![]()

Ratus is a RESTful asynchronous task queue server. It translated concepts of distributed task queues into a set of resources that conform to REST principles and provides a consistent HTTP API for various backends based on embedded or external storage engines.
The key features of Ratus are:
- Self-contained binary with a fast in-memory storage.
- Support multiple embedded or external storage engines.
- Guaranteed at-least-once execution of tasks.
- Unified model for prioritized and time-based scheduling.
- Task-level timeout control with automatic recovery.
- Language agnostic RESTful API with built-in Swagger UI.
- Load balancing across a dynamic number of consumers.
- Horizontal scaling through replication and partitioning.
- Native support for Prometheus and Kubernetes.
Ratus offers a variety of installation options:
- Docker images are available on Docker Hub and GitHub Packages.
- Kubernetes and Docker Compose examples can be found in the deployments directory.
- Pre-built binaries for all major platforms are available on the GitHub releases page.
- Build from source with
go install github.com/hyperonym/ratus/cmd/ratus@latest.
Running Ratus from the command line is as simple as typing:
$ ratusThe above command will start an ephemeral Ratus instance using the default in-memory storage engine memdb and listen on the default HTTP port of 80.
To use another port and enable on-disk snapshot for persistence, start Ratus with:
$ ratus --port 8000 --engine memdb --memdb-snapshot-path ratus.dbDepending on the storage engine you choose, you may also need to deploy the corresponding database or broker. Using the mongodb engine as an example, assuming the database is already running locally, then start Ratus with:
$ ratus --port 8000 --engine mongodb --mongodb-uri mongodb://127.0.0.1:27017Concepts introduced by Ratus will be bolded below, see Concepts (a.k.a cheat sheet) to learn more.
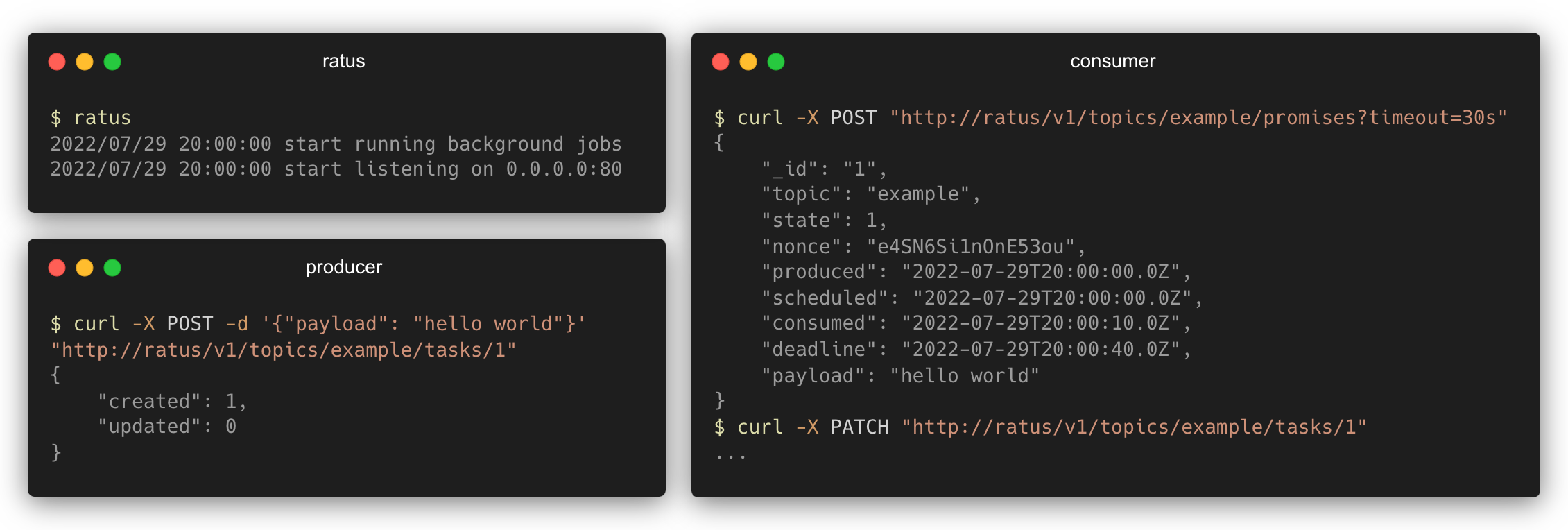
A producer creates a new task and pushes it to the example topic:
$ curl -X POST -d '{"payload": "hello world"}' "http://127.0.0.1:8000/v1/topics/example/tasks/1"Example response
{
"created": 1,
"updated": 0
}A consumer can then make a promise to claim and execute the next task in the example topic:
$ curl -X POST "http://127.0.0.1:8000/v1/topics/example/promises?timeout=30s"Example response
{
"_id": "1",
"topic": "example",
"state": 1,
"nonce": "e4SN6Si1nOnE53ou",
"produced": "2022-07-29T20:00:00.0Z",
"scheduled": "2022-07-29T20:00:00.0Z",
"consumed": "2022-07-29T20:00:10.0Z",
"deadline": "2022-07-29T20:00:40.0Z",
"payload": "hello world"
}After executing the task, remember to acknowledge Ratus that the task is completed using a commit:
$ curl -X PATCH "http://127.0.0.1:8000/v1/topics/example/tasks/1"Example response
{
"_id": "1",
"topic": "example",
"state": 2,
"nonce": "",
"produced": "2022-07-29T20:00:00.0Z",
"scheduled": "2022-07-29T20:00:00.0Z",
"consumed": "2022-07-29T20:00:10.0Z",
"deadline": "2022-07-29T20:00:40.0Z",
"payload": "hello world"
}If a commit is not received before the promised deadline, the state of the task is will be set back to pending, which in turn allows consumers to try to execute it again.
