{kind=link}
A tiny, efficient fuzzy search that doesn't suck. This is my fuzzy 🐈. There are many like it, but this one is mine.¹
uFuzzy is a fuzzy search library designed to match a relatively short search phrase (needle) against a large list of short-to-medium phrases (haystack). It might be best described as a more forgiving String.includes(). Common applications include list filtering, auto-complete/suggest, and searches for titles, names, descriptions, filenames, and functions.
In uFuzzy's default MultiInsert mode, each match must contain all alpha-numeric characters from the needle in the same sequence;
in SingleError mode, single typos are tolerated in each term (Damerau–Levenshtein distance = 1).
Its .search() API can efficiently match out-of-order terms, supports multiple substring exclusions (e.g. fruit -green -melon), and exact terms with non-alphanum chars (e.g. "C++", "$100", "#hashtag").
When held just right, it can efficiently match against multiple object properties, too.
- Junk-free, high quality results with any dataset. No need to fine-tune indexing options or boosting params to attain some arbitrary relevance score cut-off.
- Precise fuzziness control that follows straightforward rules, without returning unexpected matches.
- Sorting you can reason about and customize using a simple
Array.sort()which gets access to each match's stats/counters. There's no composite, black box "score" to understand. - Concise set of options that don't interact in mysterious ways to drastically alter combined behavior.
- Fast with low resource usage - there's no index to build, so startup is below 1ms with near-zero memory overhead. Searching a three-term phrase in a 162,000 phrase dataset takes 5ms with out-of-order terms.
- Micro, with zero dependencies - currently ~7.5KB min
uFuzzy is optimized for the Latin/Roman alphabet and relies internally on non-unicode regular expressions.
Support for more languages works by augmenting the built-in Latin regexps with additional chars or by using the slower, universal {unicode: true} variant.
A more simple, but less flexible {alpha: "..."} alternative replaces the A-Z and a-z parts of the built-in Latin regexps with chars of your choice (the letter case will be matched automatically during replacement).
The uFuzzy.latinize() util function may be used to strip common accents/diacritics from the haystack and needle prior to searching.
// Latin (default)
let opts = { alpha: "a-z" };
// OR
let opts = {
// case-sensitive regexps
interSplit: "[^A-Za-z\\d']+",
intraSplit: "[a-z][A-Z]",
intraBound: "[A-Za-z]\\d|\\d[A-Za-z]|[a-z][A-Z]",
// case-insensitive regexps
intraChars: "[a-z\\d']",
intraContr: "'[a-z]{1,2}\\b",
};
// Latin + Norwegian
let opts = { alpha: "a-zæøå" };
// OR
let opts = {
interSplit: "[^A-Za-zæøåÆØÅ\\d']+",
intraSplit: "[a-zæøå][A-ZÆØÅ]",
intraBound: "[A-Za-zæøåÆØÅ]\\d|\\d[A-Za-zæøåÆØÅ]|[a-zæøå][A-ZÆØÅ]",
intraChars: "[a-zæøå\\d']",
intraContr: "'[a-zæøå]{1,2}\\b",
};
// Latin + Russian
let opts = { alpha: "a-zа-яё" };
// OR
let opts = {
interSplit: "[^A-Za-zА-ЯЁа-яё\\d']+",
intraSplit: "[a-z][A-Z]|[а-яё][А-ЯЁ]",
intraBound: "[A-Za-zА-ЯЁа-яё]\\d|\\d[A-Za-zА-ЯЁа-яё]|[a-z][A-Z]|[а-яё][А-ЯЁ]",
intraChars: "[a-zа-яё\\d']",
intraContr: "'[a-z]{1,2}\\b",
};
// Unicode / universal (50%-75% slower)
let opts = {
unicode: true,
interSplit: "[^\\p{L}\\d']+",
intraSplit: "\\p{Ll}\\p{Lu}",
intraBound: "\\p{L}\\d|\\d\\p{L}|\\p{Ll}\\p{Lu}",
intraChars: "[\\p{L}\\d']",
intraContr: "'\\p{L}{1,2}\\b",
};All searches are currently case-insensitive; it is not possible to do a case-sensitive search.
NOTE: The testdata.json file is a diverse 162,000 string/phrase dataset 4MB in size, so first load may be slow due to network transfer. Try refreshing once it's been cached by your browser.
