


LLaMA Box is an LM inference server(pure API, w/o frontend assets) based on the llama.cpp and stable-diffusion.cpp.
- Compatible with OpenAI Chat API.
- Support OpenAI Chat Vision API.
- LLaVA 1.5/1.6 and variants
- Mini CPM V2.5/V2.6
- Qwen2-VL
- Support OpenAI Chat Vision API.
- Compatible with OpenAI Embeddings API.
- Compatible with OpenAI Images API, see our Image Collection.
- Compatible with (Legacy) OpenAI Completions API.
- Compatible with Jina Rerank API, see our Reranker Collection.
- Support speculative decoding: draft model or n-gram lookup.
- Support RPC server mode, which can serve as a remote inference backend.
- Support injecting
X-Request-IDhttp header for tracking requests.
Download LLaMA Box from the latest release page please, now LLaMA Box supports the following platforms.
| Backend | OS/Arch | Device Requirement |
|---|---|---|
| NVIDIA CUDA 12.4 | linux/amd64windows/amd64 |
Compute capability matches 6.0, 6.1, 7.0, 7.5 ,8.0, 8.6, 8.9 or 9.0, see https://developer.nvidia.com/cuda-gpus. Driver version requires >=525.60.13(linux)/>=528.33(windows), see https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#id4. |
| NVIDIA CUDA 11.8 | linux/amd64windows/amd64 |
Compute capability matches 6.0, 6.1, 7.0, 7.5 ,8.0, 8.6, 8.9 or 9.0, see https://developer.nvidia.com/cuda-gpus. Driver version requires >=450.80.02(linux)/>=452.39(windows), see https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#id4. |
| AMD ROCm/HIP 6.1 | linux/amd64windows/amd64 |
LLVM target matches gfx906 (linux only), gfx908 (linux only), gfx90a (linux only), gfx942 (linux only), gfx1030, gfx1100, gfx1101 or gfx1102, see https://rocm.docs.amd.com/projects/install-on-linux/en/docs-6.1.2/reference/system-requirements.html, https://rocm.docs.amd.com/projects/install-on-windows/en/docs-6.1.2/reference/system-requirements.html. |
| Intel oneAPI 2025.0 | linux/amd64windows/amd64 |
Support Intel oneAPI, see https://www.intel.com/content/www/us/en/developer/articles/system-requirements/intel-oneapi-base-toolkit-system-requirements.html. |
| Huawei Ascend CANN 8.0 | linux/amd64linux/arm64 |
Ascend 910b, Ascend 310p, see https://www.hiascend.com/document/detail/en/CANNCommunityEdition/600alphaX/softwareinstall/instg/atlasdeploy_03_0015.html. |
| Moore Threads MUSA rc3.1 | linux/amd64 |
MTT S4000, MTT S80, see https://en.mthreads.com. |
| Apple Metal 3 | darwin/amd64darwin/arm64 |
Support Apple Metal, see https://support.apple.com/en-sg/102894. |
| AVX2 | darwin/amd64linux/amd64windows/amd64 |
CPUs support AVX2, see https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#Advanced_Vector_Extensions_2. |
| Advanced SIMD (NEON) | linux/arm64windows/arm64 |
CPUs support Advanced SIMD (NEON), see https://en.wikipedia.org/wiki/ARM_architecture_family#Advanced_SIMD_(Neon). |
| AVX512 | linux/amd64windows/amd64 |
CPUs support AVX512, see https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#AVX-512. |
Note
Since v0.0.60, the build of Linux releases are as follows:
- "NVIDIA CUDA 12.4/11.8" and "AMD ROCm/HIP 6.1" releases are built on CentOS 7 (glibc 2.17),
- "Intel oneAPI 2025.0" releases are built on Ubuntu 22.04 (glibc 2.34).
- "Huawei Ascend CANN 8.0" releases are built on Ubuntu 20.04 (glibc 2.31) and OpenEuler 20.03 (glibc 2.28).
- "Moore Threads MUSA rc3.1" releases are built on Ubuntu 22.04 (glibc 2.34).
- "AVX2" releases are built on CentOS 7 (glibc 2.17).
- "Advanced SIMD (NEON)" releases are built on Ubuntu 18.04 (glibc 2.27).
- "AVX512" releases are built on RockyLinux 8.9 (glibc 2.28).
Note: LM Studio provides a fantastic UI for downloading the GGUF model from Hugging Face. The GGUF model files used in the following examples are downloaded via LM Studio.
-
Chat completion via Nous-Hermes-2-Mistral-7B-DPO model. Use GGUF files from NousResearch/Nous-Hermes-2-Mistral-7B-DPO-GGUF.
$ # Provide 4 sessions(allowing 4 parallel chat users), with a max of 2048 tokens per session. $ llama-box -c 8192 -np 4 --host 0.0.0.0 -m ~/.cache/lm-studio/models/NousResearch/Nous-Hermes-2-Mistral-7B-DPO-GGUF/Nous-Hermes-2-Mistral-7B-DPO.Q5_K_M.gguf $ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "hermes2", "messages": [{"role":"user", "content":"Introduce Beijing in 50 words."}]}' $ # or use the chat.sh tool $ ./llama-box/tools/chat.sh "Introduce Beijing in 50 words."
-
Chat completion with vision explanation via Qwen2-VL-2B-Instruct model. Use GGUF files from bartowski/Qwen2-VL-2B-Instruct-GGUF.
