This project has been moved to datasaucer/api.
![]()
Easily scrape data from any website, without worrying about captchas and bot detection mecanisms.






Website • Discord • ⭐ Give a Star

- No captcha, no bot detection. Websites will see you as a human.
- Integrated data extraction:
- Easily extract data with CSS / jQuery-like selectors
- Use filters to get ultra-clean data: url, price, ...
- Iterate through items (ex: search results, products list, articles, ...)
- Bulk requests: Up to 3 per call
- Post json / form-encoded body
- Set request device, headers and cookies
- Returns response body, headers, final URL & status code
- Typescript typings
Do you like this project ? Please let me know, ⭐ Give it a Star :)
-
Install the package
npm install --save scrapingapiIf you're a Yarn guy:
yarn add --save scrapingapi -
Create your free API Key
-
Make your first request (example below 👇)
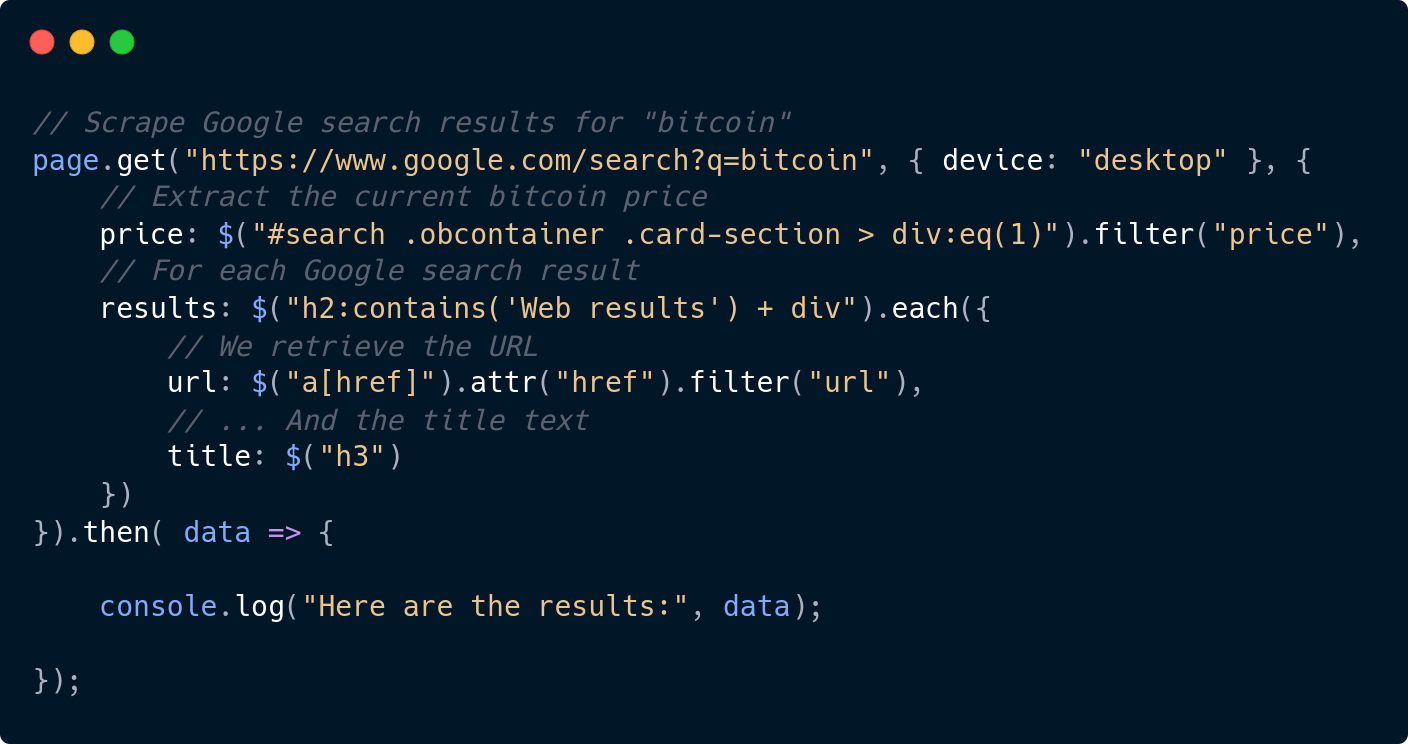
Here is an example of scraping current Bitcoin price + search results from Google Search.
