程序生成数据的速度、计算机的能力和传输带宽的限制;在接收端,UDP把每个消息段放在队列中,应用程序每次从队列中读一个消息段。
(2) 由于传输数据不建立连接,因此也就不需要维护连接状态,包括收发状态等,因此一台服务机可同时向多个客户机传输相同的消息。
(3)UDP信息包的标题很短,只有8个字节,相对于TCP的20个字节信息包的额外开销很小。
(4) 吞吐量不受拥挤控制算法的调节,只受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制。
(5)UDP使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态表(这里面有许多参数)。
(6)UDP是面向报文的。发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付给IP层。既不拆分,也不合并,而是保留这些报文的边界,因此,应用程序需要选择合适的报文大小。
UDP应用场景:
1.面向数据报方式
2.网络数据大多为短消息
3.拥有大量Client
4.对数据安全性无特殊要求
5.网络负担非常重,但对响应速度要求高
- TCP与UDP区别总结:
1)、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2)、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3)、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制(),因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4)、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5)、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6)、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
在电脑上用netstat -ano命令可以看端口的使用情况。
TCP/IP传输层的作用
TCP/IP 的传输层位于应用层和网络层之间,为终端主机提供端到端的连接。TCP/IP 的传输层有TCP(Transfer Control Protocol,传输控制协议)和UDP(User Datagram Protocol,用户数据报协议)两种主要协议。TCP 和UDP 都基于相同的网络层协议IP。传输层协议的主要作用包括:
提供面向连接或无连接的服务:传输层协议定义了通信两端点之间是否需要建立可靠的连接关系。
维护连接状态:如果必须在通信前建立连接关系,传输层协议必须在其数据库中记录这种连接关系,并且通过某种机制维护连接关系,及时发现连接故障等。
对应用层数据进行分段和封装:应用层数据往往是大块的或持续的数据流,而网络只能发送长度有限的数据包,传输层协议必须在传输应用层数据之前将其划分成适当尺寸的段(segment),再交给IP 协议发送。
实现多路复用(Multiplexing):一个IP 地址可以标识一个主机,一对“源-目的”IP地址可以标识一对主机的通信关系,而一个主机上却可能同时有多个程序访问网络,因此传输层协议采用端口号(port number)来标识这些上层的应用程序,从而使这些程序可以复用网络通道。
可靠地传输数据:数据在跨网络传输过程中可能出现错误、丢失、乱序等种种问题,传输层协议必须能够检测并更正这些问题。
执行流量控制(flow control) :当发送方的发送速率超过接受方的接受速率时,或者当资源不足以支持数据的处理时,传输层负责将流量控制在合理的水平;反之,当资源允许时,传输层可以放开流量,使其增加到适当的水平。
在列表中查询值的时间复杂度高,因此采用字典来代替查询过程。字典的查询、删除、插入平均时间复杂度都是O(1)。
1、字典是通过哈希算法实现的,字典的key可以是str,int,tuple等不可变对象,不能是列表(可变,不可哈希);
2、python3.7之前字典是无序的;
Python3.6之前的无序字典
字典底层是维护一张哈希表,可以把哈希表看成一个列表,哈希表中的每一个元素又存储了哈希值(hash)、键(key)、值(value)3个元素。

3、字典的实现过程(python3.7之后):

3.1 哈希表和indices:
indices = [None, None, index, None, index, None, index] entries = [ [hash0, key0, value0], [hash1, key1, value1], [hash2, key2, value2] ] 3.2、hash(key)后得到的值与len(entries)-1做‘与’操作得到index(哈希出来的值通常很大,所以做‘与’操作)
3.3、indices中找到index对应的值,此时indices中存储的是key在entries的位置(len(entries))
3.4、解决冲突:python的哈希一般保证indices辅助表间隔取值【None,index,None,index】,使得冲突时能很快找到下一个值。
4、为什么新字典是有序的?
新字典的entries不再是稀疏的,而是由indices维护具体的位置,所以插入的值是有序的。
时间复杂度
字典的平均时间复杂度是O(1),因为字典是通过哈希算法来实现的,哈希算法不可避免的问题就是hash冲突,Python字典发生哈希冲突时,会向下寻找空余位置,直到找到位置。如果在计算key的hash值时,如果一直找不到空余位置,则字典的时间复杂度就变成了O(n)了。
常见的哈希冲突解决方法:
1 开放寻址法(open addressing)
开放寻址法中,所有的元素都存放在散列表里,当产生哈希冲突时,通过一个探测函数计算出下一个候选位置,如果下一个获选位置还是有冲突,那么不断通过探测函数往下找,直到找个一个空槽来存放待插入元素。
2 再哈希法
这个方法是按顺序规定多个哈希函数,每次查询的时候按顺序调用哈希函数,调用到第一个为空的时候返回不存在,调用到此键的时候返回其值。
3 链地址法
将所有关键字哈希值相同的记录都存在同一线性链表中,这样不需要占用其他的哈希地址,相同的哈希值在一条链表上,按顺序遍历就可以找到。
4 公共溢出区
其基本思想是:所有关键字和基本表中关键字为相同哈希值的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
(7条消息) Python字典底层实现原理_Generalzy的博客-CSDN博客_python字典原理
一、什么是索引 索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的特殊数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到需要的内容,索引就是为了避免数据库进行顺序查找.提高查找效率.。
索引(index):好比书的目录,用于加快查找的效率;
索引的作用:加快查找效率.减慢插入和删除,修改效率.(需要同步调整索引结果)
应用的场景主要是应用在查找很频繁,但是插入,删除,修改都不频繁的场景.[非常常见]
二、索引类型
Mysql索引大概有五种类型:
普通索引(INDEX):最基本的索引,没有任何限制
唯一索引(UNIQUE):与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引(PRIMARY):它 是一种特殊的唯一索引,不允许有空值。
全文索引(FULLTEXT ):可用于 MyISAM 表,mysql5.6之后也可用于innodb表, 用于在一篇文章中,检索文本信息的, 针对较大的数据,生成全文索引很耗时和空间。
联合(组合)索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
唯一索引:表上一个字段或者多个字段的组合建立的索引,这些字段组合起来能够确定唯一,允许存在空值(只允许存在一条空值)
最大的所用就是确保写入数据库的数据是唯一值。
提高查询速度
**非唯一索引:**表上一个字段或者多个字段的组合建立的索引,可以重复,不需要唯一 主键索引:(主索引)根据主键pk_clolum(length)建立索引,不允许重复,不允许空值; 聚合索引:表中记录的物理顺序与键值的索引顺序相同 非聚合索引:表中记录的物理顺序与键值的索引顺序无关 全文索引:在某个字段设置全文索引后,根据特定语法查找满足条件的字段; 普通索引:用表中的普通列构建的索引,没有任何限制 组合索引:用多个列组合 构建的索引,但是在使用过程中有诸多规则,遵循最左前缀原则,顺序至关重要 **Hash索引(Memory存储引擎)**是通过索引列的值计算出hashCode,之后在相应的物理位置存取索引列的值,由于hashCode的唯一性,因此Hash索引不能进行范围查找或者是顺序查找
四、索引的优缺点 优点 通过创建唯一索引可以保证数据库表中每一行数据的唯一性。 可以给所有的 MySQL 列类型设置索引。 可以大大加快数据的查询速度,减少IO次数,这是使用索引最主要的原因。 在实现数据的参考完整性方面可以加速表与表之间的连接。 在使用分组和排序子句进行数据查询时也可以显著减少查询中分组和排序的时
缺点 创建和维护索引组要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
索引需要占磁盘空间,除了数据表占数据空间以外,每一个索引还要占一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
当对表中的数据进行增加、删除和修改的时候,索引也要动态维护,这样就降低了数据的维护速度。
五、索引的使用建议 使用聚集索引的查询效率要比非聚集索引的效率要高,但是如果需要频繁去改变聚集索引的值,写入性能并不高,因为需要移动对应数据的物理位置。 非聚集索引在查询的时候可以的话就避免二次查询,这样性能会大幅提升。 不是所有的表都适合建立索引,只有数据量大表才适合建立索引,且建立在选择性高的列上面性能会更好 在where后使用or,导致索引失效(尽量少用or) 使用like ,like查询是以%开头,以%结尾不会失效 不符合最左原则 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引 5使用in导致索引失效 使用mysql内部函数导致索引失效,可能会导致索引失效。 如果MySQL估计使用索引比全表扫描更慢,则不使用索引
唯一索引和主键索引的具体区别 1:唯一性约束所在的列允许空值,但是主键约束所在的列不允许空值。 2:可以把唯一性约束放在一个或者多个列上,这些列或列的组合必须有唯一的。但是,唯一性约束所在的列并不是表的主键列。 3:唯一性约束强制在指定的列上创建一个唯一性索引。在默认情况下,创建唯一性的非聚簇索引,但是,也可以指定所创建的索引是聚簇索引。 4:建立主键的目的是让外键来引用. 5: 一个表最多只有一个主键,但可以有很多唯一键
序列化:把对象转化为可传输的字节的序列过程称为序列化
反序列化:把字节序列还原为对象的过程称为反序列化
为什么需要序列化?
序列化的最终目的是为了对象可以跨平台传输,和进行网络传输。而我们进行跨平台存储和网络传输的方式就是IO,而IO支持的数据格式就是字节数组。
因为我们单方面的只把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,所以我们必须在把对象转成字节数组的时候就制定一种规则,即序列化,那么我们从IO流里面读出数据的时候再以这种规则把对象还原回来,即反序列化。
如果我们要把一栋房子从一个地方运输到另一个地方去,序列化就是把房子拆成一个个砖块放在车子里,然后保留一张房子原来结构的图纸,反序列化就是我们把房子运输到目的地以后,根据图纸把一个个砖块还原成完整房子的过程。
什么时候使用序列化?
凡是需要进行跨平台存储的网络传输的数据,都需要进行序列化。
本质上存储和网络传输都需要经过把一个对象状态保存成一种跨平台识别的字节格式,然后其它的平台才可以通过字节信息解析还原对象信息
最常见的解释是:
a,b = b,a 中右侧是元组表达式,即 b,a 是一个两个元素的 tuple(a,b)。表达式左侧是两个待分配元素,而 = 相当于元组元素拆包赋值操作。
从字节码一窥交换变量
大家可能不太了解 Python 字节码。Python 解释器是一个基于栈的虚拟机。Python 解释器就是编译、解释 Python 代码的二进制程序。
虚拟机是一种执行代码的容器,相较于二进制代码具有方便移植的特点。而 Python 的虚拟机就是栈机器。
Python 中函数调用、变量赋值等操作,最后都转换为对栈的操作。这些对栈的具体操作,就保存在字节码里。
dis 模块可以反编译字节码,使其变成人类可读的栈机器指令。
d是daemon的缩写,说明它自己是个守护进程(daemon) ,它在后台运行,一般都是用来做服务端程序。 如mysqld代表是mysql数据库服务的守护进程。
守护进程是运行在Linux服务器后台的一种服务程序。现在比较常用 是 service 这个词。 它周期性地执行某种任务或等待处理某些发生的事件。 Linux的大多数服务就是用守护进程实现的。 比如: xinetd 提供网络服务, sshd 提供 ssh登录服务, vsftpd 提供ftp服务器, httpd提供Web服务 等等。 一般是daemon,指后台进程的意思。大部分这种程序应该是服务类型的程序。
总体来说设计模式分为三大类:
一、创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
二、结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
三、行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
1、工厂方法模式:
定义一个用于创建对象的接口,让子类决定实例化哪一个类。FactoryMethod使一个类的实例化延迟到其子类。
工厂模式有一个问题就是,类的创建依赖工厂类,也就是说,如果想要拓展程序,必须对工厂类进行修改,这违背了闭包原则,所以,从设计角度考虑,有一定的问题,这就用到工厂方法模式。
创建一个工厂接口和创建多个工厂实现类,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
2、抽象工厂模式:
提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。抽象工厂需要创建一些列产品,着重点在于"创建哪些"产品上,也就是说,如果你开发,你的主要任务是划分不同差异的产品线,并且尽量保持每条产品线接口一致,从而可以从同一个抽象工厂继承。
3、单例模式:
单例对象(Singleton)是一种常用的设计模式。在Java应用中,单例对象能保证在一个JVM中,该对象只有一个实例存在。这样的模式有几个好处:
(1)某些类创建比较频繁,对于一些大型的对象,这是一笔很大的系统开销。
(2)省去了new操作符,降低了系统内存的使用频率,减轻GC压力。
(3)有些类如交易所的核心交易引擎,控制着交易流程,如果该类可以创建多个的话,系统完全乱了。(比如一个军队出现了多个司令员同时指挥,肯定会乱成一团),所以只有使用单例模式,才能保证核心交易服务器独立控制整个流程。
4、建造者模式:
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
5、原型模式:
原型模式虽然是创建型的模式,但是与工程模式没有关系,从名字即可看出,该模式的思想就是将一个对象作为原型,对其进行复制、克隆,产生一个和原对象类似的新对象。本小结会通过对象的复制,进行讲解。在Java中,复制对象是通过clone()实现的,先创建一个原型类。
6、适配器模式:
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,目的是消除由于接口不匹配所造成的类的兼容性问题。主要分为三类:类的适配器模式、对象的适配器模式、接口的适配器模式。
7、装饰器模式:
顾名思义,装饰模式就是给一个对象增加一些新的功能,而且是动态的,要求装饰对象和被装饰对象实现同一个接口,装饰对象持有被装饰对象的实例。
8、代理模式:
代理模式就是多一个代理类出来,替原对象进行一些操作,比如我们在租房子的时候回去找中介,为什么呢?因为你对该地区房屋的信息掌握的不够全面,希望找一个更熟悉的人去帮你做,此处的代理就是这个意思。
9、外观模式:
外观模式是为了解决类与类之家的依赖关系的,像spring一样,可以将类和类之间的关系配置到配置文件中,而外观模式就是将他们的关系放在一个Facade类中,降低了类类之间的耦合度,该模式中没有涉及到接口。
10、桥接模式:
桥接模式就是把事物和其具体实现分开,使他们可以各自独立的变化。桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化,像我们常用的JDBC桥DriverManager一样。
JDBC进行连接数据库的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不用动,原因就是JDBC提供统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了。
11、组合模式:
组合模式有时又叫部分-整体模式在处理类似树形结构的问题时比较方便。使用场景:将多个对象组合在一起进行操作,常用于表示树形结构中,例如二叉树,数等。
12、享元模式:
享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用。
13、策略模式:
策略模式定义了一系列算法,并将每个算法封装起来,使其可以相互替换,且算法的变化不会影响到使用算法的客户。需要设计一个接口,为一系列实现类提供统一的方法,多个实现类实现该接口,设计一个抽象类(可有可无,属于辅助类),提供辅助函数。
14、模板方法模式:
一个抽象类中,有一个主方法,再定义1...n个方法,可以是抽象的,也可以是实际的方法,定义一个类,继承该抽象类,重写抽象方法,通过调用抽象类,实现对子类的调用。
15、观察者模式:
观察者模式很好理解,类似于邮件订阅和RSS订阅,当我们浏览一些博客或wiki时,经常会看到RSS图标,就这的意思是,当你订阅了该文章,如果后续有更新,会及时通知你。
其实,简单来讲就一句话:当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化!对象之间是一种一对多的关系。
16、迭代子模式:
顾名思义,迭代器模式就是顺序访问聚集中的对象,一般来说,集合中非常常见,如果对集合类比较熟悉的话,理解本模式会十分轻松。这句话包含两层意思:一是需要遍历的对象,即聚集对象,二是迭代器对象,用于对聚集对象进行遍历访问。
17、责任链模式:
责任链模式,有多个对象,每个对象持有对下一个对象的引用,这样就会形成一条链,请求在这条链上传递,直到某一对象决定处理该请求。但是发出者并不清楚到底最终那个对象会处理该请求,所以,责任链模式可以实现,在隐瞒客户端的情况下,对系统进行动态的调整。
18、命令模式:
命令模式的目的就是达到命令的发出者和执行者之间解耦,实现请求和执行分开。
19、备忘录模式:
主要目的是保存一个对象的某个状态,以便在适当的时候恢复对象,个人觉得叫备份模式更形象些,通俗的讲下:假设有原始类A,A中有各种属性,A可以决定需要备份的属性,备忘录类B是用来存储A的一些内部状态,类C呢,就是一个用来存储备忘录的,且只能存储,不能修改等操作。
20、状态模式:
状态模式在日常开发中用的挺多的,尤其是做网站的时候,我们有时希望根据对象的某一属性,区别开他们的一些功能,比如说简单的权限控制等。
21、访问者模式:
访问者模式把数据结构和作用于结构上的操作解耦合,使得操作集合可相对自由地演化。访问者模式适用于数据结构相对稳定算法又易变化的系统。因为访问者模式使得算法操作增加变得容易。
若系统数据结构对象易于变化,经常有新的数据对象增加进来,则不适合使用访问者模式。访问者模式的优点是增加操作很容易,因为增加操作意味着增加新的访问者。访问者模式将有关行为集中到一个访问者对象中,其改变不影响系统数据结构。其缺点就是增加新的数据结构很困难。
22、中介者模式:
中介者模式也是用来降低类类之间的耦合的,因为如果类类之间有依赖关系的话,不利于功能的拓展和维护,因为只要修改一个对象,其它关联的对象都得进行修改。
如果使用中介者模式,只需关心和Mediator类的关系,具体类类之间的关系及调度交给Mediator就行,这有点像spring容器的作用。
23、解释器模式:
解释器模式一般主要应用在OOP开发中的编译器的开发中,所以适用面比较窄。
软件设计七大原则(OOP原则)
开闭原则:对扩展开放,对修改关闭。 里氏替换原则:不要破坏继承体系,子类重写方法功能发生改变,不应该影响父类方法的含义。 依赖倒置原则:要面向接口编程,不要面向实现编程。 单一职责原则:控制类的粒度大小、将对象解耦、提高其内聚性。 接口隔离原则:要为各个类建立它们需要的专用接口。 迪米特法则:一个类应该保持对其它对象最少的了解,降低耦合度。 合成复用原则:尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
实际上,七大原则的目的只有一个:降低对象之间的耦合,增加程序的可复用性、可扩展性和可维护性。
什么是AJAX?
AJAX = Asynchronous JavaScript And XML.
AJAX并非编程语言,是一种实现前后端数据交换的技术
AJAX 仅仅组合了:
- 浏览器内建的 XMLHttpRequest 对象(从 web 服务器请求数据)
- JavaScript 和 HTML DOM(显示或使用数据)
AJAX工作流程
网页中发生一个事件(页面加载、按钮点击) 由 JavaScript 创建 XMLHttpRequest 对象 XMLHttpRequest 对象向 web 服务器发送请求 服务器处理该请求 服务器将响应发送回网页 由 JavaScript读取响应 由 JavaScript 执行正确的动作(比如更新页面)

