forked from CharonChui/AndroidNote
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
51d0b32
commit 4ac2e82
Showing
12 changed files
with
452 additions
and
388 deletions.
There are no files selected for viewing
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -29,9 +29,7 @@ Base64加密 | |
|  | ||
|
|
||
|
|
||
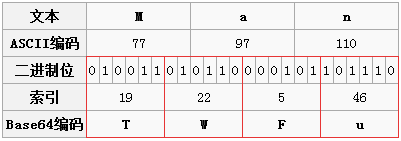
| 正式因为这,所以 | ||
| 想要转换成`Base64`最少要三个字节才可以,转换出来的`Base64`最少是4个字节,但是如果我要转换的字节不够3个怎么办?比如我想对字符`A`进行`Base64` | ||
| 加密。,`A`对应的第二个`Base64`的二进制位只有两个,把后边的四个补0就是了。 | ||
| 正是因为这,所以想要转换成`Base64`最少要三个字节才可以,转换出来的`Base64`最少是4个字节,但是如果我要转换的字节不够3个怎么办?比如我想对字符`A`进行`Base64`加密。,`A`对应的第二个`Base64`的二进制位只有两个,把后边的四个补0就是了。 | ||
| 所以`A`对应的`Base64`字符就是QQ。上边已经说过了,原则是`Base64`字符的最小单位是四个字符一组,那这才两个字符,后边补两个"="吧。 | ||
| 其实不用"="也不耽误解码,之所以用"=",可能是考虑到多段编码后的Base64字符串拼起来也不会引起混淆。 | ||
| 由此可见 Base64字符串只可能最后出现一个或两个"=",中间是不可能出现"="的。下图中字符"BC"的编码过程也是一样的。 | ||
|
|
@@ -50,4 +48,4 @@ Base64加密 | |
| - 邮箱 :[email protected] | ||
| - Good Luck! | ||
|
|
||
|
|
||
|
|
||
Large diffs are not rendered by default.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,35 +1,66 @@ | ||
| HashMap实现原理分析 | ||
| === | ||
|
|
||
| HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用null建和null值,因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。 | ||
|
|
||
| === | ||
| HashMap是Map接口的实现,元素以键值对的方式存储,并且允许使用null建和null值,因为key不允许重复,因此只能有一个键为null。 | ||
| HashMap被认为是Hashtable的增强版,HashMap是一个非线程安全的容器,如果想构造线程安全的Map考虑使用ConcurrentHashMap。 | ||
| HashMap是无序的,因为HashMap无法保证内部存储的键值对的有序性。 | ||
|
|
||
| ### 重要属性 | ||
|
|
||
| - 初始容量 | ||
| HashMap的默认初始容量是由DEFAULT_INITIAL_CAPACITY属性管理的。 | ||
| `static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; | ||
| HashMap的默认初始容量是 1 << 4 = 16, << 是一个左移操作,它相当于是: | ||
|  | ||
|
|
||
| - 最大容量 | ||
| HashMap的最大容量是 | ||
| `static final int MAXIMUM_CAPACITY = 1 << 30;` | ||
| 这里是不是有个疑问?int 占用四个字节,按说最大容量应该是左移 31 位,为什么 HashMap 最大容量是左移 30 位呢?因为在数值计算中,最高位也就是最左位的位 是代表着符号为,0 -> 正数,1 -> 负数,容量不可能是负数,所以 HashMap 最高位只能移位到 2 ^ 30 次幂。 | ||
| - 默认负载因子 | ||
| HashMap的默认负载因子是 | ||
| `static final float DEFAULT_LOAD_FACTOR = 0.75f;` | ||
| float 类型所以用 .f 为单位,负载因子是和扩容机制有关,这里大致提一下,后面会细说。扩容机制的原则是当 HashMap 中存储的数量 > HashMap 容量 * 负载因子时,就会把 HashMap 的容量扩大为原来的二倍。 | ||