import Scraper, { $ } from 'scrapingapi';
const page = new Scraper('API_KEY');
// Scrape Google search results for "bitcoin"
page.get("https://www.google.com/search?q=bitcoin", { device: "desktop" }, {
// Extract the current bitcoin price
price: $("#search .obcontainer .card-section > div:eq(1)").filter("price"),
// For each Google search result
results: $("h2:contains('Web results') + div").each({
// We retrieve the URL
url: $("a[href]").attr("href").filter("url"),
// ... And the title text
title: $("h3")
})
}).then( data => {
console.log("Here are the results:", data);
});The Scraper.get method sends a GET request to the provided URL, and automatically extract the data you asked: the price and the results.

In the data parameter, you will get a TScrapeResult object, containing the scraping results.
{
"url": "https://www.google.com/search?q=bitcoin",
"status": 200,
"time": 2.930,
"bandwidth": 26.33,
"data": {
"price": {
"amount": 49805.02,
"currency": "EUR"
},
"results": [{
"url": "https://bitcoin.org/",
"title": "Bitcoin - Open source P2P money"
}, {
"url": "https://coinmarketcap.com/currencies/bitcoin/",
"title": "Bitcoin price today, BTC to USD live, marketcap and chart"
}, {
"url": "https://www.bitcoin.com/",
"title": "Bitcoin.com | Buy BTC, ETH & BCH | Wallet, news, markets ..."
}, {
"url": "https://en.wikipedia.org/wiki/Bitcoin",
"title": "Bitcoin - Wikipedia"
}]
}
}Take advantage of the power of typescript by typing your response data:
import Scraper, { $, TExtractedPrice } from '../src';
const page = new Scraper('API_KEY');
type BitcoinGoogleResults = {
// Metadata generated by the price filter
price: TExtractedPrice,
// An array containing an informations object for each Google search result
results: {
url: string,
title: string
}[]
}
page.get<BitcoinGoogleResults>("https://www.google.com/search?q=bitcoin").then( ... );Do you like this project ? Please let me know, ⭐ Give it a Star :)
Let's consider we want to scrape an Amazon product page to retrieve the following info:
- Product info
- Title
- Current price
- Image URL
- Reviews
- Average rating
- List of reviews
Ready ? Let's start step by step:
This SDK provides one method per supported HTTP method:
- GET: See the definition
page.get( url, options, extractor );
- POST: See the definition
page.post( url, body, bodyType, options, extractor );
- Bulk requests:
With the
scrapemethod, You can also send up to 3 requests per call if each of them points to different domain names. See the definitionpage.scrape( requests );
Show Example
For our example, we only need to make a get request.
page.get( "https://www.amazon.com/dp/B08L76BSZ5", <options>, <extractors> );page.get( url, options, extractor );
^^^^^^^Depending on your needs, you can change some settings for your request:
- device (string): Which user-agent do you want to use for your request:
desktop,mobileortablet{ "device": "mobile" } - cookies (string): The cookie string you want to pass to the request. Example:
{ "cookies": "sessionId=34; userId=87;" } - withBody (boolean): If you want to get the page HTML in the response. Default:
false{ "withBody": true } - withHeaders (boolean): If you want to retrieve the response headers. Default:
false{ "withHeaders": true }
For POST requests only:
- body (object): The data to send in your POST request. Must be combined with bodyType.
{ "body": { "name": "bob", "age": 25 } } - bodyType (string): In which format do you want to POST your data:
formorjson{ "bodyType": "form" }
Show the Example
Here, we will simulate a mobile device, because the mobile version of Amazon is easier to scrape given that there are less elements on the page. We will also retrieve the response headers.
page.get("https://www.amazon.com/dp/B08L76BSZ5", { device: 'mobile', withHeaders: true }, <extractors>);We're now at the most interesting part: how to extract & filter values, and how to iterate items.
page.get( url, options, extractor );
^^^^^^^^^Let's start with the basics: extract a single information from the webpage.
Extractors are simple javascript objects, were you can associate a key (the name of your data) to a value selector.
