

Agenda is a light-weight job scheduling library for Node.js.
It offers:
- Minimal overhead. Agenda aims to keep its code base small.
- Mongo backed persistance layer.
- Scheduling with configurable priority, concurrency, and repeating
- Scheduling via cron or human readable syntax.
- Event backed job queue that you can hook into.
- Optional standalone web-interface (see agenda-ui)
Install via NPM
npm install agenda
You will also need a working mongo database (2.4+) to point it to.
var agenda = new Agenda({db: { address: 'localhost:27017/agenda-example'}});
agenda.define('delete old users', function(job, done) {
User.remove({lastLogIn: { $lt: twoDaysAgo }}, done);
});
agenda.every('3 minutes', 'delete old users');
// Alternatively, you could also do:
agenda.every('*/3 * * * *', 'delete old users');
agenda.start();agenda.define('send email report', {priority: 'high', concurrency: 10}, function(job, done) {
var data = job.attrs.data;
emailClient.send({
to: data.to,
from: '[email protected]',
subject: 'Email Report',
body: '...'
}, done);
});
agenda.schedule('in 20 minutes', 'send email report', {to: '[email protected]'});
agenda.start();var weeklyReport = agenda.schedule('Saturday at noon', 'send email report', {to: '[email protected]'});
weeklyReport.repeatEvery('1 week').save();
agenda.start();Agenda's basic control structure is an instance of an agenda. Agenda's are mapped to a database collection and load the jobs from within.
- Configuring an agenda
- Defining job processors
- Creating jobs
- Managing jobs
- Starting the job processor
- Multiple job processors
- Manually working with jobs
- Job Queue Events
- Frequently asked questions
- Example Project structure
- Acknowledgements
All configuration methods are chainable, meaning you can do something like:
var agenda = new Agenda();
agenda
.database(...)
.processEvery('3 minutes')
...;Agenda uses Human Interval for specifying the intervals. It supports the following units:
seconds, minutes, hours, days,weeks, months -- assumes 30 days, years -- assumes 365 days
More sophisticated examples
agenda.processEvery('one minute');
agenda.processEvery('1.5 minutes');
agenda.processEvery('3 days and 4 hours');
agenda.processEvery('3 days, 4 hours and 36 seconds');Specifies the database at the url specified. If no collection name is given,
agendaJobs is used.
agenda.database('localhost:27017/agenda-test', 'agendaJobs');You can also specify it during instantiation.
var agenda = new Agenda({db: { address: 'localhost:27017/agenda-test', collection: 'agendaJobs' }});Use an existing mongoskin instance. This can help consolidate connections to a
database. You can instead use .database to have agenda handle connecting for
you.
Please note that this must be a collection. Also, you will want to run the following afterwards to ensure the database has the proper indexes:
function ignoreErrors() {}
agenda._db.ensureIndex("nextRunAt", ignoreErrors)
.ensureIndex("lockedAt", ignoreErrors)
.ensureIndex("name", ignoreErrors)
.ensureIndex("priority", ignoreErrors);
function ignoreErrorsYou can also specify it during instantiation.
var agenda = new Agenda({mongo: mongoSkinInstance});Takes a string name and sets lastModifiedBy to it in the job database.
Useful for if you have multiple job processors (agendas) and want to see which
job queue last ran the job.
agenda.name(os.hostname + '-' + process.pid);You can also specify it during instantiation
var agenda = new Agenda({name: 'test queue'});Takes a string interval which can be either a traditional javascript number,
or a string such as 3 minutes
Specifies the frequency at which agenda will query the database looking for jobs
that need to be processed. Agenda internally uses setTimeout to guarantee that
jobs run at (close to ~3ms) the right time.
Decreasing the frequency will result in fewer database queries, but more jobs being stored in memory.
Also worth noting is that if the job is queue is shutdown, any jobs stored in memory that haven't run will still be locked, meaning that you may have to wait for the lock to expire.
agenda.processEvery('1 minute');You can also specify it during instantiation
var agenda = new Agenda({processEvery: '30 seconds'});Takes a number which specifies the max number of jobs that can be running at
any given moment. By default it is 20.
agenda.maxConcurrency(20);You can also specify it during instantiation
var agenda = new Agenda({maxConcurrency: 20});Takes a number which specifies the default number of a specific that can be running at
any given moment. By default it is 5.
agenda.defaultConcurrency(5);You can also specify it during instantiation
var agenda = new Agenda({defaultConcurrency: 5});Takes a number which specifies the default lock lifetime in milliseconds. By
default it is 10 minutes. This can be overridden by specifying the
lockLifetime option to a defined job.
A job will unlock if it is finished (ie. done is called) before the lockLifetime.
The lock is useful if the job crashes or times out.
agenda.defaultLockLifetime(10000);You can also specify it during instantiation
var agenda = new Agenda({defaultLockLifetime: 10000});Before you can use a job, you must define its processing behavior.