AJAX的核心是XMLHttpRequest对象。
XMLHttpRequest 对象用于同幕后服务器交换数据。这意味着可以更新网页的部分,而不需要重新加载整个页面。
GET 还是 POST?
GET 比 POST 更简单更快,可用于大多数情况下。
不过,请在以下情况始终使用 POST:
缓存文件不是选项(更新服务器上的文件或数据库) 向服务器发送大量数据(POST 无大小限制) 发送用户输入(可包含未知字符),POST比 GET 更强大更安全发送
异步请求对 web 开发人员来说是一个巨大的进步。服务器上执行的许多任务都非常耗时。在 AJAX 之前,此操作可能会导致应用程序挂起或停止。
通过异步发送,JavaScript 不必等待服务器响应,而是可以:
在等待服务器响应时执行其他脚本 当响应就绪时处理响应
在SQL语言中,常用四种类型语言:DDL(数据定义语言)、DML(数据操纵语言)、DQL(数据查询语言)、DTL(数据事务语言).
-
4.DCL(Data Transaction Language)
主要内容:处理操作量大,复杂程度高的数据 事务定义:最小的不可分隔的单元。一般是由多条sql语句构成一个事务,然后共同完成一个业务(如转账) 事务特性:原子性、一致性、隔离性、持久性 事务控制语句:开启:begin/start transaction 回滚:rollback 提交:commit
事务隔离性: 1、read uncommitted ; 读未提交 -------事务a对数据进行操作过程中,事务没有被提交,但是b可以看到a操作的结果(一个rollback,另一个可以看到撤回的结果) 2、read committed ;读已提交 3、repeatable read ;可以重复读*(MySQL默认可重复读取(REPEATABLE-READ)的事务隔离级别)* 4、serializable; 串行化 —事务a和事务b同时操作一张表,如果有一方想要插入数据,要等到事务b commit 后才能进行(会有等待超时)
脏读:事务a读到了事务b没有提交的数据
不可重复读:事务 A 多次读取同一数据,但事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
1、第一范式(1NF);2、第二范式(2NF);3、第三范式(3NF)。
其中,第一范式(1NF)的要求是属性不可分割,第二范式(2NF)的要求是满足第一范式,且不存在部分依赖;第三范式(3NF)的要求是满足第二范式,且不存在传递依赖。
1.第一范式(确保每列保持原子性) 第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
2.第二范式(确保表中的每列都和主键相关) 第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关) 第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
-
数据库架构可以简要分为两个部分:**查询引擎和存储引擎**。 存储引擎部分主要完成的功能: - 数据访存接口 - 事务处理 - 日志与恢复 本文将从以下功能组件介绍存储引擎: - 数据组织与索引管理 (高效数据访存) - 并发控制 (高效事务处理) - 日志与恢复
拥塞控制主要有四种方法,滑动窗口机制、慢启动机制、拥塞避免机制、快速重传与恢复。
[
数据库的优化包括几个方面
1.表的设计合理化(三范式)
2.sql语句的优化
3.表添加合适的索引(如何使用索引)
4.分表技术(水平分割、垂直分割)
5.定时清除垃圾数据,定时进行碎片整理
6.多用存储过程、程触发器
7.对MysqL配置进行优化
8.读写分离
9.服务器硬件升级
数据库的设计
良好的数据库:能节省数据库存储空间,保证数据完整性。
不好的数据库:数据冗余,存储空间浪费,产生数据不完整。
设计数据库的步骤:
1.充分了解需求
2.标识实体(具体存在的对象)
3.标识实体属性
4.标识关系(一对一,一对多,多对多)
如何将E-R图转换成表
1.将实体转成表,将属性转成字段。
2.标识每个表的主键列,如果找不到合适字段做主键。我们就添加一个自动增长列作为主键。
3.建立正确表与表之间的关系。
数据规范化
表设计出来以后,并不是最合理的结构,我们需要对表进行规范化
(我们需要用三范式来对表进行规范)
1.确保每列的原子性(字段不可再分)
第一范式用来规范所有字段,所有字段都不可再分。
2.非键字段必须依赖于键字段
说白了就是一张表只描述一件事
3.消除传递依赖
在非主键字段中,如果一个字段可以推导出另一个字段,这就是传递依赖。
反三范式
范式越高,数据的冗余就越少,但有的时候效率越低下,为了提高效率,可以适当的让数据冗余。
https://www.cnblogs.com/TddCoding/p/11809048.html
1、互斥条件:一个资源每次只能被一个进程使用;如果另一进程申请该资源,那么申请进程应等到该资源释放为止。
2、请求与等待条件:—个进程应占有至少一个资源,并等待另一个资源,而该资源为其他进程所占有。
3、不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺;只能被进程在完成任务后自愿释放。
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系;
我们强调所有四个条件必须同时成立才会出现死锁。循环等待条件意味着占有并等待条件,这样四个条件并不完全独立。
(12条消息) 进程线程与死锁(死锁产生原因、条件)及解决办法_FFFXXXFFF的博客-CSDN博客_死锁是线程还是进程
SSL/TLS 协议位于网络 OSI 七层模型的会话层,用来加密通信。SSL(Secure Sockets Layer,安全套接字层)是一种标准安全协议,用于在在线通信中建立Web服务器和浏览器之间的加密链接。SSL 通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。
TLS(Transport Layer Security,传输层安全)是 IETF 在 SSL 3.0 的基础上设计的协议,它是 SSL 协议的升级版。两者差别极小,可以理解为 TLS 是 SSL 3.1。
TLS 协议结构
TLS 协议分成两层:TLS 记录协议(TLS record protocol)、TLS 握手协议(TLS handshake protocol)
我们称尚未加密的数据为明文,通过固定算法加密后的数据为密文。
密钥是一种参数,它是在明文转换为密文或密文转换为明文时算法的输入参数。可以理解成密码的钥匙。
常见的数字加密方式分为两类:对称加密 和 非对称加密。
对称加密
对称加密算法中,数据发送方将明文和密钥一起经过特殊加密算法处理成密文后,将它发送出去。接收方收到密文后,若想解读原文,则需要使用加密用到的相同密钥及相同算法的逆算法对密文进行解密,才能使其恢复成原文。 它的最大优势是加/解密速度快,适用于大数据量进行加密,缺点是密钥管理困难,最典型的问题就是如何同步这个密钥,同步过程如果在公网上,不进行加密是可以抓包拿到的,那么这里就遇到了要对密钥加密的问题。对称加密的核心是只有一把密钥。
非对称加密
非对称加密算法中,有两个密钥:公钥和私钥。它们是一对,如果用公钥进行加密,只有用对应的私钥才能解密;如果用私钥进行加密,只有用对应的公钥才能解密。 非对称加密算法实现机密信息的交换过程为:甲方生成一对密钥并将其中一个作为公钥向其他方公开;得到该公钥的乙方使用该密钥对机密信息进行加密后发送给甲方;甲方再用自己的另一个专用密钥对加密后的信息进行解密。 最有名的非对称加密算法当属 RSA 了,本文将对 RSA 算法的加/解密过程进行详细剖析。 非对称加密拥有两把密钥。
RSA算法本身基于一个简单的数论知识:给出两个素数,很容易将它们相乘,然而给出它们的乘积,想得到这两个素数就显得尤为困难。如果能够解决大整数(比如几百位的整数)分解的快速方法,那么 RSA 算法将轻易被破解。
物理存储结构不同
数组是顺序存储结构,链表是链式存储结构。链表与数组的逻辑结构是相同的,都是零个或多个数据元素构成的线性表。
数组用一组地址连续的存储单元来存储表中的元素,这种结构称为顺序存储结构,它以元素在计算机内物理位置上的紧邻来表示线性表中数据元素之间相邻的逻辑关系
链式存储结构不要求逻辑上相邻的两个元素在物理位置上也相邻,链表元素除了存储元素本身的数据外,还需要存储一个指向下一个元素的位置数据,程序可以通过该信息访问到下一个元素。
内存分配方式不同
数组的存储空间一般采用静态分配,在分配之前需要确定数组的大小,按照数组的大小分配内存,内存申请单位为数组内所有元素占用的空间,数组的长度一般不宜动态扩展,申请的内存区域一般在栈区;链表的存储空间一般采用动态分配,内存申请单位一般为一个链表节点的空间,链表的长度可以动态扩展,申请的内存区域一般在堆区。
元素的存取方式不同
数组是顺序存储结构,数组元素可以直接通过元素的下标(索引)进行直接存取,时间复杂度为O(1);链表是链式存储结构,链表在进行元素存取时,需要遍历链表,时间复杂度为O(n),n为链表的长度。前者支持随机访问和顺序访问,后者仅支持顺序访问
元素的插入和删除方式不同
数组在进行元素插入和删除时,需要移动数组内的元素,以保持数组元素排列的顺序性,时间复杂度为O(n);链表在进行元素插入和删除时无需移动链表内的元素,但由于链表不是顺序存储结构,为寻找第i个元素,仍然需要遍历链表,因此时间复杂度为O(n)。
InnoDB MyISAM MEMORY
1、innodb支持事务,外键,而myisam不支持事务,外键。InnoDB的最大特色就是支持了ACID兼容的事务(Transaction)功能 3、innodb默认表锁,使用索引检索条件时是行锁,而myisam是表锁(每次更新增加删除都会锁住表)读取效率较高写入效率较低。 4、innodb和myisam的索引都是基于b+树,但他们具体实现不一样,innodb的b+树的叶子节点是存放数据的,myisam的b+树的叶子节点是存放指针的。 5、innodb是聚簇索引,必须要有主键,一定会基于主键查询,但是辅助索引就会查询两次,myisam是非聚簇索引,索引和数据是分离的,索引里保存的是数据地址的指针,主键索引和辅助索引是分开的。 6、innodb不存储表的行数,所以select count( * )的时候会全表查询,而myisam会存放表的行数,select count(*)的时候会查的很快。
总结:mysql默认使用innodb,如果要用事务和外键就使用innodb,如果这张表只用来查询,可以用myisam。如果更新删除增加频繁就使用innodb。
MEMORY 内存型数据库引擎,所有的数据都存储在内存中,因此它的读写效率很高,但 MySQL 服务重启之后数据会丢失。它同样不支持事务、不支持外键。MEMORY 支持 Hash 索引或 B 树索引,其中 Hash 索引是基于 key 查询的,因此查询效率特别高,但如果是基于范围查询的效率就比较低了。而前面两种存储引擎是基于 B+ 树的数据结构实现了。
优缺点分析 MEMORY 读写性能很高,但 MySQL 服务重启之后数据会丢失,它不支持事务和外键。适用场景是读写效率要求高,但对数据丢失不敏感的业务场景。总结
MySQL 中最常见的存储引擎有:InnoDB、MyISAM 和 MEMORY,其中 InnoDB 是 MySQL 5.1 之后默认的存储引擎,它支持事务、支持外键、支持崩溃修复和自增列,它的特点是稳定(能保证业务的完整性),但数据的读写效率一般;而 MyISAM 的查询效率较高,但不支持事务和外键;MEMORY 的读写效率最高,但因为数据都保存在内存中的,所以 MySQL 服务重启之后数据就会丢失,因此它只适用于数据丢失不敏感的业务场景。
事务是一组逻辑处理单位,可以是执行一条SQL语句,也可以是执行几个SQL语句。
事务用来保证数据由一种存储情况变为另一种情况,组成事务的各个单元要么都执行成功,要么都执行失败。
为什么使用事务
如果只是简单的一条SQL语句的执行,那么是不需要事务的,但在一些复杂的情况下,一个操作会涉及到多条SQL语句的执行,这种情况下就有必要保证所有的操作全部成功或者全部失败。
比如,小明给小红转账的一个操作,就会涉及到从小明账户扣钱和给小红账户充钱的两个操作。只有两个操作都成功执行了整个操作才算成功,这时就可以提交整个事务,可以说状态由转账前变到了转账后。否则有任何一个操作执行失败的话整个操作都要算做失败,这时就需要恢复事务,保证两个账户上的金额和转账前是一样的,表示恢复到了转账前的状态。
所以事务是为了保证一组操作的完整性而出现的,也是为了保证数据操作的安全。
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈 在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息 执行优化器,顾名思义,优化语句的,准确来说是优化查询语句。其实就是在我们写的select语句前加一个Explain关键字
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
是因为mysql创建联合索引时,首先会对最左边字段排序,也就是第一个字段,然后再在保证第一个字段有序的情况下,再排序第二个字段,以此类推。
所以联合索引最左列是绝对有序的,其他字段无序。
举个例子:可以把联合索引看成“电话簿”,姓名作为联合索引,姓是第一列,名是第二列,当查找人名时,是先确定这个人姓再根据名确定人。只有名没有姓就查不到。
如果只有多条件联合查询时最好建联合索引
索引虽说提高了访问速度,但太多索引会影响数据的更新操作。
限制表上的索引数目
避免在取值朝一个方向增长的字段(例如:日期类型的字段)上,建立索引;对[复合索引](https://so.csdn.net/so/search?q=复合索引&spm=1001.2101.3001.7020),避免将这种类型的字段放置在最前面。
对复合索引,按照字段在查询条件中出现的频度建立索引。
删除不再使用,或者很少被使用的索引。
对于那些在查询中很少使用或者参考的列不应该创建索引。
不要在有大量相同取值的字段上,建立索引。
对于那些定义为text, image和bit数据类型的列不应该增加索引。
当修改性能远远大于检索性能时,不应该创建索引。
创建联合索引优点: 1.减少开销。建多个单列索引,每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
2.覆盖索引。对联合索引(Gid,Cid,UId),如果有如下的sql: select Gid,Cid,UId from student where Gid=1 and Cid=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
3.效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where Gid=1 and Cid=2 and UId=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合Gid=2 and Cid= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升很大。
**为什么不用哈希?**哈希表查找效率是O(1)
数据库的索引可以考虑使用哈希,但是也有问题.例如:查找id<6并且>3的学生信息., select * from student where id < 6 and id > 3,只能处理相等的情况,不能处理其他的逻辑.> >= < <= between and...;
哈希的查找过程:把key代入哈希函数,计算得到下标,再根据下标取到对应的链表,再去遍历比较key是否相等。
总而言之,哈希只能处理相等的情况,不能处理范围的情况、
为什么不用二叉搜索树?

二叉树是大家熟知的一种树,用它来做索引行不行,可以是可以,但有几个问题:
- 如果索引数据很多,树的层次会很高(只有左右两个子节点),数据量大时查询还是会慢
- 二叉树每个节点只存储一个记录,一次查询在树上找的时候花费磁盘IO次数较多,所以它并不适合直接拿来做索引存储,算法设计人员在二叉树的基础之上进行了变种,引入了BTREE(B树)的概念。 -获取中序遍历结果效率不高. 此时处理范围查找也就比较低效.
什么是B树,有什么优势?

如上图可知BTREE有以下特点:
-
不再是二叉搜索,而是N叉搜索,树的高度会降低,查询快 -
叶子节点,非叶子节点,都可以存储数据,且可以存储多个数据 -
通过中序遍历,可以访问树上所有节点
BTREE被作为实现索引的数据结构被创造出来,是因为它能够完美的利用“局部性原理”,其设计逻辑是这样的:
-
内存读写快,磁盘读写慢,而且慢很多 -
磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载一些看起来是冗余的数据,如果未来要读取的数据就在这一页中,可以避免未来的磁盘读写,提高效率(通常,一页数据是4K) -
局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘IO效能


什么是B+树,有什么优势?

B+TREE改进点及优势所在:
-
仍然是N叉树,层级小,非叶子节点不再存储数据,数据只存储在同一层的叶子节点上,B+树从根到每一个节点的路径长度一样,而B树不是这样 -
叶子之间,增加了链表(图中红色箭头指向),获取所有节点,不再需要中序遍历,使用链表的next节点就可以快速访问到 -
范围查找方面,当定位min与max之后,中间叶子节点,就是结果集,不用中序回溯(范围查询在SQL中用得很多,这是B+树比B树最大的优势) -
叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的PK,用于查询加速,适合内存存储 -
非叶子节点,不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引 -
 -
**B+树好处总结:** - **查询任何一条记录速度是比较平均的,不会出现效率差异大的情况.** - ***\*不需要进行额外的中序遍历了.遍历链表就是得到中序结果.处理范围查找就更高效了.\**** - ***\*叶子放到磁盘上,非叶子放到内存中.查找效率就更高了(减少了读磁盘的次数)索引在内存中占用的实际开销也不高.\****
5.其他注意事项
- 索引起到的效果:加快查找效率.减慢插入和删除,修改效率.(需要同步调整索引结果)
- 索引也会占用额外的空间(本质上使用空间来换时间)
- 给具体的表中某列加索引的时候,加在主键上的索引和加在其他列上的索引是截然不同的.
首先学习链表,因为链表进一步加工就可以变化为栈或者队列。
栈与队列的唯一区别是“栈是喝多了吐,队列是吃多了拉”
函数栈,消息队列
传统的链表在插入数据时效率非常高,但是在查询数据时,只能按照链表的顺序去遍历,这与数组使用下标直接定位元素是存在明显性能差距的。但是数组又不具有链表快速插入的特性,所以能够想到的一种优化方法是:基于数组与链表设计一种顶层数据结构,这种数据结构就是哈希表。
1.1 什么是内存泄漏(Memory Leak) 严格来说,只有对象不会再被程序用到了,但是GC又不能回收他们的情况,才叫内存泄漏。 GC Roots集合所连接的对象中有一些我们不想用了,但是又忘记断开了他们的引用,那么也无法被垃圾回收,就造成了内存泄漏 但实际情况很多时候一些不太好的实践(或疏忽)会导致 对象的生命周期变得很长甚至导致内存溢出OOM,也可以叫做宽泛意义上的内存泄漏。 内存泄漏的堆积最终会导致内存溢出。 1.2 内存泄漏举例
单例模式:单例的生命周期和应用程序是一样长的,所以单例程序中,如果持有对外部对象的引用的话,那么这个外部对象是不能被回收的,则会导致内存泄漏的产生。 一些提供close的资源未关闭导致内存泄漏 :如:数据库连接( dataSourse. getConnection()),网络连接(socket)和io连接必须手动close,否则是不能被回收的。
2.1 什么是内存溢出(Out Of Memory) 没有空闲内存,并且垃圾收集器也无法提供更多内存。 由于GC一直在发展,所有一般情况下,除非应用程序占用的内存增长速度非常快,造成垃圾回收已经跟不上内存消耗的速度,否则不太容易出现OOM的情况。
内存没有空闲的情况分析
Java虚拟机的堆内存设置不够; 代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)。 内存泄漏的堆积最终会导致内存溢出。 在抛出0utOfMemoryError之 前,通常垃圾收集器会被触发,尽其所能去清理出空间
在抛出0utOfMemoryError之 前,通常垃圾收集器会被触发,尽其所能去清理出空间。 但也不是在任何情况下垃圾收集器都会被触发的。比如,我们去分配一个超大对象,类似一个超大数组超过堆的最大值,JVM可以判断出垃圾收集并不能解决这个问题,所以直接拋出OutOfMemoryError。
2.2 内存溢出发生的地方 JVM 运行时数据区主要包括:
程序计数器 虚拟机栈; 本地方法栈; Java堆; 方法区(运行时常量池是方法区的一部分); 直接内存;(直接内存并不是运行时数据区的一部分,但这部分内存也会被频繁的使用)
在JVM中,除了程序计数器之外,其他几个运行时数据区的区域都有发生OOM(内存溢出)异常的可能,如下:
堆溢出; 虚拟机栈和本地方法栈溢出; 方法区和运行时常量池溢出; 直接内存溢出;
- 栈存放什么:栈存储运行时声明的变量——对象引用(或基础类型, primitive)内存空间, 栈的实现是先入后出的。
- 堆存放什么:堆分配每一个对象内容(实例)内存空间
栈溢出两种情况
- 线程请求的栈深度大于虚拟机允许的最大深度 StackOverflowError ==》java.lang.StackOverflowError
- 虚拟机在扩展栈深度时,无法申请到足够的内存空间 OutOfMemoryError
Redis 的优点和缺点
优点
读写性能优异
支持 RDB 和 AOF 两种数据的持久化
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
支持丰富的数据结构,如 String,List,Set,Zset(有序集合),Hash 五种数据结构
缺点
Redis 不具备自动容错和恢复功能。主机,从机的宕机都会导致读写请求失败,需要等待机器重启才能恢复
主机宕机前,如果有部分数据未能及时同步到从机,重启主机后会导致数据不一致的问题
Redis 持久化机制
持久化数据:就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。Redis 的持久化方式有 RDB 和 AOF 两种

RDB 快照持久化
AOF持久化
分布式锁,即分布式系统中的锁。在单体应用中我们通过锁解决的是控制共享资源访问的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程。
分布式锁应该具备哪些条件:
在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行 高可用的获取锁与释放锁 高性能的获取锁与释放锁 具备可重入特性(可理解为重新进入,由多于一个任务并发使用,而不必担心数据错误) 具备锁失效机制,即自动解锁,防止死锁 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的实现方式:
- 基于数据库实现分布式锁
- 基于Zookeeper实现分布式锁
- 基于reids实现分布式锁
基于数据库的锁实现也有两种方式,一是基于数据库表的增删,另一种是基于数据库排他锁。
1、基于数据库表的增删:
基于数据库表增删是最简单的方式,首先创建一张锁的表主要包含下列字段:类的全路径名+方法名,时间戳等字段。
具体的使用方式:当需要锁住某个方法时,往该表中插入一条相关的记录。类的全路径名+方法名是有唯一性约束的,如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。执行完毕之后,需要delete该记录。
(这里只是简单介绍一下,对于上述方案可以进行优化,如:应用主从数据库,数据之间双向同步;一旦挂掉快速切换到备库上;做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍;使用while循环,直到insert成功再返回成功;记录当前获得锁的机器的主机信息和线程信息,下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了,实现可重入锁)
2、基于数据库排他锁:
基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作: 在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。获得排它锁的线程即可获得分布式锁,当获得锁之后,可以执行方法的业务逻辑,执行完方法之后,释放锁connection.commit()。当某条记录被加上排他锁之后,其他线程无法获取排他锁并被阻塞。
3、基于数据库锁的优缺点:
上面两种方式都是依赖数据库表,一种是通过表中的记录判断当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
优点是直接借助数据库,简单容易理解。 缺点是操作数据库需要一定的开销,性能问题需要考虑。
基于redis的分布式锁:
redis命令说明:
(1)setnx命令:set if not exists,当且仅当 key 不存在时,将 key 的值设为 value。若给定的 key 已经存在,则 SETNX 不做任何动作。
返回1,说明该进程获得锁,将 key 的值设为 value 返回0,说明其他进程已经获得了锁,进程不能进入临界区。 命令格式:setnx lock.key lock.value
(2)get命令:获取key的值,如果存在,则返回;如果不存在,则返回nil
命令格式:get lock.key
(3)getset命令:该方法是原子的,对key设置newValue这个值,并且返回key原来的旧值。
命令格式:getset lock.key newValue
(4)del命令:删除redis中指定的key
命令格式:del lock.key
基于set命令的分布式锁 1、加锁:使用setnx进行加锁,当该指令返回1时,说明成功获得锁
2、解锁:当得到锁的线程执行完任务之后,使用del命令释放锁,以便其他线程可以继续执行setnx命令来获得锁
(1)存在的问题:假设线程获取了锁之后,在执行任务的过程中挂掉,来不及显示地执行del命令释放锁,那么竞争该锁的线程都会执行不了,产生死锁的情况。
(2)解决方案:设置锁超时时间
3、设置锁超时时间:setnx 的 key 必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放。可以使用expire命令设置锁超时时间
(1)存在问题:
setnx 和 expire 不是原子性的操作,假设某个线程执行setnx 命令,成功获得了锁,但是还没来得及执行expire 命令,服务器就挂掉了,这样一来,这把锁就没有设置过期时间了,变成了死锁,别的线程再也没有办法获得锁了。
(2)解决方案:redis的set命令支持在获取锁的同时设置key的过期时间
4、使用set命令加锁并设置锁过期时间:
命令格式:set <lock.key> <lock.value> nx ex
详情参考redis使用文档:http://doc.redisfans.com/string/set.html
(1)存在问题:
① 假如线程A成功得到了锁,并且设置的超时时间是 30 秒。如果某些原因导致线程 A 执行的很慢,过了 30 秒都没执行完,这时候锁过期自动释放,线程 B 得到了锁。
② 随后,线程A执行完任务,接着执行del指令来释放锁。但这时候线程 B 还没执行完,线程A实际上删除的是线程B加的锁。
(2)解决方案:
可以在 del 释放锁之前做一个判断,验证当前的锁是不是自己加的锁。在加锁的时候把当前的线程 ID 当做value,并在删除之前验证 key 对应的 value 是不是自己线程的 ID。但是,这样做其实隐含了一个新的问题,get操作、判断和释放锁是两个独立操作,不是原子性。对于非原子性的问题,我们可以使用Lua脚本来确保操作的原子性
为什么需要Redis集群?
在讲Redis集群架构之前,我们先简单讲下Redis单实例的架构,从最开始的一主N从,到读写分离,再到[Sentinel](https://so.csdn.net/so/search?q=Sentinel&spm=1001.2101.3001.7020)哨兵机制,单实例的Redis缓存足以应对大多数的使用场景,也能实现主从故障迁移。
(1)写并发:
Redis单实例读写分离可以解决读操作的负载均衡,但对于写操作,仍然是全部落在了master节点上面,在海量数据高并发场景,一个节点写数据容易出现瓶颈,造成master节点的压力上升。
(2)海量数据的存储压力:
单实例Redis本质上只有一台Master作为存储,如果面对海量数据的存储,一台Redis的服务器就应付不过来了,而且数据量太大意味着持久化成本高,严重时可能会阻塞服务器,造成服务请求成功率下降,降低服务的稳定性。
针对以上的问题,Redis集群提供了较为完善的方案,解决了存储能力受到单机限制,写操作无法负载均衡的问题。
Redis集群采用去中心化的思想,没有中心节点的说法,对于客户端来说,整个集群可以看成一个整体,可以连接任意一个节点进行操作,就像操作单一Redis实例一样,不需要任何代理中间件,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。
Redis也内置了高可用机制,支持N个master节点,每个master节点都可以挂载多个slave节点,当master节点挂掉时,集群会提升它的某个slave节点作为新的master节点。
什么是哈希槽算法?
前面讲到,Redis集群通过分布式存储的方式解决了单节点的海量数据存储的问题,对于分布式存储,需要考虑的重点就是如何将数据进行拆分到不同的Redis服务器上。常见的分区算法有hash算法、一致性hash算法,关于这些算法这里就不多介绍。
普通hash算法:将key使用hash算法计算之后,按照节点数量来取余,即hash(key)%N。优点就是比较简单,但是扩容或者摘除节点时需要重新根据映射关系计算,会导致数据重新迁移。 一致性hash算法:为每一个节点分配一个token,构成一个哈希环;查找时先根据key计算hash值,然后顺时针找到第一个大于等于该哈希值的token节点。优点是在加入和删除节点时只影响相邻的两个节点,缺点是加减节点会造成部分数据无法命中,所以一般用于缓存,而且用于节点量大的情况下,扩容一般增加一倍节点保障数据负载均衡。
只有TCP有粘包现象,UDP永远不会粘包!
粘包:在接收数据时,一次性多接收了其它请求发送来的数据(即多包接收)。如,对方第一次发送hello,第二次发送world,
在接收时,应该收两次,一次是hello,一次是world,但事实上是一次收到helloworld,一次收到空,这种现象叫粘包。
原因
粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
什么情况会发生:
1、发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据很小,会合到一起,产生粘包)
2、接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
解决方案:
一个思路是发送之前,先打个招呼,告诉对方自己要发送的字节长度,这样对方可以根据长度判断什么时候终止接受。
现在的高级语言如java,c#等,都采用了垃圾收集机制,而不再是c,c++里用户自己管理维护内存的方式。自己管理内存极其自由,可以任意申请内存,但如同一把双刃剑,为大量内存泄露,悬空指针等bug埋下隐患。 对于一个字符串、列表、类甚至数值都是对象,且定位简单易用的语言,自然不会让用户去处理如何分配回收内存的问题。 python里也同java一样采用了垃圾收集机制,不过不一样的是: python采用的是引用计数机制为主,标记-清除和分代收集(隔代回收)两种机制为辅的策略。 双向链表(Refchain)
当python程序运行时,会更具数据类型的不同,找到其对应的结构体,根据结构体中的字段,来进行创建相关的数据,然后将对象添加到refchain双向链表中。目前就简单理解成计数器为0,我们就进行垃圾回收。因为循环引用导致数据没有被及时的销毁导致了内存泄漏。为了解决循环引用的不足,python的底层不会单单只用引用计数器,引入了一个机制叫做标记清除。
平衡二叉树、B树、B+树、B*树 理解其中一种你就都明白了 - 知乎 (zhihu.com)
什么是 B 树?-蒲公英云 (dandelioncloud.cn)
什么是B+树?-蒲公英云 (dandelioncloud.cn)
Docker的三大核心概念:镜像、容器、仓库
镜像:类似虚拟机的镜像、用俗话说就是安装文件。
容器:类似一个轻量级的沙箱,容器是从镜像创建应用运行实例,可以将其启动、开始、停止、删除、而这些容器都是相互隔离、互不可见的。
仓库:类似代码仓库,是Docker集中存放镜像文件的场所。
镜像(image)
Docker镜像类似于一个虚拟机镜像(xxx.iso), 可以将它理解为一个只读的模板!
例如, 一个镜像可以包含一个基本的操作系统环境, 里面仅安装了 Apache应用程序(或用户需要的其他软件). 可以把它称为Apache镜像.
镜像是创建Docker容器的基础.通过版本管理和增量的文件系统, Docker提供了一套十分简单的机制来创建和更新现有的镜像, 用户甚至可以从网上下载一个已经做好的应用镜像, 并直接使用它.
容器(container)
Docker 容器类似于一个轻量级的沙箱, Docker 利用容器来运行和隔离应用。 容器是从镜像创建的应用运行实例。它可以启动、开始、停止、删除,而这些容器都是彼此相互隔离、互不可见的。
可以把容器看作一个简易版的 Linux 系统环境(包括 root 用户权限、进程空间、用户空间和网络空间等)以及运行在其中的应用程序打包而成的盒子。
镜像自身是只读的。
容器从镜像启动的时候,会在镜像的最上层创建一个可写层。
仓库(repository)
Docker 仓库类似于代码仓库,是 Docker 集中存放镜像文件的场所。
根据所存储的镜像公开分享与否, Docker 仓库可以分为公开仓库(Public)和私有仓库(Private)两种形式。
目前,最大的公开仓库是官方提供的 Docker Hub ,其中存放着数量庞大的镜像供用户下载。国内不少云服务提供商(如腾讯云 、 阿里云等)也提供了仓库的本地源,可以提供稳定的国内访问。当然,用户如果不希望公开分享自己的镜像文件, Docker 也支持用户在本地网络内创建一个只能自己访问的私有仓库。
当用户创建了自己的镜像之后就可以使用 push 命令将它上传到指定的公有或者私有仓库。 这样用户下次在另外一台机器上使用该镜像时,只需要将其从仓库上 pull 下来就可以了。