The following example will extract the text content of the element that matches given selector:
{
<key>: $( <selector> )
}Here you have two elements:
- The Key: You can choose any name for the key, but it should not:
- Start by a
$ - Be a reserved key:
selectis the one and only reserved key for the moment
-
The Selector of the element which contains the information you want to extract. To create a value selector will use the
$()function. If you've already used jQuery, it should look a bit familiar :) And for the attribute you put in the$()function, it's a CSS-like / jQuery-like selector that matches the element you want to extract the value.Show examples
$("h3"): Simply matches allh3elements- Matches:
<h3>This is a title</h3>
- Do not matches because it's not a
h3element:<p>Hello</p>
- Matches:
$("a.myLink[href]"): Matchesaelements having the classmyLink, and where thehrefattribute is defined- Matches:
<a class="myLink anotherclass" href="https://scrapingapi.io">Link Text</a>
- Do not matches, because it doesn't contains the
myLinkclass<a class="thisClassIsAlone" href="https://scrapingapi.io">Link Text</a>
- Matches:
$("h2:contains('Scraping API') + div"): Matchesdivelements that are next toh2elements where the content is equal toScraping API- Matches:
<h2>Scraping API</h2> <div>is cool</div>
- Do not matches, because the
divelement is not next to theh2element<h2>Scraping API</h2> <p>is maybe not</p> <div>well configured</div>
- Matches:
Don't hesitate to go deeper by checking theses references:
But instead of extracting the text content of the element, you can also extract the HTML content.
For that, simply use the .html() method:
{
<key>: $( <selector> ).html()
^^^^^^^
}It's also possible to extract any other HTML attributes: href, class, src, etc ...
{
<key>: $( <selector> ).attr( <attribute> )
^^^^^^^^^^^^^^^^^^^
}Show the Example
Let's start by extracting the product info:
- Title
- Current price
- Image URL
- Rating
page.get("https://www.amazon.com/dp/B08L76BSZ5", { device: 'mobile', withHeaders: true }, {
title: $("#title"),
price: $("#corePrice_feature_div .a-offscreen:first"),
image: $("#main-image").attr("src"),
reviews: {
rating: $(".cr-widget-Acr [data-hook='average-stars-rating-text']")
}
});Pretty easy, isn't it ? 🙂 With this code, you will get the following data:
{
"title": "sportbull Unisex 3D Printed Graphics Novelty Casual Short Sleeve T-Shirts Tees",
"price": "$9.99",
"image": "https://m.media-amazon.com/images/I/71c3pFtZywL._AC_AC_SY350_QL65_.jpg",
"reviews": {
"rating": "4.4 out of 5"
}
}That's cool, but here we have two problems:
- The price is a string, and we need to parse it if we want to separate the price amount from the currency.
In a perfect world, we could simply make a
to get the amount. Yes, but depending on any factors, he price format could vary in
const amount = parseFloat( data.price.substring(1) );
9.99 USD,9.99 dollars incl. taxes,$9.99 USD free shipping, etc ... In addition, what warranties you that the price element systematically contains a price ? For some reaosns, we could have another random value. We want to build something strong, so we need to solve this issue. - Same issue with the image URL, we need to filter and validate it to be sure we have an URL in the correct form.
That's a great transition to see how you can filter the data you've extracted.
To ensure that the data we've extracted matches with what we're expecting, we can specify filters for each selector:
$( <selector> ).attr( <attribute> ).filter( <filter name> )
^^^^^^^^^^^^^^^^^^^^^^^^For the moment, we only support two filters:
- url: Checks if the value is an URL. If the URL is relative, it will be transformed into an absolute URL.
- price: Powered by the price-extract package, this filter ensures that the value express a price, autodetect the currency ISO code, and separate the amount from the currency.
It will give you an object with the price info:
{ "amount": 9.99, "currency": "USD" }
💡 If you want I add another filter, please don't hesitate to share your purposal by submitting a an issue. Thank you !