First, uFuzzy in isolation to demonstrate its performance.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy&search=super%20ma
Now the same comparison page, booted with fuzzysort, QuickScore, and Fuse.js:
Here is the full library list but with a reduced dataset (just hearthstone_750, urls_and_titles_600) to avoid crashing your browser:
Answers:
- https://news.ycombinator.com/item?id=33035580
- https://old.reddit.com/r/javascript/comments/xtrszc/ufuzzyjs_a_tiny_efficient_fuzzy_search_that/
Else: https://github.com/leeoniya/uFuzzy/issues
npm i @leeoniya/ufuzzy
const uFuzzy = require('@leeoniya/ufuzzy');<script src="./dist/uFuzzy.iife.min.js"></script>let haystack = [
'puzzle',
'Super Awesome Thing (now with stuff!)',
'FileName.js',
'/feeding/the/catPic.jpg',
];
let needle = 'feed cat';
let opts = {};
let uf = new uFuzzy(opts);
// pre-filter
let idxs = uf.filter(haystack, needle);
// idxs can be null when the needle is non-searchable (has no alpha-numeric chars)
if (idxs != null && idxs.length > 0) {
// sort/rank only when <= 1,000 items
let infoThresh = 1e3;
if (idxs.length <= infoThresh) {
let info = uf.info(idxs, haystack, needle);
// order is a double-indirection array (a re-order of the passed-in idxs)
// this allows corresponding info to be grabbed directly by idx, if needed
let order = uf.sort(info, haystack, needle);
// render post-filtered & ordered matches
for (let i = 0; i < order.length; i++) {
// using info.idx here instead of idxs because uf.info() may have
// further reduced the initial idxs based on prefix/suffix rules
console.log(haystack[info.idx[order[i]]]);
}
}
else {
// render pre-filtered but unordered matches
for (let i = 0; i < idxs.length; i++) {
console.log(haystack[idxs[i]]);
}
}
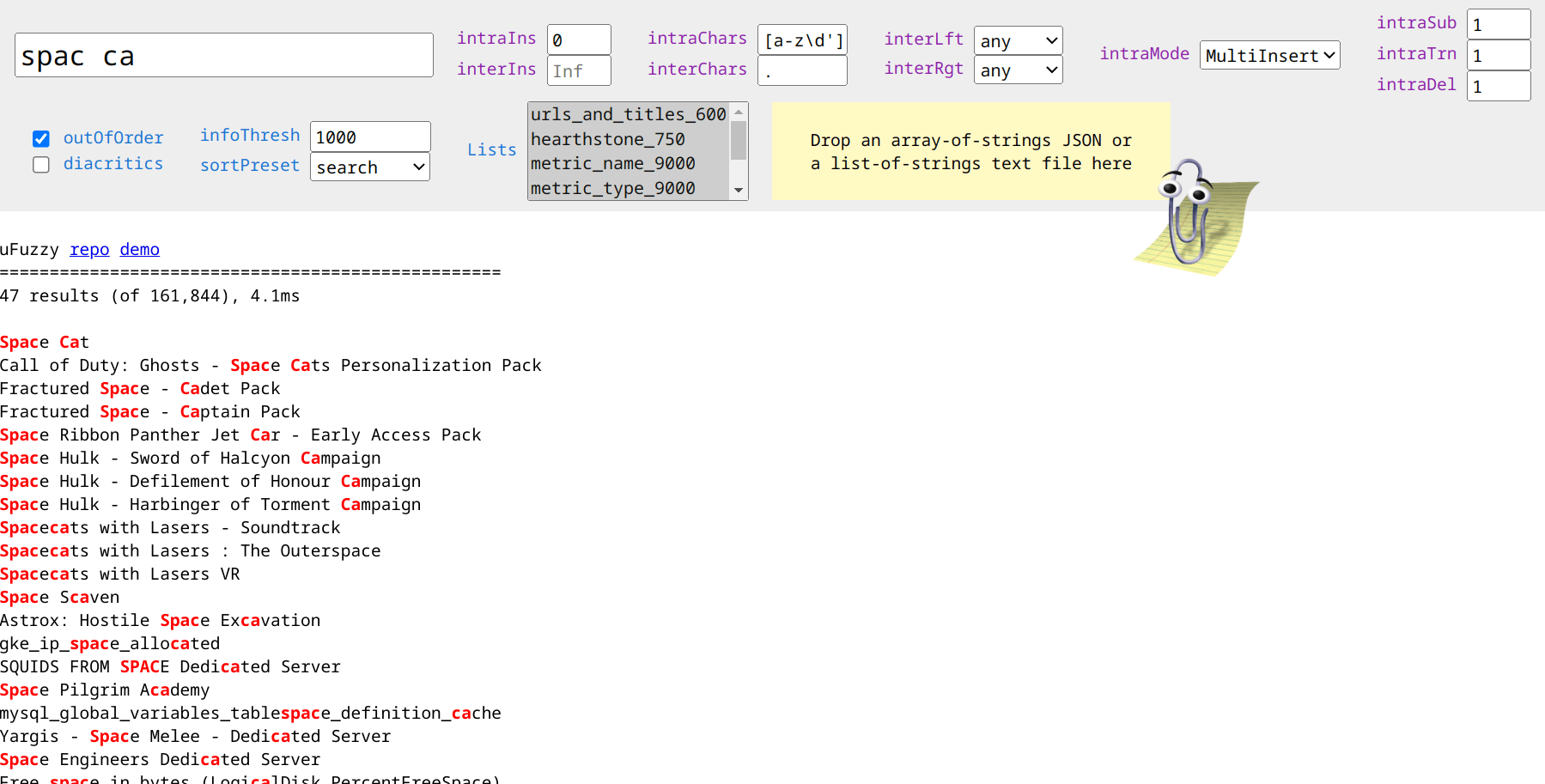
}uFuzzy provides a uf.search(haystack, needle, outOfOrder = 0, infoThresh = 1e3) => [idxs, info, order] wrapper which combines the filter, info, sort steps above.
