golang 分布式对象存储
本项目来自,由胡世杰先生编著的《分布式对象存储--原理,架构及GO语言实现》一书
分八个版本,对应书中八个章节
├── 对象存储简介
└── v1
├── 可推展的分布式系统
└── v2
├── 元数据服务
└── v3
├── 数据校验与去重
└── v4
├── 数据冗余和即时修复
└── v5
├── 断点续传
└── v6
├── 数据压缩
└── v7
├── 数据维护
└── v8
项目涉及到的 rabbitmq 和 elaticsearch 的知识可以看我做的笔记
.
├── go.mod
├── main.go
└── objects
└── handler.go
第一个版本非常简单
支持两种请求,put 和 get,对应上传文件和下载文件
上传文件的流程是:服务端收到 http 请求,将请求体 body 中的文本写入到 url 指定名称的文件中
下载文件的流程是:服务端收到 http 请求,将 url 中指定名称的文件的内容写入到响应体中
启动命令:
# LISTEN_ADDRESS 监听端口
# STORE_ROOT 文件目录
LISTEN_ADDRESS=:8888 STORE_ROOT=/object/1 go run main.go
当然目录要提前建好
测试:
PUT /object/test
.
├── apiservice
│ ├── go.mod
│ ├── go.sum
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ ├── objectstream
│ │ └── objectstream.go
│ └── rabbitmq
│ └── rabbitmq.go
├── dataservice
│ ├── go.mod
│ ├── go.sum
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ └── rabbitmq
│ └── rabbitmq.go
└── script
└── startup.sh
v1 只是最简单的单体服务,我们现在实现可扩展的分布式存储
将单体服务拆分为数据服务与接口服务。服务间的通信采用 rabbitmq,在 rabbitmq 服务器上新建两个交换机 apiServers 和 dataServers(类型都是fanout) 。
数据服务向 apiServers 发送心跳信息(服务地址),接口服务5秒未收到心跳信息,认为该数据服务出现异常。
接口服务向 dataServers 发送文件信息,新建一个临时消息队列,消息的正文是需要定位的对象,返回地址则是该临时队列的名字。如果某数据服务有该文件,向接口服务的临时队列发送自己的服务地址,接口服务收到后调用数据服务的下载文件接口(超时时间为1秒)
业务流程如下:

启动脚本:
#! /bin/bash
for i in `seq 1 6`
do
mkdir -p /tmp/$i/object
done
export RABBITMQ_SERVER=amqp://harukaze:123456@localhost:5672
cd ../dataservice/
echo $PWD
LISTEN_ADDRESS=localhost:12345 STORE_ROOT=/tmp/1 go run main.go &
LISTEN_ADDRESS=localhost:12346 STORE_ROOT=/tmp/2 go run main.go &
LISTEN_ADDRESS=localhost:12347 STORE_ROOT=/tmp/3 go run main.go &
LISTEN_ADDRESS=localhost:12348 STORE_ROOT=/tmp/4 go run main.go &
LISTEN_ADDRESS=localhost:12349 STORE_ROOT=/tmp/5 go run main.go &
LISTEN_ADDRESS=localhost:12350 STORE_ROOT=/tmp/6 go run main.go &
cd ../apiservice/
LISTEN_ADDRESS=localhost:12351 go run main.go &
LISTEN_ADDRESS=localhost:12352 go run main.go.