Defines a job with the name of jobName. When a job of job name gets run, it
will be passed to fn(job, done). To maintain asynchronous behavior, you must
call done() when you are processing the job. If your function is synchronous,
you may omit done from the signature.
options is an optional argument which can overwrite the defaults. It can take
the following:
concurrency:numbermaxinum number of that job that can be running at once (per instance of agenda)lockLifetime:numberinterval in ms of how long the job stays locked for (see multiple job processors for more info). A job will automatically unlock ifdone()is called.priority:(lowest|low|normal|high|highest|number)specifies the priority of the job. Higher priority jobs will run first. See the priority mapping below
Priority mapping:
{
highest: 20,
high: 10,
default: 0,
low: -10,
lowest: -20
}
Async Job:
agenda.define('some long running job', function(job, done) {
doSomelengthyTask(function(data) {
formatThatData(data);
sendThatData(data);
done();
});
});Sync Job:
agenda.define('say hello', function(job) {
console.log("Hello!");
});Runs job name at the given interval. Optionally, data can be passed in.
Every creates a job of type single, which means that it will only create one
job in the database, even if that line is run multiple times. This lets you put
it in a file that may get run multiple times, such as webserver.js which may
reboot from time to time.
interval can be a human-readable format String, a cron format String, or a Number.
data is an optional argument that will be passed to the processing function
under job.attrs.data.
Returns the job.
agenda.define('printAnalyticsReport', function(job, done) {
User.doSomethingReallyIntensive(function(err, users) {
processUserData();
console.log("I print a report!");
done();
});
});
agenda.every('15 minutes', 'printAnalyticsReport');Optionally, name could be array of job names, which is convenient for scheduling
different jobs for same interval.
agenda.every('15 minutes', ['printAnalyticsReport', 'sendNotifications', 'updateUserRecords']);In this case, every returns array of jobs.
Schedules a job to run name once at a given time. when can be a Date or a
String such as tomorrow at 5pm.
data is an optional argument that will be passed to the processing function
under job.attrs.data.
Returns the job.
agenda.schedule('tomorrow at noon', 'printAnalyticsReport', {userCount: 100});Optionally, name could be array of job names, similar to every method.
agenda.schedule('tomorrow at noon', ['printAnalyticsReport', 'sendNotifications', 'updateUserRecords']);In this case, schedule returns array of jobs.
Schedules a job to run name once immediately.
data is an optional argument that will be passed to the processing function
under job.attrs.data.
Returns the job.
agenda.now('do the hokey pokey');Returns an instance of a jobName with data. This does NOT save the job in
the database. See below to learn how to manually work with jobs.
var job = agenda.create('printAnalyticsReport', {userCount: 100});
job.save(function(err) {
console.log("Job successfully saved");
});Lets you query all of the jobs in the agenda job's database. This is a full mongoskin
find query. See mongoskin's documentation for details.
agenda.jobs({name: 'printAnalyticsReport'}, function(err, jobs) {
// Work with jobs (see below)
});Cancels any jobs matching the passed mongoskin query, and removes them from the database.
agenda.cancel({name: 'printAnalyticsReport'}, function(err, numRemoved) {
});This functionality can also be achieved by first retrieving all the jobs from the database using agenda.jobs(), looping through the resulting array and calling job.remove() on each. It is however preferable to use agenda.cancel() for this use case, as this ensures the operation is atomic.
Removes all jobs in the database without defined behaviors. Useful if you change a definition name and want to remove old jobs.
IMPORTANT: Do not run this before you finish defining all of your jobs. If you do, you will nuke your database of jobs.
agenda.purge(function(err, numRemoved) {
});To get agenda to start processing jobs from the database you must start it. This
will schedule an interval (based on processEvery) to check for new jobs and
run them. You can also stop the queue.
Starts the job queue processing, checking processEvery time to see if there
are new jobs.
Stops the job queue processing. Unlocks currently running jobs.
This can be very useful for graceful shutdowns so that currently running/grabbed jobs are abandoned so that other job queues can grab them / they are unlocked should the job queue start again. Here is an example of how to do a graceful shutdown.
function graceful() {
agenda.stop(function() {
process.exit(0);
});
}
process.on('SIGTERM', graceful);
process.on('SIGINT' , graceful);Sometimes you may want to have multiple node instances / machines process from the same queue. Agenda supports a locking mechanism to ensure that multiple queues don't process the same job.
You can configure the locking mechanism by specifying lockLifetime as an
interval when defining the job.
agenda.define('someJob', {lockLifetime: 10000}, function(job, cb) {
//Do something in 10 seconds or less...
});This will ensure that no other job processor (this one included) attempts to run the job again for the next 10 seconds. If you have a particularly long running job, you will want to specify a longer lockLifetime.
