Squeeze-and-Excitation block (SE-block) was first proposed in the following paper:
https://arxiv.org/pdf/1709.01507v2.pdf
Instead of an equal representation of all channels in a given layer, it suggests developing a weighted representation. The corresponding weights of each channel can be learned in the SE-block. It introduces an addition hyperparameter, r (ratio) to be used in the SE-block. For c number of channels, it attempts to learn a (sigmoidal) vector of size c (a tensor of 1x1xc to be exact) and multiplies it with the current tensor in the given layer.
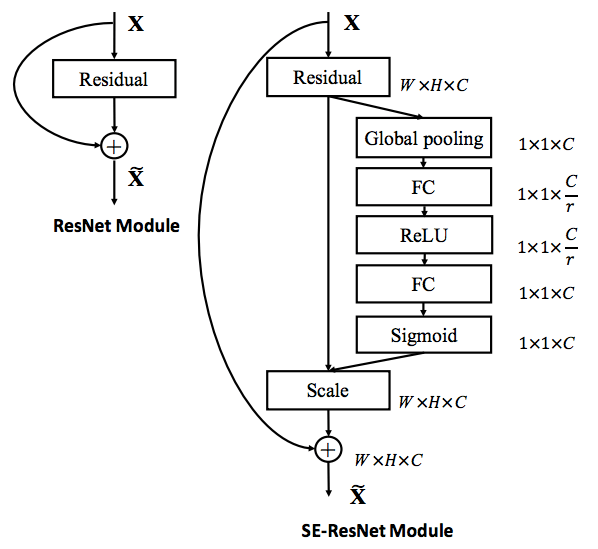
Apart from ResNet, SE-blocks can also be implemented in other popular classification models such as Inception and DenseNet.