Ratus comes with a Go client library that not only encapsulates all API calls, but also provides idiomatic poll-execute-commit workflows like Client.Poll and Client.Subscribe. The examples directory contains ready-to-run examples for using the library:
- The hello world example demonstrated the basic usage of the client library.
- The crawl frontier example implemented a simple URL frontier for distributed web crawlers. It utilized advanced features like concurrent subscribers and time-based task scheduling.
- Task references an idempotent unit of work that should be executed asynchronously.
- Topic refers to an ordered subset of tasks with the same topic name property.
- Promise represents a claim on the ownership of an active task.
- Commit contains a set of updates to be applied to a task.
- Producer client pushes tasks with their desired date-of-execution (scheduled times) to a topic.
- Consumer client makes a promise to execute a task polled from a topic and acknowledges with a commit upon completion.
- Both producer and consumer clients can have multiple instances running simultaneously.
- Consumer instances can be added dynamically to increase throughput, and tasks will be naturally load balanced among consumers.
- Consumer instances can be removed (or crash) at any time without risking to lose the task being executing: a task that has not received a commit after the promised deadline will be picked up and executed again by other consumers.
- pending (0): The task is ready to be executed or is waiting to be executed in the future.
- active (1): The task is being processed by a consumer. Active tasks that have timed out will be automatically reset to the
pendingstate. Consumer code should handle failure and set the state topendingto retry later if necessary. - completed (2): The task has completed its execution. If the storage engine implementation supports TTL, completed tasks will be automatically deleted after the retention period has expired.
- archived (3): The task is stored as an archive. Archived tasks will never be deleted due to expiration.
- Task IDs across all topics share the same namespace (ADR). Topics are simply subsets generated based on the
topicproperties of the tasks, so topics do not need to be created explicitly. - Ratus is a task scheduler when consumers can keep up with the task generation speed, or a priority queue when consumers cannot keep up with the task generation speed.
- Tasks will not be executed until the scheduled time arrives. After the scheduled time, excessive tasks will be executed in the order of the scheduled time.
Ratus provides a consistent API for various backends, allowing users to choose a specific engine based on their needs without having to modify client-side code.
To use a specific engine, set the --engine flag or ENGINE environment variable to one of the following names:
| Name | Persistence | Replication | Partitioning | Expiration |
|---|---|---|---|---|
memdb |
○/● | ○ | ○ | ● |
mongodb |
● | ● | ● | ● |
![]()
MemDB is the default storage engine for Ratus. It is implemented on top of go-memdb, which is built on immutable radix trees. MemDB is suitable for development and production environments where durability is not critical.
The MemDB storage engine is ephemeral by default, but it also provides snapshot-based persistence options. By setting the --memdb-snapshot-path flag or MEMDB_SNAPSHOT_PATH environment variable to a non-empty file path, Ratus will write on-disk snapshots at an interval specified by MEMDB_SNAPSHOT_INTERVAL.
MemDB does not write Append-Only Files (AOF), which means in case of Ratus stopping working without a graceful shutdown for any reason you should be prepared to lose the latest minutes of data. If durability is critical to your workflow, switch to an external storage engine like mongodb.
- List operations are relatively expensive as they require scanning the entire database or index until the required number of results are collected. Fortunately, these operations are not used in most scenarios.
- Snapshotting is performed along with the periodic background jobs when appropriate. Writing snapshot files may delay the execution of background jobs if the amount of data is large.
- Since the resolution of the scheduled time in MemDB is in millisecond level and is affected by the instance's own clock, the order in which consumers receive tasks is not strictly guaranteed.
- TTL cannot be disabled for
completedtasks, in order to preserve a task forever, set it to thearchivedstate.
![]()
Ratus works best with MongoDB version ~4.4. MongoDB 5.0+ is also supported but requires additional considerations, see Implementation Details to learn more.
💭 TL;DR set
MONGODB_DISABLE_ATOMIC_POLL=truewhen using Ratus with MongoDB 5.0+.
When using the MongoDB storage engine, the Ratus instance itself is stateless. For high availability, start multiple instances of Ratus and connect them to the same MongoDB replica set.
