使用 OCR + 正则表达式实现核酸检测截图的自动校验,复现复旦大学博士生的代码。
相关报道:

Python + OCR + 正则表达式
以北京健康报的核酸检测截图作为示例:

OCR 使用 PaddlePaddle,会得到结果:
1:21 AM 100% D 健康服务预约查询 【通知】这里是通知内容... 核酸检测 疫苗接种 姓 名: 张** 身份证号:43**************22 阴性 距离本次检测已过5天 核酸检测机构 XXXX医院 核酸检测时间 2020.06.23 导出或打印检测报告 历史检测结果查询 本电子报告与医院或其他检测机构提供的纸质报告具有同等效力 可o 点击这里打“核酸检测”服务,您可通 可2 过本服务进大规模筛查检测预约、预 约码展示及采样信息绑定、预约记录查 预约 询、检测结果查询。①
使用正则表达式提取相关内容:
- 提取姓名:
姓\s*名:\s*(\S*) - 提取阴性/阳性结果:
(\S性) - 提取核酸检测时间:
核酸检测时间\s*(\S*)
会得到提取到的核酸检测界面的结果:

我这里校验了三个条件:
- 核酸检测时间与当前日期不超过 2 天;
- 识别出的姓名的汉字个数与截图文件名中姓名汉字字数相等;
- 识别出的姓名的汉字个数与截图文件名中姓名汉字第一个字(姓)相同;
如果这三个条件都满足,就认为没问题。
最后,遍历文件夹下所有的截图,逐一运行上面的代码,把结果输出成 Excel 里。 运行的命令是:
python main.py --date=2020.06.24打开生成的 Excel 是这样的:
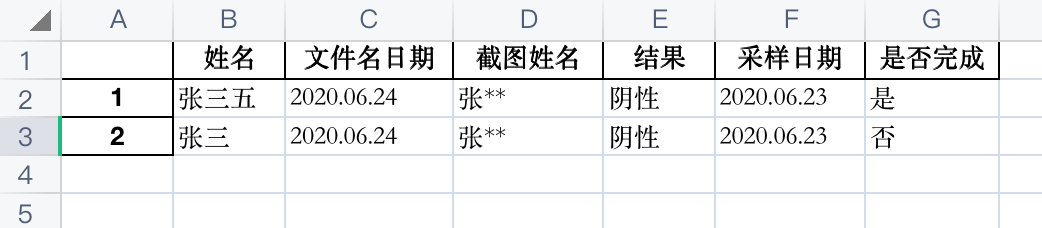
是不是大大解放了生产力? 我写的这份代码的总行数只有 82 行,比复旦博士的代码要简短一些。

但是代码的运行时间比较慢:检验两张截图的时间需要 12 秒,也就是平均 6 秒检验一张截图。
假如一个辅导员检查 60 个学生的话,上面的程序需要跑 10 分钟出检查结果。(但是收集、下载、重命名 60 个人的核酸检测截图需要多长时间?) 运行比较慢的是 OCR 识别部分,真需要优化运行速度的时候再说吧!
clone 本项目到本地:
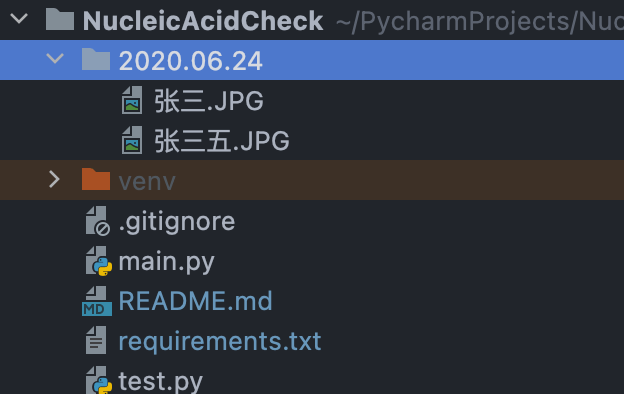
git clone [email protected]:fuxuemingzhu/NucleicAcidCheck.git在项目目录下创建需要检查的日期的文件夹,把需要检查的所有核酸检测结果的截图放在目录下,注意把截图命名为人名:
创建 Python 虚拟环境:
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/进入 Python 虚拟环境:
conda activate paddle_env安装运行需要的包:
pip install -r requirements.txt执行检查与判断:
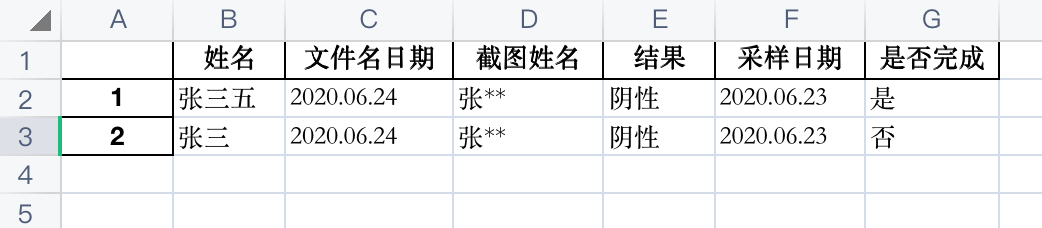
python main.py --date=2020.06.24在同一级目录下生成 check_2020.06.24.xlsx。
打开此 Excel,查看核酸检测结果、采样日期、是否完成核酸检测等信息:
本仓库的做法无法防止 P 图,也无法防止使用别人的截图。
对于健康码核查最理想方案是采用上策:个人授权给机构,机构统一核查。对于上千、上万人的企业和单位来说,将大大提高疫情信息收集能力。
希望未来可以把疫情防控更加信息化,让防疫工作者把精力投入到更有价值的工作上,释放防疫生产力。
愿疫情早日结束!
本仓库的作者是 负雪明烛,现在是互联网大厂的程序员一枚,想为疫情防控贡献出一份力。
「负雪明烛」,来自于“苍山负雪,明烛天南”,乐于分享与帮助别人。
我坚持刷算法题 7 年,写了 1000 多篇题解,博客累计阅读量 400 万+。
关注我,你可以获得优质算法题解、求职技巧、大厂内推、工作经验。