两者都是虚拟技术
虚拟机需要模拟整台机器包括硬件,每台虚拟机都需要有自己的操作系统,虚拟机一旦被开启,预分配给他的资源将部被占用。
容器包含应用和其所有的依赖包,但是与其他容器共享内核。容器在宿主机操作系统中,在用户空间以分离的进程运行。
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
GPU(全称:Graphics Processing Unit-图形处理器),GPU相当于显卡的心脏,好比cpu在电脑中的作用,gpu的强大决定了显卡的性能。简单地说GPU就是能够在硬件上支持T&L的显示芯片。
GPU是相对于CPU的一个概念,由于在现代的计算机中(特别是家用系统,游戏的发烧友)图形的处理变得越来越重要,需要一个专门的图形的核心处理器。于是NVIDIA公司在1999年发布GeForce 256图形处理芯片时首先提出GPU的概念。
GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时。GPU所采用的核心技术有硬体T&L、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬体T&L技术可以说是GPU的标志。GPU核心频率、管线数量、着色单元数量基本可以代表一款GPU的性能。
什么是CPU?CPU是英语“Central Processing Unit/中央处理器”的缩写,CPU一般由逻辑运算单元、控制单元和存储单元组成。在逻辑运算和控制单元中包括一些寄存器,这些寄存器用于CPU在处理数据过程中数据的暂时保存, 其实我们在买CPU时,并不需要知道它的构造,只要知道它的性能就可以了。 CPU,是个英文缩写,中文名称叫作“中央处理器”,或叫作微处理器。它由运算器和控制器组成,是电脑的心脏,它决定电脑档次的高低。它是用半导体材料经过复杂的加工而生产出来的。
CPU的功能是取出、解释并执行指令。我们不是听说过386、486吗?它指的就是该计算机的CPU的型号是386或486,它是衡量一台电脑性能高低的标志。平常我们所说的386、486、586(又分为P5、5X86、K5),都是CPU的型号,同一类型号的CPU,又有主频的不同,如486/100、486/133,P5/166、P5/200,就是主频分别为100MHZ和133MHZ的486,166和200MHZ的奔腾586。主频高,则相应运算速度就快。有的软件就要求在486/66以上CPU以下才能很好地工作。 世界上研究和开发CPU的“龙头老大”是美国的英特尔公司,许多电脑的外面贴着InterInside的标志。
CPU:中央处理器(英文Central Processing Unit)是一台计算机的运算核心和控制核心。CPU、内部存储器和输入/输出设备是电子计算机三大核心部件。其功能主要是解释计算机指令以及处理计算机软件中的数据。
GPU:英文全称Graphic Processing Unit,中文翻译为“图形处理器”。一个专门的图形核心处理器。GPU是显示卡的“大脑”,决定了该显卡的档次和大部分性能,同时也是2D显示卡和3D显示卡的区别依据。2D显示芯片在处理3D图像和特效时主要依赖CPU的处理能力,称为“软加速”。3D显示芯片是将三维图像和特效处理功能集中在显示芯片内,也即所谓的“硬件加速”功能。
GPU的功能众多,而且都很重要,还要做内存管理和响应输入,因此在实际的图形处理时效率会大打折扣,所以gpu 加速就显得尤为重要。尤其是现在信息数据的复杂和多样性,对于处理速度和准确度上都有了更高的要求。想要在短时间内处理大量复杂的信息并且正确打开是非常困难的,gpu高性能计算就显得尤为重要。GPU加速可以在人工智能、高性能计算以及专业图像处理方面可以满足更多用户的需求,那么GPU加速软件有哪些呢? 给大家推荐四款好用的GPU 加速软件:Radeon ProRender、Lumion、Eevee、OctaneRender
gpu与cpu的区别有哪些?
1、计算量的区别
CPU:计算量小,只有几个运算单元
GPU:计算量大,有上千个运算单元
2、计算复杂度比较
CPU:复杂的计算用cpu,虽然运算单元少,但都属于运算专家级别
GPU:简单的计算用GPU,不能计算复杂的,运算单元属于小学生水平。
3、对于复杂计算的速度比较
CPU:较快。计算原理:单线程计算?,专一而且专业,单个芯片性能强劲,能计算出来且速度较快
GPU:较慢,有可能还计算不出来结果。计算原理:单个芯片性能弱,计算能力弱,很有可能计算不出来
4、计算速度比较
CPU:速度较慢。计算好一个在计算下一个
GPU:速度很快。同时计算上千个,效率更高
首先 CPU 和 GPU 是为了不同的计算任务而设计的:
a)CPU 主要为串行指令而优化,而 GPU 则是为大规模的并行运算而优化。
b)从并行的角度来看,现代的多核 CPU 针对的是指令集并行(ILP)和任务并行(TLP),而 GPU 则是数据并行(DLP)。
c)在同样面积的芯片之上,CPU 更多的放置了多级缓存(L1/L2/LLC)和指令并行相关的控制部件(乱序执行,分支预测等等),而 GPU 上则更多的是运算单元(整数、浮点的乘加单元,特殊运算单元等等)
d)GPU 往往拥有更大带宽的 Memory,也就是所谓的显存,因此在大吞吐量的应用中也会有很好的性能。
其次 GPU 真正的速度优势并没有宣传中的那么大,这主要是因为:
a)我们所看到的这些比较中,并没有很好的利用上 CPU 中的 SIMD 运算部件。
b)GPU的运算任务无法独立于CPU而执行,运算任务与数据也必须通过总线在GPU与CPU之间传输,因此很多任务是无法达到理论加速的。
GPU和CPU适合的应用场景不同
a)如果是数据相关性不大的重复运算,GPU确实有优势,有时候加速比能到几百倍
b)如果是相关性比较大的运算,比如迭代、尤其是迭代译码之类的运算,后面的计算需要前面计算的结果,这时候GPU的运算性对于CPU没有什么优势,有时候运算速度更慢。
c)另外GPU器件的启动时间、内存和显存之间的数据交互也很耗时间,这些也会影响比较的结果。
如何使用免费的GPU? 我是学生党,最近在学习深度学习,需要用到GPU加速,现分享两个免费使用GPU的方法。
1、使用 Kaggle 的免费GPU,Kaggle每周可以赠送30~43小时免费使用GPU。
2、使用 Google Colab 免费GPU加速,长时间连续使用会有所限制。 前提条件:
电脑上需装有梯子,可以访问外网。
Kaggle使用免费GPU 首先打开浏览器,搜索Kaggle
进入Kaggle网址后,点击Code
新建notebook笔记本,在线运行代码(此处类似于jupyter notebook)
从右侧侧边栏找到手机验证选项,点击验证(注意,首先要先注册一个账号哦,google账号或qq邮箱均可)
切记,一定要连上外网,否则是无法出现人机验证选项的,也无法点击Verification发送验证码信息
注册成功后,关闭该页面即可
现在,选择Accelerator选项,选择GPU选项
打开GPU加速选项,点击Turn On
现在我们可以看到,现在我可以免费使用43个小时的GPU
现在可以输入 !nvidia-smi 命令,查看Kaggle的GPU信息
可以看到Kaggle分配给我们的显卡为 Tesla P100-PCIE,查看该显卡的性能
此时就直接可以在Kaggle的在线notebook里面运行代码使用GPU加速了!
Google Colab 使用免费GPU 在google网页搜索 Google Colab,如下界面
打开网页,可见
此时,直接使用 colab 内的 notebook 即可,会自动进行GPU加速
注意,如果是你的电脑是AMD显卡的话,可能需要安装一下英伟达的驱动器才能使用。
小结 使用GPU加速时需注意,请将模型与参数存入GPU所在的内存,如net.to(device), X.to(device)等。
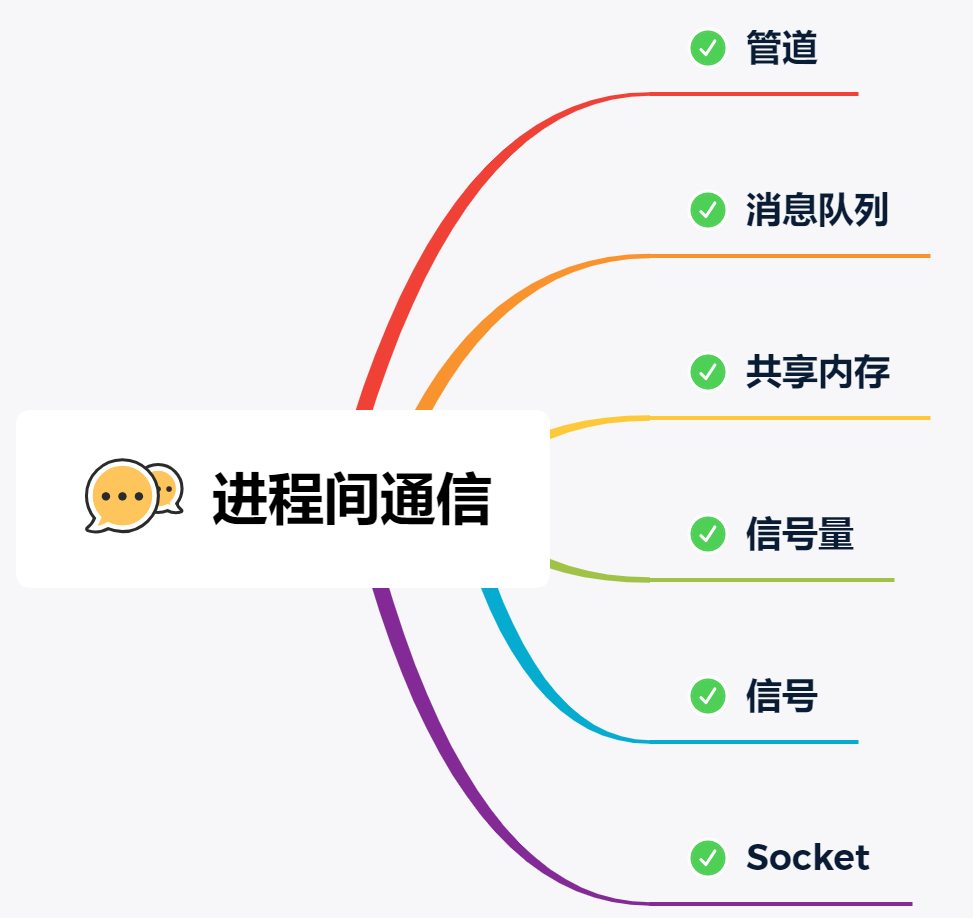
管道:
管道是最简单,效率最差的一种通信方式。
管道本质上就是内核中的一个缓存,当进程创建一个管道后,Linux会返回两个文件描述符,一个是写入端的描述符,一个是输出端的描述符,可以通过这两个描述符往管道写入或者读取数据。
如果想要实现两个进程通过管道来通信,则需要让创建管道的进程fork子进程,这样子进程们就拥有了父进程的文件描述符,这样子进程之间也就有了对同一管道的操作。
缺点:
半双工通信,一条管道只能一个进程写,一个进程读。 一个进程写完后,另一个进程才能读,反之同理。
消息队列:
管道的通信方式效率是低下的,不适合进程间频繁的交换数据。这个问题,消息队列的通信方式就可以解决。A进程往消息队列写入数据后就可以正常返回,B进程需要时再去读取就可以了,效率比较高。
而且,数据会被分为一个一个的数据单元,称为消息体,消息发送方和接收方约定好消息体的数据类型,不像管道是无格式的字节流类型,这样的好处是可以边发送边接收,而不需要等待完整的数据。
但是也有缺点,每个消息体有一个最大长度的限制,并且队列所包含消息体的总长度也是有上限的,这是其中一个不足之处。
另一个缺点是消息队列通信过程中存在用户态和内核态之间的数据拷贝问题。进程往消息队列写入数据时,会发送用户态拷贝数据到内核态的过程,同理读取数据时会发生从内核态到用户态拷贝数据的过程。
共享内存:
共享内存解决了消息队列存在的内核态和用户态之间数据拷贝的问题。
现代操作系统对于内存管理采用的是虚拟内存技术,也就是说每个进程都有自己的虚拟内存空间,虚拟内存映射到真实的物理内存。共享内存的机制就是,不同的进程拿出一块虚拟内存空间,映射到相同的物理内存空间。这样一个进程写入的东西,另一个进程马上就能够看到,不需要进行拷贝。
(这里的物理内存貌似不是内核空间的内存?)
信号量:
当使用共享内存的通信方式,如果有多个进程同时往共享内存写入数据,有可能先写的进程的内容被其他进程覆盖了。
因此需要一种保护机制,信号量本质上是一个整型的计数器,用于实现进程间的互斥和同步。
信号量代表着资源的数量,操作信号量的方式有两种:
P操作:这个操作会将信号量减一,相减后信号量如果小于0,则表示资源已经被占用了,进程需要阻塞等待;如果大于等于0,则说明还有资源可用,进程可以正常执行。 V操作:这个操作会将信号量加一,相加后信号量如果小于等于0,则表明当前有进程阻塞,于是会将该进程唤醒;如果大于0,则表示当前没有阻塞的进程。 (1)信号量实现互斥:
信号量初始化为1
进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。 (2)信号量实现同步:
由于多线程下各线程的执行顺序是无法预料的,有些时候我们希望多个线程之间能够密切合作,这时候就需要考虑线程的同步问题。
信号量初始化为0
如果进程 B 比进程 A 先执行了,那么执行到 P 操作时,由于信号量初始值为 0,故信号量会变为 -1,表示进程 A 还没生产数据,于是进程 B 就阻塞等待; 接着,当进程 A 生产完数据后,执行了 V 操作,就会使得信号量变为 0,于是就会唤醒阻塞在 P 操作的进程 B; 最后,进程 B 被唤醒后,意味着进程 A 已经生产了数据,于是进程 B 就可以正常读取数据了。
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
最近最少使用算法(LRU)是大部分操作系统为最大化页面命中率而广泛采用的一种页面置换算法。该算法的思路是,发生缺页中断时,选择未使用时间最长的页面置换出去。 [1] 从程序运行的原理来看,最近最少使用算法是比较接近理想的一种页面置换算法,这种算法既充分利用了内存中页面调用的历史信息,又正确反映了程序的局部问题。利用 LRU 算法对上例进行页面置换的结果如图1所示。当进程第一次对页面 2 进行访问时,由于页面 7 是最近最久未被访问的,故将它置换出去。当进程第一次对页面 3进行访问时,第 1 页成为最近最久未使用的页,将它换出。由图1可以看出,前 5 个时间的图像与最佳置换算法时的相同,但这并非是必然的结果。因为,最佳置换算法是从“向后看”的观点出发的,即它是依据以后各页的使用情况;而 LRU 算法则是“向前看”的,即根据各页以前的使用情况来判断,而页面过去和未来的走向之间并无必然的联系。
LRU(Least Recently Used,最近最少使用)算法是一种淘汰策略,简单来讲实现的是如下工作:将一些元素放在一个容量固定的容器中进行存取,由于容器的容量有限,该容器就要保证那些最近才被用到的元素始终在容器内,而将已经很久没有用的元素剔除,实现容器内元素的动态维护。这种算法是一种缓存维护策略,因为缓存空间有限,让缓存中存储的都是最近才被用到的元素可以实现系统缓存的高效运作。 根据以上要求,我们可以确定:
LRUCache本身需要用一个具体的存储容器来实现,该容器内部存储的元素形式是键值对的形式,并且该容器查找元素是通过输入键,返回键所对应的值来实现的,因此可以确定,LRUCache容器本身可以使用哈希表这种数据结构来实现。并且根据键与值的参数类型可以确定,该哈希表的键和值都是int类型。 LRUCache的int get(int key)接口完成的操作是哈希表本身就可以完成的操作。同时,该接口定义了缓存中元素被使用的含义,即最近一次通过get接口被查询到的键值对元素是缓存中最近一次被使用到的元素。 LRUCache的void put(int key, int value)接口完成的操作隐含了动态维护LRUCache中元素的需求。动态维护的方法就是LRU算法,即将LRUCache中的元素(int键值对)按照使用的时间顺序排列。同时需要特别注意的是,该接口操作也定义了缓存中元素另一种被使用的含义,即最近一次通过put接口被放入缓存中的元素是缓存中最近一次被使用到的元素。 可以通过双向链表来实现LRU算法,细节如下:
双向链表的节点存储内容是用来实现LRUCache容器的哈希表元素(int类型键值对) 双向链表存在界限,即最大节点数就是LRUCache的容量。 每次通过int get(int key)接口查询到LRUCache中的一个元素,就将该元素在双向链表中移动到头部。 操作LRUCache的void put(int key, int value)接口可能会使得双向链表的节点数增加(当缓存中没有该key值,且缓存容量未满时),每次put操作(无论是存在key,只是更新value,还是不存在key,插入新的key-value对)都会将该put操作的key-value元素在双向链表中移动到头部 通过上述操作,双向链表的尾节点一定是LRUCache中最久没有被使用过的元素,则当双向链表超出限定长度后,删除超长的尾节点
最佳置换算法(OPT)
这是一种理想情况下的页面置换算法,但实际上是不可能实现的。该算法的基本思想是:发生缺页时,有些页面在内存中,其中有一页将很快被访问(也包含紧接着的下一条指令的那页),而其他页面则可能要到10、100或者1000条指令后才会被访问,每个页面都可以用在该页面首次被访问前所要执行的指令数进行标记。最佳页面置换算法只是简单地规定:标记最大的页应该被置换。这个算法唯一的一个问题就是它无法实现。当缺页发生时,操作系统无法知道各个页面下一次是在什么时候被访问。虽然这个算法不可能实现,但是最佳页面置换算法可以用于对可实现算法的性能进行衡量比较。
先进先出置换算法(FIFO)
最简单的页面置换算法是先入先出(FIFO)法。这种算法的实质是,总是选择在主存中停留时间最长(即最老)的一页置换,即先进入内存的页,先退出内存。理由是:最早调入内存的页,其不再被使用的可能性比刚调入内存的可能性大。建立一个FIFO队列,收容所有在内存中的页。被置换页面总是在队列头上进行。当一个页面被放入内存时,就把它插在队尾上。这种算法只是在按线性顺序访问地址空间时才是理想的,否则效率不高。因为那些常被访问的页,往往在主存中也停留得最久,结果它们因变“老”而不得不被置换出去。
FIFO的另一个缺点是,它有一种异常现象,即在增加存储块的情况下,反而使缺页中断率增加了。当然,导致这种异常现象的页面走向实际上是很少见的。
最少使用(LFU)置换算法
在采用最少使用置换算法时,应为在内存中的每个页面设置一个移位寄存器,用来记录该页面被访问的频率。该置换算法选择在之前时期使用最少的页面作为淘汰页。由于存储器具有较高的访问速度,例如100 ns,在1 ms时间内可能对某页面连续访问成千上万次,因此,通常不能直接利用计数器来记录某页被访问的次数,而是采用移位寄存器方式。每次访问某页时,便将该移位寄存器的最高位置1,再每隔一定时间(例如100 ns)右移一次。这样,在最近一段时间使用最少的页面将是∑Ri最小的页。LFU置换算法的页面访问图与LRU置换算法的访问图完全相同;或者说,利用这样一套硬件既可实现LRU算法,又可实现LFU算法。应该指出,LFU算法并不能真正反映出页面的使用情况,因为在每一时间间隔内,只是用寄存器的一位来记录页的使用情况,因此,访问一次和访问10 000次是等效的。
Python的优点
Python 很灵活。以网站的形式加载、清理、提交和呈现数据是高效的。
它是可扩展的。它提供了高质量的库,如 Matplotlib、Numpy、Tensorflow、Pandas 等。这些包提供了处理海量数据集的方法。
代码是开源的。
它具有简单的语法,使其易于学习。
在开发周期的背景下,它是稳定的和可预测的。
Python的缺点
Python 是一种解释型语言。因此,每一行代码一次执行一个。
它会减慢 Python 的速度,从而导致执行速度变慢。
它不适合移动和浏览器计算,因为它在这个领域缺乏安全性。
Python 没有必要指定可能导致运行时问题的变量类型
GO 的缺点
Go 不是可用的语言。
没有官方认可的用于 API 集成的 Go SDK。
图书馆支持不足
碎片化依赖管理
Python 是一种高端编程语言,本质上是面向对象的。
Go 是一种同时开发的过程编程语言。
它是 Python 与 Go 编程之间差异的重要因素。
Python 编程是一种动态类型语言。
而 Go 编程语言是静态类型的。
支持的编程范式
Python 比 Go 支持更多的“编程范式”; Python 的常用技术包括面向对象编程、过程编程和函数范式。
另一方面,Go 不提供继承、类或对象。它是一种非常注重功能的过程语言。
类和对象
Python 编程语言包括类和对象。
然而,Golang 不允许面向对象编程。结果,它缺少类和对象。
速度
下一个因素是 Python 与 Go 编程之间差异的速度。
与 Go 相比,Python 编程速度较慢。
另一方面,Go 比 Python 快得多,这是它相对于后者的主要优势之一。
图书馆
Python 最显着的优势之一是其广泛的库。 Django 和 Flask,Python Web 框架,允许您创建 Web 应用程序或应用程序编程接口 (API)。
然而,Go 的库比 Python 少。然而,这并不意味着 Go 失败了。
基于用户的协同过滤推荐算法 当目标用户需要推荐时,可以先通过兴趣、爱好或行为习惯找到与他相似的其他用户,然后把那些与目标用户相似的用户喜欢的并且目标用户没有浏览过的物品推荐给目标用户。
1、基于用户的CF原理如下:
① 分析各个用户对物品的评价,通过浏览记录、购买记录等得到用户的隐性评分;
② 根据用户对物品的隐性评分计算得到所有用户之间的相似度;
③ 选出与目标用户最相似的K个用户;
④ 将这K个用户隐性评分最高并且目标用户又没有浏览过的物品推荐给目标用户。
2、优点:
① 基于用户的协同过滤推荐算法是给目标用户推荐那些和他有共同兴趣的用户喜欢的物品,所以该算法推荐较为社会化,即推荐的物品是与用户兴趣一致的那个群体中的热门物品;
② 适于物品比用户多、物品时效性较强的情形,否则计算慢;
③ 能实现跨领域、惊喜度高的结果。
3、缺点:
① 在很多时候,很多用户两两之间的共同评分仅有几个,也即用户之间的重合度并不高,同时仅有的共同打了分的物品,往往是一些很常见的物品,如票房大片、生活必需品;
② 用户之间的距离可能变得很快,这种离线算法难以瞬间更新推荐结果;
③ 推荐结果的个性化较弱、较宽泛。
4、改进:
① 两个用户对流行物品的有相似兴趣,丝毫不能说明他们有相似的兴趣,此时要增加惩罚力度;
② 如果两个用户同时喜欢了相同的物品,那么可以给这两个用户更高的相似度;
③ 在描述邻居用户的偏好时,给其最近喜欢的物品较高权重;
④ 把类似地域用户的行为作为推荐的主要依据。
基于物品的协同过滤推荐算法 当一个用户需要个性化推荐时,举个例子由于我之前购买过许嵩的《梦游计》这张专辑,所以会给我推荐《青年晚报》,因为很多其他用户都同时购买了许嵩的这两张专辑。
1、基于物品的CF原理如下:
① 分析各个用户对物品的浏览记录;
② 依据浏览记录分析得出所有物品之间的相似度;
③ 对于目标用户评价高的物品,找出与之相似度最高的K个物品;
④ 将这K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 基于物品的协同过滤推荐算法则是为目标用户推荐那些和他之前喜欢的物品类似的物品,所以基于物品的协同过滤推荐算法的推荐较为个性,因为推荐的物品一般都满足目标用户的独特兴趣。
② 物品之间的距离可能是根据成百上千万的用户的隐性评分计算得出,往往能在一段时间内保持稳定。因此,这种算法可以预先计算距离,其在线部分能更快地生产推荐列表。
③ 应用最广泛,尤其以电商行业为典型。
④ 适于用户多、物品少的情形,否则计算慢
⑤ 推荐精度高,更具个性化
⑥ 倾向于推荐同类商品
3、缺点:
① 不同领域的最热门物品之间经常具有较高的相似度。比如,基于本算法,我们可能会给喜欢听许嵩歌曲的同学推荐汪峰的歌曲,也就是推荐不同领域的畅销作品,这样的推荐结果可能并不是我们想要的。
② 在物品冷启动、数据稀疏时效果不佳
③ 推荐的多样性不足,形成信息闭环
4、改进:
① 如果是热门物品,很多人都喜欢,就会接近1,就会造成很多物品都和热门物品相似,此时要增加惩罚力度;
② 活跃用户对物品相似度的贡献小于不活跃的用户;
③ 同一个用户在间隔很短的时间内喜欢的两件商品之间,可以给予更高的相似度;
④ 在描述目标用户偏好时,给其最近喜欢的商品较高权重;
⑤ 同一个用户在同一个地域内喜欢的两件商品之间,可以给予更高的相似度。
基于内容的推荐算法 协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,而根本不会考虑到物品本身的属性,而基于内容的算法会考虑到物品本身的属性。
根据用户之前对物品的历史行为,如用户购买过什么物品、对什么物品收藏过、评分过等等,然后再根据计算与这些物品相似的物品,并把它们推荐给用户。例如某用户之前购买过许嵩的《寻宝游戏》,这可以说明该用户可能是一个嵩鼠,这时就可以给该用户推荐一些许嵩的其他专辑或著作。
1、基于内容的推荐算法的原理如下:
① 选取一些具有代表性的特征来表示每个物品
② 使用用户的历史行为数据分析物品的这些特征,从而学习出用户的喜好特征或兴趣,也即构建用户画像
③ 通过比较上一步得到的用户画像和待推荐物品的画像(由待推荐物品的特征构成),将具有相关性最大的前K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点: ① 是最直观的算法
② 常借助文本相似度计算
③ 很好地解决冷启动问题,并且也不会囿于热度的限制
3、缺点:
① 容易受限于对文本、图像、音视频的内容进行描述的详细程度
② 过度专业化(over-specialisation),导致一直推荐给用户内容密切关联的item,而失去了推荐内容的多样性。
③ 主题过于集中,惊喜度不足
欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况;
过拟合是指模型在训练集上表现很好,到了验证和测试阶段就大不如意了,即模型的泛化能力很差。
解决欠拟合(高偏差)的方法
1. 模型复杂化
• 对同一个算法复杂化。例如回归模型添加更多的高次项,增加决策树的深度,增加[神经网络](http://www.elecfans.com/tags/神经网络/)的隐藏层数和隐藏单元数等
• 弃用原来的算法,使用一个更加复杂的算法或模型。例如用神经网络来替代线性回归,用随机森林来代替决策树等
2. 增加更多的特征,使输入数据具有更强的表达能力
• 特征挖掘十分重要,尤其是具有强表达能力的特征,往往可以抵过大量的弱表达能力的特征
• 特征的数量往往并非重点,质量才是,总之强特最重要
• 能否挖掘出强特,还在于对数据本身以及具体应用场景的深刻理解,往往依赖于经验
3. 调整参数和超参数
• 超参数包括:
神经网络中:学习率、学习衰减率、隐藏层数、隐藏层的单元数、[Ad](https://bbs.elecfans.com/zhuti_1472_1.html)am优化算法中的β1和β2参数、batch_size数值等
其他算法中:随机森林的树数量,k-means中的cluster数,正则化参数λ等
4. 增加训练数据往往没有用
• 欠拟合本来就是模型的学习能力不足,增加再多的数据给它训练它也没能力学习好
5. 降低正则化约束
• 正则化约束是为了防止模型过拟合,如果模型压根不存在过拟合而是欠拟合了,那么就考虑是否降低正则化参数λ或者直接去除正则化项
解决过拟合(高方差)的方法
1. 增加训练数据数
• 发生过拟合最常见的现象就是数据量太少而模型太复杂
• 过拟合是由于模型学习到了数据的一些噪声特征导致,增加训练数据的量能够减少噪声的影响,让模型更多地学习数据的一般特征
• 增加数据量有时可能不是那么容易,需要花费一定的时间和精力去搜集处理数据
• 利用现有数据进行扩充或许也是一个好办法。例如在图像识别中,如果没有足够的图片训练,可以把已有的图片进行旋转,拉伸,镜像,对称等,这样就可以把数据量扩大好几倍而不需要额外补充数据
• 注意保证训练数据的分布和测试数据的分布要保持一致,二者要是分布完全不同,那模型预测真可谓是对牛弹琴了
2. 使用正则化约束
• 在代价函数后面添加正则化项,可以避免训练出来的参数过大从而使模型过拟合。使用正则化缓解过拟合的手段广泛应用,不论是在线性回归还是在神经网络的梯度下降计算过程中,都应用到了正则化的方法。常用的正则化有l1正则和l2正则,具体使用哪个视具体情况而定,一般l2正则应用比较多
3. 减少特征数
• 欠拟合需要增加特征数,那么过拟合自然就要减少特征数。去除那些非共性特征,可以提高模型的泛化能力
4. 调整参数和超参数
• 不论什么情况,调参是必须的
5. 降低模型的复杂度
• 欠拟合要增加模型的复杂度,那么过拟合正好反过来
6. 使用Dropout
• 这一方法只适用于神经网络中,即按一定的比例去除隐藏层的神经单元,使神经网络的结构简单化
7. 提前结束训练
• 即early stop[pi](http://www.elecfans.com/tags/pi/)ng,在模型迭代训练时候记录训练精度(或损失)和验证精度(或损失),倘若模型训练的效果不再提高,比如训练误差一直在降低但是验证误差却不再降低甚至上升,这时候便可以结束模型训练了
从偏差与方差的角度来分析模型常常会有四种情况:
偏差很低,方差很高: 意味着训练误差很低,测试误差很高,此时发生了过拟合现象。
偏差很高,方差很低: 意味着训练误差,测试误差都很高,此时发生了欠拟合现在。
偏差,方差都很高: 意味着此时同时发生了欠拟合和过拟合现象。
偏差很低,方差很低: 意味着训练误差很低,测试误差也很低,表示我们的模型训练的结果很好。
loss曲线:X轴为训练集大小时,Y轴为错误率、loss时。可以用于判断数据集的数量是否合适,有无必要继续增加数据量。
Python 中一切皆对象,这些对象的内存都是在运行时动态地在堆中进行分配的,就连 Python 虚拟机使用的栈也是在堆上模拟的。既然一切皆对象,那么在 Python 程序运行过程中对象的创建和释放就很频繁了,而每次都用 malloc() 和 free() 去向操作系统申请内存或释放内存就会对性能造成影响,毕竟这些函数最终都要发生系统调用引起上下文的切换。其实核心就是池化技术,一次性向操作系统申请一批连续的内存空间,每次需要创建对象的时候就在这批空间内找到空闲的内存块进行分配,对象释放的时候就将对应的内存块标记为空闲,这样就避免了每次都向操作系统申请和释放内存,只要程序中总的对象内存空间稳定,Python 向操作系统申请和释放内存的频率就会很低。数据库连接池也是类似的思路。一般后端应用程序也是提前跟数据库建立多个连接,每次执行 SQL 的时候就从中找一个可用的连接与数据库进行交互,SQL 完成的时候就将连接交还给连接池,如果某个连接长时间未被使用,连接池就会将其释放掉。本质上,这些都是用空间换时间,消耗一些不算太大的内存,降低诸如内存申请和 TCP 建立连接等耗时操作的频率,提高程序整体的运行速度。
Python 内存管理器对内存进行了分层
每个 pool 内的 block 的大小是相等的,不同 pool 的 block 大小可以不等。

