The Filecoin Proving Subsystem provides the storage proofs required by the Filecoin protocol. It is implemented entirely in Rust, as a series of partially inter-dependent crates – some of which export C bindings to the supported API. This decomposition into distinct crates/modules is relatively recent, and in some cases current code has not been fully refactored to reflect the intended eventual organization.
There are currently four different crates:
-
Storage Proofs (
storage-proofs) A library for constructing storage proofs – including non-circuit proofs, corresponding SNARK circuits, and a method of combining them.storage-proofsis intended to serve as a reference implementation for Proof-of-Replication (PoRep), while also performing the heavy lifting forfilecoin-proofs.Primary Components:
- PoR (Proof-of-Retrievability: Merkle inclusion proof)
- DrgPoRep (Depth Robust Graph Proof-of-Replication)
- StackedDrgPoRep
- PoSt (Proof-of-Spacetime)
-
Filecoin Proofs (
filecoin-proofs) A wrapper aroundstorage-proofs, providing an FFI-exported API callable from C (and in practice called by go-filecoin via cgo). Filecoin-specific values of setup parameters are included here, and circuit parameters generated by Filecoin’s (future) trusted setup will also live here.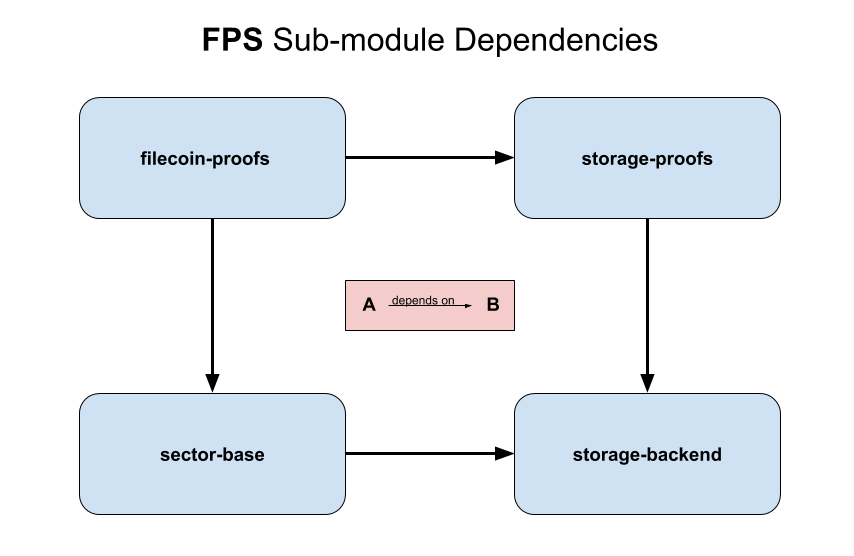

Earlier in the design process, we considered implementing what has become the FPS in Go – as a wrapper around potentially multiple SNARK circuit libraries. We eventually decided to use bellman – a library developed by Zcash, which supports efficient pedersen hashing inside of SNARKs. Having made that decision, it was natural and efficient to implement the entire subsystem in Rust. We considered the benefits (self-contained codebase, ability to rely on static typing across layers) and costs (developer ramp-up, sometimes unwieldiness of borrow-checker) as part of that larger decision and determined that the overall project benefits (in particular ability to build on Zcash’s work) outweighed the costs.
We also considered whether the FPS should be implemented as a standalone binary accessed from go-filecoin either as a single-invocation CLI or as a long-running daemon process. Bundling the FPS as an FFI dependency was chosen for both the simplicity of having a Filecoin node deliverable as a single monolithic binary, and for the (perceived) relative development simplicity of the API implementation.
If at any point it were to become clear that the FFI approach is irredeemably problematic, the option of moving to a standalone FPS remains. However, the majority of technical problems associated with calling from Go into Rust are now solved, even while allowing for a high degree of runtime configurability. Therefore, continuing down the same path we have already invested in, and have begun to reap rewards from, seems likely.
NOTE: If you have installed rust-fil-proofs incidentally, as a submodule of go-filecoin, then you may already have installed Rust.
The instructions below assume you have independently installed rust-fil-proofs in order to test, develop, or experiment with it.
Configure to use nightly:
> rustup default nightly
NOTE: rust-fil-proofs can only be built for and run on 64-bit platforms; building will panic if the target architecture is not 64-bits.
> cargo build --release --all
> cargo test --all
> cargo build --all --examples --release
Running them
> ./target/release/examples/merklepor
> ./target/release/examples/drgporep
> ./target/release/examples/drgporep-vanilla
> ./target/release/examples/drgporep-vanilla-disk
> cargo bench --all
To benchmark the examples you can bencher.
# build the script
> cargo build
# run the benchmarks
> ./target/debug/bencher
The results are written into the .bencher directory, as JSON files. The benchmarks are controlled through the bench.config.toml file.
Note: On macOS you need gtime (brew install gnu-time), as the built in time command is not enough.
For development purposes we have an (experimental) support for CPU and memory profiling in Rust through a gperftools binding library. These can be enabled though the cpu-profile and heap-profile features in filecoin-proofs. An example setup can be found in this Dockerfile to profile CPU usage for the stacked example.
For better logging with backtraces on errors, developers should use expects rather than expect on Result<T, E> and Option<T>.
The crate use log for logging, which by default does not log at all. In order to log output crates like fil_logger can be used.
For example
fn main() {
fil_logger::init();
}and then when running the code setting
> RUST_LOG=filecoin_proofs=infowill enable all logging.