| HashMap 的第一次扩容就在 DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR = 12 时进行。 | ||
| - 树化阈值 | ||
| HashMap 的树化阈值是 | ||
| `static final int TREEIFY_THRESHOLD = 8;` | ||
|
|
||
| 在进行添加元素时,当一个桶中存储元素的数量 > 8 时,会自动转换为红黑树(JDK1.8 特性)。 | ||
| - 链表阈值 | ||
| HashMap 的链表阈值是 | ||
| `static final int UNTREEIFY_THRESHOLD = 6;` 在进行删除元素时,如果一个桶中存储元素数量 < 6 后,会自动转换为链表 - 扩容临界值 `static final int MIN_TREEIFY_CAPACITY = 64;` | ||
| 这个值表示的是当桶数组容量小于该值时,优先进行扩容,而不是树化 | ||
|
|
||
|
|
||
| ## 原理 | ||
|
|
||
| 其底层数据结构是数组称之为哈希桶,每个桶(bucket)里面放的是链表,链表中的每个节点,就是哈希表中的每个元素。 | ||
|
|
||
| 通过hash的方法,通过put和get存储和获取对象。存储对象时,我们将K / V传给put方法时,它调用hashCode计算hash | ||
| 从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量 (超过Load Facotr则resize为原来的2倍)。 | ||
| 获取对象时,我们将K传给get()方法,它调用hashCodeO()计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。 | ||
| 如果发生碰撞的时候,HashMap通过链表将产生碰撞冲突的元素组织起来,在JDK8中,如果一个bucket中碰撞冲突的元素超过8个, | ||
| 则使用红黑树来替换链表,从而提高速度。 | ||
| 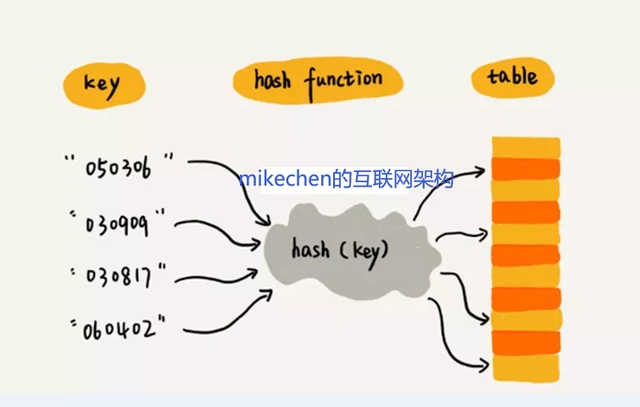 | ||
| 哈希表中哈希函数的设计是相当重要的,这也是建哈希表过程中的关键问题之一。 | ||
| 建立一个哈希表之前需要解决两个主要问题: | ||
|
|
||
| - 构造一个合适的哈希函数,均匀性 H(key)的值均匀分布在哈希表中 | ||
| - 冲突的处理 | ||
|
|
||
| 冲突:在哈希表中,不同的关键字值对应到同一个存储位置的现象。 | ||
|
|
||
| 当一个值中要存储到HashMap中的时候会根据Key的值来计算出他的hash,通过hash值来确认存放到数组中的位置,如果发生hash冲突就以链表的形式存储,当链表过长的话,HashMap会把这个链表转换成红黑树来存储通过hash的方法,通过put和get存储和获取对象。存储对象时,我们将K / V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量 (超过Load Factor则resize为原来的2倍)。 | ||
| 获取对象时,我们将K传给get()方法,它调用hashCode()计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。 | ||
|
|
||
| 因其底层哈希桶的数据结构是数组,所以也会涉及到扩容的问题。当HashMap的容量达到threshold域值时,就会触发扩容。 | ||
| 扩容前后,哈希桶的长度一定会是2的次方。这样在根据key的hash值寻找对应的哈希桶时,可以用位运算替代取余操作,更加高效。 | ||
| 而key的hash值,并不仅仅只是key对象的hashCode()方法的返回值,还会经过扰动函数的扰动,以使hash值更加均衡。 | ||
| 因为hashCode()是int类型,取值范围是40多亿,只要哈希函数映射的比较均匀松散,碰撞几率是很小的。 但就算原本的hashCode()取的很好, | ||
| 每个key的hashCode()不同,但是由于HashMap的哈希桶的长度远比hash取值范围小,默认是16,所以当对hash值以桶的长度取余, | ||
| 以找到存放该key的桶的下标时,由于取余是通过与操作完成的,会忽略hash值的高位。因此只有hashCode()的低位参加运算, | ||
| 因为hashCode()是int类型,取值范围是40多亿,只要哈希函数映射的比较均匀松散,碰撞几率是很小的。 但就算原本的hashCode()取的很好,每个key的hashCode()不同,但是由于HashMap的哈希桶的长度远比hash取值范围小,默认是16,所以当对hash值以桶的长度取余,以找到存放该key的桶的下标时,由于取余是通过与操作完成的,会忽略hash值的高位。因此只有hashCode()的低位参加运算, | ||
