forked from CrackerCat/simpread
-
Notifications
You must be signed in to change notification settings - Fork 2
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Upload new file: [原创] 某外卖软件 libmtguard 混淆分析 - Android 安全 - 看雪 - 安全社区 …
…| 安全招聘 | kanxue.com.md via simpread
- Loading branch information
1 parent
1502b20
commit 98666b3
Showing
1 changed file
with
171 additions
and
0 deletions.
There are no files selected for viewing
171 changes: 171 additions & 0 deletions
171
md/[原创] 某外卖软件 libmtguard 混淆分析 - Android 安全 - 看雪 - 安全社区 | 安全招聘 | kanxue.com.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,171 @@ | ||
| > 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [bbs.kanxue.com](https://bbs.kanxue.com/thread-283411.htm) | ||
| > [原创] 某外卖软件 libmtguard 混淆分析 | ||
| 字符串加密 | ||
| ===== | ||
|
|
||
| sub_25CDC 这个函数就是字符串解密函数,byte_218F01 是标记有没有解密的 | ||
|  | ||
| 字符串解密函数就是一个异或,参数第一个存放解密后字符串,第二个是加密的字符串,第三个是密钥,第四个是长度 | ||
|  | ||
|
|
||
| 字符串还是挺多的,需要批量处理一下 | ||
|  | ||
| 解密算法已经知道了,直接从解密函数调用前的 10 个指令开始模拟执行到解密函数,得到解密函数的 4 个参数 | ||
| 找解密函数调用处的前 10 个指令时,需要判断一下是不是 bxx 之类的分支指令,是的话就不往前找了,避免模拟执行跑飞 | ||
| 然后根据参数解密出字符串,patch 到第一个参数的地址 | ||
|
|
||
| ``` | ||
| import flare_emu | ||
| from idc import * | ||
| from idaapi import * | ||
| import idaapi | ||
| import ida_allins | ||
| from ida_ida import * | ||
| from idautils import * | ||
| import unicorn | ||
| from keystone import * | ||
| from unicorn import arm64_const | ||
| my_EH = flare_emu.EmuHelper() | ||
| def emu_last_x_insn(ea, insn_cnt=10, skip_ea=True, stop_in_brach=True, reg_info={}): | ||
| count = 0 | ||
| curr_addr = ea | ||
| while count < insn_cnt: | ||
| curr_addr = prev_head(curr_addr, 0) | ||