$ # Provide 4 session(allowing 4 parallel chat users), with a max of 2048 tokens per session. $ llama-box -c 8192 -np 4 --host 0.0.0.0 -m ~/.cache/lm-studio/models/bartowski/Qwen2-VL-2B-Instruct-GGUF/Qwen2-VL-2B-Instruct-Q4_0.gguf --mmproj ~/.cache/lm-studio/models/bartowski/Qwen2-VL-2B-Instruct-GGUF/mmproj-Qwen2-VL-2B-Instruct-f32.gguf $ IMAGE_URL="$(echo "data:image/jpeg;base64,$(curl https://raw.githubusercontent.com/haotian-liu/LLaVA/main/llava/serve/examples/extreme_ironing.jpg --output - | base64)")"; \ echo "{\"model\": \"qwen2-vl\", \"temperature\": 0.1, \"messages\": [{\"role\":\"system\", \"content\": [{\"type\": \"text\", \"text\": \"You are a helpful assistant.\"}]}, {\"role\":\"user\", \"content\": [{\"type\": \"image_url\", \"image_url\": {\"url\": \"$IMAGE_URL\"}}, {\"type\": \"text\", \"text\": \"What is unusual about this image?\"}]}]}" > /tmp/data.json $ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d @/tmp/data.json $ # or use the chat.sh tool $ ./llama-box/tools/chat.sh @/tmp/data.json
-
Image generation via Stable Diffusion 3.5 Medium model. Use GGUF files from gpustack/stable-diffusion-v3-5-medium-GGUF.
$ # Provide 1 session(allowing 1 parallel chat user). $ llama-box -np 1 --host 0.0.0.0 -m ~/.cache/lm-studio/models/gpustack/stable-diffusion-v3.5-medium-GGUF/stable-diffusion-v3-5-medium-FP16.gguf --images $ curl http://localhost:8080/v1/images/generations -H "Content-Type: application/json" -d '{"model": "sd3-medium", "prompt": "A lovely cat"}' $ # or use the image_generate.sh tool $ ./llama-box/tools/image_generate.sh "A lovely cat"
-
Draft model speculative decoding via Qwen2-7B-Instruct and Qwen2-1.5B-Instruct models. Use GGUF files from QuantFactory/Qwen2-7B-Instruct-GGUF and QuantFactory/Qwen2-1.5B-Instruct-GGUF.
$ # Provide 4 session(allowing 4 parallel chat users), with a max of 2048 tokens per session. $ llama-box -c 8192 -np 4 --host 0.0.0.0 -m ~/.cache/lm-studio/models/QuantFactory/Qwen2-7B-Instruct-GGUF/Qwen2-7B-Instruct.Q5_K_M.gguf -md ~/.cache/lm-studio/models/QuantFactory/Qwen2-1.5B-Instruct-GGUF/Qwen2-1.5B-Instruct.Q5_K_M.gguf --draft 8 $ curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{"model": "qwen2", "stream": true, "prompt": "Write a short story about a cat and a dog, more than 100 words."}' $ # or use the chat.sh tool $ ./llama-box/tools/chat.sh "Write a short story about a cat and a dog, more than 100 words."
-
Lookup speculative decoding via Mistral-Nemo-Instruct-2407 model. Use GGUF files from QuantFactory/Mistral-Nemo-Instruct-2407-GGUF.
$ # Provide 2 session(allowing 2 parallel chat users), with a max of 8192 tokens per session. $ llama-box -c 16384 -np 2 --host 0.0.0.0 -m ~/.cache/lm-studio/models/QuantFactory/Mistral-Nemo-Instruct-2407-GGUF/Mistral-Nemo-Instruct-2407.Q5_K_M.gguf --lookup-ngram-min 1 --draft 8 $ CONTENT="$(curl https://en.wikipedia.org/w/api.php\?action\=query\&format\=json\&titles\=Medusa\&prop\=extracts\&exintro\&explaintext | jq '.query.pages | to_entries | .[0].value.extract | gsub("\n"; "\\n") | gsub("\t"; "\\t")')"; \ echo "{\"model\": \"mistral-nemo\", \"stream\": true, \"messages\": [{\"role\":\"user\", \"content\": [{\"type\": \"text\", \"text\": \"Please read the following content and summarize the article in 5 sentences.\"}, {\"type\": \"text\", \"text\": "$CONTENT"}]}]}" > /tmp/data.json $ curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d @/tmp/data.json $ # or use the chat.sh tool $ ./llama-box/tools/chat.sh @/tmp/data.json
-
Maximize search relevancy and RAG accuracy via jinaai/jina-reranker-v1-tiny-en model. Use GGUF files from gpustack/jina-reranker-v1-tiny-en-GGUF.
$ # Provide 4 session(allowing 4 parallel chat users), with a max of 2048 tokens per session. $ llama-box -c 8192 -np 4 --host 0.0.0.0 -m ~/.cache/lm-studio/models/gpustack/jina-reranker-v1-tiny-en-GGUF/jina-reranker-v1-tiny-en-FP16.gguf --rerank $ curl http://localhost:8080/v1/rerank -H "Content-Type: application/json" -d '{"model":"jina-reranker-v1-tiny-en","query":"Organic skincare products for sensitive skin","top_n":3,"documents":["Eco-friendly kitchenware for modern homes","Biodegradable cleaning supplies for eco-conscious consumers","Organic cotton baby clothes for sensitive skin","Natural organic skincare range for sensitive skin","Tech gadgets for smart homes: 2024 edition","Sustainable gardening tools and compost solutions","Sensitive skin-friendly facial cleansers and toners","Organic food wraps and storage solutions","All-natural pet food for dogs with allergies","oga mats made from recycled materials"]}'
-
RPC server mode.
In RPC server mode, LLaMA Box functions as the
ggmlbackend on a remote host. This setup allows non-RPC server instances (clients) to communicate with the RPC servers, offloading computational tasks to them.While the RPC server facilitates the use of larger models, it requires the RPC client to transfer the necessary computational materials. This transfer can lead to increased startup times for the RPC client. Additionally, network latency and bandwidth limitations may impact the overall performance of the RPC client.
By understanding these dynamics, users can better manage expectations and optimize their use of LLaMA Box in an RPC server environment.