意思不同
.h中一般放的是同名.c文件中定义的变量、数组、函数的声明,需要让.c外部使用的声明。
.c文件一般放的是变量、数组、函数的具体定义。
用法不同
.c文件,以c为扩展名,一般存储具体功能的实现。
.h文件,称为头文件,一般存储类型的定义,函数的声明等。通常,头文件被.c文件包含,使用#include 语句。但值得注意的是,这只是一种约定,而非强制。
.c 和 .h 文件作用
如果在.h文件中实现一个函数体,那么如果在多个.c文件中引用它,而且又同时编译多个.c文件,将其生成的目标文件连接成一个可执行文件,在每个引用此.h文件的.c文件所生成的目标文件中,都有一份这个函数的代码,如果这段函数又没有定义成局部函数,那么在连接时,就会发现多个相同的函数,就会报错。
如果在.h文件中定义全局变量,并且将此全局变量赋初值,那么在多个引用此.h文件的.c文件中同样存在相同变量名的拷贝,关键是此变量被赋了初值,所以编译器就会将此变量放入DATA段。
最终在连接阶段,会在DATA段中存在多个相同的变量,它无法将这些变量统一成一个变量,也就是仅为此变量分配一个空 间,而不是多份空间,假定这个变量在.h文件没有赋初值,编译器就会将之放入BSS段,连接器会对BSS段的多个同名变量仅分配一个存储空间。
.c 和 .h 文件的关系
高手写程序时,发现别人写的严格的程序都带有一个“KEY.H”,里面定义了.C文件里用到的自己写的函数。
.H文件就是头文件,估计就是Head的意思吧,这是规范程序结构化设计的需要,既可以实现大型程序的模块化,又可以实现根各模块的连接调试。
两者都是代码,为什么要做这样的区分呢?
主要有几点好处:
是头文件用于共享,只用一句#include就能包含,当然.c也可以包含;
如果你要写库的话,可是你又不想暴露你的源代码,你可以把.c编译成.obj或是.lib发给别人用,然后把.h作为使用说明书。
所以一般情况下,.h里面全部都是声明,.c里面全部都是实现,有了.h就可以编译。
.h文件的由来:
“在编译器只认识.c(.cpp))文件,而不知道.h是何物的年代,那时的人们写了很多的.c(.cpp)文件,渐渐地,人们发现在很多.c(.cpp)文件中的声明语句就是相同的,但他们却不得不一个字一个字地重复地将这些内容敲入每个.c(.cpp)文件。但更为恐怖的是,当其中一个声明有变更时,就需要检查所有的.c(.cpp)文件
于是人们将重复的部分提取出来,放在一个新文件里,然后在需要的.c(.cpp)文件中敲入#include XXXX这样的语句。这样即使某个声明发生了变更,也再不需要到处寻找与修改了。因为这个新文件,经常被放在.c(.cpp)文件的头部,所以就给它起名叫做“头文件”,扩展名是.h。
闪击PPT闪击PPT - 高效内容演示 (sankki.com)
Mindshow首页 - MindShow,让想法快速展示
ChatPDF聊天PDF - 与任何PDF聊天! (chatpdf.com)
ChatExcel酷表ChatExcel
热心网友通过 Notion 收集了这份英文版本的 ChatGPT 使用指南课程,在这份课程中拥有超过 1000 多种利用 ChatGPT 改善生活的方式与方法,从整理 Excel 的公式到提高生产力,从改善工作流到AI 写作,仿佛上天入地无所不能,强烈推荐你试试。
https://tested-salto-cab.notion.site/The-Ultimate-Chat-GPT-Course-69ed24a317a942d288e740419b1ad6f6
chatgpt api 接入指南https://juejin.cn/post/7199293850494091301
Base64编码是网络上很常见的用于8Bit字节码的编码方式之一
什么是Base64 编码
Base64是一种用64个字符来表示任意二进制数据的方法。它是一种编码方式,而非加密方式。它通过将二进制数据转变为64个“可打印字符”,完成了数据在HTTP协议上的传输。Base64是从二进制数据到字符的过程。所以计算机中所有的内容,包括文本、图片、音频、视频等等都可以使用Base64编码来表示。
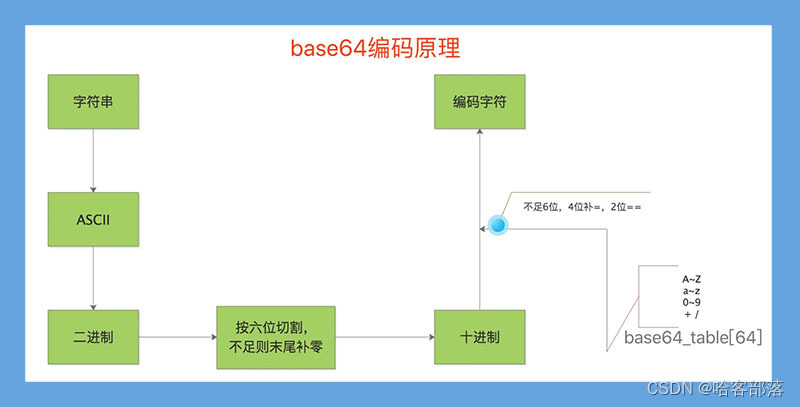
为什么要使用Base64 编码
1、电子邮件协议smtp只能传输ASCII码可打印字符(注:[0,31],及127, 33个属于不可打印的控制字符),所以可以使用base64编码解决;
2、在传输数据中进行简单加密,不会一眼看出明文;
3、http协议中,可对图片的资源进行base64处理,使接口格式统一。
Base64 编码有哪些优缺点
优点:减少一个图片的http请求。
缺点:
1、根据Base64的编码原理,编码后的大小会比原文件大小大1/3,如果把大图片编码到html/css中,不仅会造成文件体积增加,影响文件的加载速度,还会增加浏览器对html或css文件解析渲染的时间。
2、使用Base64无法直接缓存,要缓存只能缓存包含base64的文件,比如HTML或者CSS,这相比于直接缓存图片的效果要差很多。
3、兼容性的问题,ie8以前的浏览器不支持;一般一些网站的小图标可以使用base64图片来引入。
Base64 是加密算法吗?
Base64 主要不是用来加密的,它主要的用途是把一些二进制数转成普通字符用于网络传输,这是因为一些二进制字符在传输协议中属于控制字符,不能直接在网络上传输。另外,还有一些系统中只能使用ASCII字符。
Base64 编码就是用来将非ASCII字符的数据转换成ASCII字符的一种方法。Base64 并不是安全领域下的加密解密算法,虽然有时候也会经常看到所谓的Base64加密解密算法。 其实Base64只能算是一个编码算法,对数据内容进行编码来适合网络传输。虽然Base64编码过后原文也变成无法直接理解的字符格式,但是这种编码方式比较初级,很简单,很容易就可以被还原成原文,所以如果有比较重要的信息需要加密,一定要使用我们之前文章中介绍的那些加密算法进行数据的安全保护。
Base64 是一种常见数据编码方式,常用于数据传输。对于移动开发者来讲,网络请求中会经常使用到。对 JSON 熟悉的同学都知道,JSON 的序列化工具都不支持将 byte 数组直接放入 JSON 数据中,针对这种二进制数据,在处理的时候,都需要进行 Base64 编码,然后将编码后的字符串放入到 JSON 中。 从刚入行到现在,Base64 是一个非常常用的功能,从网上“搬运” Base64 编解码工具到使用 Android SDK 中内置的 Base64。虽熟练使用,但终未深入了解 Base64 的底层机制。
巧的是,近期工作中,又遇到了 Base64 的相关事情,于是去相对深入了解了 Base64 的相关内容。以下仅作为自身学习记录。
Base64 定义 Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法,用人话讲叫可以把二进制数据打印在控制台上,可以很好的拷贝以及传输。
在编码中使用的 64 个可打印字符只需要 6 个 Bit 位就可以表示:2^6 = 642
在计算机世界中,3 个 Byte 的二进制数据相当于 24 个 Bit , 因此在编码时需要对应 4 个 Base64 的字符来表示。
Base64 的可打印字符集包含了字母 A-Z、a-Z、数字 0-9, 这样就有了 62 个字符,另外两个在不同的系统中可能会不同,我们一般使用的为 + 、 /,在 URL Safe 的模式下为 -、_
Base64 码表:
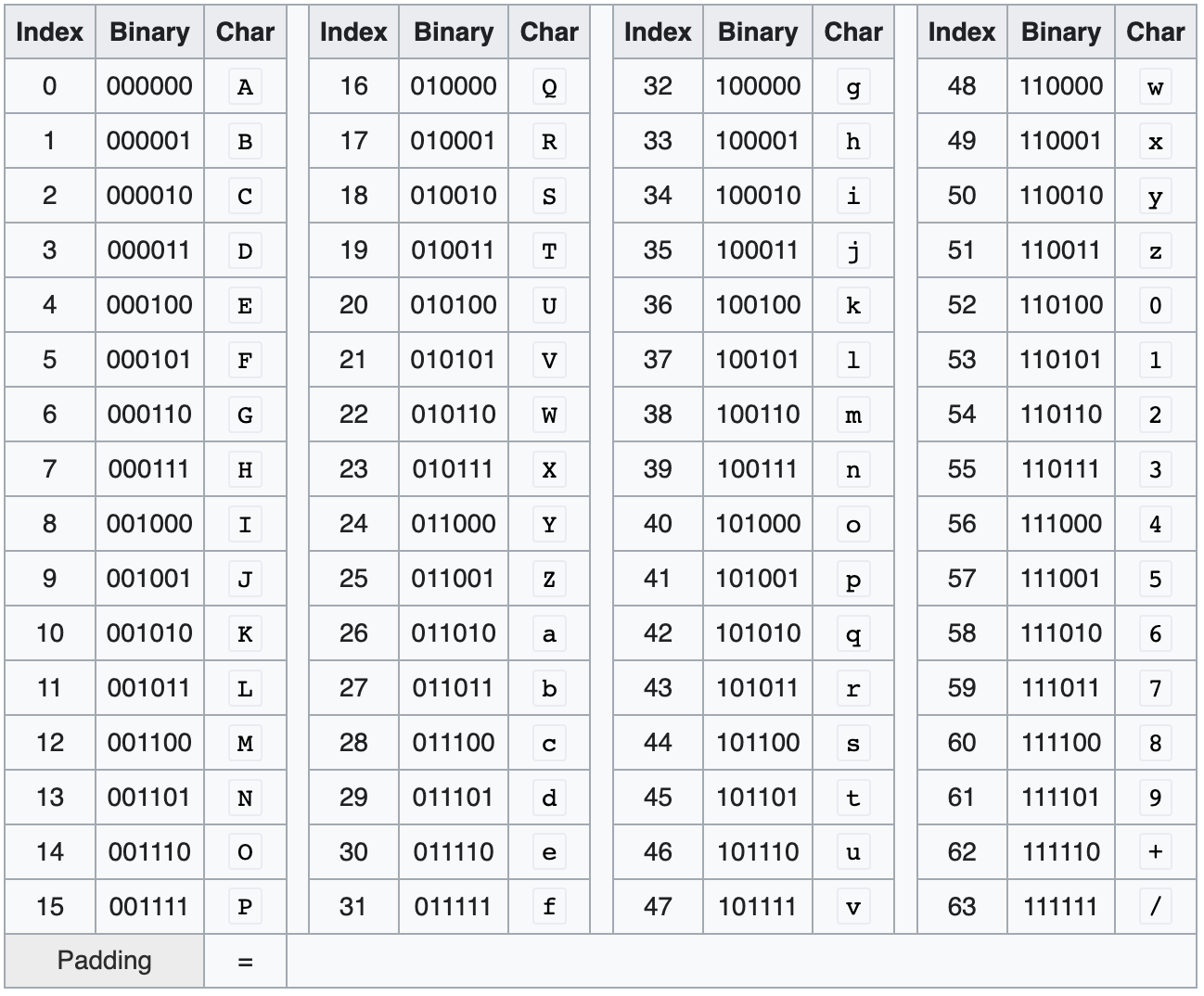
Base64 转换
我们将 byte 数组中的每一个 byte 都转换成 8 位 bit, 组成一串二进制数据,然后按 6 位进行分割,再将每 6 位转换成一个 bit ,将转换后的 bit 作为 index ,去码表中查找对应显示的字符。
编码示例如下:
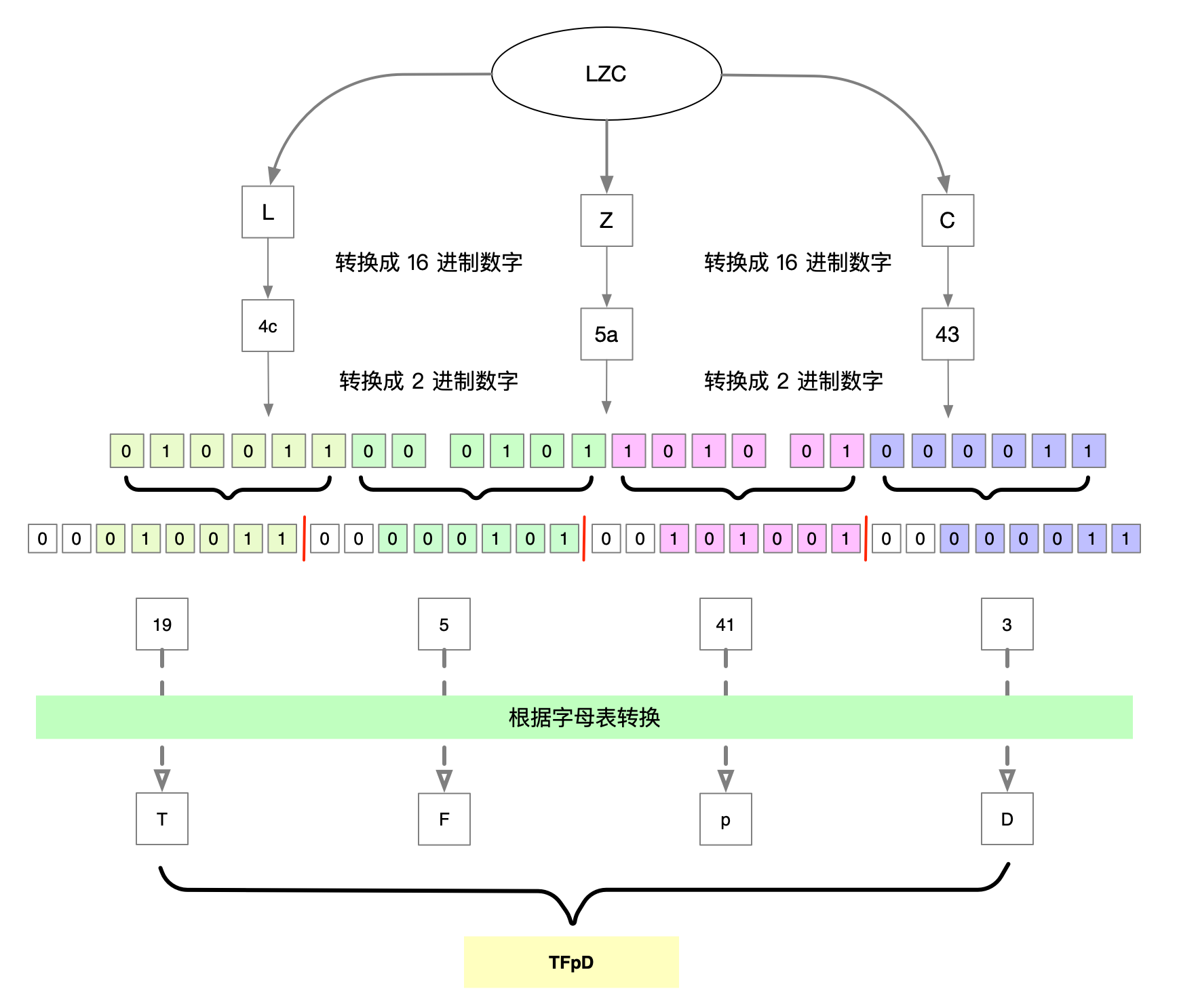
如上图所示,将 LZC 转换成 Base64 编码的可打印的字符串为 TFpD。 从这个示例可以看出来,刚好可以将 3 个 byte 转成 4 个 byte。
聪明的你可能已经发现存在的问题,如果要编码的原始 byte[] 的长度不能被三整除应该怎么处理呢?
在码表中,除了编码中用到的 64 个字符,在末尾还有一个填充字符: = ,用来填充不足的位数。
举例说明:
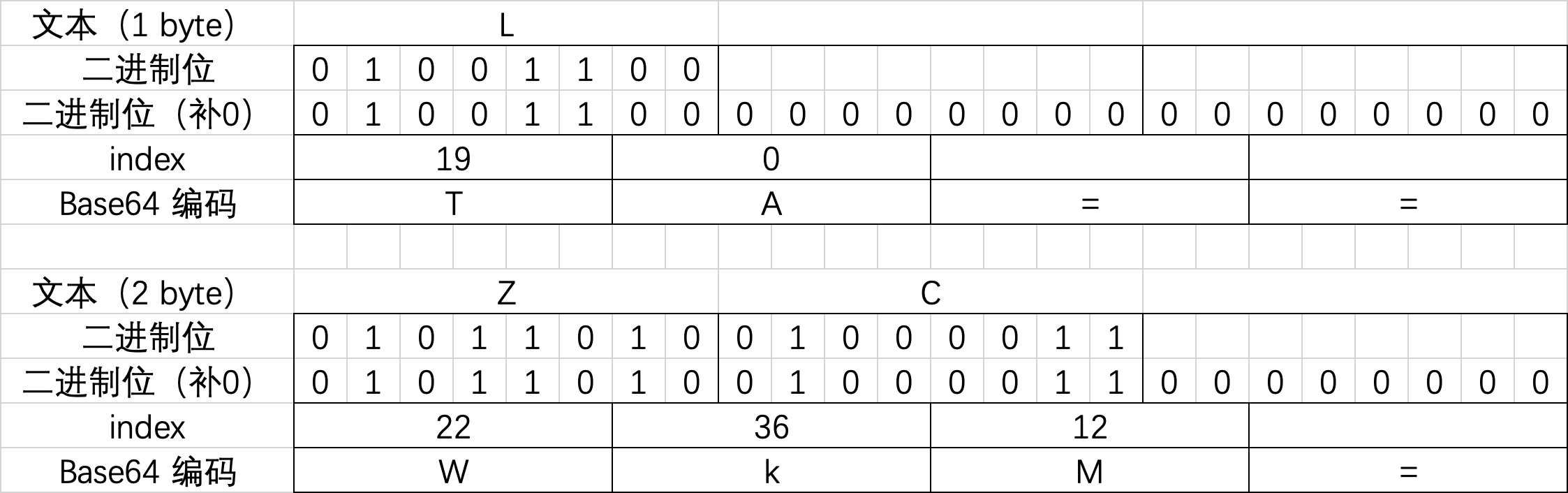
思考一:Base64 编码一定要添加填充(Padding)吗? 在前文中,对于不足 3 个 byte 的数据转换过程中,需要在编码后的串中加入填充字符 = ,让最后输出的 Base64 的串正好是 4 的整数倍。那么问题来了,为什么要使用 = 号进行填充?不填充可以吗?
在 android.utils.Base64 的实现中,有一个叫 NO_PADDING 的 flag。如果在使用的过程中,传入了这个 flag,最后的输出结果就是没有埋充 = 的结果。 因此,在进行编码的时候,对于不足 3 个 byte 的数据处理时,也可以不进行填充。
当然,如果进行填充,在解码的时候,能够更加简单的去处理,直接将编码的串,4 个字符一组进行处理,而不用判断字符数量,走不同的解码逻辑。当然,Padding 还可以用来标识编码结束,来防止多个 Base64 拼接到一起后,解码失败。
思考二:Base64 是否可以认为是一种加密方式呢? Base64 是一种编码方式,将原始数据转换成了一种可打印的字符串。 在工作中,也经常会有人称之为 Base64 加密 ,按照 加密 的定义:
以某种特殊的算法改变原有的信息数据,使得未授权的用户即使获得了已加密的信息,但因不知解密的方法,仍然无法了解信息的内容。
对于 Base64 来讲,在使用的过程中,早已经遵从了常用的编码标准: RFC 4648 以及 RFC 2045,使用标准的码表来进行处理,并不能算得上是“加密”,但如果,在进行编解码的过程中,使用特殊的码表,可以让编码的内容不容易被解码出来,也可以实现对原始内容的“加密”功能。
ROS是机器人领域中比较受到关注的一种系统,它的应用比较方便而且有许多的工具比如传感器驱动包可以直接使用。但是ROS对于传感器数据有自己的格式和规范。而在OpenCV中,图像是以Mat矩阵的形式存储的,这与ROS定义的图像消息的格式有一定的区别,所以我们需要利用cv_bridge将这两种不相同的格式联系起来,如下图所示。

