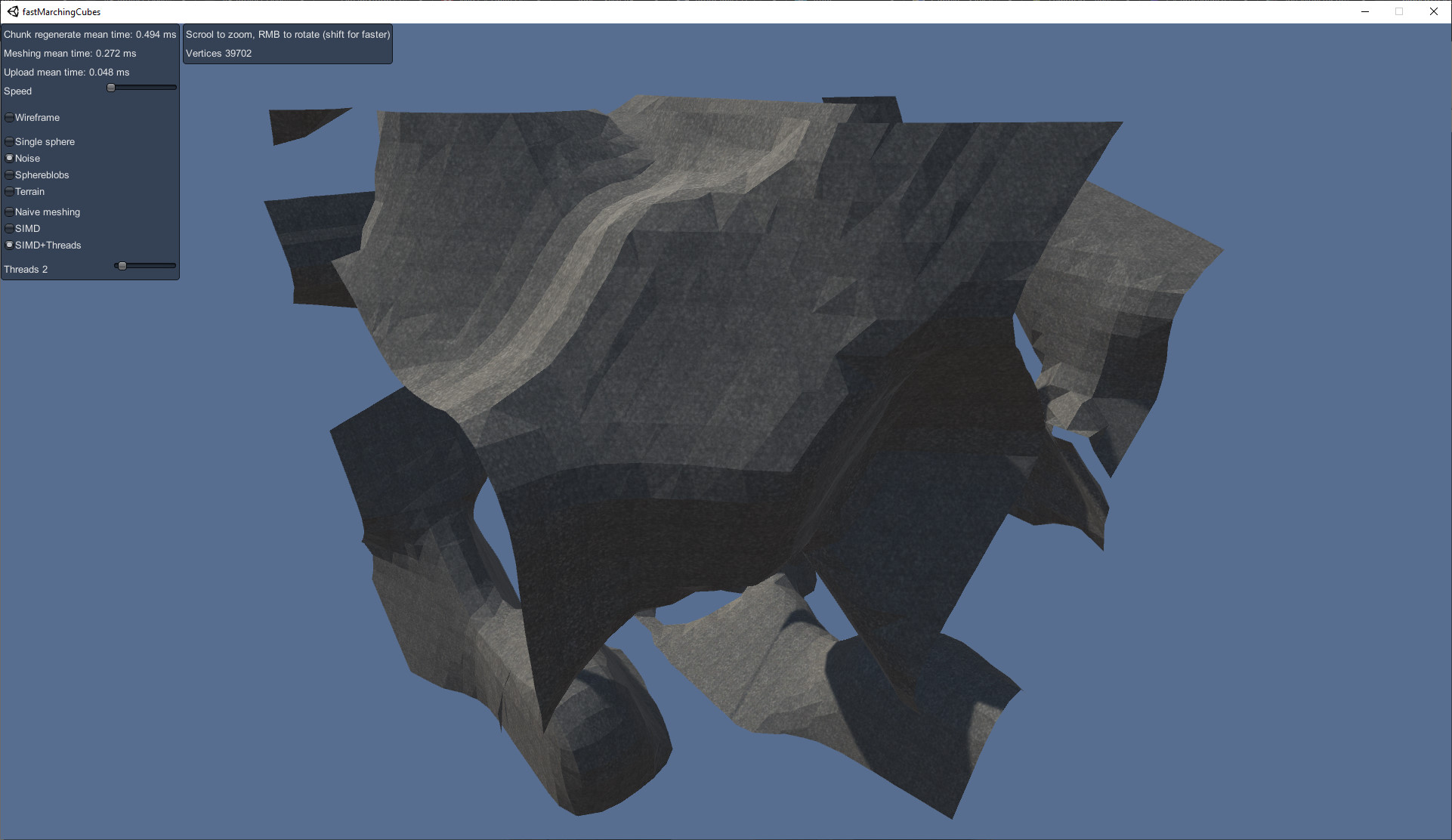
- Fast implementation of Marching Cubes in Unity, using Burst and SIMD instructions.
- Less than 1ms (around ~0.2-0.5 depends on complexity of meshed area)
- Similiar to : https://github.com/bigos91/fastNaiveSurfaceNets
- Triangulation table is a bit different than original - different corner indexing is used to make simd stuff possible
 https://www.youtube.com/watch?v=fIzZdO7FxqQ&ab_channel=Bigos91
https://www.youtube.com/watch?v=fIzZdO7FxqQ&ab_channel=Bigos91
{kind=link}
- 2 different triangulation tables (read Mesher.Arrays.cs)
- Naive version, SIMD, and SIMD multithreaded.
- No normals generated, intead they are calculated in fragment shader (ddx,ddy)
- No comment on simd stuff - if you need explanation read https://github.com/bigos91/fastNaiveSurfaceNets it is same.
- Cornermask calculations are done using SIMD stuff, 32 cubes at time (32x2x2 voxels), reusing values calculated from previous loop steps.
- Multithreaded version sometimes gives better performance results, sometimes not. No idea why.
- Meshed area must have 32 voxels in Z dimension to make SIMD implementation work
- 32x32x32 volumes, but it is possible to make it working with 32xNxM (Chunk.cs), or any size if you do not use SIMD stuff.
- It is only meshing algorithm. No any king of world management, etc.
- Unity (2020.3 works fine, dont know about previous versions)
- CPU with SSE4.1 support (around year 2007)
- Clone, run, open scene [FastMarchingCubes/Scenes/SampleScene],
- Disable everything what makes burst safe to make it faster :)
- http://paulbourke.net/geometry/polygonise/ - table
- http://paulbourke.net/geometry/polygonise/table2.txt - alternative table
- https://github.com/SebLague/Marching-Cubes - corner tables
- https://github.com/Chaser324/unity-wireframe - for wireframe.
- 16^3 size version
- maybe 64^3 size version but on AVX