| insn = idaapi.insn_t() | ||
| length = idaapi.decode_insn(insn, curr_addr) | ||
| if stop_in_brach: | ||
| if (insn.get_canon_feature() & CF_JUMP) != 0 or (insn.get_canon_feature() & CF_CALL) != 0 or insn.itype in [ | ||
| ARM_b, ARM_bl, ARM_br, ARM_bx, ARM_blx1, ARM_blx2, ARM_cbz, ARM_cbnz, ARM_blr, | ||
| ARM_tbz, ARM_tbnz, ARM_ldrpc, ARM_ret] : | ||
| curr_addr = next_head(curr_addr, BADADDR) | ||
| break | ||
| count += 1 | ||
| start_addr = curr_addr | ||
| end_addr = ea | ||
| my_EH.emulateRange(start_addr, end_addr, registers=reg_info, count=insn_cnt) | ||
| return my_EH.uc | ||
| def is_valid_address(addr, segment_name = ".data"): | ||
| seg = get_segm_by_name(segment_name) | ||
| return addr >= seg.start_ea and addr <= seg.end_ea | ||
| def is_valid_string(string): | ||
| for c in string: | ||
| if c not in string.printable: | ||
| return False | ||
| return True | ||
| def dec_str(): | ||
| func_addr = 0x25CDC | ||
| all_used_addr = list(CodeRefsTo(func_addr, False)) | ||
| error_process_addr = [] | ||
| for used_addr in all_used_addr: | ||
| try: | ||
| uc_stata = emu_last_x_insn(used_addr, reg_info={"X0": 0, "X1": 0, "X2": 0, "X3": 0}) | ||
| x0 = uc_stata.reg_read(arm64_const.UC_ARM64_REG_X0) | ||
| x1 = uc_stata.reg_read(arm64_const.UC_ARM64_REG_X1) | ||
| x2 = uc_stata.reg_read(arm64_const.UC_ARM64_REG_X2) | ||
| x3 = uc_stata.reg_read(arm64_const.UC_ARM64_REG_X3) | ||
| out_addr, enc_addr, key, lens = x0, x1, x2, x3 | ||
| if is_valid_address(enc_addr): | ||
| curr_str_bytes = [] | ||
| for i in range(lens): | ||
| curr_char = get_wide_byte(enc_addr + i) | ||
| curr_char ^= key | ||
| key += 3 | ||