├── apiservice
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ ├── objectstream
│ │ └── objectstream.go
│ └── versions
│ └── veriosn.go
├── dataservice
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ └── objects
│ └── handler.go
├── es
│ ├── hit.go
│ └── meta.go
├── go.mod
├── go.sum
├── rabbitmq
│ └── rabbitmq.go
├── script
│ └── startup.sh
└── utils
└── hash.go
除了那些系统定义的元数据以外,用户也可以为这个对象添加自定义的元数据
我们给文件定义的元数据是
name 名称
version 版本
size 大小
hash 散列值
对象的散列值是一种非常特殊的元数据,因为对象存储通常将对象的散列值作为其全局唯一的标识符。在此前,数据服务节点上的对象都是用名字来引用的,如果两个对象名字不同,那么我们无法知道它们的内容是否相同。这让我们无法实现针对不同对象的去重。
现在,以对象的散列值作为标识符,我们就可以将接口服务层访问的对象和数据服务存取的对象数据解耦合。客户端和接口服务通过对象的名字来引用一个对象,而实际则是通过其散列值来引用存储在数据节点上的对象数据,只要散列值相同则可以认为对象的数据相同,这样就可以实现名字不同但数据相同的对象之间的去重。
对象的散列值是通过散列函数计算出来的,散列函数会将对象的数据进行重复多轮的数学运算,这些运算操作包括按位与、按位或、按位异或等,最后计算出来一个长度固定的数字,作为对象的散列值。一个理想的散列函数具有以下5个特征:
- 操作具有决定性,同样的数据必定计算出同样的散列值。
- 无论计算任何数据都很快。
- 无法根据散列值倒推数据,只能遍历尝试所有可能的数据。
- 数据上微小的变化就会导致散列值的巨大改变,新散列值和旧散列值不具有相关性。
- 无法找到两个能产生相同散列值的不同数据。
可惜这只是理想的情况,现实世界里不可能完全满足。在现实世界,一个散列函数 hash 的安全级别根据以下 3 种属性决定:
- 抗原像攻击: 给定一个散列值 h ,难以找到一个数据 m 令 h=hash(m)。这个属性称为函数的单向性。欠缺单向性的散列函数易受到原像攻击。
- 抗第二原像攻击: 给定一个数据 m1,难以找到第二个数据 m2 令 hash(m1)= hash(m2) 。欠缺该属性的散列函数易受到第二原像攻击。
- 抗碰撞性: 难以找到两个不同的数据 m1 和 m2 令 hash(m1)=hash(m2)。这样的一对数据被称为散列碰撞。
本项目使用的散列函数是 SHA-256,该函数使用64轮的数学运算,产生一个长度为256位的二进制数字作为散列值
我们使用 es(ElasticSearch)保存元数据
目前ES的索引的主分片(primary shards)数量一旦被创建就无法更改,
对于对象存储来说这会导致元数据服务的容量无法自由扩容.
对于有扩展性需求的开发者,推荐的一种解决方法是使用ES滚动索引(rollover index)。使用滚动索引之后,只要当前索引中的文档数量超出设定的阈值,ES就会自动创建一个新的索引用于数据的插入,而数据的搜索则依然可以通过索引的别名访问之前所有的旧索引
es 新建索引:
PUT /metadata
{
"mappings": {
"properties": {
"name": {
"type": "text",
"index": "true"
},
"version": {
"type": "integer"
},
"size": {
"type": "integer"
},
"hash": {
"type": "keyword"
}
}
}
}es 新建文档数据:
POST /metadata/_doc/testone_1
{
"name": "testone",
"version": "1",
"size": 1000,
"hash": ""
}业务逻辑:

#! /bin/bash
for i in `seq 1 6`
do
mkdir -p /tmp/$i/object
done
export RABBITMQ_SERVER=amqp://harukaze:123456@localhost:5672
export ES_SERVER=localhost:9200
LISTEN_ADDRESS=localhost:12345 STORE_ROOT=/tmp/1 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12346 STORE_ROOT=/tmp/2 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12347 STORE_ROOT=/tmp/3 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12348 STORE_ROOT=/tmp/4 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12349 STORE_ROOT=/tmp/5 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12350 STORE_ROOT=/tmp/6 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12351 go run apiservice/main.go &
LISTEN_ADDRESS=localhost:12352 go run apiservice/main.go计算 hash:
echo -n "this is object test3" | openssl dgst -sha256 –binary | base64.