Loadingflowchart TD clix-->|TCP|srva clix-->|TCP|srvb cliy-->|TCP|srvb cliy-.->|TCP|srvn subgraph hostn[Any] srvn["llama-box-*-cuda/metal/... (rpc server)"] end subgraph hostb[Apple Mac Studio] srvb["llama-box-*-metal (rpc server)"] end subgraph hosta[NVIDIA 4090] srva["llama-box-*-cuda (rpc server)"] end subgraph hosty[Apple Mac Max] cliy["llama-box-*-metal"] end subgraph hostx[NVIDIA 4080] clix["llama-box-*-cuda"] end style hostn stroke:#66,stroke-width:2px,stroke-dasharray: 5 5
$ # Start the RPC server on the main GPU 0, reserve 1 GiB memory. $ llama-box --rpc-server-host 0.0.0.0 --rpc-server-port 8081 --rpc-server-main-gpu 0 --rpc-server-reserve-memory 1024
usage: llama-box [options]
general:
-h, --help, --usage print usage and exit
--version print version and exit
--system-info print system info and exit
--list-devices print list of available devices and exit
-v, --verbose, --log-verbose
set verbosity level to infinity (i.e. log all messages, useful for debugging)
-lv, --verbosity, --log-verbosity V
set the verbosity threshold, messages with a higher verbosity will be ignored
--log-colors enable colored logging
server:
--host HOST ip address to listen (default: 127.0.0.1)
--port PORT port to listen (default: 8080)
-to --timeout N server read/write timeout in seconds (default: 600)
--threads-http N number of threads used to process HTTP requests (default: -1)
--conn-idle N server connection idle in seconds (default: 60)
--conn-keepalive N server connection keep-alive in seconds (default: 15)
-m, --model FILE model path (default: models/7B/ggml-model-f16.gguf)
-a, --alias NAME model name alias
--lora FILE apply LoRA adapter (implies --no-mmap)
--lora-scaled FILE SCALE
apply LoRA adapter with user defined scaling S (implies --no-mmap)
--lora-init-without-apply
load LoRA adapters without applying them (apply later via POST /lora-adapters) (default: disabled)
-s, --seed N RNG seed (default: -1, use random seed for -1)
-mg, --main-gpu N the GPU to use for the model (default: 0)
-fa, --flash-attn enable Flash Attention (default: disabled)
--metrics enable prometheus compatible metrics endpoint (default: disabled)
--infill enable infill endpoint (default: disabled)
--embeddings enable embedding endpoint (default: disabled)
--images enable image endpoint (default: disabled)
--rerank enable reranking endpoint (default: disabled)
--slots enable slots monitoring endpoint (default: disabled)
--rpc SERVERS comma separated list of RPC servers
--no-warmup skip warming up the model with an empty run
server/completion:
-dev, --device <dev1,dev2,...>
comma-separated list of devices to use for offloading (none = don't offload)
use --list-devices to see a list of available devices
-ngl, --gpu-layers, --n-gpu-layers N
number of layers to store in VRAM
-sm, --split-mode SPLIT_MODE how to split the model across multiple GPUs, one of:
- none: use one GPU only
- layer (default): split layers and KV across GPUs
- row: split rows across GPUs, store intermediate results and KV in --main-gpu
-ts, --tensor-split SPLIT fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1
--override-kv KEY=TYPE:VALUE
advanced option to override model metadata by key. may be specified multiple times.
types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false
--chat-template JINJA_TEMPLATE
set custom jinja chat template (default: template taken from model's metadata)
list of built-in templates:
chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, exaone3, falcon, gemma, granite, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llava, llava-mistral, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, monarch, openchat, orion, phi3, rwkv-world, vicuna, vicuna-orca, zephyr
--chat-template-file FILE
set a file to load a custom jinja chat template (default: template taken from model's metadata)
--slot-save-path PATH path to save slot kv cache (default: disabled)
-sps, --slot-prompt-similarity N
how much the prompt of a request must match the prompt of a slot in order to use that slot (default: 0.50, 0.0 = disabled)
-tps --tokens-per-second N maximum number of tokens per second (default: 0, 0 = disabled, -1 = try to detect)
when enabled, limit the request within its X-Request-Tokens-Per-Second HTTP header
-t, --threads N number of threads to use during generation (default: -1)
-C, --cpu-mask M set CPU affinity mask: arbitrarily long hex. Complements cpu-range (default: "")
-Cr, --cpu-range lo-hi range of CPUs for affinity. Complements --cpu-mask
--cpu-strict <0|1> use strict CPU placement (default: 0)
--prio N set process/thread priority (default: 0), one of:
- 0-normal
- 1-medium
- 2-high
- 3-realtime
--poll <0...100> use polling level to wait for work (0 - no polling, default: 50)
-tb, --threads-batch N number of threads to use during batch and prompt processing (default: same as --threads)
-Cb, --cpu-mask-batch M set CPU affinity mask: arbitrarily long hex. Complements cpu-range-batch (default: same as --cpu-mask)
-Crb, --cpu-range-batch lo-hi ranges of CPUs for affinity. Complements --cpu-mask-batch
--cpu-strict-batch <0|1>
use strict CPU placement (default: same as --cpu-strict)
--prio-batch N set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime (default: --priority)
--poll-batch <0...100> use polling to wait for work (default: same as --poll
-c, --ctx-size N size of the prompt context (default: 4096, 0 = loaded from model)
--no-context-shift disables context shift on infinite text generation (default: disabled)
-n, --predict N number of tokens to predict (default: -1, -1 = infinity, -2 = until context filled)
-b, --batch-size N logical maximum batch size (default: 2048)
-ub, --ubatch-size N physical maximum batch size (default: 512)
--keep N number of tokens to keep from the initial prompt (default: 0, -1 = all)
-e, --escape process escapes sequences (\n, \r, \t, \', \", \\) (default: true)