By default it is 10 minutes. Typically you shouldn't have a job that runs for 10 minutes, so this is really insurance should the job queue crash before the job is unlocked.
When a job is finished (ie. done is called), it will automatically unlock.
A job instance has many instance methods. All mutating methods must be followed
with a call to job.save() in order to persist the changes to the database.
Specifies an interval on which the job should repeat.
interval can be a human-readable format String, a cron format String, or a Number.
job.repeatEvery('10 minutes');
job.save();Specifies a time when the job should repeat. Possible values
job.repeatAt('3:30pm');
job.save();Specifies the next time at which the job should run.
job.schedule('tomorrow at 6pm');
job.save();Specifies the priority weighting of the job. Can be a number or a string from
the above priority table.
job.priority('low');
job.save();Ensure that only one instance of this job exists with the specified properties
job.unique({'data.type': 'active', 'data.userId': '123', nextRunAt(date)});
job.save();Sets job.attrs.failedAt to now, and sets job.attrs.failReason
to reason.
Optionally, reason can be an error, in which case job.attrs.failReason will
be set to error.message
job.fail('insuficient disk space');
// or
job.fail(new Error('insufficient disk space'));
job.save();Runs the given job and calls callback(err, job) upon completion. Normally
you never need to call this manually.
job.run(function(err, job) {
console.log("I don't know why you would need to do this...");
});Saves the job.attrs into the database.
job.save(function(err) {
if(!err) console.log("Successfully saved job to collection");
})Removes the job from the database.
job.remove(function(err) {
if(!err) console.log("Successfully removed job from collection");
})Resets the lock on the job. Useful to indicate that the job hasn't timed out when you have very long running jobs.
agenda.define('super long job', function(job, done) {
doSomeLongTask(function() {
job.touch(function() {
doAnotherLongTask(function() {
job.touch(function() {
finishOurLongTasks(done);
});
});
});
});
});An instance of an agenda will emit the following events:
start- called just before a job startsstart:job name- called just before the specified job starts
agenda.on('start', function(job) {
console.log("Job %s starting", job.attrs.name);
});complete- called when a job finishes, regardless of if it succeeds or failscomplete:job name- called when a job finishes, regardless of if it succeeds or fails
agenda.on('complete', function(job) {
console.log("Job %s finished", job.attrs.name);
});success- called when a job finishes successfullysuccess:job name- called when a job finishes successfully
agenda.on('success:send email', function(job) {
console.log("Sent Email Successfully to: %s", job.attrs.data.to);
});fail- called when a job throws an errorfail:job name- called when a job throws an error
agenda.on('fail:send email', function(err, job) {
console.log("Job failed with error: %s", err.message);
});Agenda doesn't have a preferred project structure and leaves it to the user to choose how they would like to use it. That being said, you can check out the example project structure below.
Thanks! I'm flattered, but it's really not necessary. If you really want to, you can find my gittip here.
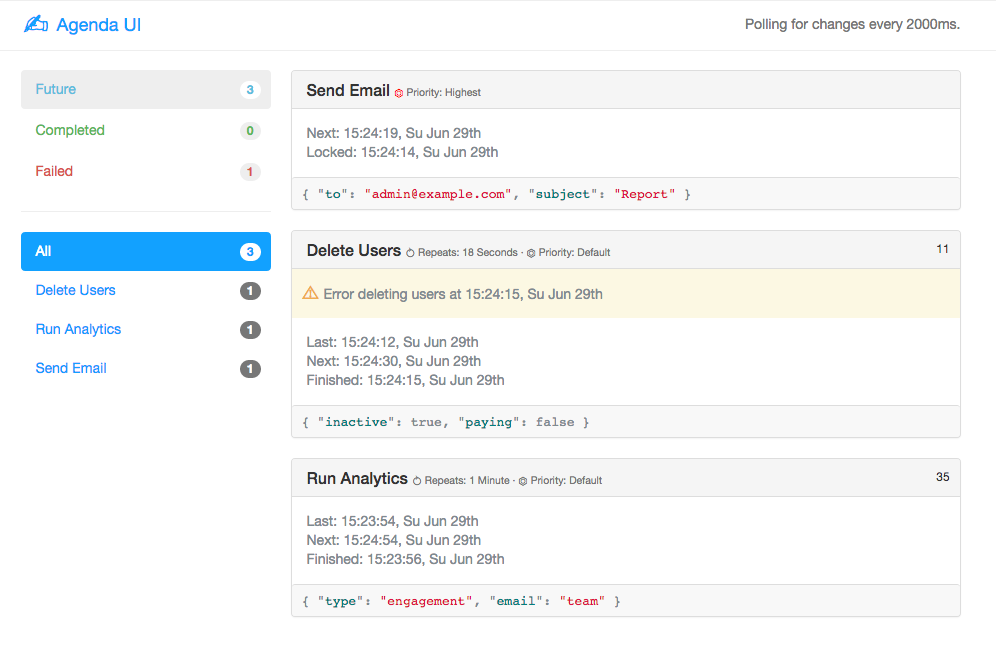
Agenda itself does not have a web interface built in. That being said, there is a stand-alone web interface in the form of agenda-ui.