├── apiservice
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ ├── objectstream
│ │ └── objectstream.go
│ └── versions
│ └── veriosn.go
├── dataservice
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ └── temp
│ └── temp.go
├── es
│ ├── hit.go
│ └── meta.go
├── go.mod
├── go.sum
├── rabbitmq
│ └── rabbitmq.go
├── script
│ └── startup.sh
└── utils
└── hash.go
由于各种原因,从客户端传给服务的 hash 值与上传的数据可能不一致,因此我们必须进行数据校验,验证客户端提供的散列值和我们自己根据对象数据计算出来的散列值是否一致
但是这时就出现了一个大问题:
一直以来我们都是以数据流的形式处理来自客户端的请求,接口服务调用 io.Copy 从对象 PUT 请求的正文中直接读取对象数据并写入数据服务。这是因为客户端上传的对象大小可能超出接口服务节点的内存,我们不能把整个对象读入内存后再进行处理。而现在我们必须等整个对象都上传完以后才能算出散列值,然后才能决定是否要存进数据服务。
这就形成了一个悖论:在客户端的对象完全上传完毕之前,我们不知道要不要把这个对象写入数据服务;但是等客户端的对象上传完毕之后再开始写入我们又做不到,因为对象可能太大,内存里根本放不下。
并且,考虑到在后面还会对数据进行压缩,这就表示不能在数据服务节点进行数据校 验,将校验一致的对象保留,不一致的删除。因为压缩之后的数据显然和未压缩的数据完全不同。我们就无法在数据服务节点上进行数据校验。数据校验这一步骤必须在接口服务节点完成。
方案:
为了真正解决上述矛盾,我们需要在数据服务上提供对象的缓存功能,接口服务不需要将用户上传的对象缓存在自身节点的内存里,而是传输到某个数据服务节点的一个临时对象里,并在传输数据的同时计算其散列值。当整个数据传输完毕以后,散列值计算也同步完成,如果一致,接口节点需要将临时对象转成正式对象;如果不一致,则将临时对象删除
启动脚本:
#! /bin/bash
for i in `seq 1 6`
do
mkdir -p /tmp/$i/object
mkdir /tmp/$i/temp
done
export RABBITMQ_SERVER=amqp://harukaze:123456@localhost:5672
export ES_SERVER=localhost:9200
LISTEN_ADDRESS=localhost:12345 STORE_ROOT=/tmp/1 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12346 STORE_ROOT=/tmp/2 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12347 STORE_ROOT=/tmp/3 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12348 STORE_ROOT=/tmp/4 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12349 STORE_ROOT=/tmp/5 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12350 STORE_ROOT=/tmp/6 go run dataservice/main.go &
LISTEN_ADDRESS=localhost:12351 go run apiservice/main.go &
LISTEN_ADDRESS=localhost:12352 go run apiservice/main.go.
├── apiservice
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ ├── objectstream
│ │ └── objectstream.go
│ ├── rs
│ │ ├── getStream.go
│ │ └── putStream.go
│ └── versions
│ └── veriosn.go
├── dataservice
│ ├── heartbeat
│ │ └── heartbeat.go
│ ├── locate