| 发生不同的hash值,但是得到的index相同的情况的几率会大大增加,这种情况称之为hash碰撞。即碰撞率会增大。 | ||
| 扰动函数就是为了解决hash碰撞的。它会综合hash值高位和低位的特征,并存放在低位,因此在与运算时,相当于高低位一起参与了运算, | ||
| 以减少hash碰撞的概率。(在JDK8之前,扰动函数会扰动四次,JDK8简化了这个操作)扩容操作时,会new一个新的Node数组作为哈希桶, | ||
| 然后将原哈希表中的所有数据(Node节点)移动到新的哈希桶中,相当于对原哈希表中所有的数据重新做了一个put操作。所以性能消耗很大, | ||
| 可想而知,在哈希表的容量越大时,性能消耗越明显。扩容时,如果发生过哈希碰撞,节点数小于8个。则要根据链表上每个节点的哈希值, | ||
| 依次放入新哈希桶对应下标位置。因为扩容是容量翻倍,所以原链表上的每个节点,现在可能存放在原来的下标,即low位, 或者扩容后的下标, | ||
| 即high位。 high位= low位+原哈希桶容量如果追加节点后,链表数量》=8,则转化为红黑树由迭代器的实现可以看出,遍历HashMap时, | ||
| 扰动函数就是为了解决hash碰撞的。它会综合hash值高位和低位的特征,并存放在低位,因此在与运算时,相当于高低位一起参与了运算,以减少hash碰撞的概率。(在JDK8之前,扰动函数会扰动四次,JDK8简化了这个操作)扩容操作时,会new一个新的Node数组作为哈希桶,然后将原哈希表中的所有数据(Node节点)移动到新的哈希桶中,相当于对原哈希表中所有的数据重新做了一个put操作。所以性能消耗很大,可想而知,在哈希表的容量越大时,性能消耗越明显。扩容时,如果发生过哈希碰撞,节点数小于8个。则要根据链表上每个节点的哈希值,依次放入新哈希桶对应下标位置。因为扩容是容量翻倍,所以原链表上的每个节点,现在可能存放在原来的下标,即low位, 或者扩容后的下标,即high位。 high位= low位+原哈希桶容量如果追加节点后,链表数量 >=8,且只有数组长度大于64才处理,则转化为红黑树由迭代器的实现可以看出,遍历HashMap时, | ||
| 顺序是按照哈希桶从低到高,链表从前往后,依次遍历的。 | ||
|
|
||
| 数组的特点:查询效率高,插入删除效率低。 | ||
| 链表的特点:查询效率低,插入删除效率高。 | ||
|
|
||
| 在HashMap底层使用数组加(链表或红黑树)的结构完美的解决了数组和链表的问题,使得查询和插入,删除的效率都很高。 | ||
|
|
||
|
|
||
| ## JDK1.7 | ||
|
|
||
| HashMap在JDK1.8中发生了改变,下面的部分是基于JDK1.7的分析。HashMap主要是用数组来存储数据的,我们都知道它会对key进行哈希运算, | ||
|
|
@@ -147,7 +178,7 @@ public V get(Object key) { | |
| ## JDK1.8 | ||
|
|
||
| 在Jdk1.8中HashMap的实现方式做了一些改变,但是基本思想还是没有变的,只是在一些地方做了优化,下面来看一下这些改变的地方, | ||
| 数据结构的存储由数组+链表的方式,变化为数组+链表+红黑树的存储方式,当链表长度超过阈值(8)时,将链表转换为红黑树。 | ||
| 数据结构的存储由数组+链表的方式,变化为数组+链表+红黑树的存储方式,当链表长度超过阈值(8)时,且只有数组长度大于64才处理,将链表转换为红黑树。 | ||
| 利用红黑树快速增删改查的特点来提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。HashMap中, | ||
| 如果key经过hash算法得出的数组索引位置全部不相同,即Hash算法非常好,那样的话,getKey方法的时间复杂度就是O(1), | ||
| 如果Hash算法技术的结果碰撞非常多,假如Hash算法极其差,所有的Hash算法结果得出的索引位置一样,那样所有的键值对都集中到一个桶中, | ||
|
|
@@ -505,6 +536,9 @@ resize()方法用于初始化数组或数组扩容,每次扩容后容量为原 | |
| 是0的话索引没变,是1的话索引变成 “原索引 + oldCap”。可以看看下图为16扩充为32的resize示意图: | ||
|  | ||
|
|
||
| 这里有一个需要注意的点就是在JDK1.8 HashMap扩容阶段重新映射元素时不需要像1.7版本那样重新去一个个计算元素的hash值,而是通过hash & oldCap的值来判断,若为0则索引位置不变,不为0则新索引=原索引+旧数组长度,为什么呢?具体原因如下: | ||
|
|
||
| 因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap | ||
|
|
||