Screenshot:
The decision to use Mongo instead of Redis is intentional. Redis is often used for non-essential data (such as sessions) and without configuration doesn't guarantee the same level of persistence as Mongo (should the server need to be restarted/crash).
Agenda decides to focus on persistence without requiring special configuration of Redis (thereby degrading the performance of the Redis server on non-critical data, such as sessions).
Ultimately if enough people want a Redis driver instead of Mongo, I will write one. (Please open an issue requesting it). For now, Agenda decided to focus on guaranteed persistence.
Ultimately Agenda can work from a single job queue across multiple machines, node processes, or forks. If you are interested in having more than one worker, Bars3s has written up a fantastic example of how one might do it:
var cluster = require('cluster'),
cpuCount = require('os').cpus().length,
jobWorkers = [],
webWorkers = [];
if (cluster.isMaster) {
// Create a worker for each CPU
for (var i = 0; i < cpuCount; i += 1) {
addJobWorker();
addWebWorker();
}
cluster.on('exit', function (worker, code, signal) {
if (jobWorkers.indexOf(worker.id) != -1) {
console.log('job worker ' + worker.process.pid + ' died. Trying to respawn...');
removeJobWorker(worker.id);
addJobWorker();
}
if (webWorkers.indexOf(worker.id) != -1) {
console.log('http worker ' + worker.process.pid + ' died. Trying to respawn...');
removeWebWorker(worker.id);
addWebWorker();
}
});
} else {
if (process.env.web) {
console.log('start http server: ' + cluster.worker.id);
require('./app/web-http');//initialize the http server here
}
if (process.env.job) {
console.log('start job server: ' + cluster.worker.id);
require('./app/job-worker');//initialize the agenda here
}
}
function addWebWorker() {
webWorkers.push(cluster.fork({web: 1}).id);
}
function addJobWorker() {
jobWorkers.push(cluster.fork({job: 1}).id);
}
function removeWebWorker(id) {
webWorkers.splice(webWorkers.indexOf(id), 1);
}
function removeJobWorker(id) {
jobWorkers.splice(jobWorkers.indexOf(id), 1);
}Agenda will only process jobs that it has definitions for. This allows you to selectively choose which jobs a given agenda will process.
Consider the following project structure, which allows us to share models with the rest of our code base, and specify which jobs a worker processes, if any at all.
- server.js
- worker.js
lib/
- agenda.js
controllers/
- user-controller.js
jobs/
- email.js
- video-processing.js
- image-processing.js
models/
- user-model.js
- blog-post.model.js
Sample job processor (eg. jobs/email.js)
var email = require('some-email-lib'),
User = require('../models/user-model.js');
module.exports = function(agenda) {
agenda.define('registration email', function(job, done) {
User.get(job.attrs.data.userId, function(err, user) {
if(err) return done(err);
email(user.email(), 'Thanks for registering', 'Thanks for registering ' + user.name(), done);
});
});
agenda.define('reset password', function(job, done) {
// etc etc
})
// More email related jobs
}lib/agenda.js
var Agenda = require('agenda');
var agenda = new Agenda(connectionOpts);
var jobTypes = process.env.JOB_TYPES ? process.env.JOB_TYPES.split(',') : [];
jobTypes.forEach(function(type) {
require('./lib/jobs/' + type)(agenda);
})
if(jobTypes.length) {
agenda.start();
}
module.exports = agenda;lib/controllers/user-controller.js
var app = express(),
User = require('../models/user-model'),
agenda = require('../worker.js');
app.post('/users', function(req, res, next) {
var user = new User(req.body);
user.save(function(err) {
if(err) return next(err);
agenda.now('registration email', { userId: user.primary() });
res.send(201, user.toJson());
});
});worker.js
require('./lib/agenda.js');Now you can do the following in your project:
node server.js
Fire up an instance with no JOB_TYPES, giving you the ability to process jobs,
but not wasting resources processing jobs.
JOB_TYPES=email node server.js
Allow your http server to process email jobs.
JOB_TYPES=email node worker.js
Fire up an instance that processes email jobs.
JOB_TYPES=video-processing,image-processing node worker.js
Fire up an instance that processes video-processing/image-processing jobs. Good for a heavy hitting server.
Agenda has some great community members that help a great deal.
(The MIT License)
Copyright (c) 2013 Ryan Schmukler [email protected]
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the 'Software'), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.