│ │ └── locate.go
│ ├── main.go
│ ├── objects
│ │ └── handler.go
│ └── temp
│ └── temp.go
├── es
│ ├── hit.go
│ └── meta.go
├── go.mod
├── go.sum
├── rabbitmq
│ └── rabbitmq.go
├── script
│ └── startup.sh
├── types
│ └── locateMessage.go
└── utils
└── hash.go
数据存储肯定是要保证数据的可靠,防止数据丢失,我们还需要加上数据冗余
在计算机领域,数据冗余是指在存储和传输的过程中,除了实际需要的数据,还存在一些额外数据用来纠正错误。这些额外的数据可以是一份简单的原始数据的复制,也可以是一些经过精心选择的校验数据,允许我们在一定程度上检测并修复损坏的数据。
在此项目中实现了 Reed Solomon纠 删码。
在编码理论学中,RS纠删码属于非二进制循环码,它的实现基于有限域上的一元多项式,并被广泛应用于CD、DVD、蓝光、QR码等消费品技术,DSL、WiMAX等数据传输技术,DVB、ATSC等广播技术以及卫星通信技术等。
RS纠删码允许我们选择数据片和校验片的数量,本项目选择了4个数据片加两个校验片,也就是说会把一个完整的对象平均分成6个分片对象,其中包括4个数据片对象,每个对象的大小是原始对象大小的25%,另外还有两个校验片,其大小和数据片一样。这6个分片对象被接口服务存储在6个不同的数据服务节点上,只需要其中任意4个就可以恢复出完整的对象。
业务流程:
上传文件:
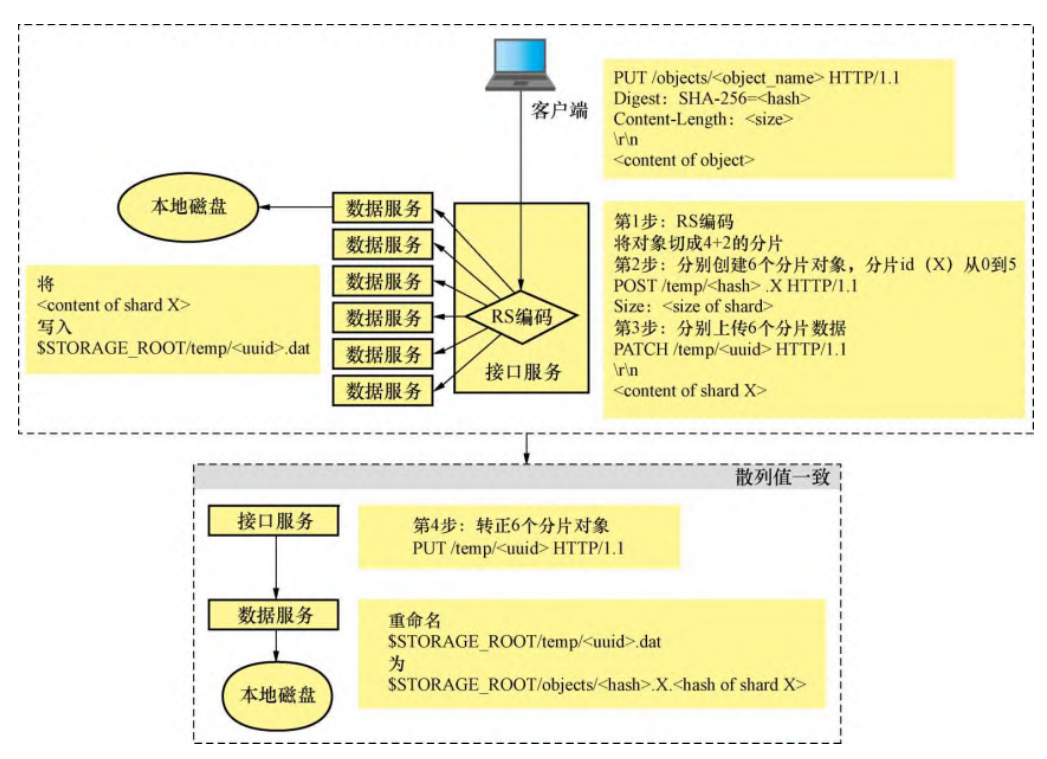
下载文件:

测试:
echo -n "this object will be separate to 4+2 shards" |
openssl dgst -sha256 -binary | base64
MBMxWHrPMsuOBaVYHkwScZQRyTRMQyiKp2oelpLZza8=
上传文件:
curl -v 10.29.2.1:12345/objects/test5 -XPUT -d "this object
will be separate to 4+2 shards" -H "Digest: SHA-
256=MBMxWHrPMsuOBaVYHkwScZQRy TRMQyiKp2oelpLZza8="
* Hostname was NOT found in DNS cache
*
Trying 10.29.2.1...
* Connected to 10.29.2.1 (10.29.2.1) port 12345 (#0)
> PUT /objects/test5 HTTP/1.1
> User-Agent: curl/7.38.0
> Host: 10.29.2.1:12345
> Accept: */*
> Digest: SHA-256=MBMxWHrPMsuOBaVYHkwScZQRyTRMQyiKp2oelpLZza8=
> Content-Length: 42
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 42 out of 42 bytes
< HTTP/1.1 200 OK
< Date: Wed, 09 Aug 2017 18:07:28 GMT
< Content-Length: 0
< Content-Type: text/plain; charset=utf-8
<
* Connection #0 to host 10.29.2.1 left intact

下载文件:
curl 10.29.2.1:12345/objects/test5
之后还可以将某个节点的文件删除,看看是否能否成功获取文本和将删除分片恢复
断点下载的实现非常简单,客户端在GET对象请求时通过设置Range头部来告诉接口服务需要从什么位置开始输出对象的数据
接口服务的处理流程在生成对象流之前和上一章没有任何区别,但是在成功打开了对象数据流之后,接口服务会额外调用 rs.RSGetStream.Seek 方法跳至客户端请求的位置,然后才开始输出数据。
接口服务会对数据进行散列值校验,当发生网络故障时,如果上传的数据跟期望的不一致,那么整个上传的数据都会被丢弃。所以断点上传在一开始就需要客户端和接口服务做好约定,使用特定的接口进行上传
客户端在知道自己要上传大对象时就主动改用对象 POST 接口,提供对象的散列值和大小。接口服务的处理流程和上一章处理对象 PUT 一样,搜索 6 个数据服务并分别 POST 临时对象接口。数据服务的地址以及返回的 uuid 会被记录在一个 token 里返回给客户端