This method also implements efficient logic for matching search terms out of order and support for multiple substring exclusions, e.g. fruit -green -melon.
Get your ordered matches first:
let haystack = [
'foo',
'bar',
'cowbaz',
];
let needle = 'ba';
let u = new uFuzzy();
let idxs = u.filter(haystack, needle);
let info = u.info(idxs, haystack, needle);
let order = u.sort(info, haystack, needle);Basic innerHTML highlighter (<mark>-wrapped ranges):
let innerHTML = '';
for (let i = 0; i < order.length; i++) {
let infoIdx = order[i];
innerHTML += uFuzzy.highlight(
haystack[info.idx[infoIdx]],
info.ranges[infoIdx],
) + '<br>';
}
console.log(innerHTML);innerHTML highlighter with custom marking function (<b>-wrapped ranges):
let innerHTML = '';
const mark = (part, matched) => matched ? '<b>' + part + '</b>' : part;
for (let i = 0; i < order.length; i++) {
let infoIdx = order[i];
innerHTML += uFuzzy.highlight(
haystack[info.idx[infoIdx]],
info.ranges[infoIdx],
mark,
) + '<br>';
}
console.log(innerHTML);DOM/JSX element highlighter with custom marking and append functions:
let domElems = [];
const mark = (part, matched) => {
let el = matched ? document.createElement('mark') : document.createElement('span');
el.textContent = part;
return el;
};
const append = (accum, part) => { accum.push(part); };
for (let i = 0; i < order.length; i++) {
let infoIdx = order[i];
let matchEl = document.createElement('div');
let parts = uFuzzy.highlight(
haystack[info.idx[infoIdx]],
info.ranges[infoIdx],
mark,
[],
append,
);
matchEl.append(...parts);
domElems.push(matchEl);
}
document.getElementById('matches').append(...domElems);uFuzzy has two operational modes which differ in matching strategy:
- intraMode: 0 (default) requires all alpha-numeric characters in each search term to exist in the same sequence in all matches. For example, when searching for "cat", this mode is capable of matching the strings below. What is actually matched will depend on additonal fuzziness settings.