- ROS图像消息转换为OpenCV图像的函数 cv_bridge源码中执行转换的类为CvImage,该类包含了OpenCV的Mat格式的图像、该消息的encoding以及ROS header。类在源码中的定义如下:
namespace cv_bridge {
class CvImage
{
public:
std_msgs::Header header;
std::string encoding;
cv::Mat image;
};
typedef boost::shared_ptr<CvImage> CvImagePtr;
typedef boost::shared_ptr<CvImage const> CvImageConstPtr;
}
当cv_bridge将ROS的图像消息转换为OpenCV图像格式时都是通过CvImage类实现的。一般来说,cv_bridge提供了两种方式转换为CvImage类,分别为复制(copy)和共享(share)。
// Case 1: Always copy, returning a mutable CvImage
CvImagePtr toCvCopy(const sensor_msgs::ImageConstPtr& source,
const std::string& encoding = std::string());
CvImagePtr toCvCopy(const sensor_msgs::Image& source,
const std::string& encoding = std::string());
// Case 2: Share if possible, returning a const CvImage
CvImageConstPtr toCvShare(const sensor_msgs::ImageConstPtr& source,
const std::string& encoding = std::string());
CvImageConstPtr toCvShare(const sensor_msgs::Image& source,
const boost::shared_ptr<void const>& tracked_object,
const std::string& encoding = std::string());
上面是这两类方式实现的函数对应为toCvCopy和toCvShare,两个函数的输入有两个:图像消息的指针和可选的编码参数。这两个函数的区别: (1)toCvCopy函数会从ROS消息中拷贝一个图像数据,不管如何修改CvImage类的内容都不会影响源数据,使用例子如下。
cv::Mat img;
cv_bridge::CvImagePtr cv_ptr;
cv_ptr = cv_bridge::toCvCopy(msg, "mono8");
cv_ptr->image.copyTo(img);
(2)toCvShare函数则是在源和编码都匹配的情况下将返回的OpenCV指针指向ROS的消息,即共享指针地址。它的特点是只要你还保持着返回的CvImage类的副本,那么ROS的消息类型就不会被释放。当编码参数不匹配时,它还能够另外开辟一个新的缓存区并执行编码参数转换工作。toCvShare函数对于有一个指向另一个相同类型消息的指针时会很方便(比如双目图像)。如果没有给定编码类型时,toCvShare会使目标图像编码将会与消息编码相同。toCvShare函数的使用例子如下。
cv::Mat img;
cv_bridge::CvImageConstPtr cv_ptr;
cv_ptr=cv_bridge::toCvShare(msg, "mono8");
img = cv_ptr->image;
CvBridge中常用的编码有以下那么几种:
mono8: CV_8UC1, grayscale image
mono16: CV_16UC1, 16-bit grayscale image
bgr8: CV_8UC3, color image with blue-green-red color order
rgb8: CV_8UC3, color image with red-green-blue color order
bgra8: CV_8UC4, BGR color image with an alpha channel
rgba8: CV_8UC4, RGB color image with an alpha channel
- OpenCV图像转换为ROS消息的函数 在CvImage类中执行的OpenCV图像转换为ROS消息的成员函数为 toImageMsg(),其源码中的定义如下所示:
class CvImage
{
sensor_msgs::ImagePtr toImageMsg() const;
// Overload mainly intended for aggregate messages that contain
// a sensor_msgs::Image as a member.
void toImageMsg(sensor_msgs::Image& ros_image) const;
};
该函数的输入有三个:标准消息包的头、图像编码和OpenCV源图像,使用例程如下:
cv::Mat image = cv::imread(......);
sensor_msgs::ImagePtr msg = cv_bridge::CvImage(std_msgs::Header(), "bgr8", image).toImageMsg();
本次笔记大部分参考的是ROS官网给出的一些的定义和技术细节,网址如下:
第一个参数ret的值为True或False,代表有没有读到图片
第二个参数是frame,是当前截取一帧的图片。
cv2.VideoCapture()中第一参数为0,代表使用的是电脑的内置摄像头;
ret, frame = cap.read()中,cap.read()是按帧读取,其会返回两个值:ret,frame(ret是布尔值,如果读取帧是正确的则返回True,如果文件读取到结尾,它的返回值就为False;后面的frame该帧图像的三维矩阵BGR形式。)
FinClip 是一款小程序容器,不论是 移动App ,还是 电脑、电视、车载主机等设备 ,在集成 FinClip 小程序SDK 之后,都能快速获得 运行小程序 的能力。
FinClip 是与“微信小程序”、“百度小应用”等其他小程序开放平台具有类似属性的技术平台。FinClip 的核心是提供一个小程序容器技术。它由能渲染与执行小程序的客户端引擎、统一管理小程序上下架的中心、支撑小程序服务器端运行的云端设施、以及合规监管工具共同组成。
https://www.zhihu.com/question/432239913/answer/2269030011
https://www.finclip.com/mop/document/develop/guide/feature.html#%E9%80%BB%E8%BE%91%E5%B1%82
10 分钟搭建自己的专属 ChatGPThttps://www.finclip.com/blog/chatgptwithfinclip/
https://juejin.cn/post/7203153899246223397
处理请求对的服务器:
1 debug server. 单进程单线程处理 请求串行,后面的会被阻塞;开启多线程 性能会得到提升
2 WSGI server . WSGI server是通过进程(pre-fork)来并发的。这样并发就取决与进程数。如果WSGI server用了gevent, eventlet等 green thread技术,就可以支持更多并发。
app = Flask() @app.route('/')
def index():
return render_temple('index.html')
这段程序只是一个APP服务的一个路由。你的APP服务又被用WSGI接入到HTTP服务器,就是你说的nginx。这个问题跟nginx无关,因为这里它只是一个通道。跟Flask也无关,因为它只是负责根据Request产生Response。有关的就是WSGI server。通常来讲WSGI server是通过进程(pre-fork)来并发的。这样并发就取决与进程数。如果WSGI server用了gevent, eventlet等 green thread技术,就可以支持更多并发。
IPV4中,0.0.0.0地址被用于表示一个无效的,未知的或者不可用的目标。
- 在服务器中,0.0.0.0指的是本机上的所有IPV4地址,如果一个主机有两个IP地址,192.168.1.1 和 10.1.2.1,并且该主机上的一个服务监听的地址是0.0.0.0 和端口 8080,那么通过这两个<ip地址:8080>都能够访问该服务。
- 在路由中,0.0.0.0表示的是默认路由,即当路由表中没有找到完全匹配的路由的时候所对应的路由。
用途总结
- 当一台主机还没有被分配一个IP地址的时候,用于表示主机本身。(DHCP分配IP地址的时候)
- 用作默认路由,表示”任意IPV4主机”。
- 用来表示目标机器不可用。
- 用作服务端,表示本机上的任意IPV4地址。
网关地址 0.0.0.0 表示直连规则,即当前记录对应的 Destination 跟本机在同一个网段,通信时不需要经过网关(路由器)。也就是说使用二层交换机通过MAC即可通信。
- 命中容器的路由表直连规则,意思是目的IP是在局域网内,不用走到出口网关
- 局域网内直接是通过二层网络来发送包。
IP地址的基本概念
IP地址是互联网协议地址的缩写,是分配给网络中每个设备的唯一标识,用于在网络中进行通信。就像我们现实生活中的门牌号一样,每个设备的IP地址帮助数据包找到正确的接收设备。
公网IP和内网IP
- 公网IP(公有IP):全球唯一的,可以直接访问互联网的IP地址。由Internet NIC(因特网信息中心)分配,不能重复。
- 内网IP(私有IP):在局域网内部使用的IP地址,不直接与互联网连接。常见的内网IP范围有:
- A类:10.0.0.0 - 10.255.255.255
- B类:172.16.0.0 - 172.31.255.255
- C类:192.168.0.0 - 192.168.255.255
内网IP通过NAT(网络地址转换)技术可以转换成公网IP,实现内网设备访问互联网。
localhost、127.0.0.1和0.0.0.0的区别
localhost
- 定义:localhost是一个域名,通常被解析为127.0.0.1,但实际指向的IP地址可以在系统中配置。
- 作用:用于表示本机的回环地址,即本机自己。
127.0.0.1
- 定义:这是一个回环地址,属于127.0.0.0/8这个网络段,专门用于本地回环测试。
- 作用:任何发送到127.0.0.1的数据都会被本机自己接收,不会经过网络接口。常用于测试网络服务是否正常。
0.0.0.0
- 定义:在IP地址中,0.0.0.0表示所有IP地址,通常用于绑定网络服务时,表示监听所有网络接口。
- 作用:当服务器绑定到0.0.0.0时,意味着它会接收来自所有网络接口的连接请求,包括本地回环和所有公网IP。
本机IP
- 定义:本机IP是指设备在局域网内的实际IP地址,例如192.168.10.128。
- 作用:用于在同一局域网内设备之间的通信,也可以通过NAT转换访问互联网。
具体例子分析
假设有一个局域网内有两台PC,分别是PC1和PC2,PC1有一个网卡,IP地址为192.168.10.128。
情况1:PC1上的服务器监听127.0.0.1
-
PC1的客户端:
- 连接127.0.0.1:成功,因为服务器监听的是本地回环地址。
- 连接192.168.10.128:失败,因为服务器没有监听本机IP。
-
PC2的客户端:
- 连接127.0.0.1:失败,因为127.0.0.1是PC1的回环地址,PC2无法访问。
- 连接192.168.10.128:失败,同上。
情况2:PC1上的服务器监听192.168.10.128
-
PC1的客户端:
- 连接192.168.10.128:成功,因为服务器监听的是本机IP。
- 连接127.0.0.1:失败,因为服务器没有监听回环地址。
-
PC2的客户端:
- 连接192.168.10.128:成功,如果PC2在同一局域网内并且网络连通。
情况3:PC1上的服务器监听0.0.0.0
-
PC1的客户端:
- 连接127.0.0.1和192.168.10.128:都成功,因为服务器监听所有接口。
-
PC2的客户端:
- 连接192.168.10.128:成功,如果网络连通。
为什么在情况2中,PC1的客户端无法连接127.0.0.1
因为服务器只监听了192.168.10.128这个IP地址,没有监听127.0.0.1。虽然PC1的127.0.0.1和192.168.10.128都是本机的IP地址,但它们是不同的接口,服务器需要分别监听才能接受相应的连接请求。
总结
- localhost:域名,通常指向127.0.0.1,但可以配置为其他IP。
- 127.0.0.1:本地回环地址,用于本机测试。
- 0.0.0.0:表示所有IP地址,用于监听所有网络接口。
- 本机IP:实际在局域网内的IP地址,用于局域网内通信。
假设有如下目录结构:
-- dir0
| file1.py
| file2.py
| dir3
| file3.py
| dir4
| file4.py
dir0文件夹下有file1.py、file2.py两个文件和dir3、dir4两个子文件夹,dir3中有file3.py文件,dir4中有file4.py文件。
1.导入同级模块
python导入同级模块(在同一个文件夹中的py文件)直接导入即可。
import xxx如在file1.py中想导入file2.py,注意无需加后缀".py":
import file2
# 使用file2中函数时需加上前缀"file2.",即:
# file2.fuction_name()2.导入下级模块
导入下级目录模块也很容易,需在下级目录中新建一个空白的__init__.py文件再导入:
from dirname import xxx如在file1.py中想导入dir3下的file3.py,首先要在dir3中新建一个空白的__init*__*.py文件。
-- dir0
| file1.py
| file2.py
| dir3
| __init__.py
| file3.py
| dir4
| file4.py
再使用如下语句:
# plan A
from dir3 import file3或是
# plan B
import dir3.file3
# import dir3.file3 as df3但使用第二种方式则下文需要一直带着路径dir3书写,较为累赘,建议可以另起一个别名。
3.导入上级模块
要导入上级目录下模块,可以使用sys.path:
import sys
sys.path.append("..")
import xxx 如在file4.py中想引入import上级目录下的file1.py:
import sys
sys.path.append("..")
import file1**sys.path的作用:**当使用import语句导入模块时,解释器会搜索当前模块所在目录以及sys.path指定的路径去找需要import的模块,所以这里是直接把上级目录加到了sys.path里。
**“..”的含义:**等同于linux里的‘..’,表示当前工作目录的上级目录。实际上python中的‘.’也和linux中一致,表示当前目录。
4.导入隔壁文件夹下的模块
如在file4.py中想引入import在dir3目录下的file3.py。
这其实是前面两个操作的组合,其思路本质上是将上级目录加到sys.path里,再按照对下级目录模块的方式导入。
同样需要被引文件夹也就是dir3下有空的__init__.py文件。
-- dir
| file1.py
| file2.py
| dir3
| __init__.py
| file3.py
| dir4
| file4.py
同时也要将上级目录加到sys.path里:
import sys
sys.path.append("..")
from dir3 import file35.常见错误及import原理:
在使用直接从上级目录引入模块的操作时:
from .. import xxx经常会报错:
ValueError: attempted relative import beyond top-level package这是由于相对导入时,文件夹实质上充当的是package,也就是包的角色(比如我们常用的numpy、pandas都是包)。如果python解释器没有认同该文件夹是package,那么这就是一个普通的文件夹,无法实现相对导入。
文件夹作为package需要满足如下两个条件:
- 文件夹中必须存在有__init__.py文件,可以为空。
- 不能作为顶层模块来执行该文件夹中的py文件。
ssh -L 9090:localhost:9090 [email protected] ssh -L 9090:localhost:9090 [email protected]
https://uestc.feishu.cn/wiki/XCgxwHY8yiqtMIkQhYuc5qornqy http://localhost:9090/ui/
SSH 是 Secure Shell 的缩写,它是一种网络协议,用于在不安全的网络中为计算机设备之间提供安全的加密通信。SSH 协议主要用于远程登录和执行命令,但它也支持多种网络服务,包括文件传输。
通过 SSH 协议,用户可以安全地访问远程服务器,执行命令,管理文件,以及运行各种应用程序。SSH 使用公钥加密来验证远程计算机和允许远程计算机验证用户,确保通信的安全性和数据的隐私。
SSH 主要有两大版本:SSH-1 和 SSH-2。SSH-2 是较新的版本,解决了 SSH-1 中的一些安全问题,并且具有更强的安全功能和更好的性能。
使用 SSH 的一个常见场景是通过 SSH 客户端从本地计算机安全地连接到一个远程服务器。在命令行界面中,可以使用如下命令来建立 SSH 连接:
ssh username@remote_host 这里的 是你在远程主机上的用户名,而 是远程服务器的IP地址或域名。输入正确的密码或使用SSH密钥对进行身份验证后,用户就可以安全地访问远程主机了。usernameremote_host
SSH 也常与其他技术一起使用,如:
SFTP(SSH File Transfer Protocol)或 SCP(Secure Copy)用于在计算机之间安全地传输文件。 SSH密钥,一种基于公钥加密的身份验证方法,提供比传统密码更安全的登录方式。 SSH端口转发,允许将数据从一个网络端口转发到另一个,这可以用来建立安全的隧道。 总体而言,SSH 是在不安全的网络上进行安全远程操作的标准工具。
SSH密钥身份验证的例子: SSH密钥身份验证是使用一对密钥(公钥和私钥)进行验证的过程,其中公钥可以安全地存储在远程服务器上,而私钥则必须保密并存储在客户端。以下是生成和使用SSH密钥进行身份验证的基本步骤:
在客户端生成密钥对。可以使用工具来生成密钥对:ssh-keygen
ssh-keygen -t rsa -b 4096 -C "[email protected]"
-t rsa指定使用RSA加密算法,-b 4096指定密钥长度为4096位,-C后面跟的是一个注释,通常是你的电子邮件地址。
安全复制公钥到远程服务器。可以使用工具来做这件事:ssh-copy-id
ssh-copy-id username@remote_host
这里的username是你远程服务器上的用户名,而remote_host是远程服务器的IP地址或域名。执行这个命令后,它会要求你输入密码来完成复制过程。
使用SSH密钥进行身份验证。一旦公钥存储在远程服务器的文件中,你可以使用私钥进行无密码登录:~/.ssh/authorized_keys
ssh username@remote_host
如果你的私钥有密码保护,系统可能会要求你输入私钥的密码。之后,你将不需要再输入用户密码就能安全登录服务器。 SSH端口转发的例子: SSH端口转发可以将远程服务器上的一个端口转发到本地计算机或反方向的操作,通常用于访问那些直接访问不了的服务。以下是两种类型的SSH端口转发的例子:
本地端口转发:将本地端口转发到远程服务器上的某个端口。例如,如果你想通过SSH安全地连接到远程服务器上的数据库(如MySQL运行在默认的3306端口),你可以如下设置本地端口转发:
ssh -L 9000:localhost:3306 username@remote_host
这将把本地机器上的9000端口转发到远程主机的3306端口。现在,你可以在你的本地机器上使用localhost的9000端口来访问远程服务器上的MySQL服务。
远程端口转发:将远程服务器上的端口转发到本地计算机上的某个端口。例如,如果你想让远程服务器上的一台机器访问你本地机器上的一个Web服务(假设运行在本地的8080端口),你可以设置远程端口转发:
ssh -R 8000:localhost:8080 username@remote_host
这将把远程服务器上的8000端口转发到你的本地主机的8080端口。现在,远程用户可以访问他们的8000端口来连接到你的本地8080端口提供的Web服务。 SSH端口转发是一种强大的工具,可以用来安全地穿越防火墙、访问内网资源或为没有直接互联网连接的服务提供临时的外部访问。
黑白电视呈现的图像通常可以被视为灰度图像,而彩色电视使用的色彩模型通常是RGB。
灰度图像(黑白电视): 灰度图像仅包含亮度信息,没有色彩。灰度图中的每个像素仅反映了那个点的亮度或暗度程度。在黑白电视中,不同级别的灰度用来表示不同的明暗度,从纯黑(最暗)到纯白(最亮)。黑白电视的技术仅需关注亮度的变化,没有色彩数据。
RGB(彩色电视): RGB是一种颜色模型,代表红(Red)、绿(Green)、蓝(Blue)这三个颜色通道的混合。彩色电视及计算机屏幕通常使用RGB模型来显示全彩图像。每个像素的颜色由这三种颜色以不同的强度组合而成。理论上,RGB模型能够通过不同比例的混合来创造出几乎所有可感知的颜色。
彩色电视标准,如NTSC、PAL和SECAM,是设计出来传输和显示彩色图像的。电视中的彩色信号通常包含一个亮度部分(在NTSC中称为Y,代表亮度)和两个色度部分(在NTSC中分别称为I和Q),这些分量结合起来显示出丰富的彩色图像。这样,彩色电视不仅能显示灰度级别,还能显示各种颜色。
当彩色电视接收到黑白信号时,它也能正确显示为灰度图像,因为亮度信号是兼容的。
红色(Red)、绿色(Green)和蓝色(Blue)被选为彩色视觉再现系统中的三原色是基于人类视觉系统的生理特性。人类眼睛中有三种不同类型的视锥细胞,分别对这三种颜色的光波长较为敏感:
S型视锥细胞对蓝色光(短波长)最敏感。 M型视锥细胞对绿色光(中波长)最敏感。 L型视锥细胞对红色光(长波长)最敏感。 因此,通过调整不同强度的红、绿、蓝三种颜色的光,可以混合出人眼能够感知的几乎所有颜色,这个过程被称为加色混合(Additive Color Mixing)。这三种颜色作为三原色,是因为它们无法通过混合其他颜色而产生,但却能混合出许多其他颜色。这些特性使得RGB成为电视和计算机显示器等设备的理想选择。
至于谁“规定”的问题,其实这不是被某个人或组织规定的,而是根据人类视觉科学的研究发现确定的。自19世纪起,科学家便开始研究颜色理论和人类视觉系统,其中托马斯·杨(Thomas Young)和赫尔曼·冯·亥姆霍兹(Hermann von Helmholtz)对于颜色视觉的三色理论有很大的贡献。这些研究形成了我们现在所知的关于颜色感知和颜色混合的科学基础。
现代的设备和技术通常基于这种理论,设计了适应人眼视觉感应的系统,使得RGB模型成为了业界的一种标准。当然,除了RGB以外,还有其他的颜色模型和三原色系统被用于不同的目的,例如在印刷中使用的CMYK(青色Cyan、洋红色Magenta、黄色Yellow和黑色Key)颜色模型。
印刷业普遍采用CMYK颜色模型而非RGB模型,这主要是因为这两种颜色系统的工作原理和用途不同。RGB是一种加色模型(additive color model),而CMYK是一种减色模型(subtractive color model)。
RGB模型(加色系统): RGB模型是用于电子显示设备如电脑屏幕、电视机和手机屏等,它是基于光的原理,其中红色、绿色和蓝色光按不同的强度组合以创造出其他颜色。当这些颜色混合在一起时,它们会形成更亮的色彩,最终三种颜色光线齐全且亮度都达到最大值时,合成的颜色是白色。
CMYK模型(减色系统): 印刷模型使用的是减色系统,这意味着它是基于吸收光线的原理。当我们在白色纸张上打印时,纸张将反射大部分光(除非纸张本身偏向某种颜色)。CMYK代表青色(Cyan)、洋红色(Magenta)、黄色(Yellow)和黑色(Key,原指版面定位的关键黑色)。在印刷过程中,这些油墨相互叠加吸收了一部分光,每种颜色吸收掉光谱中的某些部分,反射其他部分。例如,黄色吸收蓝光,青色吸收红光,洋红色吸收绿光。通过组合这些颜色的不同量和强度,可以形成他们之间的混合颜色。理论上,CMY三种颜色混合等于黑色,但实际上这种混合常常产生一种暗褐色,且耗墨较多,因此印刷中通常额外加入了黑色墨水(K)以产生更深更纯的黑色以及更高的打印效率。
因此,RGB适合用于发光的设备,而CMYK更适合用于印刷,因为在吸收和反射光线的过程中可以更精确地控制颜色。印刷时如果使用RGB,将无法有效地通过油墨的叠加来复位屏幕上看到的颜色,且无法使用RGB中的“白色”,因为纸张上无法打印出白色(纸张自身就是白色的)。
https://blog.csdn.net/Backli/article/details/131554069
主要区别如下:
- JSON 文件:
使用大括号 {} 表示对象,使用方括号 [] 表示数组。
整个文件是一个有效的 JSON 对象或数组。
适合存储结构化的数据,如配置文件、API 响应等。
一次性读取整个文件,解析成一个 JSON 对象,可以随机访问其中的数据。
- JSONL 文件:
每行是一个独立的有效 JSON 对象。
每行之间没有逗号或其他分隔符。
适合存储每行为独立记录的数据,如日志、传感器数据、日志行等。
逐行读取文件,逐行解析 JSON 对象,一次处理一行的数据。
- JSONL 文件适合用于以下情况:
当数据以行为单位独立存储,并且每行数据之间没有明确的分隔符时。
当需要逐行处理数据,以节省内存和提高处理速度时。
当数据量非常大,无法一次性加载到内存中时,JSONL 格式提供了一种流式处理数据的方式。
这么对比下来,JSON 文件更适合结构化的数据存储和传输,而 JSONL 文件更适合每行为独立记录的数据存储和处理。
project目录详解
project-root/
├── backend/ # 后端代码目录
│ ├── api/ # API接口目录
│ │ ├── v1/ # API版本控制
│ │ └── __init__.py
│ ├── core/ # 核心业务逻辑
│ │ ├── models/ # 数据模型
│ │ ├── services/ # 业务服务
│ │ └── utils/ # 工具函数
│ ├── tests/ # 后端测试
│ ├── config.py # 配置文件
│ └── requirements.txt # 后端依赖
│
├── frontend/ # 前端代码目录
│ ├── src/ # 源代码
│ │ ├── api/ # API调用
│ │ ├── components/ # React组件
│ │ ├── pages/ # 页面
│ │ ├── store/ # 状态管理(Redux等)
│ │ └── utils/ # 工具函数
│ ├── public/ # 静态文件
│ ├── package.json # 前端依赖
│ └── README.md
│
├── assets/ # 共享资源目录
│ ├── images/ # 图片资源
│ │ ├── logo/
│ │ └── icons/
│ ├── fonts/ # 字体文件
│ ├── styles/ # 共享样式
│ └── documents/ # 文档资源
│
├── docs/ # 项目文档
│ ├── api/ # API文档
│ ├── frontend/ # 前端文档
│ └── backend/ # 后端文档
│
├── scripts/ # 部署/构建脚本
│ ├── deploy/
│ └── build/
│
├── .gitignore
├── README.md
└── docker-compose.yml # 容器编排
assets目录详解
assets/
├── images/ # 图片资源
│ ├── logo/ # logo相关
│ │ ├── logo.svg
│ │ └── favicon.ico
│ ├── icons/ # 图标资源
│ └── backgrounds/ # 背景图片
│
├── fonts/ # 字体文件
│ ├── roboto/
│ └── open-sans/
│
├── styles/ # 共享样式资源
│ ├── variables.scss # 样式变量
│ └── mixins.scss # 样式混合
│
├── documents/ # 文档资源
│ ├── templates/ # 文档模板
│ └── exports/ # 导出文档
│
└── media/ # 多媒体文件
├── videos/
└── audio/
前端代码组织(以React为例)
frontend/
├── src/
│ ├── api/ # API请求
│ │ ├── auth.js
│ │ └── users.js
│ │
│ ├── components/ # 组件
│ │ ├── common/ # 通用组件
│ │ ├── layout/ # 布局组件
│ │ └── features/ # 功能组件
│ │
│ ├── pages/ # 页面
│ │ ├── Home/
│ │ ├── Login/
│ │ └── Dashboard/
│ │
│ ├── store/ # 状态管理
│ │ ├── actions/
│ │ ├── reducers/
│ │ └── index.js
│ │
│ ├── styles/ # 样式
│ │ ├── global.scss
│ │ └── variables.scss
│ │
│ ├── utils/ # 工具函数
│ │ ├── auth.js
│ │ └── helpers.js
│ │
│ ├── App.js
│ └── index.js
│
├── public/ # 静态资源
├── package.json
└── README.md
开发流程建议
1. 资源管理
- 共享资源放在根目录的assets/
- 前端专用资源放在frontend/public/
- 使用CDN的资源在配置文件中管理
2. 前后端分离开发
# 后端开发
cd backend
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python manage.py runserver # 假设使用Django
# 前端开发
cd frontend
npm install
npm start
3. 开发环境配置
// frontend/src/config.js
export const API_URL = process.env.NODE_ENV === 'production'
? 'https://api.example.com'
: 'http://localhost:8000';
4. API开发流程
- 在backend/api/定义接口
- 在frontend/src/api/实现调用
- 使用Swagger或其他工具生成API文档
5. 资源使用建议
// 引用assets中的资源
import logo from '@/assets/images/logo/logo.svg';
// 使用样式变量
import '@/assets/styles/variables.scss';
6. 部署考虑
使用Docker容器化
前端静态文件可部署到CDN
后端API部署到应用服务器
前后端通信最佳实践
1. API版本控制
backend/api/v1/users.py
frontend/src/api/v1/users.js
2. 状态管理
// frontend/src/store/actions/auth.js
export const login = (credentials) => async (dispatch) => {
try {
const response = await api.auth.login(credentials);
dispatch({ type: 'LOGIN_SUCCESS', payload: response.data });
} catch (error) {
dispatch({ type: 'LOGIN_ERROR', payload: error });
}
};
3. 错误处理
// frontend/src/utils/api.js
const handleError = (error) => {
if (error.response) {
// 处理后端返回的错误
}
throw error;
};
netstat -ano | findstr 7860
输出 TCP 0.0.0.0:7860 0.0.0.0:0 LISTENING 154896
杀进程
taskkill /PID 154896 /F
成功: 已终止 PID 为 154896 的进程。
OpenAPI 和 SDK(Software Development Kit,软件开发工具包)都是与API(Application Programming Interface,应用程序编程接口)相关的,但它们在概念和用途上有所不同:
- OpenAPI:
- OpenAPI 是一个规范,用于描述RESTful API(一种基于HTTP协议的API)。它允许开发者使用一个统一的方式来编写和使用API。
- OpenAPI规范通常包括API的端点、请求方法、参数、请求和响应的数据结构等信息。
- 它允许开发者通过阅读OpenAPI文档来理解API的功能,而无需查看具体的实现代码。
- SDK:
- SDK 是一套工具、库、文档和示例代码的集合,用于帮助开发者在特定平台上构建应用程序。
- SDK通常包括API的客户端库,这些库提供了一种简便的方式来与API进行交互,而不需要开发者自己处理底层的网络通信细节。
- SDK可以是针对特定编程语言的,例如Java SDK、Python SDK等,它们封装了API调用,使得开发者可以更加专注于业务逻辑的实现。
简而言之,OpenAPI是一种API描述规范,而SDK是一种帮助开发者更容易使用API的工具集。两者都是API生态系统中的重要组成部分,但它们服务于不同的目标和用途。
API(Application Programming Interface,应用程序编程接口)是一个广泛的概念,它指的是软件系统之间进行交互的一套规则和定义。在这个大概念下,OpenAPI 和 SDK 都是实现API交互的不同形式。
- OpenAPI 是一种规范,它定义了如何描述API,使得开发者能够通过阅读文档来了解API的功能和使用方法。OpenAPI规范通常使用YAML或JSON格式来编写,它详细描述了API的端点、请求方法、参数、请求和响应的数据结构等。
- SDK 可以看作是对OpenAPI规范的进一步封装。它提供了一套工具和库,使得开发者在使用特定API时更加方便。SDK通常包括了API的客户端库,这些库会根据OpenAPI规范来实现API调用的细节,让开发者可以更加专注于应用逻辑的实现,而不需要处理底层的网络请求等细节。
因此,虽然OpenAPI和SDK都是API实现的一部分,但它们在实现方式和使用层面上有所区别。统一称为API是因为它们都是实现应用程序之间交互的接口,只是表现形式和使用方式不同。
一百零二、机器学习/深度学习比赛网站
1、Kaggle