客户端 POST 对象后会得到一个 token。对 token 进行 PUT 可以上传数据在上传时客户端需要指定 range 头部来告诉接口服务上传数据的范围。接口服务对 token 进行解码,获取 6 个分片所在的数据服务地址以及 uuid, 分别调用 PATCH 将数据写入 6 个临时对象。
通过 PUT 上传的数据并不一定会被接口服务完全接收。我们在第5章已经知道,经过RS分片的数据是以块的形式分批写入4个数据片的,每个数据片一次写入 8000 字节,4个数据片一共写入 32 000 字节。所以除非是最后一批数据,否则接口服务只接收 32 000 字节的整数倍进行写入。这是一个服务端的行为逻辑,我们不能要求客户端知道接口服务背后的逻辑,所以接口服务必须提供 token 的 HEAD 操作,让客户端知道服务端上该 token 目前的写入进度
测试:
首先,让我们生成一个长度为100文件,并计算散列值。
# 生成一个长度为100文件
$ dd if=/dev/urandom of=/tmp/file bs=1000 count=100
# 计算散列值
$ openssl dgst -sha256 -binary /tmp/file | base64将这个文件分段上传为 test6 对象
$ curl -v localhost:12351/object/test6 -XPOST -H "Digest:SHA-256=mXNXv6rY7k+jC6jKT4LFhVL5ONslk+rSGLoKbSeE5nc=" -H "Size: 100000"接口服务将 token 放在 Location 响应头部返回,我们先上传随机文件的前 50 000 字节
$ dd if=/tmp/file of=/tmp/first bs=1000 count=50$ curl -v -XPUT --data-binary @/tmp/first localhost:12351/temp/eyJOYW1lIjoidGVzdDYiLCJTaXplIjoxMDAwMDAsIkhhc2giOiJObFlrSzdrUn5ZQUxKR01jRkVzNEpCclJpa2w2YXIsYk9TdDlnZnFoSkVNXyIsIlNlcnZlcnMiOlsibG9jYWxob3N0OjEyMzUwIiwibG9jYWxob3N0OjEyMzQ1IiwibG9jYWxob3N0OjEyMzQ5IiwibG9jYWxob3N0OjEyMzQ4IiwibG9jYWxob3N0OjEyMzQ3IiwibG9jYWxob3N0OjEyMzQ2Il0sIlV1aWRzIjpbImI5MGZjYzE1LTc4NzktNGJhYy05MDRjLTQ3MzFlZjA0OTgwOCIsIjY1ZTA0NGRiLTY1YTYtNGY4YS05YTM0LTZhMjFmMWFkNzE3MiIsIjdjMzUyOGFhLWZjNTUtNDNjOC04ZGY4LTJhM2FkZmMzZjcxMiIsIjE0MGI2OTNkLWE0ZjYtNDAyYy1iYzAxLWRhMTUyMzQyZWJjYSIsImQ3YjNhZTkxLWMwNWQtNGNlMC04NzVlLTg3MzY5Njc4NmNjNyIsImYyOTdmNGY3LTQxODEtNDE0MS04YTgzLTk5OTU1ZmE5NzRlNSJdfQ__返回 200
我们用HEAD命令查看实际写入token的数据有多少
$ curl -I localhost:12351/temp/eyJOYW1lIjoidGVzdDYiLCJTaXplIjoxMDAwMDAsIkhhc2giOiJObFlrSzdrUn5ZQUxKR01jRkVzNEpCclJpa2w2YXIsYk9TdDlnZnFoSkVNXyIsIlNlcnZlcnMiOlsibG9jYWxob3N0OjEyMzUwIiwibG9jYWxob3N0OjEyMzQ1IiwibG9jYWxob3N0OjEyMzQ5IiwibG9jYWxob3N0OjEyMzQ4IiwibG9jYWxob3N0OjEyMzQ3IiwibG9jYWxob3N0OjEyMzQ2Il0sIlV1aWRzIjpbImI5MGZjYzE1LTc4NzktNGJhYy05MDRjLTQ3MzFlZjA0OTgwOCIsIjY1ZTA0NGRiLTY1YTYtNGY4YS05YTM0LTZhMjFmMWFkNzE3MiIsIjdjMzUyOGFhLWZjNTUtNDNjOC04ZGY4LTJhM2FkZmMzZjcxMiIsIjE0MGI2OTNkLWE0ZjYtNDAyYy1iYzAxLWRhMTUyMzQyZWJjYSIsImQ3YjNhZTkxLWMwNWQtNGNlMC04NzVlLTg3MzY5Njc4NmNjNyIsImYyOTdmNGY3LTQxODEtNDE0MS04YTgzLTk5OTU1ZmE5NzRlNSJdfQ__
