
With the support of big data and AI, Oracle bone script research has entered a new era. This once obscure field is poised to reveal more secrets, offering valuable insights for deciphering other ancient scripts. We aim to open-source Oracle-related datasets and methods, but our efforts alone are not enough. We welcome the community's support to further advance the decoding of Oracle bone script.
1. [ACL-2024 Oral-Best Paper] Deciphering Oracle Bone Language with Diffusion Models
3. [ArXiv-2024] An open dataset for the evolution of oracle bone characters: EVOBC
4. [Scientific Data 2024] An open dataset for oracle bone script recognition and decipherment
Guan, Haisu and Yang, Huanxin and Wang, Xinyu and Han, Shengwei and Liu, Yongge and Jin, Lianwen and Bai, Xiang and Liu, Yuliang.
This paper introduces a novel approach by adopting image generation techniques, specifically through the development of Oracle Bone Script Decipher (OBSD). Utilizing a conditional diffusion-based strategy, OBSD generates vital clues for decipherment, charting a new course for AI-assisted analysis of ancient
languages. To validate its efficacy, extensive experiments were conducted on an oracle bone script dataset, with quantitative results demonstrating the effectiveness of OBSD.
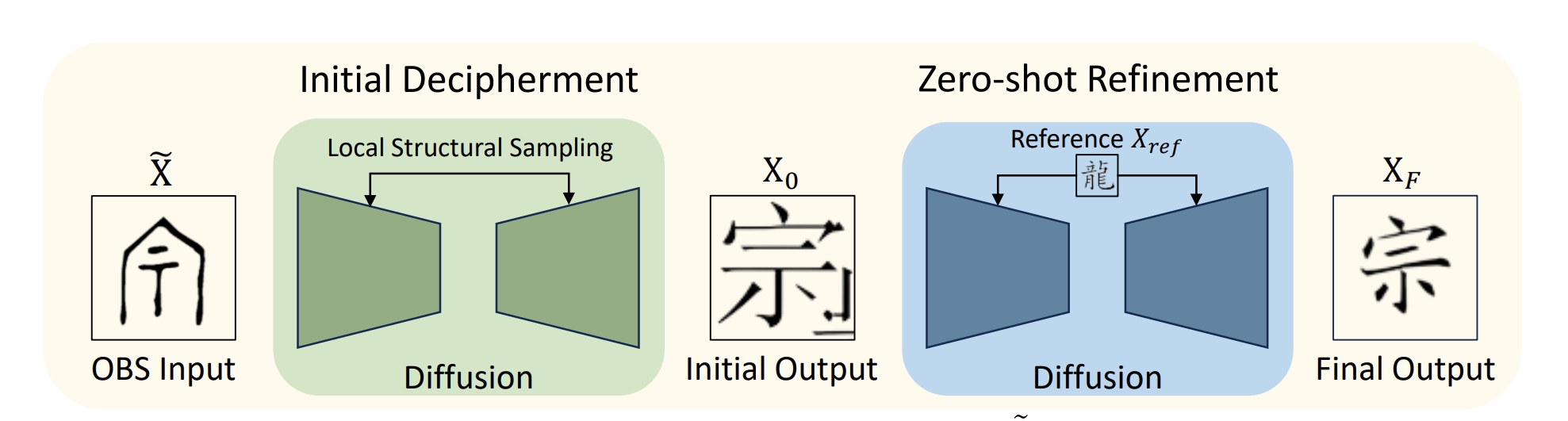
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@inproceedings{guan2024deciphering,
title={Deciphering Oracle Bone Language with Diffusion Model},
author={Guan, Haisu and Yang, Huanxin and Wang, Xinyu and Han, Shengwei and Liu, Yongge and Jin, Lianwen and Bai, Xiang and Liu, Yuliang},
booktitle={Proceedings of the 62th Annual Meeting of the Association for Computational Linguistics},
year={2024}
}📘 [ICDAR-2024 Oral] Puzzle Pieces Picker: Deciphering Ancient Chinese Characters with Radical Reconstruction
Wang, Pengjie and Zhang, Kaile and Wang, Xinyu and Han, Shengwei and Liu, Yongge and Jin, Lianwen and Bai, Xiang and Liu, Yuliang.
This paper introduces a novel approach, namely Puzzle Pieces Picker (P3), to decipher these enigmatic characters through radical reconstruction. We deconstruct OBI into foundational strokes and radicals, then employ a Transformer model to reconstruct them into their modern counterparts, offering a groundbreaking solution to ancient script analysis.