Show the Example
To come back on our Amazon example, we will simply add filters on the price and image data:
page.get("https://www.amazon.com/dp/B08L76BSZ5", { device: 'mobile', withHeaders: true }, {
title: $("#title"),
price: $("#corePrice_feature_div .a-offscreen:first").filter("price"),
^^^^^^^^^^^^^^^^
image: $("#main-image").attr("src").filter("url"),
^^^^^^^^^^^^^^
reviews: {
rating: $(".cr-widget-Acr [data-hook='average-stars-rating-text']")
}
});By running this code, you will get the following data:
{
"title": "sportbull Unisex 3D Printed Graphics Novelty Casual Short Sleeve T-Shirts Tees",
"price": { "amount": 9.99, "currency": "USD" },
"image": "https://m.media-amazon.com/images/I/71c3pFtZywL._AC_AC_SY350_QL65_.jpg",
"reviews": {
"rating": "4.4 out of 5"
}
}We get clean price data, and we're certain that image is an URL.
By default, all values you will select are required. That means we absolutly want this value to be present in the item, otherwhisee, this item will be excluded from the response.
But you can of course make a value optional:
$( <selector> ).attr( <attribute> ).optional()
^^^^^^^^^^^When a value is optional and it has not been found on the scraped page, you will get an undefined value.
Here are the reasons why a value could not be found:
- The selector do not matches with any element in the page
- The attribute you want to retrieve do not exists
- The value is empty
- The filter has rejected the value
Show the Example
Let's consider that the average rating is not necessarly present on the page.
Even if we're not able to get this info, we still want to retireve all the other values.
So, we have to make the reviews.rating data optional.
page.get("https://www.amazon.com/dp/B08L76BSZ5", { device: 'mobile', withHeaders: true }, {
title: $("#title"),
price: $("#corePrice_feature_div .a-offscreen:first").filter("price"),
image: $("#main-image").attr("src").filter("url"),
reviews: {
rating: $(".cr-widget-Acr [data-hook='average-stars-rating-text']").optional()
^^^^^^^^^^^
}
});If reviews.rating has not been found, you will get the following data:
{
"title": "sportbull Unisex 3D Printed Graphics Novelty Casual Short Sleeve T-Shirts Tees",
"price": { "amount": 9.99, "currency": "USD" },
"image": "https://m.media-amazon.com/images/I/71c3pFtZywL._AC_AC_SY350_QL65_.jpg",
"reviews": {}
}Now, you know how to extract high quality data from webpages. But what if we want to extract lists, like search results, products lists, blog articles, etc ... ? That's the next topic 👇
The scrapingapi SDK allows you to extract every item that matches a selector. Again, it's highly inspired by the jQuery API:
$( <items selector> ).each( <values> );Firstly, you have to provide the items selector which will match all the DOM elements you want to iterate. Then, you specify the values you want to extract for each element that will be iterated, like we've seen previously.
💡 All the selectors you provide to extract the values will be executed inside the items selector.
In the values, if the selector is "this", it will make reference to the items selector.
By exemple:
$("> ul.tags > li").each({
text: $("this")
})
The text value will be the text content of every "> ul.tags > li element.
Show the Example
We can now extract every review item:
page.get("https://www.amazon.com/dp/B08L76BSZ5", { device: 'mobile', withHeaders: true }, {
title: $("#title"),
price: $("#corePrice_feature_div .a-offscreen:first").filter("price"),
image: $("#main-image").attr("src").filter("url"),
reviews: {
rating: $(".cr-widget-Acr [data-hook='average-stars-rating-text']").optional(),
list: $("#cm-cr-dp-aw-review-list > [data-hook='mobley-review-content']").each({
author: $(".a-profile-name"),
title: $("[data-hook='review-title']")
})
}
});You will get the following result:
{
"title": "sportbull Unisex 3D Printed Graphics Novelty Casual Short Sleeve T-Shirts Tees",
"price": { "amount": 9.99, "currency": "USD" },
"image": "https://m.media-amazon.com/images/I/71c3pFtZywL._AC_AC_SY350_QL65_.jpg",
"reviews": {
"rating": "4.4 out of 5",
"list": [
{ "author": "Jon", "title": "Great shirt; very trippy" },
{ "author": "LK", "title": "Birthday Gift for Bartender Son" },
{ "author": "Yessica suazo", "title": "Decepcionada del producto que recibi" },
{ "author": "Avid Reader", "title": "Worth it." },
{ "author": "Nancy K", "title": "Husband loves it!" },
{ "author": "Mychelle", "title": "Gets Noticed" },
{ "author": "Suzy M. Lewis", "title": "Wish I had bought a size up" },
{ "author": "Devann Shultz", "title": "Great buy!" }
]
}
}Every time you launch a request, you will receive a response following this format:
type Response = {
// The final URL after all the redirections
url: string,
// The scraped page status code
status: number,
// The scraped page headers (must provide the withHeaders option)
headers?: { [key: string]: string },
// The page HTML (when the withBody option is true)
body?: string,
// The extracted data, if you provided extractors
data?: object;
// The time, in seconds, your request took to be resolved from our server
// The communication delays between your app and our servers are ignored
time: number,
// The used bandwidth, in kb
bandwidth: number,Every option uses additionnal CPU resources, slows down communication inside scrapingapi's network, and increase your response size.