我们可以看到写入的数据只有32 000个字节,所以下一次PUT要从32 000字节开始,让我们一次性把剩下的数据全部上传。
$ dd if=/tmp/file of=/tmp/second bs=1000 skip=32 count=68$ curl -v -XPUT --data-binary @/tmp/second localhost:12351/temp/eyJOYW1lIjoidGVzdDYiLCJTaXplIjoxMDAwMDAsIkhhc2giOiJObFlrSzdrUn5ZQUxKR01jRkVzNEpCclJpa2w2YXIsYk9TdDlnZnFoSkVNXyIsIlNlcnZlcnMiOlsibG9jYWxob3N0OjEyMzUwIiwibG9jYWxob3N0OjEyMzQ1IiwibG9jYWxob3N0OjEyMzQ5IiwibG9jYWxob3N0OjEyMzQ4IiwibG9jYWxob3N0OjEyMzQ3IiwibG9jYWxob3N0OjEyMzQ2Il0sIlV1aWRzIjpbImI5MGZjYzE1LTc4NzktNGJhYy05MDRjLTQ3MzFlZjA0OTgwOCIsIjY1ZTA0NGRiLTY1YTYtNGY4YS05YTM0LTZhMjFmMWFkNzE3MiIsIjdjMzUyOGFhLWZjNTUtNDNjOC04ZGY4LTJhM2FkZmMzZjcxMiIsIjE0MGI2OTNkLWE0ZjYtNDAyYy1iYzAxLWRhMTUyMzQyZWJjYSIsImQ3YjNhZTkxLWMwNWQtNGNlMC04NzVlLTg3MzY5Njc4NmNjNyIsImYyOTdmNGY3LTQxODEtNDE0MS04YTgzLTk5OTU1ZmE5NzRlNSJdfQ__现在让我们GET这个对象对比一下数据
$ curl localhost:12351/object/test6 > /tmp/output
$ diff -s /tmp/output /tmp/file接下来让我们试试用 range 头部指定下载 test6 对象的后 68KB 数据。
$ curl localhost:12351/object/test6 -H "range: bytes=32000-" > /tmp/output2
$ diff -s /tmp/output2 /tmp/output 最适合做数据压缩的地方是客户端。
一个高性能的客户端不仅可以将大量小对象打包成大对象高存储和传输的效率,也可以在客户机本地进行数据压缩,进一步节省网络带宽和存储空间。所以如果你的云存储系统在设计最初就包含了专门的客户端,那么别犹豫,一定要将数据压缩功能放在客户端,而不是服务端。
本项目采用 gzip 压缩算法,在服务端进行压缩
客户端在下载对象时可以设置Accept-Encoding头部为gzip。接口服务在检查到这个头部后会将对象数据流经过gzip压缩后写入HTTP响应的正文
为了体现应用gzip压缩后存储和传输的数据量变化,我们生成一个100MB的测试文件,并且其中的数据都填为0
$ dd if=/dev/zero of=/tmp/file bs=1M count=100
$ openssl dgst -sha256 -binary /tmp/file | base64文件上传
$ curl -v localhost:12351/object/test7 -XPUT --data-binary @/tmp/file -H "Digest: SHA-256=IEkqTQ2E+L6xdn9mFiKfhdRMKCe2S9v7Jg7hL6EQng4="用ls命令查看分片对象的大小。
ls -ltr /tmp/?/objects/IE*如果不使用数据压缩,一个100MB的对象,经过4+2 RS编码后每个分片是25MB,但是经过gzip压缩后,我们可以看到实际的分片大小只有25KB。
接下来我们下载test7对象并对比数据。
$ curl -v localhost:12351/object/test7 -o /tmp/output
$ diff -s /tmp/output /tmp/file$ curl -v localhost:12351/object/test7 -H "Accept-Encoding: gzip" -o /tmp/output2.gz
$ gunzip /tmp/output2.gz
$ diff -s /tmp/output2 /tmp/file