To run the leak detector against the FFI-exposed portion of libsector_builder_ffi.a, simply run the FFI example with leak detection enabled. On a Linux machine, you can run the following command:
RUSTFLAGS="-Z sanitizer=leak" cargo run --release --package filecoin-proofs --example ffi --target x86_64-unknown-linux-gnuIf using mac OS, you'll have to run the leak detection from within a Docker container. After installing Docker, run the following commands to build and run the proper Docker image and then the leak detector itself:
docker build -t foo -f ./Dockerfile-ci . && \
docker run \
-it \
-e RUSTFLAGS="-Z sanitizer=leak" \
--privileged \
-w /mnt/crate \
-v `pwd`:/mnt/crate -v $(TMP=$(mktemp -d) && mv ${TMP} /tmp/ && echo /tmp${TMP}):/mnt/crate/target \
foo:latest \
cargo run --release --package filecoin-proofs --example ffi --target x86_64-unknown-linux-gnuWhile replicating and generating the Merkle Trees (MT) for the proof at the same time there will always be a time-memory trade-off to consider, we present here strategies to optimize one at the cost of the other.
One of the most computational expensive operations during replication (besides the encoding itself) is the generation of the indexes of the (expansion) parents in the Stacked graph, implemented through a Feistel cipher (used as a pseudorandom permutation). To reduce that time we provide a caching mechanism to generate them only once and reuse them throughout replication (across the different layers). Already built into the system it can be activated with the environmental variable
FIL_PROOFS_MAXIMIZE_CACHING=1
To check that it's working you can inspect the replication log to find using parents cache of unlimited size. As the log indicates, we don't have a fine grain control at the moment so it either stores all parents or none. This cache can add almost an entire sector size to the memory used during replication, if you can spare it though this setting is very recommended as it has a considerable impact on replication time.
(You can also verify if the cache is working by inspecting the time each layer takes to encode, encoding, layer: in the log, where the first two layers, forward and reverse, will take more time than the rest to populate the cache while the remaining 8 should see a considerable time drop.)
Speed Optimized Pedersen Hashing - we use Pedersen hashing to generate Merkle Trees and verify Merkle proofs. Batched Pedersen hashing has the property that we can pre-compute known intermediary values intrinsic to the Pedersen hashing process that will be reused across hashes in the batch. By pre-computing and cacheing these intermediary values, we decrease the runtime per Pedersen hash at the cost of increasing memory usage. We optimize for this speed-memory trade-off by varying the cache size via a Pedersen Hash parameter known as the "window-size". This window-size parameter is configured via the pedersen_hash_exp_window_size setting in storage-proofs. By default, Bellman has a cache size of 256 values (a window-size of 8 bits), we increase the cache size to 65,536 values (a window-size of 16 bits) which results in a roughly 40% decrease in Pedersen Hash runtime at the cost of a 9% increase in memory usage. See the Pedersen cache issue for more benchmarks and expected performance effects.
At the moment the default configuration is set to reduce memory consumption as much as possible so there's not much to do from the user side. (We are now storing MTs on disk, which were the main source of memory consumption.) You should expect a maximum RSS between 1-2 sector sizes, if you experience peaks beyond that range please report an issue (you can check the max RSS with the /usr/bin/time -v command).
Memory Optimized Pedersen Hashing - for consumers of storage-proofs concerned with memory usage, the memory usage of Pedersen hashing can be reduced by lowering the Pederen Hash window-size parameter (i.e. its cache size). Reducing the cache size will reduce memory usage while increasing the runtime per Pedersen hash. The Pedersen Hash window-size can be changed via the setting pedersen_hash_exp_window_size in settings.rs. See the Pedersen cache issue for more benchmarks and expected performance effects.
The following benchmarks were observed when running replication on 1MiB (1024 kibibytes) of data on a new m5a.2xlarge EC2 instance with 32GB of RAM for Pedersen Hash window-sizes of 16 (the current default) and 8 bits:
$ cargo build --bin benchy --release
$ env time -v cargo run --bin benchy --release -- stacked --size=1024
window-size: 16
User time (seconds): 87.82
Maximum resident set size (kbytes): 1712320
window-size: 8
User time (seconds): 128.85
Maximum resident set size (kbytes): 1061564
Note that for a window-size of 16 bits the runtime for replication is 30% faster while the maximum RSS is about 40% higher compared to a window-size of 8 bits.
First, navigate to the rust-fil-proofs directory.
- If you installed
rust-fil-proofsautomatically as a submodule ofgo-filecoin:
> cd <go-filecoin-install-path>/go-filecoin/proofs/rust-fil-proofs
- If you cloned
rust-fil-proofsmanually, it will be wherever you cloned it:
> cd <install-path>/rust-fil-proofs
[Note that the version of rust-fil-proofs included in go-filecoin as a submodule is not always the current head of rust-fil-proofs/master. For documentation corresponding to the latest source, you should clone rust-fil-proofs yourself.]
Now, generate the documentation:
> cargo doc --all --no-deps
View the docs by pointing your browser at: …/rust-fil-proofs/target/doc/proofs/index.html.
The FPS is accessed from go-filecoin via FFI calls to its API, which is the union of the APIs of its constituents:
The Rust source code serves as the source of truth defining the FPS APIs. View the source directly:
Or better, generate the documentation locally (until repository is public). Follow the instructions to generate documentation above. Then navigate to:
-
Sector Base API:
…/rust-fil-proofs/target/doc/sector_base/api/index.html -
Filecoin Proofs API:
…/rust-fil-proofs/target/doc/filecoin_proofs/api/index.html -
Go implementation of filecoin-proofs sectorbuilder API and associated interface structures.
-
Go implementation of filecoin-proofs verifier API and associated interface structures.
See Contributing
The Filecoin Project is dual-licensed under Apache 2.0 and MIT terms:
- Apache License, Version 2.0, (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT license (LICENSE-MIT or http://opensource.org/licenses/MIT)