https://www.kaggle.com/
2、AI研习社
https://god.yanxishe.com/
3、FlyAI
https://www.flyai.com/
4、天池
https://tianchi.aliyun.com/
5、百度点石
https://dianshi.bce.baidu.com/competition
6、京东JDATA
https://jdata.jd.com/index.html
7、和鲸社区Kesci
https://www.kesci.com/
8、华为云
https://competition.huaweicloud.com/home
9、腾讯广告算法大赛
https://algo.qq.com/
10、DC竞赛
https://dev.ehualu.com/dev/home/homePage
11、DCLAb
https://www.dclab.run/index.html
12、讯飞开放平台
http://challenge.xfyun.cn/
13、九天
https://jiutian.10086.cn/
14、datafountain
https://www.datafountain.cn/
15、赛氪竞赛
https://www.saikr.com/
- 计算机视觉(CV)竞赛: 10个案例
- 自然语言处理(NLP)竞赛: 4个案例
- 多模态竞赛: 4个案例
- 时序数据竞赛: 5个案例
这个汇总为数据科学爱好者和专业人士提供了一个很好的资源,可以了解不同领域的挑战和最新趋势。它涵盖了从医疗、农业到金融、教育等多个行业的应用,展示了数据科学在各个领域的广泛应用和重要性。
本文汇总了计算机视觉(CV)、自然语言处理(NLP)、多模态和时序数据四个方向的经典数据科学竞赛案例。
-
Image Matching Challenge 2023(kaggle-2023图像匹配大赛)
- 📅 2023.4.11-2023.6.12
- 👤 78+支队伍
- 💰 $50,000
- 方向: CV-三维重建
- 竞赛链接
- 介绍: 参赛者在帮助建立准确的3D模型方面的工作可能会应用于摄影、文化遗产保护和谷歌的许多服务。
-
Vesuvius Challenge - Ink Detection(kaggle-图书墨水检测大赛)
- 📅 2023.3.15-2023.6.14
- 👤 579+支队伍
- 💰 $1,000,000
- 方向: CV-语义分割
- 竞赛链接
- 介绍: 在本次比赛中,参赛者的任务是检测3D X射线扫描中的墨水并读取内容。
-
Google - Isolated Sign Language Recognition(kaggle-Google手语识别大赛)
- 📅 2023.2.23-2023.5.1
- 👤 1080+支队伍
- 💰 $100,000
- 方向: CV-图像分类
- 竞赛链接
- 介绍: 本次比赛的目的是对孤立的美国手语(ASL)标志进行分类。参赛者将创建一个TensorFlow Lite模型,该模型使用MediaPipe整体解决方案提取的标记数据进行训练。
-
UW-Madison GI Tract Image Segmentation
-
Global Wheat Detection
-
HuBMAP - Hacking the Kidney
-
Cassava Leaf Disease Classification
-
Bristol-Myers Squibb – Molecular Translation
-
SETI Breakthrough Listen - E.T. Signal Search
-
TensorFlow - Help Protect the Great Barrier Reef
- BirdCLEF 2023
- 📅 2023.3.7-2023.5.24
- 👤 831+支队伍
- 💰 $50,000
- 方向: NLP-语音识别的多标签多分类任务
- 竞赛链接
- 介绍: 在这次比赛中,参赛者将使用先进的机器学习技能,通过声音识别东非鸟类物种。通过算法以处理连续的音频数据,并通过其呼叫来识别物种。
-
CommonLit Readability Prize
-
NBME - Score Clinical Patient Notes
-
U.S. Patent Phrase to Phrase Matching
-
Stable Diffusion - Image to Prompts
- 📅 2023.2.13-2023.5.15
- 👤 1034+支队伍
- 💰 $50,000
- 方向: 多模态、数据挖掘、时序预测
- 竞赛链接
- 介绍: 比赛的目标是扭转生成文本到图像模型的典型方向:不是从文本提示生成图像,而是可以创建一个模型来预测给定生成图像的文本提示。参赛选手需要对包含由Stable Diffusion 2.0生成的各种(提示、图像)对的数据集进行预测,以了解潜在关系的可逆性。
-
Predict Student Performance from Game Play
- 📅 2023.2.6-2023.6.14
- 👤 1454+支队伍
- 💰 $55,000
- 方向: ML+ NLP 多模态任务
- 竞赛链接
- 介绍: 比赛的目标是实时预测学生在游戏中的学习表现。我们将基于大量的游戏log来预测学生们对知识的掌握程度。
-
Shopee - Price Match Guarantee
-
PetFinder.my - Pawpularity Contest
- CAFA 5 Protein Function Prediction
- 📅 2023.4.18-2023.8.21
- 👤 111+支队伍
- 💰 $50,000
- 方向: ML、时序预测
- 竞赛链接
- 介绍: 该竞赛的目标是预测一组蛋白质的功能。参赛者将开发一个针对蛋白质的氨基酸序列和其他数据进行训练的模型。
-
M5 Forecasting - Accuracy
-
Riiid Answer Correctness Prediction
-
Jane Street Market Prediction
-
Optiver Realized Volatility Prediction
一个用户的状态变化不会影响其他用户的会话。
-
组件状态的隔离: 每个组件都有自己的状态,状态的改变只会触发该组件及其子组件的重新渲染。
-
JSX的虚拟DOM: React通过JSX创建虚拟DOM,当组件状态发生变化时,React会比较新旧虚拟DOM,只更新发生变化的部分,从而提高性能。
为什么这个特性很重要?
- 可维护性: 每个组件都可以独立开发和测试,减少了组件之间的耦合。
- 性能: 避免了不必要的重新渲染,提高了应用的性能。
- 用户体验: 确保每个用户都有独立的会话,不会受到其他用户操作的影响。
数据流单向流动: React的数据流通常是单向的,从父组件向子组件传递,这使得应用的状态管理更加清晰。
函数式编程思想: React鼓励使用函数式编程的思维来构建组件,这有助于编写更纯净、可测试的代码。
-
Windows 与 Unix 系统的区别:
- 在 Windows 的
cmd中,使用curl发送 JSON 数据时,需使用双引号"包裹整个 JSON 字符串,内部的双引号不需要转义。 - 在 Unix-like 系统(如 Linux 或 macOS)中,可以使用单引号
'包裹 JSON 字符串,而无需担心转义问题。
- 在 Windows 的
-
正确格式示例:
-
Windows
curl -N -H "Content-Type: application/json" -H "Authorization: Bearer your_token" -d "{\"report\":\"长时间发现电池短路\",\"stream\":true}" http://127.0.0.1:5000/api/result-report -
Unix-like 系统
curl -N -H "Content-Type: application/json" -H "Authorization: Bearer your_token" -d '{"report":"长时间发现电池短路","stream":true}' http://127.0.0.1:5000/api/result-report
-
-
错误提示: 如果格式不正确,服务器会返回
400 Bad Request错误,表明请求格式不被服务器理解。
关键要点
- 确保 JSON 数据的引号使用符合操作系统的解析规则。
- 使用
curl发送请求时,了解不同操作系统的命令行行为,避免常见错误。
这两个命令之间的区别在于 JSON 数据的格式和转义方式:curl
-
第一个命令 (Error Case):
bash 复制代码 curl -N -H "Content-Type: application/json" -H "Authorization: Bearer b1811003dc4116fa41f28efa892989d3" -d '{\"report\":\"长时间发现电池短路\",\"stream\":true}' http://127.0.0.1:5000/api/result-report在此命令中,您将在 JSON 数据周围使用单引号,并在其中转义双引号。这在 Windows 上是不正确的,因为它不会像类 Unix 系统那样解释单引号。Windows 要求整个 JSON 有效负载周围加上双引号,并且无需在内部转义双引号。
'``\"``cmd -
第二个命令(成功案例):
bash 复制代码 curl -N -H "Content-Type: application/json" -H "Authorization: Bearer b1811003dc4116fa41f28efa892989d3" -d "{\"report\":\"长时间发现电池短路\",\"stream\":true}" http://127.0.0.1:5000/api/result-report在这里,您将整个 JSON 负载周围使用双引号,这是在 Windows 上格式化 JSON 数据的正确方法。这就是正确处理请求并且您会收到流式响应的原因。
curl
解释:
- Windows 命令行解析:在 Windows 中,命令行 () 处理引号的方式与类似 Unix 的 shell(如 Bash)不同。双引号用于将整个字符串括起来,在它们内部,双引号不需要转义。
cmd.exe - 在 Windows 上更正
curl的 JSON 格式:要在 Windows 命令行中使用发送 JSON 数据,您应该:curl- 使用双引号将 JSON 字符串括起来。
- 避免转义 JSON 字符串中的内部双引号。
- Error Message: 表示服务器无法理解请求格式。这通常发生在 JSON 有效负载格式错误或由于引用不正确而无法正确解析时。
{"error":"400 Bad Request: The browser (or proxy) sent a request that this server could not understand."}
正确的使用摘要:
-
对于 Windows,请使用:
cmdbash 复制代码 curl -N -H "Content-Type: application/json" -H "Authorization: Bearer your_token" -d "{\"report\":\"长时间发现电池短路\",\"stream\":true}" http://127.0.0.1:5000/api/result-report -
对于类 Unix 系统(Linux、macOS),您可以使用:
bash 复制代码 curl -N -H "Content-Type: application/json" -H "Authorization: Bearer your_token" -d '{"report":"长时间发现电池短路","stream":true}' http://127.0.0.1:5000/api/result-report
通过根据您的操作系统使用正确的引用格式,您可以确保正确解释 JSON 有效负载并将其发送到服务器。
在Windows系统下配置Nginx:
-
下载Nginx:
- 访问 http://nginx.org/en/download.html
- 下载适用于Windows的稳定版本
-
解压Nginx:
- 将下载的zip文件解压到一个方便的位置,如
C:\nginx
- 将下载的zip文件解压到一个方便的位置,如
-
配置Nginx:
-
打开
C:\nginx\conf\nginx.conf文件 -
修改配置以适应您的项目结构。例如:
http { server { listen 80; server_name localhost; location / { root C:/path/to/your/project-root/frontend/build; try_files $uri $uri/ /index.html; } location /api { proxy_pass http://localhost:5000; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } } }
-
-
启动Nginx:
- 打开命令提示符(以管理员身份运行)
- 导航到Nginx目录:
cd C:\nginx - 启动Nginx:
start nginx
-
停止Nginx:
nginx -s stop
-
重新加载配置:
nginx -s reload
对于一个深度学习神经网络来说,其通常包含很多卷积层,用于不断提取目标的特征,或对目标进行最终定位或者分类。
1 数据存储精度与存储空间
在深度学习神经网络中,最常见的数据格式是float32,占4个字节(Byte)。类似地,float16,占2个字节。1024个字节为1KB,1024x1024个字节为1MB。那么存储10000个参数需要的内存大小为10000x4 Bytes,约为39KB。存储100万个参数需要的内存大小为39x100/1024MB,约为3.8MB。
- 深度学习神经网络的参数量通常是百万级之上的,所以我们可以将3.8MB看作是一个基本单位,即每一百万个数字需要3.8MB。
- 注意到,不仅仅是参数存储需要空间,数据本身(例如图像的像素、特征图中的每个元素)也是一个数字,也需要相同的存储空间。
2 单层卷积参数量
这里,首先以一层卷积为例,假设卷积为二维卷积Conv2d,输入通道为C1,输出通道为C2,卷积核大小为KxK,batch size大小为N,数据格式为float 32,经过卷积后特征图大小为HxW。
- 那么,卷积本身的参数量为C2xC1xKxK。将C1看作输入数据的特征维度,卷积是要对每个特征维度都进行KxK卷积。每进行一次卷积就可以得到一个HxW的特征图。通道C2相当于进行了C2次卷积,为特征图的每个元素赋予C2个特征。因此,卷积本身的参数量为C2xC1xKxK,亦即模型本身的大小。如果除卷积外,还有偏置参数,那么参数量为C2xC1x(KxK+1)。这里忽略偏置参数量,因为相比总的参数量来说,偏置所占比例较小。
- 在训练阶段,模型还需要存储梯度相关参数,并且不同的优化器需要的参数个数也是不同的。因此,模型参数量至少需要乘以2,即C2xC1xKxKx2。
3 单层输出参数量
输出参数量是指特征图存储的参数量。如上所述,模型输出的特征图尺寸大小为HxW,通道数为C2,那么总的参数量为C2xHxW。对于三维卷积,模型输出的特征图会有三个维度,即HxWxD。
- 在模型训练时,计算还需要存储反向传播的特征图,因此输出参数量也需要乘以2,即C2xHxWx2。由于训练阶段会有多个batch同时进行,因此参数量还需乘上batch size,即NxC2xHxWx2。
4 总体参数量与显存大小
模型总的参数量为各个卷积层参数量之后,每一层参数量用C2xC1xKxK计算。
- 训练阶段总的参数为模型参数量与输出参数量之和,即C2xC1xKxK+NxC2xHxWx2。
- 推理阶段总的参数为模型参数量与输出参数量之和,即C2xC1xKxKx2+C2xHxW。
5 示例
假设C1=256,C2=512,H=128,W=128,K=3,N=8。
- 那么模型参数量为:C2xC1xKxKx2=2359296,存储大小为2359296x4/1024/1024MB=9MB。
- 训练阶段参数量为C2xC1xKxK+NxC2xHxWx2=136577024,显存占用136577024x4/1024/1024MB=521MB。
- 推理阶段参数量为C2xC1xKxKx2+C2xHxW=10747904,显存占用41MB。
- 以上仅仅是就一层而言的计算结果,深度学习神经网络总的参数量、模型大小和显存可以通过逐一计算每层的结果,最后求和即可。
一百零六、[一篇文章让你了解大模型项目的整个研发流程]([一篇文章让你了解大模型项目的整个研发流程 - 知乎 (zhihu.com)])
大模型是什么? 大模型,全名大语言模型.简单来说,模型是AI系统的核心,用于处理数据和执行任务。而“大”模型则是指拥有大量参数的模型。这些参数可以看作是模型的“知识”。例如,OpenAI的GPT-4就是一个具有千亿级参数的大模型。
为什么大模型如此重要?
- 高准确性:随着模型参数的增加,模型通常能更好地学习和适应各种数据,从而提高其预测和生成的准确性。
- 多功能性:大模型通常更为“通用”,能够处理更多种类的任务,而不仅仅局限于特定领域。
- 持续学习:大模型的巨大容量使其更适合从持续的数据流中学习和适应新知识。
大模型的研发流程 大模型的研发流程涵盖了从数据采集到模型训练的多个步骤,以下是详细的过程:
一、数据采集: 这是大模型项目的起点,根据大模型训练的需求收集大量的数据。这些数据可以来自多种来源,如公开的数据集、公司内部的数据库、用户生成的数据、传感器数据等。数据的类型可以多样,包括图像、文本、声音、视频等。 以下是详细的数据采集流程:
- 定义数据需求:确定你需要收集什么样的数据。这应该基于你的问题陈述和项目目标。你需要理解你的问题是什么,然后决定哪种类型的数据(例如,数字、类别、文本、图像等)和哪些特定的特征可能对解决问题有帮助。
- 找到数据源:确定数据来源。这可能包括公开的数据库、在线资源,或者你可以从公司内部的数据库或系统中收集数据。在某些情况下,你可能需要收集新的数据,例如通过调查或实验。
- 数据收集:从选择的数据源中收集数据。这可能涉及到从数据库中导出数据,使用API来收集在线数据,或者使用特殊的数据采集设备。
- 数据存储:将收集到的数据存储在合适的地方,以便进一步处理和分析。这可能涉及到设置数据库或使用文件系统。
- 检查数据质量:查看收集的数据,确保其质量满足需求。你需要检查数据是否完整,是否有错误,是否有重复的数据等。
- 数据整理:如果数据来自多个来源,或者在一个大的数据集中,你可能需要整理数据,使其在一定的上下文中有意义。这可能包括对数据进行排序,或者将数据分组,或者将数据从多个源合并在一起。
数据采集可能是一个持续的过程,特别是对于需要实时更新或处理新信息的项目。在整个数据采集过程中,需要关注数据的质量和一致性,同时也要注意遵守数据隐私和安全的相关规定。
二、数据清洗和预处理: 收集的原始数据可能含有噪声、缺失值、错误数据等,所以首先要对数据进行清洗。清洗后的数据要进行一系列预处理操作,如归一化、编码转换等,使其适合输入到模型中。数据清洗和预处理是数据科学项目的重要步骤,它们有助于提高模型的性能并减少可能的错误。 以下是数据清洗和预处理的详细流程:
**数据质量检查:**这是数据清洗的第一步,其中涉及识别和处理数据集中的错误、重复值、缺失值和异常值。你需要验证数据的完整性、一致性和准确性,确保所有的记录都是准确的,与实际情况相符。
处理缺失值:有多种方法可以处理数据集中的缺失值。这些方法包括:删除包含缺失值的记录;用特定值(如列的平均值、中位数或众数)填充缺失值;使用预测模型(如 KNN 或回归)预测缺失值;或者使用一种标记值来表示缺失值。
**处理重复值:**如果数据集中存在重复的记录,那么可能需要删除这些重复的记录。在一些情况下,重复的记录可能是数据收集过程中的错误,但在其他情况下,重复的记录可能是有意义的,所以这需要根据具体情况来判断。
**处理异常值:**异常值是那些远离其他观察值的值,这些值可能由测量错误或其他原因产生。处理异常值的方法包括:删除这些异常值;使用统计方法(如四分位数间距法)将它们替换为更合理的值;或者使用机器学习算法对其进行预测。
**数据转换:**将数据转换为适合进行分析或建模的形式。这可能包括一下几种形式:
规范化或标准化:将数值特征缩放到同一范围内,如 0 到 1,或者转换为具有零均值和单位方差的值。
**特征工程:**创建新的特征,这些特征可能更好地表达数据的某些方面或者提高模型的性能。
这个流程根据具体的项目和数据集可能会有所不同。在进行数据清洗和预处理时,你需要对数据有深入的理解,以便做出最好的决策。
三、数据标注: 数据标注,也叫数据标记,是一项为原始数据添加元信息的工作,以帮助大模型更好地理解和学习数据。对于监督学习任务,模型需要有标签的数据进行训练,数据标注的目标就是为数据提供这些标签,这个过程可能需要专门的标注团队.对于非监督学习任务,如聚类或生成模型,这一步则不需要。 以下是数据标注详细流程:
理解任务需求:首先需要理解你要解决的问题以及数据标注应该如何进行。例如,如果你在进行图像分类任务,你可能需要给每个图像一个分类标签;如果你在进行物体检测任务,你可能需要在图像中的每个目标物体周围画一个边界框,并给出这个物体的分类标签。
**制定标注规范:**这是一个详细解释如何进行数据标注的指南,它应该解释哪些数据应该被标记,应该如何标记,以及如何处理可能出现的问题或歧义。清晰、详细的标注规范可以帮助保持标注的一致性,并提高标注的质量。
**选择或开发标注工具:**有许多可用的数据标注工具,可以用于各种类型的数据标注任务。你应该选择或开发一个适合你的任务的标注工具。标注工具应该方便使用,提高标注效率,并尽可能减少错误。
**进行数据标注:**按照标注规范,使用标注工具进行数据标注。这可能是一个时间和人力密集型的过程,尤其是当你有大量数据需要标注时。
**质量检查:**检查标注的数据,确保标注的质量。这可能涉及到随机抽查一部分数据,并检查它们是否被正确和一致地标注。
反馈和修正:根据质量检查的结果,如果发现任何问题或不一致,需要反馈给标注团队,并修正错误的标注。
数据标注是一个重要但往往被忽视的步骤。高质量的标注数据对于训练出高性能的机器学习模型至关重要。因此,尽管这是一个复杂和耗时的过程,但投入在这个过程中的努力会得到回报。
四、数据集划分: 数据通常被划分为训练集、验证集和测试集。训练集用于模型训练,验证集用于超参数调整和模型选择,测试集用于最后的模型性能评估。数据集划分是大模型项目中的一个重要步骤,它可以帮助我们更好地理解模型在未见过的数据上的性能。 以下是数据集划分的详细流程:
**确定划分策略:**确定数据集划分的策略,这主要取决于你的数据集的大小和特性。一般的策略是将数据集划分为训练集、验证集和测试集。在大多数情况下,数据被划分为80%的训练集,10%的验证集和10%的测试集,但这并不是硬性规定,具体的划分比例需要根据实际情况来确定。
**随机划分:**为了确保每个划分的数据分布与原始数据集相似,通常需要对数据进行随机划分。这可以通过洗牌数据索引来实现。
**分层抽样:**在某些情况下,你可能需要确保每个划分中各类别的数据比例与整个数据集相同。这称为分层抽样。例如,如果你的数据集是一个二分类问题,你可能希望训练集、验证集和测试集中正负样本的比例都与整个数据集中的比例相同。
**时间序列数据的划分:**对于时间序列数据,数据划分的策略可能会不同。通常,我们不能随机划分数据,而是基于时间来划分数据。例如,我们可能会使用前80%的数据作为训练集,然后使用接下来10%的数据作为验证集,最后10%的数据作为测试集。
**分割数据:**按照你选择的策略,使用编程语言或者数据处理工具来划分数据。
**保存数据:**保存划分后的数据集,以便于后续的训练和测试。确保训练数据、验证数据和测试数据被正确地保存,并且可以方便地加载。
这个流程可能根据数据的类型和任务的需求有所不同。无论如何,正确的数据划分策略对于避免过拟合,以及准确评估模型的性能至关重要。
五、模型设计: 模型设计是大模型项目的关键环节,需要结合项目目标、数据特性以及算法理论选择或设计适合任务的模型架构。大模型可能会使用复杂的深度学习架构,如Transformer、BERT、ResNet等。 以下是一般的模型设计流程:
**理解问题:**首先,你需要理解你要解决的问题,并根据问题类型(例如,分类、回归、聚类、生成模型等)决定采用何种类型的模型。
**选择算法:**根据你要解决的问题,选择合适的机器学习算法。这可能包括决策树、线性回归、逻辑回归、支持向量机、神经网络、集成学习等。在选择算法时,你需要考虑各种因素,如问题的复杂性、数据的大小和维度、计算资源等。
**设计模型架构:**这主要涉及到深度学习模型,你需要设计模型的架构,例如神经网络的层数、每层的节点数、激活函数的选择等。此步骤可能需要根据经验和实验结果进行调整。
**设置超参数:**超参数是在开始学习过程之前设置的参数,而不是通过训练得到的参数。例如,学习率、批量大小、迭代次数等。超参数的选择可能需要通过经验或者系统的搜索(例如,网格搜索、随机搜索或贝叶斯优化)来确定。
**正则化和优化策略:**为了防止过拟合并提高模型的泛化能力,你可能需要使用一些正则化策略,如L1/L2正则化、dropout、early stopping等。同时,你还需要选择合适的优化算法(例如,SGD、Adam、RMSprop等)以及可能的学习率调整策略。
**定义评估指标:**你需要定义合适的评估指标来衡量模型的性能。选择的评估指标应与你的业务目标和模型目标相一致。常见的评估指标包括精度、召回率、F1分数、AUC、均方误差等。
这个流程可能需要根据具体的项目和需求进行迭代和调整。模型设计是一个需要技术知识、经验以及实验验证的过程。在设计模型时,你需要保持对模型复杂性和泛化能力之间平衡的认识,并始终以实现业务目标为导向。
六、模型初始化: 模型初始化是大模型项目中的一个重要步骤。在训练开始前,需要初始化模型的参数。这通常通过随机的方式进行。正确的初始化策略可以帮助模型更快地收敛,并减少训练过程中可能出现的问题。 以下是模型初始化的详细流程:
- 选择初始化策略:有许多不同的初始化策略可以选择,例如零初始化、随机初始化、He初始化、Xavier初始化等。你需要根据你的模型和激活函数来选择合适的初始化策略。例如,如果你的模型使用ReLU激活函数,He初始化可能是一个好的选择;如果你的模型使用tanh或sigmoid激活函数,Xavier初始化可能是一个好的选择。
- 初始化权重:使用选择的初始化策略来初始化模型的权重。对于每一层,你都需要初始化它的权重。在大多数情况下,权重应该被初始化为小的随机数,以打破对称性并保证不同的神经元学到不同的特征。
- 初始化偏置:初始化模型的偏置。在许多情况下,偏置可以被初始化为零。但是,对于某些类型的层(如Batch Normalization层),偏置的初始化可能需要更复杂的策略。
- 设置初始化参数:某些初始化策略可能需要额外的参数。例如,随机初始化可能需要一个范围或者一个标准差,你需要设置这些参数。
- 执行初始化:在你的模型代码中,执行初始化操作。大多数深度学习框架(如TensorFlow和PyTorch)都提供了内置的方法来执行初始化。
模型初始化是一个比较技术性的主题,正确的初始化策略可能对模型的训练速度和性能有很大的影响。你应该了解不同的初始化策略,以便根据你的模型选择最适合的策略。
七、模型训练: 模型训练是大模型项目中的关键步骤,其中包含了多个环节。 以下是大模型训练的详细流程:
**设置训练参数:**首先,你需要设置训练参数,如学习率、训练迭代次数(epochs)、批次大小(batch size)等。
**准备训练数据:**你需要将数据集划分为训练集、验证集和测试集。通常,大部分数据用于训练,一部分用于验证模型性能和调整超参数,剩余的一部分用于测试。
**前向传播:**在前向传播阶段,模型接收输入数据,并通过网络层传递,直到输出层。这个过程中会生成一个预测输出。
**计算损失:**根据预测输出和实际标签,使用损失函数(如均方误差、交叉熵等)计算损失。损失反映了模型预测的准确程度。
**反向传播:**在反向传播阶段,算法计算损失函数关于模型参数的梯度,并根据这些梯度来更新模型参数。这个过程通常使用优化算法(如梯度下降、随机梯度下降、Adam等)来进行。
**验证和调整:**在每个epoch结束后,使用验证集评估模型性能。如果模型在验证集上的性能没有提高,或者开始下降,这可能意味着模型过拟合了。你可能需要调整模型的超参数,或者使用一些正则化技术(如dropout、L1/L2正则化、早停法等)。
**重复上述步骤:**重复前向传播、计算损失、反向传播和验证的步骤,直到模型性能达到满意,或者达到预设的训练迭代次数。
**模型测试:**当模型训练完成后,使用测试集进行最终的性能评估。这能够提供模型在未见过的数据上的性能表现。
以上就是模型训练的基本流程。但需要注意的是,实际操作中可能需要根据特定任务或特定模型进行相应的调整。
八、模型验证: 模型验证是大模型项目中非常关键的一步,目的是在训练过程中,评估模型的性能,定期在验证集上测试模型的性能,监控过拟合,根据测试和监控结果调整模型的超参数。 以下是模型验证的详细流程:
**准备验证集:**在数据集划分阶段,你应该保留一部分数据作为验证集。这部分数据不参与模型训练,仅用于模型验证。
**进行模型预测:**使用训练好的模型对验证集进行预测。通常,在每一轮(epoch)训练结束后进行一次验证。
**计算评估指标:**根据模型在验证集上的预测结果和真实标签,计算相应的评估指标。评估指标的选择取决于你的任务类型,例如,对于分类任务,常见的评估指标有准确率(accuracy)、精确率(precision)、召回率(recall)、F1分数(F1-score)等;对于回归任务,常见的评估指标有均方误差(MSE)、平均绝对误差(MAE)等。
**比较性能:**将这一轮的验证性能与前一轮进行比较。如果性能提高,则可以继续进行下一轮训练;如果性能下降,则可能需要调整学习率、增加正则化等措施。
**早停法:**如果在连续多轮训练后,验证性能没有显著提高,你可以使用早停法(early stopping)来提前结束训练,以避免过拟合。
**调整超参数:**如果模型在验证集上的性能不佳,你可能需要调整模型的超参数,如学习率、批次大小、正则化参数等。一种常用的方法是使用网格搜索(grid search)或随机搜索(random search)等方式来自动搜索最优的超参数组合。
以上就是模型验证的基本流程。需要注意的是,验证集应保持独立,不能用于训练模型,否则就可能导致模型的性能评估不准确,无法真实反映模型在未见过的数据上的性能。
九、模型保存: 模型保存是大模型项目的重要一步,能够让我们将训练好的模型存储起来,以便于后续的测试、部署或进一步训练或分享。 以下是模型保存的详细流程:
**选择保存格式:**你需要选择一个合适的模型保存格式。常用的模型保存格式包括:Python的pickle文件、joblib文件,或者某些深度学习框架的专有格式,如TensorFlow的SavedModel格式和PyTorch的pth格式。你的选择可能会受到你使用的工具和框架、模型的大小和复杂性、以及你的具体需求等因素的影响。
**保存模型参数:**对于神经网络模型,你通常会保存模型的参数(即权重和偏置)。这些参数是通过训练学习到的,可以用于在相同的模型架构上进行预测。
**保存模型架构:**除了模型参数,你也可能需要保存模型的架构。这包括模型的层数、每层的类型(例如,卷积层、全连接层等)、每层的参数(例如,卷积核的大小和数量、步长、填充等)、激活函数的类型等。
**保存训练配置:**此外,你也可能需要保存一些训练的配置信息,如优化器类型、学习率、损失函数类型等。
**执行保存操作:**使用所选工具或框架的保存函数,将模型保存到文件中。通常,这会创建一个可以在其他计算机或在其他时间加载的文件。
**验证保存的模型:**加载保存的模型,并在一些测试数据上运行,以确保模型被正确保存并可以再次使用。
以上就是模型保存的基本流程。需要注意的是,这个流程可能会根据你的具体需求和所使用的工具或框架进行一些调整。
十、模型测试: 模型测试是大模型部署前的最后一步,目的是在测试集上评估模型的最终性能。 以下是模型测试的一般流程:
**准备测试集:**在数据集划分阶段,你应该保留一部分数据作为测试集。这部分数据既不参与训练,也不参与验证,仅用于最后的模型测试。
**进行模型预测:**使用训练并经过验证的模型对测试集进行预测。在此步骤中,你应当使用已保存的模型,而不是在训练过程中任何阶段的模型。
**计算评估指标:**根据模型在测试集上的预测结果和真实标签,计算相应的评估指标。这些指标应当与你在训练和验证阶段使用的指标一致,以便于进行比较。
**分析结果:**除了计算总体的评估指标,你也可以分析模型在特定类型的任务或数据上的性能。例如,你可以查看模型在某个特定类别上的精确率和召回率,或者分析模型在不同难度级别的任务上的表现。
**记录和报告:**记录模型在测试集上的性能,并编写报告。报告应当包含模型的详细信息(例如,架构、训练参数等),以及模型在测试集上的性能结果。
以上就是模型测试的基本流程。需要注意的是,测试集应当保持独立和未知,不能用于训练或验证模型,以确保测试结果能够真实反映模型在实际环境中的表现。
十一、模型部署: 模型部署是将训练好的大模型应用于实际生产环境中,使模型能够对新的数据进行预测。 以下是大模型部署的详细流程:
**模型选择:**在多个模型中选择一个适合部署的模型。这个模型应该是在验证和测试阶段表现最优秀的模型。
**模型转换:**如果需要,将模型转换为适用于特定生产环境的格式。例如,如果你计划在移动设备上运行模型,你可能需要将模型转换为TensorFlow Lite或Core ML格式。
**部署策略:**确定你的模型部署策略。你可能会选择将模型部署在本地服务器上,也可能选择将模型部署在云服务器上。此外,你还需要决定是否使用API、微服务或其他形式来提供模型服务。
**环境配置:**配置你的生产环境。这可能包括安装必要的软件库,设置服务器参数,配置网络等。
**模型加载和测试:**在生产环境中加载你的模型,并对其进行测试,以确保模型在生产环境中能够正确运行。
**模型监控:**设置监控系统,以实时监测模型的性能。如果模型性能下降或出现其他问题,你应该能够及时得到通知。
**模型更新:**根据模型在生产环境中的表现和新的数据,定期更新模型。这可能涉及到收集新的训练数据,重新训练模型,测试新模型,然后将新模型部署到生产环境中。
以上就是模型部署的基本流程。需要注意的是,这个流程可能会根据你的具体需求和所使用的技术进行一些调整。部署机器学习模型是一个复杂的过程,需要考虑的因素很多,如模型性能、可扩展性、安全性、成本等。
一百零七、[什么是 CI/CD ?][(https://zhuanlan.zhihu.com/p/422815048)]
CI/CD 是一种通过在应用开发阶段引入自动化来频繁向客户交付应用的方法。
CI/CD 的核心概念是持续集成、持续交付和持续部署。它是作为一个面向开发和运营团队的解决方案,主要针对在集成新代码时所引发的问题(也称为:“集成地狱”)。
CI/CD 可让持续自动化和持续监控贯穿于应用的整个生命周期(从集成和测试阶段,到交付和部署)。
这些关联的事务通常被统称为 CI/CD 管道,由开发和运维团队以敏捷方式协同支持。
协同开发是目前主流的开发方式,也就是多位开发人员可以同时处理同一个应用的不同模块或者功能。
但是,如果企业计划在同一天,将所有开发分支代码集成在一起,最终可能会花费很多时间和进行很多重复劳动,费事费力。因为代码冲突是难以避免的。
如果开发人员本地的环境和线上不一致的话,那么这个问题就更加复杂了。
持续集成(CI)可以帮助开发者更加方便地将代码更改合并到主分支。
一旦开发人员将改动的代码合并到主分支,系统就会通过自动构建应用,并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏。
如果自动化测试发现新代码和现有代码之间存在冲突,CI 可以更加轻松地快速修复这些错误。