--no-escape do not process escape sequences
--samplers SAMPLERS samplers that will be used for generation in the order, separated by ';' (default: dry;top_k;typ_p;top_p;min_p;xtc;temperature)
--sampling-seq SEQUENCE simplified sequence for samplers that will be used (default: dkypmxt)
--penalize-nl penalize newline tokens (default: false)
--temp T temperature (default: 0.8)
--top-k N top-k sampling (default: 40, 0 = disabled)
--top-p P top-p sampling (default: 0.9, 1.0 = disabled)
--min-p P min-p sampling (default: 0.1, 0.0 = disabled)
--xtc-probability N xtc probability (default: 0.0, 0.0 = disabled)
--xtc-threshold N xtc threshold (default: 0.1, 1.0 = disabled)
--typical P locally typical sampling, parameter p (default: 1.0, 1.0 = disabled)
--repeat-last-n N last n tokens to consider for penalize (default: 64, 0 = disabled, -1 = ctx_size)
--repeat-penalty N penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled)
--presence-penalty N repeat alpha presence penalty (default: 0.0, 0.0 = disabled)
--frequency-penalty N repeat alpha frequency penalty (default: 0.0, 0.0 = disabled)
--dry-multiplier N set DRY sampling multiplier (default: 0.0, 0.0 = disabled)
--dry-base N set DRY sampling base value (default: 1.75)
--dry-allowed-length N set allowed length for DRY sampling (default: 2)
--dry-penalty-last-n N set DRY penalty for the last n tokens (default: -1, 0 = disable, -1 = context size)
--dry-sequence-breaker N
add sequence breaker for DRY sampling, clearing out default breakers (
;:;";*) in the process; use "none" to not use any sequence breakers
--dynatemp-range N dynamic temperature range (default: 0.0, 0.0 = disabled)
--dynatemp-exp N dynamic temperature exponent (default: 1.0)
--mirostat N use Mirostat sampling, Top K, Nucleus, Tail Free and Locally Typical samplers are ignored if used (default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)
--mirostat-lr N Mirostat learning rate, parameter eta (default: 0.1)
--mirostat-ent N Mirostat target entropy, parameter tau (default: 5.0)
-l --logit-bias TOKEN_ID(+/-)BIAS
modifies the likelihood of token appearing in the completion, i.e. "--logit-bias 15043+1" to increase likelihood of token ' Hello', or "--logit-bias 15043-1" to decrease likelihood of token ' Hello'
--grammar GRAMMAR BNF-like grammar to constrain generations (see samples in grammars/ dir) (default: '')
--grammar-file FILE file to read grammar from
-j, --json-schema SCHEMA JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON object. For schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead
--rope-scaling {none,linear,yarn}
RoPE frequency scaling method, defaults to linear unless specified by the model
--rope-scale N RoPE context scaling factor, expands context by a factor of N
--rope-freq-base N RoPE base frequency, used by NTK-aware scaling (default: loaded from model)
--rope-freq-scale N RoPE frequency scaling factor, expands context by a factor of 1/N
--yarn-orig-ctx N YaRN: original context size of model (default: 0 = model training context size)
--yarn-ext-factor N YaRN: extrapolation mix factor (default: -1.0, 0.0 = full interpolation)
--yarn-attn-factor N YaRN: scale sqrt(t) or attention magnitude (default: 1.0)
--yarn-beta-fast N YaRN: low correction dim or beta (default: 32.0)
--yarn-beta-slow N YaRN: high correction dim or alpha (default: 1.0)
-nkvo, --no-kv-offload disable KV offload
--no-cache-prompt disable caching prompt
--cache-reuse N min chunk size to attempt reusing from the cache via KV shifting (default: 0)
-ctk, --cache-type-k TYPE KV cache data type for K, allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 (default: f16)
-ctv, --cache-type-v TYPE KV cache data type for V, allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1 (default: f16)
-dt, --defrag-thold N KV cache defragmentation threshold (default: 0.1, < 0 - disabled)
-np, --parallel N number of parallel sequences to decode (default: 1)
-nocb, --no-cont-batching disable continuous batching
--mmproj FILE path to a multimodal projector file for LLaVA
--mlock force system to keep model in RAM rather than swapping or compressing
--no-mmap do not memory-map model (slower load but may reduce pageouts if not using mlock)
--numa TYPE attempt optimizations that help on some NUMA systems
- distribute: spread execution evenly over all nodes
- isolate: only spawn threads on CPUs on the node that execution started on
- numactl: use the CPU map provided by numactl
if run without this previously, it is recommended to drop the system page cache before using this, see https://github.com/ggerganov/llama.cpp/issues/1437
--control-vector FILE add a control vector
--control-vector-scaled FILE SCALE
add a control vector with user defined scaling SCALE
--control-vector-layer-range START END
layer range to apply the control vector(s) to, start and end inclusive
--spm-infill use Suffix/Prefix/Middle pattern for infill (instead of Prefix/Suffix/Middle) as some models prefer this (default: disabled)
-sp, --special special tokens output enabled (default: false)
server/completion/speculative:
--draft-max, --draft, --draft-n N
number of tokens to draft for speculative decoding (default: 16)
--draft-min, --draft-n-min N
minimum number of draft tokens to use for speculative decoding (default: 5)
--draft-p-min P minimum speculative decoding probability (greedy) (default: 0.9)
-md, --model-draft FNAME draft model for speculative decoding (default: unused)
-devd, --device-draft <dev1,dev2,...>
comma-separated list of devices to use for offloading the draft model (none = don't offload)
use --list-devices to see a list of available devices
-ngld, --gpu-layers-draft, --n-gpu-layers-draft N
number of layers to store in VRAM for the draft model
--lookup-ngram-min N minimum n-gram size for lookup cache (default: 0, 0 = disabled)
-lcs, --lookup-cache-static FILE
