My implementation of Few-Shot Adversarial Learning of Realistic Neural Talking Head Models (Egor Zakharov et al.). https://arxiv.org/abs/1905.08233




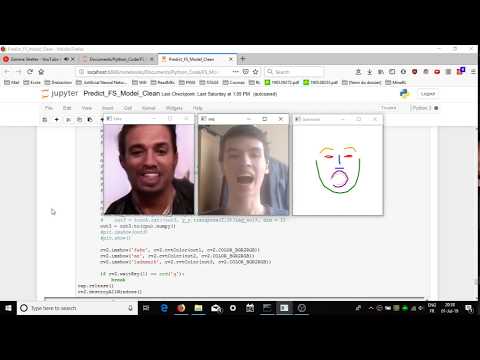
Inference after 5 epochs of training on the smaller test dataset, due to a lack of compute ressources I stopped early (author did 75 epochs with finetuning method and 150 with feed-forward method on the full dataset).
Follow these instructions to install the VGGFace from the paper (https://arxiv.org/pdf/1703.07332.pdf):
$ wget http://www.robots.ox.ac.uk/~vgg/software/vgg_face/src/vgg_face_caffe.tar.gz
$ tar xvzf vgg_face_caffe.tar.gz
$ sudo apt install caffe-cuda
$ pip install mmdnn
Convert Caffe to IR (Intermediate Representation)
$ mmtoir -f caffe -n vgg_face_caffe/VGG_FACE_deploy.prototxt -w vgg_face_caffe/VGG_FACE.caffemodel -o VGGFACE_IR
If you have a problem with pickle, delete your numpy and reinstall numpy with version 1.16.1
IR to Pytorch code and weights
$ mmtocode -f pytorch -n VGGFACE_IR.pb --IRWeightPath VGGFACE_IR.npy --dstModelPath Pytorch_VGGFACE_IR.py -dw Pytorch_VGGFACE_IR.npy
Pytorch code and weights to Pytorch model
$ mmtomodel -f pytorch -in Pytorch_VGGFACE_IR.py -iw Pytorch_VGGFACE_IR.npy -o Pytorch_VGGFACE.pth
At this point, you will have a few files in your directory. To save some space you can delete everything and keep Pytorch_VGGFACE_IR.py and Pytorch_VGGFACE.pth
- face-alignment
- torch
- numpy
- cv2 (opencv-python)
- matplotlib
The VoxCeleb2 dataset has videos in zip format. (Very heavy 270GB for the dev one and 8GB for the test) http://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox2.html
Available at https://drive.google.com/open?id=1vdFz4sh23hC_KIQGJjwbTfUdPG-aYor8
- train.py: initialize and train the network or continue training from trained network
- embedder_inference.py: (Requires trained model) Run the embedder on videos or images of a person and get embedding vector in tar file
- fine_tuning_trainng.py: (Requires trained model and embedding vector) finetune a trained model
- webcam_inference.py: (Requires trained model and embedding vector) run the model using person from embedding vector and webcam input, just inference
I followed the architecture guidelines from the paper on top of details provided by M. Zakharov.
The images that are fed from voxceleb2 are resized from 224x224 to 256x256 by using zero-padding. This is done so that spatial dimensions don't get rounded when passing through downsampling layers.
The residuals blocks are from LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS(K. S. Andrew Brock, Jeff Donahue.).
Embedder
The embedder uses 6 downsampling residual blocks with no normalisation. A self-attention layer is added in the middle. The output from the last residual block is resized to a vector of size 512 via maxpooling.
Generator
The downsampling part of the generator uses the same architecture as the embedder with instance normalization added at each block following the paper.
The same dimension residual part uses 5 blocks. These blocks use adaptive instance normalization. Unlike the AdaIN paper(Xun Huang et al.) where the alpha and beta learnable parameters from instance normalisation are replaced with mean and variance of the input style, the adaptative parameters (mean and variance) are taken from psi. With psi = P*e, P the projection matrix and e the embedding vector calculated by the embedder.
(P is of size 2*(512*2*5 + 512*2 + 512*2+ 512+256 + 256+128 + 128+64 + 64+3) x 512 = 17158 x 512)
There are then 6 upsampling residual blocks. The final output is a tensor of dimensions 3x224x224. I rescale the image using a sigmoid and multiplying by 255. There are two adaIN layers in each upsampling block (they replace the normalisation layers from the Biggan paper).
Self-attention layers are added both in the downsampling part and upsampling part of the generator.
Discriminator
The discriminator uses the same architecture as the embedder.