CI 在完成了构建、单元测试和集成测试这些自动化流程后,持续交付可以自动把已验证的代码发布到企业自己的存储库。
持续交付旨在建立一个可随时将开发环境的功能部署到生产环境的代码库。
在持续交付过程中,每个步骤都涉及到了测试自动化和代码发布自动化。
在流程结束时,运维团队可以快速、轻松地将应用部署到生产环境中。
对于一个完整、成熟的 CI/CD 管道来说,最后的阶段是持续部署。
它是作为持续交付的延伸,持续部署可以自动将应用发布到生产环境。
实际上,持续部署意味着开发人员对应用的改动,在编写完成后的几分钟内就能及时生效(前提是它通过了自动化测试)。这更加便于运营团队持续接收和整合用户反馈。
总而言之,所有这些 CI/CD 的关联步骤,都极大地降低了应用的部署风险。
不过,由于还需要编写自动化测试以适应 CI/CD 管道中的各种测试和发布阶段,因此前期工作量还是很大的。
CI/CD 中的“CI”始终指持续集成,它属于开发人员的自动化流程。
成功的 CI 意味着应用代码的新更改会定期构建、测试并合并到共享存储库中。
该解决方案可以解决在一次开发中有太多应用分支,从而导致相互冲突的问题。
CI/CD 中的“CD”指的是持续交付和/或持续部署,这些相关概念有时会交叉使用。两者都事关管道后续阶段的自动化,但它们有时也会单独使用,用于说明自动化程度。
持续交付(第一种CD)通常是指开发人员对应用的更改会自动进行错误测试并上传到存储库(如 GitHub 或容器注册表),然后由运维团队将其部署到实时生产环境中。
这旨在解决开发和运维团队之间可见性及沟通较差的问题。
因此,持续交付的目的就是确保尽可能减少部署新代码时所需的工作量。
持续部署(另一种“CD”)指的是自动将开发人员的更改从存储库发布到生产环境,以供客户使用。
它主要为了解决因手动流程降低应用交付速度,从而使运维团队超负荷的问题。持续部署以持续交付的优势为根基,实现了管道后续阶段的自动化。
所以,用一张图总结一下就是:

CI/CD 既可能仅指持续集成和持续交付构成的关联环节,也可以指持续集成、持续交付和持续部署这三项构成的关联环节。
更为复杂的是,有时“持续交付”也包含了持续部署流程。
归根结底,我们没必要纠结于这些语义,您只需记得 CI/CD 其实就是一个流程(通常形象地表述为管道),用于实现应用开发中的高度持续自动化和持续监控。
一文看懂英伟达A100、A800、H100、H800各个版本有什么区别?_a100 a800-CSDN博客

**据统计NVIDIA当前在售的AI加速卡至少有9款型号,其中高性能的有4款,分别是V100、A800、A100及H100。价格方面,V100加速卡至少10000美元,按当前的汇率,约合6.9万元人民币;A800售价12000美元,约合人民币8.7万元,市场一度炒高到10万元人民币;A100售价在1.5万美元,约合人民币10.8万元;H100加速卡是NVIDIA当前最强的,售价3.65万美元,约合26.4万元人民币。**
- Code:基于JavaScript+HTML原子化开发。
- ProCode:基于框架开发(jQuery、Vue)。
- LowCode:基于可视化配置,需要编程辅助(LowCodeEngin、opentiny)。
- NoCode: 基于可视化界面完成整个应用搭建和发布,无需编码或少量语法定义(amis、nocobase、budibase)。
- AICode: 根据图片(草图、海报、网页截图....)、UI设计稿、大模型生成代码和应用(img-cook、gpt)。
在实现基于前缀树的热词增强时,通常会构建一个包含热词的前缀树。当语音识别系统接收到语音输入时,它会将语音转换为文本,并在前缀树中查找匹配的热词。由于前缀树的结构,这种查找过程非常快速,可以实时进行。一旦找到热词,系统就可以立即将其识别结果输出,而不需要等待整个句子的识别完成。
前缀树,又称字典树或键树,是一种用于快速检索字符串数据集中的键的树形数据结构。它能够高效地存储和检索字符串集合,特别适用于实现自动补全、拼写检查、词频统计等功能。前缀树的主要特点如下:
- 树形结构:前缀树由节点组成,每个节点可以有多个子节点,通常对应于字母表中的一个字符。
- 共享前缀:如果多个字符串有共同的前缀,那么这些字符串在前缀树中会共享相同的路径,直到前缀结束。
- 检索效率:由于前缀共享,前缀树可以高效地检索字符串或其前缀,这对于快速匹配和搜索非常有利。
数据结构
- 节点结构:每个节点通常包含一个字符(或字符的编码),以及指向子节点的指针。根节点不包含任何字符。
- 路径表示字符串:从根节点到某个节点的路径表示一个字符串。例如,如果有一个字符串"cat",那么从根节点到代表"cat"的节点的路径就是"c" -> "a" -> "t"。
- 共享前缀:前缀树可以共享公共前缀,这意味着如果多个字符串有相同的前缀,它们可以共享树中的相同路径,这可以节省存储空间。
- 结束标记:通常,一个节点会有一个标记(如一个布尔值),用来表示该节点是否表示一个完整的字符串的结束。
- 动态构建:前缀树是动态构建的,即在插入新的字符串时,树会根据需要进行扩展。
- 查找效率:前缀树可以非常快速地查找字符串,因为查找操作的时间复杂度通常与字符串的长度成正比,而不是与树中字符串的数量成正比。
- 插入和删除:前缀树也支持高效的字符串插入和删除操作。
前缀树的一个简单例子如下:
root
/ | \
a b c
/ \ |
t n o
| |
g m
在这个例子中,树中存储了字符串 "at", "an", "cat", "cot"。从根节点到每个节点的路径表示一个字符串,例如,"cat" 由路径 "c" -> "a" -> "t" 表示。这个结构使得查找、插入和删除操作都非常高效。
热词增强是指在语音识别过程中,系统会特别关注一些常用的、重要的或者上下文中频繁出现的词汇(热词)。具体来说:
- 热词识别:在语音识别系统中,会预先定义一个热词列表。这些热词可能是基于语言模型统计得到的高频词汇,或者是特定应用场景中的关键词。
- 优先处理:在识别过程中,系统会优先识别这些热词。由于热词在前缀树中的位置较高,可以更快地被检索到,从而提高识别速度。
- 提高准确率:热词增强可以减少识别过程中的歧义,因为热词往往是上下文中的关键信息,正确识别这些词汇可以提高整个句子的识别准确率。
- 上下文适应:在不同的应用场景中,热词可能会有所不同。热词增强允许系统根据上下文动态调整热词列表,以适应不同的识别需求。
支持格式mp3、mp4、mpweg、mpga、m4a、wav、webm
网上博主测试:
在准确性方面,Whisper 对英文的识别错误率为 **4.2**,中文则为 **14.7**。
如果转录的内容是英文,那么用 **samll** 模型就能保证绝大多数正确。
而如果转录的内容是中文,那么至少要用 **medium** 模型,才能保证绝大多数正确。
Whisper 强在多语言支持,还有超高的英语识别率。
经过用中英文歌曲测试后,发现英文歌曲基本没有识别错误,中文歌曲在base模型上有某些错误,在medium模型上效果还是不错,效率相对于其他厂家可能有些慢,但是在gpu上可能会快很多
在将音乐剪切为1分钟,半分钟,10秒钟测试表现得效果还是很好
对于嘈杂的场地录音(人声音较低)的情况下依然可以识别
注意:使用whisper设置参数--language zh,会生成繁体中文的文件。(但是这个应该可以解决)
特别:Whisper 的转录速度,极度依赖显卡的加持。
语音听写流式接口,用于1分钟内的即时语音转文字技术,支持实时返回识别结果,达到一边上传音频一边获得识别文本的效果。
以上测式效果均表现不太好,可能实时性比较好
支持pcm wav amr三种格式,时长为60秒以内
以上测式效果均不太好,如果是良好的环境与声音效果会很好,速度也很快,可能实时性比较好

剪映,通义听悟使用起来不错,感觉对中文效果好一些(明显的是中文首选Funasr,英文首选Whisper)
无论怎样,任何一款语音识别工具都没办法保证 100% 准确。
提示工程指南 | Prompt Engineering Guide (promptingguide.ai)
Advanced Prompt Engineering (thinkific.com)
吴恩达DeepLearning.AI - Learning Platform
下面这个网站是个人网站,以后可以考虑自己部署一个,非常好!!!
openai出的swarm框架
微软的autogen框架
agentchat.conversable_agent |AutoGen (microsoft.github.io)
书生浦语的lagent框架
InternLM/lagent: A lightweight framework for building LLM-based agents (github.com)
Pinecone关于langchain的书籍
LangChain AI Handbook | Pinecone
缺点:前端暂时没开源
可以参考其软件使用流程,目前是特定方向(论文+课题报告)
缺点:闭源
长上下文的大模型
LongWriter - a Hugging Face Space by THUDM
可以关注的国内厂商
面壁智能MiniCPM3-4B (理论上支持无限长文本输入)
目前用法:Prompt---->LLM---->Response
RAG只是多添加一步变为:User Query---->RAG Moudule---->Prompt---->LLM---->Response
其中向量模型是确定的。
RAG 两个关键要素:检索器和知识库 (思路很简单,落地很难))
检索器:混合搜索, 基于关键词和嵌入式的搜索, Reranker(对于生成的候选结果重新排序)等等
知识库: 解析->分块->嵌入->加载 (基本流程)
大致有这些需求
良好的文档准备:文档有md、doc、excel、ppt、pdf(后两个明显较难处理)
分块(切片)方式:固定的长度?连续的文本设置一定的重叠?考虑文本中标题等关键信息? 等等
其所有目的就是---->显示出主题语义(向量化)
内部知识的特殊性: 对于垂直领域的知识(专用术语)识别是有缺陷的。例:缩写所表示的具体含义
User提问的随意性:用户query是较为模糊笼统的,其实际的意图没有完整体现。例如,如果直接问一句“请给我推荐一辆车”,模型不知道用户想要什么价位,什么类型的车,给出的答案肯定是无法满足。
问题解决思路
对文档内容进行处理:针对各种类型的文档,进行定制化的措施,用于完整的提取文档内容(这部分基本上就是花时间就行)
语义切分:对处理后的文档(树状)内容进行语义切分效果应该就可以显现出来。例如语义段落可能较长的可以通过大模型进行摘要
RAG Fusion:当接收用户query时,让大模型生成5-10个相似的query,然后每个query去匹配5-10个文本块,接着对所有返回的文本块再做个**倒排**,如果有需求就再加个精排,最后取Top K个文本块拼接至prompt。目的就是增加文本块的召回率。(时间增加了)
增加追问机制:通过Prompt或者其他方法实现。在Prompt中加入“如果无法从背景知识回答用户的问题,则根据背景知识内容,对用户进行追问,问题限制在3个以内”。(**主要依靠大模型的能力**)
微调向量模型(暂时不需要):解决垂直领域(专用术语),在向量模型中权重过大,query出现的话整个向量就会跑偏。例如:我是ssvip客户,我希望买一辆车。由于sssvip权重高检索可能返回的是ssvip相关的内容。所以需要用垂直领域问答对构建数据集训练向量模型,使得向量模型能够理解垂直领域的场景。
https://github.com/hyintell/RetrievalQA
关于 RAG 的优化方案及评估 - 知乎 (zhihu.com)
大语言模型检索增强生成(RAG)综述 - 知乎 (zhihu.com)
几款文档框架:Mkdocs、Sphinx、Teadocs、docsify-CSDN博客
三大图表库:ECharts 、 BizCharts 和 G2,该如何选择? - 知乎
三大知名向量化模型比较分析——m3e,bge,bce_m3e模型-CSDN博客
-
需求分析不可少,一定要具体列出本次网站项目所要实现的目标,可能包括简单的页面草图与功能方块图等。
-
数据库设计。在需求分析后,开始创建数据模块前,网站中所有会用到的数据内容、格式以及各个数据之间的关系一定要理清,最好事先把要创建的数据表都确定清楚,减少开始设计程序后修改Model的工作。
-
了解网站的每一个页面,并设计网页模板(.html)文件。
-
使用virtualenv创建并启用虚拟机环境。
-
使用pip install安装django。
-
使用django-admin startproject生成项目。
-
使用python manage.py startapp创建app。
-
创建templates文件夹,并把所有网页模板(.html)文件都放在此文件夹中。
-
创建static文件夹,并把所有静态文件(图像文件、.css文件以及.js文件等)都放在此文件夹中。
-
修改settings.py文件,把相关文件夹设置都加入,也把生成的app名称加入INSTALLED_APPS序列中。
-
编辑models.py创建数据库表格。
-
编辑views.py,先import在models.py中创建的数据模型。
-
编辑admin.py,把models.py中定义的数据模型加入,并使用admin.site.register注册新增的类,让admin界面可以处理数据库内容。
-
编辑views.py设计处理数据的相关模块,输入和输出都通过templates相关的模块操作获取来自于网页的输入数据,以及显示.html文件的网页内容。
-
编辑urls.py,先import在views.py中定义的模块。
-
编辑urls.py,创建网址和views.py中定义的模块的对应关系。
-
执行python manage.py makemigrations。
-
执行python manage.py migrate。
-
执行python manage.py runserver测试网站。
在Django的MTV(Model-Template-View)架构中:
- Model 对应 MVC 中的 Model:
- 负责数据和业务逻辑的处理,包括数据的增删改查等操作。
- 无论是MVC还是MTV,Model的职责基本相同。
- Template 对应 MVC 中的 View:
- 在MVC中,View负责生成用户界面。
- 在MTV中,Template负责展示数据和生成最终的HTML页面。
- Template通常不包含业务逻辑,只负责展示数据。
- View 对应 MVC 中的 Controller:
- 在MVC中,Controller负责接收用户的输入,调用Model和View来完成用户请求,并返回响应。
- 在MTV中,View负责处理用户的请求,调用Model获取数据,并将数据传递给Template进行渲染。
- 因此,Django的View更接近于MVC中的Controller。
**MVC:**Model View Controller
**MVVM:**Model View ViewModel (ViewModel是一个单词,不能拆开)
**MVA:**Model View Adapter (只见于Angular,比较冷门,不需要理会)
**MVP:**Model View Presenter (安卓独有概念,只见于安卓开发)
MVW,MV*,MVx: Model View Whatever (也是Angular提出来的概念,因为Angular社区有一个大佬说,与其花费工夫去争论一个架构是MV什么,还不如把它们统一成同一个概念)
**MVCC:**是指“多版本并发控制(Multi-Version Concurrency Control,简称MVCC)”,这是一种并发控制机制,用于处理数据库中的并发事务,确保数据的一致性和隔离性。MVCC允许多个事务同时读取同一数据的旧版本,而不会相互干扰,从而提高数据库的并发性能。