path to static lookup cache to use for lookup decoding (not updated by generation)
-lcd, --lookup-cache-dynamic FILE
path to dynamic lookup cache to use for lookup decoding (updated by generation)
--pooling pooling type for embeddings, use model default if unspecified
server/images:
--image-max-batch N maximum batch count (default: 4)
--image-max-height N image maximum height, in pixel space, must be larger than 256 and be multiples of 64 (default: 1024)
--image-max-width N image maximum width, in pixel space, must be larger than 256 and be multiples of 64 (default: 1024)
--image-guidance N the value of guidance during the computing phase (default: 3.500000)
--image-strength N strength for noising, range of [0.0, 1.0] (default: 0.750000)
--image-sampler TYPE sampler that will be used for generation, automatically retrieve the default value according to --model, allowed values: euler_a, euler, heun, dpm2, dpm++2s_a, dpm++2m, dpm++2mv2, ipndm, ipndm_v, lcm
--image-sample-steps N number of sample steps, automatically retrieve the default value according to --model, and +2 when requesting high definition generation
--image-cfg-scale N the scale of classifier-free guidance(CFG), automatically retrieve the default value according to --model (1.0 = disabled)
--image-slg-scale N the scale of skip-layer guidance(SLG), only for DiT model, automatically retrieve the default value according to --model (0.0 = disabled)
--image-slg-skip-layer the layers to skip when processing SLG, may be specified multiple times. (default: 7;8;9)
--image-slg-start N the phase to enable SLG (default: 0.01)
--image-slg-end N the phase to disable SLG (default: 0.20)
SLG will be enabled at step int([STEP]*[--image-slg-start]) and disabled at int([STEP]*[--image-slg-end])
--image-schedule TYPE denoiser sigma schedule, allowed values: default, discrete, karras, exponential, ays, gits (default: default)
--image-no-text-encoder-model-offload
disable text-encoder(clip-l/clip-g/t5xxl) model offload
--image-clip-l-model PATH
path to the CLIP Large (clip-l) text encoder, or use --model included
--image-clip-g-model PATH
path to the CLIP Generic (clip-g) text encoder, or use --model included
--image-t5xxl-model PATH
path to the Text-to-Text Transfer Transformer (t5xxl) text encoder, or use --model included
--image-no-vae-model-offload
disable vae(taesd) model offload
--image-vae-model PATH path to Variational AutoEncoder (vae), or use --model included
--image-vae-tiling indicate to process vae decoder in tiles to reduce memory usage (default: disabled)
--image-no-vae-tiling disable vae decoder in tiles
--image-taesd-model PATH
path to Tiny AutoEncoder For StableDiffusion (taesd), or use --model included
--image-upscale-model PATH
path to the upscale model, or use --model included
--image-upscale-repeats N
how many times to run upscaler (default: 1)
--image-no-control-net-model-offload
disable control-net model offload
--image-control-net-model PATH
path to the control net model, or use --model included
--image-control-strength N
how strength to apply the control net (default: 0.900000)
--image-control-canny indicate to apply canny preprocessor (default: disabled)
--image-free-compute-memory-immediately
indicate to free compute memory immediately, which allow generating high resolution image (default: disabled)
rpc-server:
--rpc-server-host HOST ip address to rpc server listen (default: 0.0.0.0)
--rpc-server-port PORT port to rpc server listen (default: 0, 0 = disabled)
--rpc-server-main-gpu N the GPU VRAM to use for the rpc server (default: 0, -1 = disabled, use RAM)
--rpc-server-reserve-memory MEM
reserve memory in MiB (default: 0)
Available environment variables (if the corresponding command-line option is not provided):
LLAMA_ARG_MODEL: equivalent to-m,--model.LLAMA_ARG_MODEL_ALIAS: equivalent to-a,--model-alias.LLAMA_ARG_THREADS: equivalent to-t,--threads.LLAMA_ARG_CTX_SIZE: equivalent to-c,--ctx-size.LLAMA_ARG_N_PARALLEL: equivalent to-np,--parallel.LLAMA_ARG_BATCH: equivalent to-b,--batch-size.LLAMA_ARG_UBATCH: equivalent to-ub,--ubatch-size.LLAMA_ARG_DEVICE: equivalent to-dev,--device.LLAMA_ARG_N_GPU_LAYERS: equivalent to-ngl,--gpu-layers,--n-gpu-layers.LLAMA_ARG_THREADS_HTTP: equivalent to--threads-httpLLAMA_ARG_CACHE_PROMPT: if set to0, it will disable caching prompt (equivalent to--no-cache-prompt). This feature is enabled by default.LLAMA_ARG_CACHE_REUSE: equivalent to--cache-reuseLLAMA_ARG_CHAT_TEMPLATE: equivalent to--chat-templateLLAMA_ARG_N_PREDICT: equivalent to-n,--predict.LLAMA_ARG_METRICS: if set to1, it will enable metrics endpoint (equivalent to--metrics).LLAMA_ARG_SLOTS: if set to1, it will enable slots endpoint (equivalent to--slots).LLAMA_ARG_EMBEDDINGS: if set to1, it will enable embeddings endpoint (equivalent to--embeddings).LLAMA_ARG_FLASH_ATTN: if set to1, it will enable flash attention (equivalent to-fa,--flash-attn).LLAMA_ARG_CONT_BATCHING: if set to0, it will disable continuous batching (equivalent to--no-cont-batching). This feature is enabled by default.LLAMA_ARG_DEFRAG_THOLD: equivalent to-dt,--defrag-thold.LLAMA_ARG_HOST: equivalent to--hostLLAMA_ARG_PORT: equivalent to--portLLAMA_ARG_DRAFT_MAX: equivalent to--draft-maxLLAMA_ARG_DRAFT_MIN: equivalent to--draft-minLLAMA_ARG_DRAFT_P_MIN: equivalent to--draft-p-minLLAMA_ARG_MODEL_DRAFT: equivalent to-md,--model-draft.LLAMA_ARG_DEVICE_DRAFT: equivalent to-devd,--device-draft.LLAMA_ARG_N_GPU_LAYERS_DRAFT: equivalent to-ngld,--gpu-layers-draft.LLAMA_ARG_LOOKUP_NGRAM_MIN: equivalent to--lookup-ngram-min.LLAMA_ARG_LOOKUP_CACHE_STATIC: equivalent to-lcs,--lookup-cache-static.LLAMA_ARG_LOOKUP_CACHE_DYNAMIC: equivalent to-lcd,--lookup-cache-dynamic.LLAMA_ARG_RPC_SERVER_HOST: equivalent to--rpc-server-host.LLAMA_ARG_RPC_SERVER_PORT: equivalent to--rpc-server-port.LLAMA_LOG_VERBOSITY: equivalent to--log-verbosity.