- cat
- coat
- scratch
- cantina
- tractors are late
- intraMode: 1 allows for a single error in each term of the search phrase, where an error is one of: substitution (replacement), transposition (swap), insertion (addition), or deletion (omission). The search strings with errors below can return matches containing "example". What is actually matched will depend on additonal fuzziness settings. In contrast to the previous mode, searching for "example" will never match "extra maple".
example- exactexamplle- single insertion (addition)exemple- single substitution (replacement)exmaple- single transposition (swap)exmple- single deletion (omission)xamp- partialxmap- partial with transposition
There are 3 phases to a search:
- Filter filters the full
haystackwith a fast RegExp compiled from yourneedlewithout doing any extra ops. It returns an array of matched indices in original order. - Info collects more detailed stats about the filtered matches, such as start offsets, fuzz level, prefix/suffix counters, etc. It also gathers substring match positions for range highlighting. Finally, it filters out any matches that don't conform to the desired prefix/suffix rules. To do all this it re-compiles the
needleinto two more-expensive RegExps that can partition each match. Therefore, it should be run on a reduced subset of the haystack, usually returned by the Filter phase. The uFuzzy demo is gated at <= 1,000 filtered items, before moving ahead with this phase. - Sort does an
Array.sort()to determine final result order, utilizing theinfoobject returned from the previous phase. A custom sort function can be provided via a uFuzzy option:{sort: (info, haystack, needle) => idxsOrder}.
A liberally-commented 200 LoC uFuzzy.d.ts file.
Options with an inter prefix apply to allowances in between search terms, while those with an intra prefix apply to allowances within each search term.
| Option | Description | Default | Examples |
|---|---|---|---|
intraMode |
How term matching should be performed | 0 |
0 MultiInsert1 SingleErrorSee How It Works |
intraIns |
Max number of extra chars allowed between each char within a term |
Matches the value of intraMode (either 0 or 1) |
Searching "cat"...0 can match: cat, scat, catch, vacate1 also matches: cart, chapter, outcast |
interIns |
Max number of extra chars allowed between terms | Infinity |
Searching "where is"...Infinity can match: where is, where have blah wisdom5 cannot match: where have blah wisdom |
intraSubintraTrnintraDel |
For intraMode: 1 only,Error types to tolerate within terms |
Matches the value of intraMode (either 0 or 1) |
0 No1 Yes |
intraChars |
Partial regexp for allowed insert chars between each char within a term |
[a-z\d'] |
[a-z\d] matches only alpha-numeric (case-insensitive)[\w-] would match alpha-numeric, undercore, and hyphen |
intraFilt |
Callback for excluding results based on term & match | (term, match, index) => true |
Do your own thing, maybe...
- Length diff threshold - Levenshtein distance - Term offset or content |
interChars |
Partial regexp for allowed chars between terms | . |
. matches all chars[^a-z\d] would only match whitespace and punctuation |
interLft |
Determines allowable term left boundary | 0 |
Searching "mania"...0 any - anywhere: romanian1 loose - whitespace, punctuation, alpha-num, case-change transitions: TrackMania, maniac2 strict - whitespace, punctuation: maniacally |
interRgt |
Determines allowable term right boundary | 0 |
Searching "mania"...0 any - anywhere: romanian1 loose - whitespace, punctuation, alpha-num, case-change transitions: ManiaStar2 strict - whitespace, punctuation: mania_foo |
sort |
Custom result sorting function | (info, haystack, needle) => idxsOrder |
Default: Search sort, prioritizes full term matches and char density Demo: Typeahead sort, prioritizes start offset and match length |
This assessment is extremely narrow and, of course, biased towards my use cases, text corpus, and my complete expertise in operating my own library. It is highly probable that I'm not taking full advantage of some feature in other libraries that may significantly improve outcomes along some axis; I welcome improvement PRs from anyone with deeper library knowledge than afforded by my hasty 10min skim over any "Basic usage" example and README doc.
Can-of-worms #1.
Before we discuss performance let's talk about search quality, because speed is irrelevant when your results are a strange medly of "Oh yeah!" and "WTF?".
Search quality is very subjective. What constitutes a good top match in a "typeahead / auto-suggest" case can be a poor match in a "search / find-all" scenario. Some solutions optimize for the latter, some for the former. It's common to find knobs that skew the results in either direction, but these are often by-feel and imperfect, being little more than a proxy to producing a single, composite match "score".
Let's take a look at some matches produced by the most popular fuzzy search library, Fuse.js and some others for which match highlighting is implemented in the demo.