All Ratus instances should run behind load balancers configured with health checks. Producer and consumer clients should connect to the load balancer, not directly to the instances.
Horizontal scaling could be achieved through sharding the task collection. However, with the help of the TTL mechanism, partitioning is not necessary in most cases. The best performance and the strongest atomicity can only be obtained without sharding.
If the amount of data exceeds the capacity of a single node or replica set, choose from the following sharding options:
- If there is a large number of topics, use a hashed index on the
topicfield as the shard key, this will also enable the best polling performance on a sharded cluster. - If there is a huge amount of tasks in a few topics, use a hashed index on the
_idfield as the shard key, this will also result in a more balanced data distribution.
- When using the MongoDB storage engine, tasks across all topics are stored in the same collection.
- Task is the only concrete data model in the MongoDB storage engine, while topics and promises are just conceptual entities for enforcing the RESTful design principles.
- Since the resolution of the scheduled time in MongoDB is in millisecond level and is affected by the instance's own clock, the order in which consumers receive tasks is not strictly guaranteed.
- TTL cannot be disabled for
completedtasks, in order to preserve a task forever, set it to thearchivedstate. - It is not recommended to upsert tasks on sharded collections using the
topicfield as the shard key. Due to MongoDB's own limitations, atomic operations cannot be used in this case, and only a fallback scheme equivalent to delete before insert can be used, so atomicity and performance cannot be guaranteed. This problem can be circumvented by using simple inserts in conjunction with fine-tuned TTL settings. - By default, polling is implemented through
findAndModify. In the event of a conflict, MongoDB's native optimistic concurrency control (OCC) will transparently retry the operation. But in MongoDB 5.0 and above, the retry will report aWriteConflicterror in the database server's log (although the operation is still successful from the client's perspective). You can choose to ignore this error, or circumvent the problem by settingMONGODB_DISABLE_ATOMIC_POLL=truewhen using MongoDB 5.0+. This option will make Ratus to not usefindAndModifyfor polling and instead rely on the application-level OCC layer to ensure atomicity.
The following indexes will be created on startup, unless MONGODB_DISABLE_INDEX_CREATION is set to true:
| Key Patterns | Partial Filter Expression | TTL |
|---|---|---|
{"topic": "hashed"} |
- | - |
{"topic": 1, "scheduled": 1} |
{"state": 0} |
- |
{"deadline": 1} |
{"state": 1} |
- |
{"topic": 1} |
{"state": 1} |
- |
{"consumed": 1} |
{"state": 2} |
MONGODB_RETENTION_PERIOD |
Ratus exposes the following Prometheus metrics on the /metrics endpoint:
| Name | Type | Labels |
|---|---|---|
| ratus_request_duration_seconds | histogram | topic, method, endpoint, status_code |
| ratus_chore_duration_seconds | histogram | - |
| ratus_task_schedule_delay_seconds | gauge | topic, producer, consumer |
| ratus_task_execution_duration_seconds | gauge | topic, producer, consumer |
| ratus_task_produced_count_total | counter | topic, producer |
| ratus_task_consumed_count_total | counter | topic, producer, consumer |
| ratus_task_committed_count_total | counter | topic, producer, consumer |
Ratus supports liveness and readiness probes via HTTP GET requests:
- The
/livezendpoint returns a status code of 200 if the instance is running. - The
/readyzendpoint returns a status code of 200 if the instance is ready to accept traffic.
- 🚨 Topic names and task IDs must not contain plus signs ('+') due to gin-gonic/gin#2633.
- It is not recommended to use Ratus as the primary storage of tasks. Instead, consider storing the complete task record in a database, and use a minimal descriptor as the payload for Ratus.
- Ratus is a simple and efficient alternative to task queues like Celery. Consider to use RabbitMQ or Kafka if you need high-throughput message passing without task management.
For more details, see Architectural Decision Records.
Asynchronous task queues are typically used for long-running background tasks, so the overhead of HTTP is not significant compared to the time spent by the tasks themselves. On the other hand, the HTTP-based RESTful API can be easily accessed by all languages without using dedicated client libraries.
If the number of topics is limited and you don't care about the priority between them, you can choose to create multiple threads/goroutines to listen to them simultaneously. Alternatively, you can create a topic of topics to get the topic names in turn and then get the next task from the corresponding topic.
- Storage engine options
- MemDB
- Ephemeral
- Persistence with snapshots
- Persistence with AOF
- MongoDB
- Standalone
- Replica set
- Sharded cluster
- Redis
- Standalone
- Sentinel
- Cluster
- RDBMS
- MySQL
- PostgreSQL
- Message broker
- RabbitMQ
- Amazon SQS
- MemDB
- Multi-language documents
- English
- Chinese
See the open issues for a full list of proposed features.
This project is open-source. If you have any ideas or questions, please feel free to reach out by creating an issue!
Contributions are greatly appreciated, please refer to CONTRIBUTING.md for more information.
Ratus is available under the Mozilla Public License Version 2.0.
© 2022 Hyperonym