The available endpoints for the LLaMA Box server mode are:
-
GET
/health: Returns the heath check result of the LLaMA Box.RESPONSE : (application/json) CASE 1: model is still being loaded {"error": {"code": 503, "message": "Loading model", "type": "unavailable_error"}} CASE 2: model is successfully loaded and the server is ready {"status": "ok" } -
GET
/metrics: Returns the Prometheus compatible metrics of the LLaMA Box.- This endpoint is only available if the
--metricsflag is enabled. llamabox:image_process_seconds_total: (Counter) Image process time.llamabox:image_generate_seconds_total: (Counter) Image generate time.llamabox:image_generate_steps_total: (Counter) Number of image generate steps.llamabox:prompt_tokens_total: (Counter) Number of prompt tokens processed.llamabox:prompt_seconds_total: (Counter) Prompt process time.llamabox:tokens_predicted_total: (Counter) Number of generation tokens processed.llamabox:tokens_predicted_seconds_total: (Counter) Predict process time.llamabox:tokens_drafted_total: (Counter) Number of speculative decoding tokens processed.llamabox:tokens_drafted_accepted_total: (Counter) Number of speculative decoding tokens to be accepted.llamabox:n_decode_total: (Counter) Total number of llama_decode() calls.llamabox:n_busy_slots_per_decode: (Counter) Average number of busy slots per llama_decode() call.llamabox:image_steps_seconds: (Gauge) Average image generation throughput in steps/s.llamabox:prompt_tokens_seconds: (Gauge) Average prompt throughput in tokens/s.llamabox:predicted_tokens_seconds: (Gauge) Average generation throughput in tokens/s.llamabox:kv_cache_usage_ratio: (Gauge) KV-cache usage. 1 means 100 percent usage.llamabox:kv_cache_tokens: (Gauge) KV-cache tokens.llamabox:requests_processing: (Gauge) Number of request processing.llamabox:requests_deferred: (Gauge) Number of request deferred.
RESPONSE : (text/plain) # HELP llamabox:prompt_tokens_total Number of prompt tokens processed. .... - This endpoint is only available if the
-
GET
/props: Returns current server settings.RESPONSE : (application/json) { "chat_template": "...", "default_generation_settings": {...}, "total_slots": 4 } -
GET
/slots: Returns the current slots processing state.- If query param
?fail_on_no_slot=1is set, this endpoint will respond with status code 503 if there is no available slots. - This endpoint is only available if the
--slotsflag is provided. slot[i].state == 0is idle, otherwise processing.
RESPONSE : (application/json) [ { "id": 0, "id_task": -1, "state": 0, ... }, ... ] - If query param
-
POST
/slots/:id_slot?action={save|restore|erase}: Operate specific slot via ID.- This endpoint is only available if the
--slotsflag is provided and--slot-save-pathis provided.
- This endpoint is only available if the
-
POST
/infill: Returns the completion of the given prompt.- This is only work to
Text-To-Textmodels. - This endpoint is only available if the
--infillflag is enabled.
- This is only work to
-
POST
/tokenize: Convert text to tokens.- This is only work to
Text-To-TextorEmbeddingmodels.
REQUEST : (application/json) { "content": "", "add_special": false, "with_pieces": false } RESPONSE : (application/json) CASE 1: without pieces { "tokens": [123, ...] } CASE 2: with pieces { "tokens": [ {"id": 123, "piece": "Hello"}, ... ] } - This is only work to
-
POST
/detokenize: Convert tokens to text.- This is only work to
Text-To-TextorEmbeddingmodels.
REQUEST : (application/json) { "tokens": [123, ...] } RESPONSE : (application/json) { "content": "..." } - This is only work to
-
GET
/lora-adapters: Returns the current LoRA adapters.- This is only work to
Text-To-Text/Text-To-Image/Image-To-Imagemodels. - This endpoint is only available if any LoRA adapter is applied with
--loraor--lora-scaled.
RESPONSE : (application/json) [ { "id": 0, "path": "...", "scale": 1.0 }, ... ] - This is only work to
-
POST
/lora-adapters: Operate LoRA adapters apply. To disable an LoRA adapter, either remove it from the list or set scale to 0.- This is only work to
Text-To-Text/Text-To-Image/Image-To-Imagemodels. - This endpoint is only available if any LoRA adapter is applied and
--lora-init-without-applyis provided.
REQUEST : (application/json) [ { "id": 0, "scale": 0.2 }, ... ] - This is only work to
-
POST
/completion: Returns the completion of the given prompt.- This is only work to
Text-To-Textmodels.
- This is only work to
-
GET
/v1/models: (OpenAI-compatible) Returns the list of available models, see https://platform.openai.com/docs/api-reference/models/list. -
POST
/v1/chat/completions(OpenAI-compatible) Returns the completion of the given prompt, see https://platform.openai.com/docs/api-reference/chat/create.- This is only work to
Text-To-TextorImage-To-Textmodels. - This endpoint is compatible with OpenAI Chat Vision API when
enabled
--mmprojflag, see https://huggingface.co/xtuner/llava-phi-3-mini-gguf/tree/main. (Note: do not support linkurl, use base64 encoded image instead.)
- This is only work to
-
POST
/v1/embeddings: (OpenAI-compatible) Returns the embeddings of the given prompt, see https://platform.openai.com/docs/api-reference/embeddings/create.- This is only work to
Text-To-TextorEmbeddingmodels. - This endpoint is available if the
--embeddingsor--rerankflag is enabled.