| 这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,**由于新增的1bit是0还是1可以认为是随机的,因此resize的过程, | ||
| 均匀的把之前的冲突的节点分散到新的bucket了**。 | ||
|
|
@@ -690,7 +724,7 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, | |
| * 扩容时,如果发生过哈希碰撞,节点数小于8个。则要根据链表上每个节点的哈希值,依次放入新哈希桶对应下标位置。 | ||
| * 因为扩容是容量翻倍,所以原链表上的每个节点,现在可能存放在原来的下标,即low位, 或者扩容后的下标,即high位。 high位= low位+原哈希桶容量 | ||
| * 利用哈希值 与运算 旧的容量 ,if ((e.hash & oldCap) == 0),可以得到哈希值去模后,是大于等于oldCap还是小于oldCap,等于0代表小于oldCap,应该存放在低位,否则存放在高位。这里又是一个利用位运算 代替常规运算的高效点 | ||
| * 如果追加节点后,链表数量》=8,则转化为红黑树 | ||
| * 如果追加节点后,链表数量 >= 8,则转化为红黑树 | ||
| * 插入节点操作时,有一些空实现的函数,用作LinkedHashMap重写使用。 | ||
|
|
||
|
|
||
|
|
@@ -726,18 +760,22 @@ final Node<K,V> getNode(int hash, Object key) { | |
| ``` | ||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
| ## JDK 7与JDK 8中关于HashMap的对比 | ||
|
|
||
| 1. JDK8为红黑树 + 链表 + 数组的形式,当桶内元素大于8时,便会树化。 | ||
| 1. JDK8为红黑树 + 链表 + 数组的形式,当桶内元素大于8时,且只有数组长度大于64才处理,便会树化。 | ||
| 2. hash值的计算方式不同 (jdk 8 简化)。 | ||
| 3. JDK7中table在创建hashmap时分配空间,而8中在put的时候分配。 | ||
| 4. 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;因为头插法会使链表发生反转,多线程环境下会产生环; | ||
| 5. 在resize操作中,7 需要重新进行index的计算,而8不需要,通过判断相应的位是0还是1,要么依旧是原index,要么是oldCap + 原 index。 | ||
| 6. 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容; | ||
|
|
||
| 把链表转换成红黑树,树化需要满足以下两个条件: | ||
|
|
||
| - 链表长度大于等于8 | ||
| - table数组长度大于等于64 | ||
| 为什么table数组容量大于等于64才树化? | ||
|
|
||
| 因为当table数组容量比较小时,键值对节点 hash 的碰撞率可能会比较高,进而导致链表长度较长。这个时候应该优先扩容,而不是立马树化。 | ||
|
|
||
|
|
||
| ## 问题 | ||
|
|
@@ -782,6 +820,11 @@ final Node<K,V> getNode(int hash, Object key) { | |
| 扩容后为32后的二进制就高位多了1,============>为0001 1111。因为是&运算,1和任何数&都是它本身,那就分二种情况, | ||
| 原数据hashcode高位第4位为0和高位为1的情况;第四位高位为0,重新hash数值不变,第四位为1,重新hash数值比原来大16(旧数组的容量)。 | ||
|
|
||
| 6. HashMap和HashSet的区别: | ||
|
|
||
| HashSet继承于AbstractSet接口,实现了Set、Cloneable、java.io.Serializable接口。HashSet不允许集合中出现重复的值。HashSet底层其实 | ||
| 就是HashMap,所有对HashSet的操作其实就是对HashMap的操作。所以HashSet也不保证集合的顺序。 | ||
|
|
||
|
|
||
| 参考: | ||
|
|
||
|
|
@@ -794,5 +837,3 @@ final Node<K,V> getNode(int hash, Object key) { | |
| --- | ||
| - 邮箱 :[email protected] | ||
| - Good Luck! | ||
|
|
||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.