Facilitates easy static website backup.
This tool facilitates website replication a.k.a. website backup. All the target's content is saved through the tool locally. Of course, this includes non-HTML static content like CSS, JavaScript, and images, so that the entire website can be browsed locally. There are some similar tools on the Internet but they are not ideal to use. Thus, this convenient Python script.
Originally forked from user Threezh1's "SiteCopy" - http://www.threezh1.com/
They also wrote a non-English blog post about the algorithm - https://xz.aliyun.com/t/6941
Make sure you obtain appropriate authorization before copying any target website. The developers of this tool are not responsible for users' actions. You accept all responsibility by cloning or using this tool, and hereby agree to these statements.
Developed for Python 3.7
Install the dependencies - pip3 install -r requirements.txt
- Copy a single page
python sitecopy.py -u "http://www.threezh1.com"
- Copy entire website
python sitecopy.py -u "http://www.threezh1.com" -e
- Copy multiple pages based off line-delimited file
python sitecopy.py -s "site.txt"
- Copy multiple websites based off line-delimited file
python sitecopy.py -s "site.txt" -e
Specify the depth of link crawl cycles with -d flag (default is 200)
Specify the max number of threads with -e flag (default is 30)
Example: Crawling all pages of the www.threezh1.com website, specifying a link crawling cycle number of 200, and a specified number of threads of 30:
python sitecopy.py -u "http://www.threezh1.com" -e -d 200 -t 30
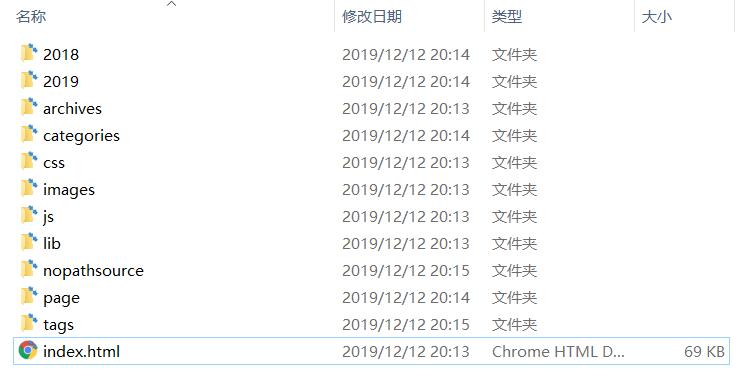
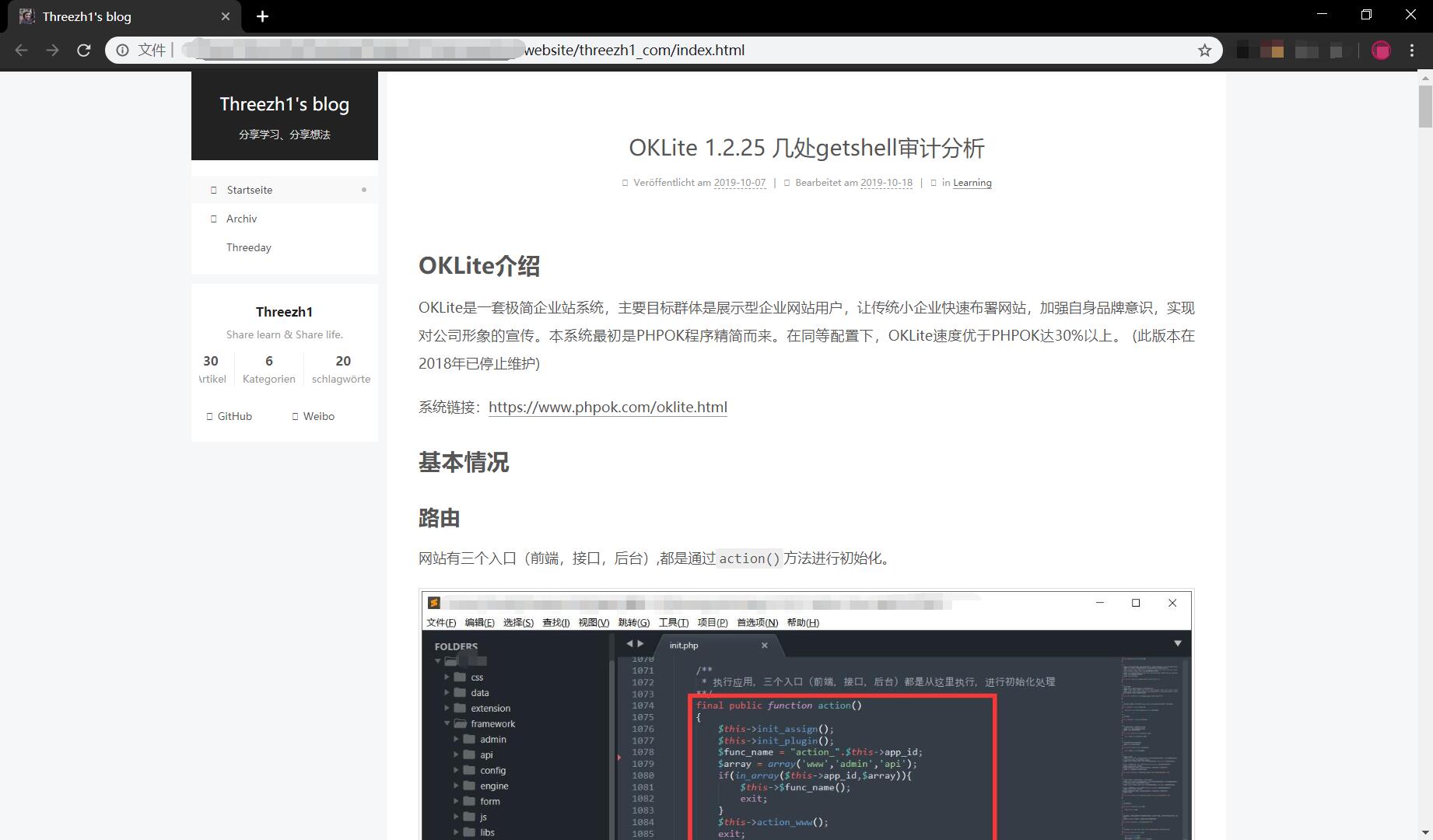
- Copy blog: https://threezh1.com
- Time taken: 2 minutes 48 seconds
Run screenshot:

Directory screenshot:
Screenshot of the page:
- In some cases, the directory will be replaced several times during the directory replacement, resulting in the page not displaying properly
- The website or map bed cannot be saved normally when there are anti-climbing measures
- Network problems cause the script to fail to execute properly
Original author provided his email related to these issues - [email protected]