- This is only work to
-
POST
/v1/completions: (LEGACY OpenAI-compatible) Returns the completion of the given prompt, see https://platform.openai.com/docs/api-reference/completions/create.- This is only work to
Text-To-Textmodels.
- This is only work to
-
POST
/v1/images/generations: (OpenAI-compatible) Returns a generated image from the given prompt, see https://platform.openai.com/docs/api-reference/images/generations/create.- This is only work to
Text-To-Imagemodels. - This endpoint is available if the
--imagesflag is enabled. - This endpoint supports
stream: trueto return the progressing of the generation.REQUEST : (application/json) { "n": 1, "response_format": "b64_json", "size": "512x512", "prompt": "A lovely cat", "quality": "standard", "stream": true, "stream_options": { "include_usage": true, // return usage information "chunk_result": true, // split the final image b64_json into chunks to avoid browser caching "chunk_size": 4096, // split the final image b64_json into chunks with the given size, default 4k "preview": true, // enable preview mode "preview_faster": true // enable faster preview mode } } RESPONSE : (text/event-stream) data: {"created":1731916353,"data":[{"index":0,"object":"image.chunk","progress":10.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":50.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":100.0,"b64_json":"..."}], "usage":{"generation_per_second":...,"time_per_generation_ms":...,"time_to_process_ms":...}, ...} data: [DONE] - This endpoint also supports some options
like Stable Diffusion web UI.
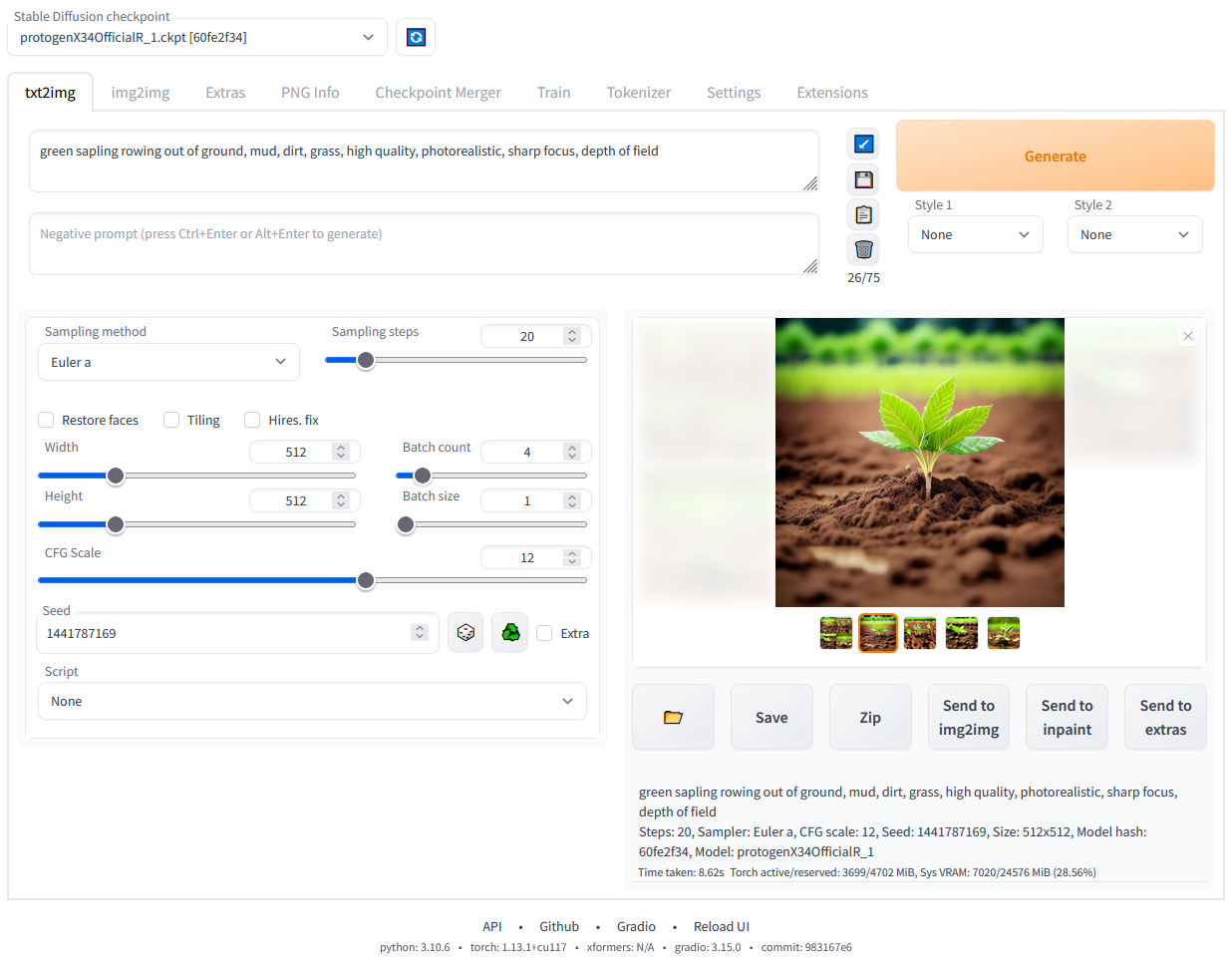
REQUEST : (application/json) { "n": 1, "response_format": "b64_json", "size": "512x512", "prompt": "A lovely cat", "sampler": "euler", // required, select from euler_a;euler;heun;dpm2;dpm++2s_a;dpm++2m;dpm++2mv2;ipndm;ipndm_v;lcm "schedule": "default", // optional, select from default;discrete;karras;exponential;ays;gits "seed": null, // optional, random seed "guidance": 3.5, // optional, unconditional guidance value "cfg_scale": 4.5, // optional, for sampler, the scale of classifier-free guidance in the output phase "sample_steps": 20, // optional, number of sample steps "negative_prompt": "", // optional, negative prompt "stream": true, "stream_options": { "include_usage": true, // return usage information "chunk_result": true, // split the final image b64_json into chunks to avoid browser caching "chunk_size": 4096, // split the final image b64_json into chunks with the given size, default 4k "preview": true, // enable preview mode "preview_faster": true // enable faster preview mode } } RESPONSE : (text/event-stream) data: {"created":1731916353,"data":[{"index":0,"object":"image.chunk","progress":10.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":50.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":100.0,"b64_json":"..."}], "usage":{"generation_per_second":...,"time_per_generation_ms":...,"time_to_process_ms":...}, ...} data: [DONE]
- This is only work to
-
POST
/v1/images/edits: (OpenAI-compatible) Returns an edited image from the given prompt and initial image, see https://platform.openai.com/docs/api-reference/images/edits/create.- This is only work to
Image-To-Imagemodels. - This endpoint is available if the
--imagesflag is enabled. - This endpoint supports
stream: trueto return the progressing of the generation.REQUEST: (multipart/form-data) n=1 response_format=b64_json size=512x512 prompt="A lovely cat" quality=standard image=... // required mask=... // optional stream=true stream_options_include_usage=true // return usage information stream_options_chunk_result=true // split the final image b64_json into chunks to avoid browser caching stream_options_chunk_size=4096 // split the final image b64_json into chunks with the given size, default 4k stream_options_preview=true // enable preview mode stream_options_preview_faster=true // enable faster preview mode RESPONSE : (text/event-stream) CASE 1: correct input image data: {"created":1731916353,"data":[{"index":0,"object":"image.chunk","progress":10.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":50.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":100.0,"b64_json":"..."}], "usage":{"generation_per_second":...,"time_per_generation_ms":...,"time_to_process_ms":...}, ...} data: [DONE] CASE 2: illegal input image error: {"code": 400, "message": "Invalid image", "type": "invalid_request_error"} - This endpoint also supports some options