| key %= 256 | ||
| curr_str_bytes.append(curr_char) | ||
| curr_str = bytearray(curr_str_bytes).decode('utf-8') | ||
| if is_valid_address(out_addr): | ||
| for k in range(lens): | ||
| patch_byte(out_addr + k, curr_str_bytes[k]) | ||
| create_strlit(out_addr,0,STRTYPE_C) | ||
| print(f"patched {hex(out_addr)} with {curr_str}") | ||
| else: | ||
| error_process_addr.append(used_addr) | ||
| else: | ||
| error_process_addr.append(used_addr) | ||
| except Exception as e: | ||
| error_process_addr.append(used_addr) | ||
| print() | ||
| for addr in error_process_addr: | ||
| print(hex(addr),end=' ') | ||
| ``` | ||
|
|
||
| 最后会有十几个字符串参数识别有问题,手动处理一下就可以 | ||
|  | ||
| 如果是把字符串解密函数直接内联到使用字符串的函数代码中可能混淆效果好一些 | ||
|
|
||
| 控制流混淆 | ||
| ===== | ||
|
|
||
| 直接看 JNI_Onload,先是给 W0 赋了个值 | ||
| 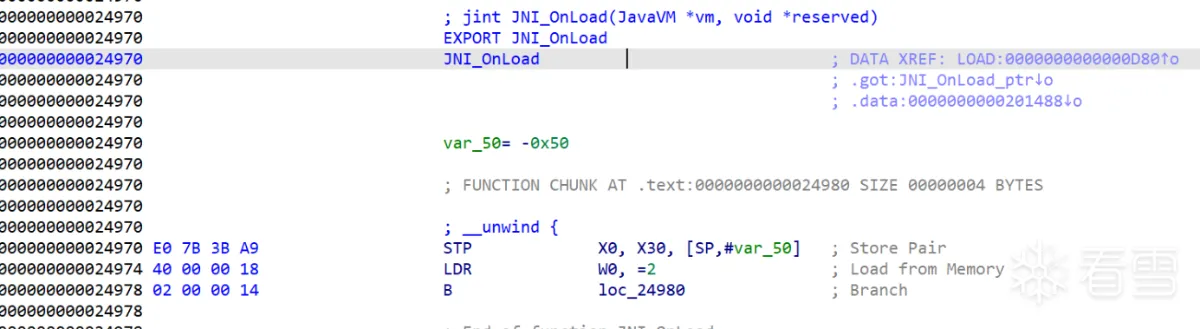 | ||
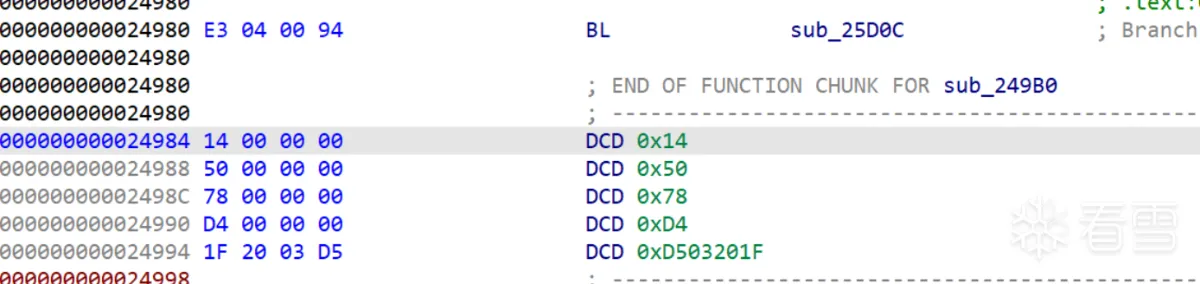
| 然后来到 0x24980 调用 sub_25d0c | ||
|  | ||
| 函数从 x30 加上 w0<<2 的内存位置取了一个 dword,然后加到 x30 | ||
|  | ||
| 函数调用时会把返回地址放到 link register(x30),所以取数据的位置就是 0x24980 下面 | ||
| 上面是取了 [0x24984 + 2<<2],也就是 0x78 | ||
|  | ||
| 加到 x30 之后 ret 来到 0x0249FC | ||
|  | ||
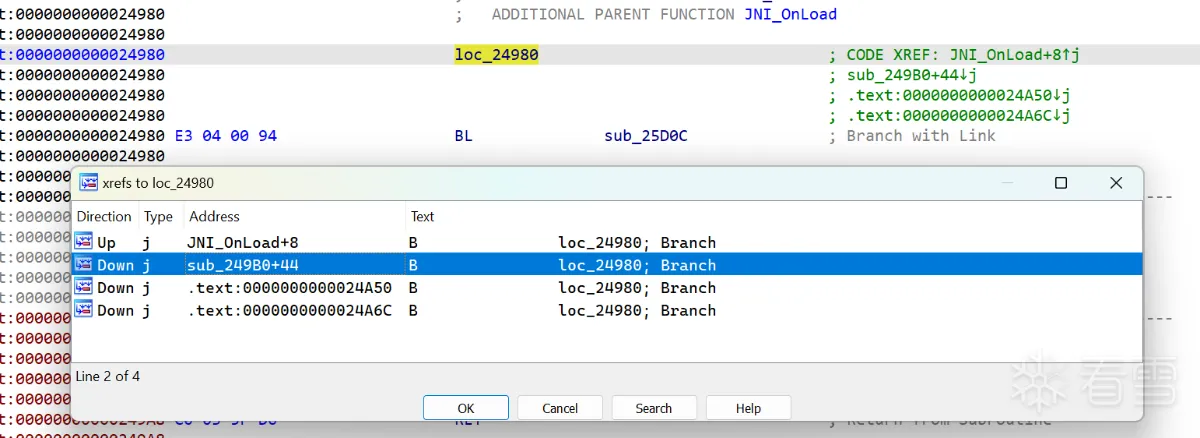
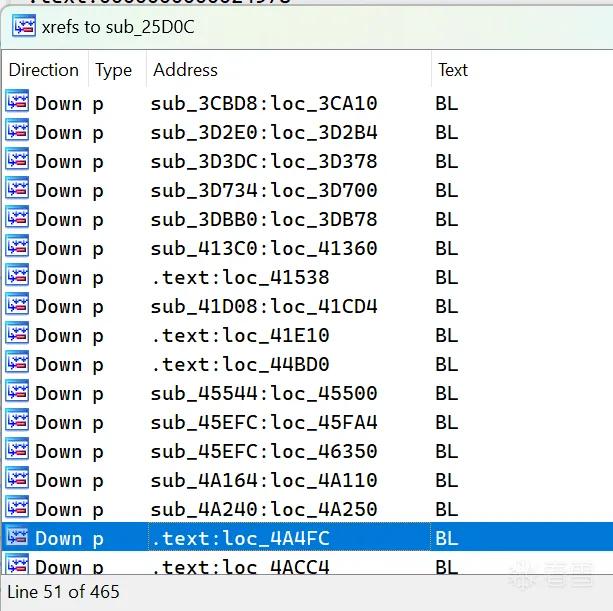
| 查看 0x24980 的地方发现还有另外几个,并且 sub_25D0C 也不止有 0x24980 调用 | ||
| 可以猜测是每个函数都有有类似 0x24980 这种类似分发器的东西,通过上面的运算分发到函数内的基本块上 | ||
|  | ||
|  | ||
| 还是要用脚本批量处理一下 | ||
| 找到 BL sub_25d0c 的所有调用处,然后每个调用处向前找 3 条指令开始模拟执行,找到取数据时的下标,取出对应的偏移加回去得到正确的跳转位置,然后用 keystone 汇编一下指令,再 patch 回 BL sub_25d0c 的调用处 | ||
| 当然也不一定非要去模拟执行,这个 so 中 BL sub_25d0c 的所有调用处的前一条指令刚好都是赋值下标的指令,也就是 LDR W0, xxx ,所以直接匹配也是可以 | ||
| 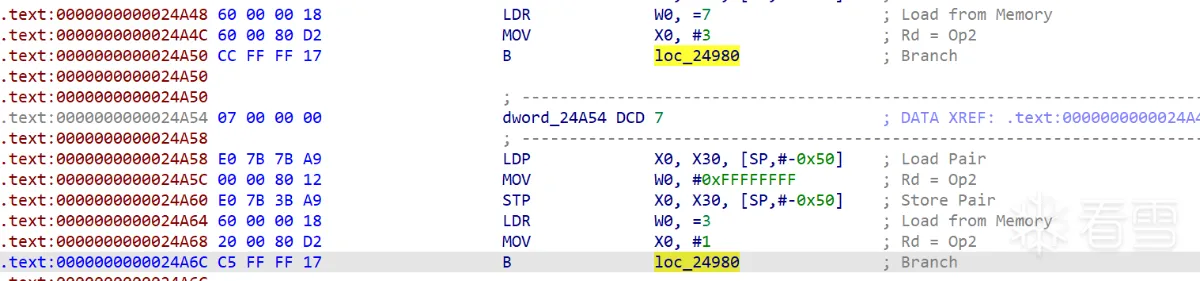 | ||
|
|
||
| ``` | ||
