Demo of PySpark and Jupyter Notebook with the Jupyter Docker Stacks. Complete information for this project can be found by reading the related blog post, Getting Started with PySpark for Big Data Analytics, using Jupyter Notebooks and Docker
-
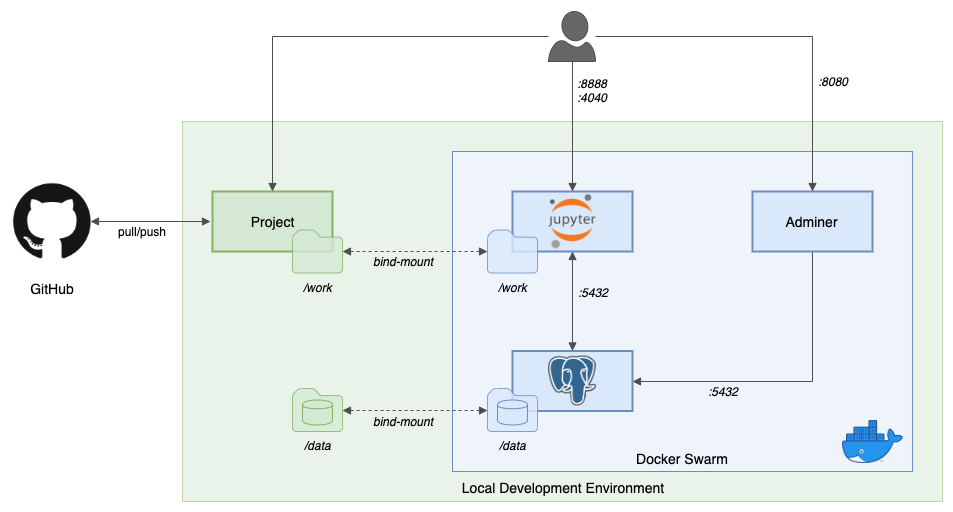
Clone this project from GitHub:
git clone \ --branch v2 --single-branch --depth 1 --no-tags \ https://github.com/garystafford/pyspark-setup-demo.git -
Create
$HOME/data/postgresdirectory for PostgreSQL files:mkdir -p ~/data/postgres -
Optional, for local development, install Python packages:
python3 -m pip install -r requirements.txt -
Optional, pull docker images first:
docker pull jupyter/all-spark-notebook:latest docker pull postgres:12-alpine docker pull adminer:latest
-
Deploy Docker Stack:
docker stack deploy -c stack.yml jupyter -
Retrieve the token to log into Jupyter:
docker logs $(docker ps | grep jupyter_spark | awk '{print $NF}') -
From the Jupyter terminal, run the install script:
sh bootstrap_jupyter.sh -
Export your Plotly username and api key to
.envfile:echo "PLOTLY_USERNAME=your-username" >> .env echo "PLOTLY_API_KEY=your-api-key" >> .env
From a Jupyter terminal window:
- Sample Python script, run
python3 01_simple_script.pyfrom Jupyter terminal - Sample PySpark job, run
$SPARK_HOME/bin/spark-submit 02_pyspark_job.pyfrom Jupyter terminal - Load PostgreSQL sample data, run
python3 03_load_sql.pyfrom Jupyter terminal - Sample Jupyter Notebook, open
04_notebook.ipynbfrom Jupyter Console - Sample Jupyter Notebook, open
05_notebook.ipynbfrom Jupyter Console - Try the alternate Jupyter stack with nbextensions pre-installed, first
cd docker_nbextensions/, then rundocker build -t garystafford/all-spark-notebook-nbext:latest .to build the new image - Then, to delete the previous stack, run
docker stack rm jupyter, followed by creating the new stack, runcd -anddocker stack deploy -c stack-nbext.yml jupyter