like Stable Diffusion web UI.
REQUEST: (multipart/form-data) n=1 response_format=b64_json size=512x512 prompt="A lovely cat" image=... // required mask=... // optional sampler=euler // required, select from euler_a;euler;heun;dpm2;dpm++2s_a;dpm++2m;dpm++2mv2;ipndm;ipndm_v;lcm schedule=default // optional, select from default;discrete;karras;exponential;ays;gits seed=null // optional, random seed guidance=3.5 // optional, unconditional guidance value strength=0.75 // optional, for sampler, the strength of noising/unnoising cfg_scale=4.5 // optional, for sampler, the scale of classifier-free guidance in the output phase sample_steps=20 // optional, number of sample steps negative_prompt="" // optional, negative prompt stream=true stream_options_include_usage=true // return usage information stream_options_chunk_result=true // split the final image b64_json into chunks to avoid browser caching stream_options_chunk_size=4096 // split the final image b64_json into chunks with the given size, default 4k stream_options_preview=true // enable preview mode stream_options_preview_faster=true // enable faster preview mode RESPONSE : (text/event-stream) CASE 1: correct input image data: {"created":1731916353,"data":[{"index":0,"object":"image.chunk","progress":10.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":50.0}], ...} ... data: {"created":1731916371,"data":[{"index":0,"object":"image.chunk","progress":100.0,"b64_json":"..."}], "usage":{"generation_per_second":...,"time_per_generation_ms":...,"time_to_process_ms":...}, ...} data: [DONE] CASE 2: illegal input image error: {"code": 400, "message": "Invalid image", "type": "invalid_request_error"}
- This is only work to
-
POST
/v1/rerank: Returns the completion of the given prompt via lookup cache.- This is only work to
Rerankermodels, like bge-reranker-v2-m3. - This endpoint is only available if the
--rerankflag is provided. - This is unavailable for the GGUF files created before llama.cpp#pr9510.
- This endpoint supports
normalize: falseto return the originalrelevance_scorescore.REQUEST: (application/json) { "model": "...", "query": "...", "documents": [ "..." ], "normalize": false }
- This is only work to
It was so hard to find a Chat UI that was directly compatible with OpenAI,
that mean, no installation required (I can live with docker run),
no tokens (or optional), no Ollama required, just a simple RESTful API.
So we are inspired by the llama.cpp/chat.sh and adjust it to interact with LLaMA Box.
All you need is a Bash shell, curl and jq.
- chat.sh: A simple script to interact with the
/v1/chat/completionsendpoint. - image_generate.sh: Script to interact with the
/v1/images/generationsendpoint. - image_edit.sh: Script to interact with the
/v1/images/editsendpoint. - completion.sh: A simple script to interact with the
/completionendpoint.
Note
Both completion.sh and chat.sh are used for talking with the LLaMA Box,
but completion.sh embeds a fixed pattern to format the given prompt format,
while chat.sh can leverage the chat template from the model's metadata or user defined.
$ # one-shot chat
$ MAX_TOKENS=4096 ./llama-box/tools/chat.sh "Tell me a joke"
$ # interactive chat
$ MAX_TOKENS=4096 ./llama-box/tools/chat.sh
$ # one-shot image generation
$ ./llama-box/tools/image_generate.sh "A lovely cat"
$ # interactive image generation
$ ./llama-box/tools/image_generate.sh
$ # one-shot image editing
$ IMAGE=/path/to/image.png ./llama-box/tools/image_edit.sh "A lovely cat"
$ # interactive image editing
$ IMAGE=/path/to/image.png ./llama-box/tools/image_generate.sh
$ # one-shot completion
$ N_PREDICT=4096 TOP_K=1 ./llama-box/tools/completion.sh "// Quick-sort implementation in C (4 spaces indentation + detailed comments) and sample usage:\n\n#include"
$ # interactive completion
$ N_PREDICT=4096 ./llama-box/tools/completion.shMIT