| def jump_deobfuscator(): | ||
| sp_modify_func = 0x25D0C | ||
| all_used_addr = list(CodeRefsTo(sp_modify_func, False)) | ||
| error_process_addr = [] | ||
| for used_addr in all_used_addr: | ||
| data_addr = used_addr + 4 | ||
| for xref_addr in list(CodeRefsTo(used_addr, False)): | ||
| insn = idaapi.insn_t() | ||
| length = idaapi.decode_insn(insn, xref_addr) | ||
| assert(insn.itype == ARM_b) | ||
| try: | ||
| uc_stata = emu_last_x_insn(xref_addr, insn_cnt=2, reg_info={"X0": 0xffffffff, "X1": 0, "X2": 0, "X3": 0}) | ||
| x0 = uc_stata.reg_read(arm64_const.UC_ARM64_REG_X0) | ||
| data_offset = x0 | ||
| if (data_offset == 0xffffffff): | ||
| error_process_addr.append([used_addr, xref_addr]) | ||
| continue | ||
| jump_addr = get_wide_dword(data_addr + (data_offset * 4)) + data_addr | ||
| if (not is_valid_address(jump_addr, ".text")): | ||
| error_process_addr.append([used_addr, xref_addr]) | ||
| continue | ||
| ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN) | ||
| assembly_code = f"b {hex(jump_addr)}" | ||
| encoding, count = ks.asm(assembly_code, as_bytes=True, addr=xref_addr) | ||
| for k in range(4): | ||
| patch_byte(xref_addr + k, encoding[k]) | ||
| except Exception as e: | ||
| error_process_addr.append([used_addr, 0]) | ||
| print() | ||
| for addr in error_process_addr: | ||
| print(f"{hex(addr[0])} {hex(addr[1])}") | ||
| ``` | ||
|
|
||
| patch 完成之后,应用到 so 文件,重新用 ida 打开就可以看到函数都可以正常分析了 | ||
|  | ||
|  | ||
|
|
||
| [[培训] 内核驱动高级班,冲击 BAT 一流互联网大厂工作,每周日 13:00-18:00 直播授课](https://www.kanxue.com/book-section_list-174.htm) | ||
|
|
||
| [#逆向分析](forum-161-1-118.htm) [#NDK 分析](forum-161-1-119.htm) [#脱壳反混淆](forum-161-1-122.htm) |