That's why it's better do use as few options as possible to make your responses faster.
Do you like this project ? Please let me know, ⭐ Give it a Star :)

Consider that http://example.com/products responds with a webpage containing the following HTML:
<h2>Space Cat Holograms to motive you programming</h2>
<p>Free shipping to all the Milky Way.</p>
<section id="products">
<article class="product">
<img src="https://wallpapercave.com/wp/wp4014371.jpg" />
<h3>Sandwich cat lost on a burger rocket</h3>
<strong class="red price">123.45 $</strong>
<ul class="tags">
<li>sandwich</li>
<li>burger</li>
<li>rocket</li>
</ul>
</article>
<article class="product">
<img src="https://wallpapercave.com/wp/wp4575175.jpg" />
<h3>Aliens can't sleep because of this cute DJ</h3>
<ul class="tags">
<li>aliens</li>
<li>sleep</li>
<li>cute</li>
<li>dj</li>
<li>music</li>
</ul>
</article>
<article class="product">
<img src="https://wallpapercave.com/wp/wp4575192.jpg" />
<h3>Travelling at the speed of light with a radioactive spaceship</h3>
<p class="details">
Warning: Contains Plutonium.
</p>
<strong class="red price">456.78 $</strong>
<ul class="tags">
<li>pizza</li>
<li>slice</li>
<li>spaceship</li>
</ul>
</article>
<article class="product">
<img src="https://wallpapercave.com/wp/wp4575163.jpg" />
<h3>Gentleman dropped his litter into a black hole</h3>
<p class="details">
Since he found this calm planet.
</p>
<strong class="red price">undefined</strong>
<ul class="tags">
<li>luxury</li>
<li>litter</li>
</ul>
</article>
</section>Let's extract the product list:
type Product = {
name: string,
image: string,
price: { amount: number, currency: string },
tags: { text: string }[],
description?: string
}
scraper.get<Product[]>("http://example.com/products", {}, $("#products > article.product").each({
name: $("> h3"),,
image: $("> img").attr("src").filter("url"),
price: $("> .price").filter("price"),
tags: $("> ul.tags > li").each({
text: $("this")
}),
description: $("> .details").optional()
}));Here is the response:
{
"url": "http://example.com/products",
"status": 200,
"data": [{
"name": "Sandwich cat lost on a burger rocket",
"image": "https://wallpapercave.com/wp/wp4014371.jpg",
"price": { "amount": 123.45, "currency": "USD" },
"tags": [
{ "text": "sandwich" },
{ "text": "burger" },
{ "text": "rocket" }
]
},{
"name": "Gentlemen can't find his litter anymore",
"image": "https://wallpapercave.com/wp/wp4575192.jpg",
"price": { "amount": 456.78, "currency": "USD" },
"tags": [
{ "text": "pizza" },
{ "text": "slice" },
{ "text": "spaceship" }
]
}]
}Did you notice ? In the request, the price data has been marked as required. but for two HTML elements we've iterated with the $foreach instruction, the extractor wasn't able to extract the price.
Aliens can't sleep because of this cute DJdoesn't contains any element that matches with> .priceGentleman dropped his litter into a black holecontains a.priceelement, but the content text doesn't represents a price
-
Search if a related issue has not been created before
-
If not, feel free to create a new issue
-
For more personal questions, or for profesionnal inquiries:
Send me an email
For any complaint about abused kittens that has been sent to the deep space, see it with WallpaperCave.