If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@inproceedings{wang2024puzzle,
title={Puzzle Pieces Picker: Deciphering Ancient Chinese Characters with Radical Reconstruction},
author={Wang, Pengjie and Zhang, Kaile and Wang, Xinyu and Han, Shengwei and Liu, Yongge and Jin, Lianwen and Bai, Xiang and Liu, Yuliang},
booktitle={International Conference on Document Analysis and Recognition},
year={2024},
organization={Springer}
}Guan, Haisu and Wan, Jinpeng and Wang, Pengjie and Zhang, Kaile and Kuang, Zhebin and Wang, Xinyu and Shengwei, Han and Yongge Liu and Bai, Xiang and Jin, Lianwen and Liu, Yuliang.
we systematically collected ancient characters from authoritative texts and websites spanning six historical stages: Oracle Bone Characters-OBC (15th century B.C.), Bronze Inscriptions-BI (13th to 221 B.C.), Seal Script-SS (11th to 8th centuries B.C.), Spring and Autumn period Characters-SAC (770 to 476 B.C.), Warring States period Characters-WSC (475 B.C. to 221 B.C.), and Clerical Script-CS (221 B.C. to 220 A.D.). Subsequently, we constructed an extensive dataset, namely EVolution Oracle Bone Characters (EVOBC), consisting of 229,170 images representing 13,714 distinct character categories. We conducted validation and simulated deciphering on the constructed dataset, and the results demonstrate its high efficacy in aiding the study of oracle bone script. This openly accessible dataset aims to digitalize ancient Chinese scripts across multiple eras, facilitating the decipherment of oracle bone script by examining the evolution of glyph forms.

If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@article{guan2024open,
title={An open dataset for the evolution of oracle bone characters: EVOBC},
author={Guan, Haisu and Wan, Jinpeng and Wang, Pengjie and Zhang, Kaile and Kuang, Zhebin and Wang, Xinyu and Shengwei, Han and Yongge Liu and Bai, Xiang and Jin, Lianwen and Liu, Yuliang},
journal={arXiv preprint arXiv:2401.12467},
year={2024}
}Wang, Pengjie and Zhang, Kaile and Liu, Yuliang and Wan, Jinpeng and Guan, Haisu and Kuang, Zhebin and Wang, Xinyu and Jin, Lianwen and Bai, Xiang.
We propose HUST-OBC dataset. This dataset encompasses 77,064 images of 1,588 individual deciphered characters and 62,989 images of 9,411 undeciphered characters, with a total of 140,053 images, compiled from diverse sources.

If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@article{wang2024open,
title={An open dataset for oracle bone script recognition and decipherment},
author={Wang, Pengjie and Zhang, Kaile and Liu, Yuliang and Wan, Jinpeng and Guan, Haisu and Kuang, Zhebin and Wang, Xinyu and Jin, Lianwen and Bai, Xiang},
journal={arXiv preprint arXiv:2401.15365},
year={2024}
}📘 [ArXiv-2024] A Cross-Font Image Retrieval Network for Recognizing Undeciphered Oracle Bone Inscriptions
Zhicong Wu, Qifeng Su, Ke Gu, Xiaodong Shi.
This paper proposes a cross-font image retrieval network (CFIRN) to assist in deciphering Oracle Bone Inscriptions (OBI) by matching undeciphered OBI characters with characters from other script forms. The approach uses a siamese network framework to extract deep features from character images across various fonts. By incorporating a multiscale feature integration (MFI) module and multiscale refinement classifier (MRC), CFIRN effectively retrieves and matches characters from three ancient scripts: Bronze Inscription (BI), Bamboo Slip Inscription (BSI), and Clerical Script (CS). Extensive experiments demonstrate the efficacy of CFIRN, advancing the recognition of undeciphered OBI characters.

If you wish to refer to the baseline results published here, please use the following BibTeX entries:
@article{wu2024cross,
title={A Cross-Font Image Retrieval Network for Recognizing Undeciphered Oracle Bone Inscriptions},
author={Wu, Zhicong and Su, Qifeng and Gu, Ke and Shi, Xiaodong},
journal={arXiv preprint arXiv:2409.06381},
year={2024}
}We welcome suggestions to help us improve the Open-Oracle. For any query, please contact Prof. Yuliang Liu: [email protected]. If you find something interesting, please also feel free to share with us through email or open an issue. Thanks!