Searching for the partial term "twili", we see these results appearing above numerous obvious "twilight" results:
- twirling
- The total number of received alerts that were invalid.
- Tom Clancy's Ghost Recon Wildlands - ASIA Pre-order Standard Uplay Activation
- theHunter™: Call of the Wild - Bearclaw Lite CB-60
Not only are these poor matches in isolation, but they actually rank higher than literal substrings.
Finishing the search term to "twilight", still scores bizzare results higher:
- Magic: The Gathering - Duels of the Planeswalkers Wings of Light Unlock
- The Wild Eight
Some engines do better with partial prefix matches, at the expense of higher startup/indexing cost:
Here, match-sorter returns 1,384 results, but only the first 40 are relevant. How do we know where the cut-off is?
Can-of-worms #2.
All benchmarks suck, but this one might suck more than others.
- I've tried to follow any "best performance" advice when I could find it in each library's docs, but it's a certainty that some stones were left unturned when implementing ~20 different search engines.
- Despite my best efforts, result quality is still extremely variable between libraries, and even between search terms. In some cases, results are very poor but the library is very fast; in other cases, the results are better, but the library is quite slow. What use is extreme speed when the search quality is sub-par? This is a subjective, nuanced topic that will surely affect how you interpret these numbers. I consider uFuzzy's search quality second-to-none, so my view of most faster libraries is typically one of quality trade-offs I'm happy not to have made. I encourage you to evaluate the results for all benched search phrases manually to decide this for yourself.
- Many fulltext & document-search libraries compared here are designed to work best with exact terms rather than partial matches (which this benchmark is skewed towards).
Still, something is better than a hand-wavy YMMV/do-it-yourself dismissal and certainly better than nothing.
Environment
| Date | 2023-10 |
|---|---|
| Hardware |
CPU: Ryzen 7 PRO 5850U (1.9GHz, 7nm, 15W TDP) RAM: 48GB SSD: Samsung SSD 980 PRO 1TB (NVMe) |
| OS | EndeavourOS (Arch Linux) v6.5.4-arch2-1 x86_64 |
| Chrome | v117.0.5938.132 |
- Each benchmark can be run by changing the
libsparameter to the desired library name: https://leeoniya.github.io/uFuzzy/demos/compare.html?bench&libs=uFuzzy - Results output is suppressed in
benchmode to avoid benchmarking the DOM. - Measurements are taken in the Performance secrion of Chrome's DevTools by recording several reloads of the bench page, with forced garbage collection in between. The middle/typical run is used to collect numbers.
- The search corpus is 162,000 words and phrases, loaded from a 4MB testdata.json.
- The benchmark types and then deletes, character-by-character (every 20ms) the following search terms, triggering a search for each keypress:
test,chest,super ma,mania,puzz,prom rem stor,twil.
To evaluate the results for each library, or to compare several, simply visit the same page with more libs and without bench: https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=super%20ma.

There are several metrics evaluated:
- Init time - how long it takes to load the library and build any required index to perform searching.
- Bench runtime - how long it takes to execute all searches.
- Memory required - peak JS heap size used during the bench as well as how much is still retained after a forced garbage collection at the end.
- GC cost - how much time is needed to collect garbage at the end (main thread jank)
| Lib | Stars | Size (min) | Init | Search (x 86) |
Heap (peak) | Retained | GC |
|---|---|---|---|---|---|---|---|
| uFuzzy (try) | ★ 2.3k | 7.6KB | 0.5ms | 434ms | 28.4MB | 7.4MB | 18ms |
|
uFuzzy
(try) (external prefix caching) |
210ms | 27.8MB | 7.4MB | 18ms | |||
|
uFuzzy
(try) (outOfOrder, fuzzier) |
545ms | 29.5MB | 7.4MB | 18ms | |||
|
uFuzzy
(try) (outOfOrder, fuzzier, SingleError) |
508ms | 30.0MB | 7.4MB | 18ms | |||
| ------- | |||||||
| Fuse.js (try) | ★ 16.6k | 24.2KB | 31ms | 33875ms | 245MB | 13.9MB | 25ms |
| FlexSearch (Light) (try) | ★ 10.7k | 6.2KB | 3210ms | 83ms | 670MB | 316MB | 553ms |
| Lunr.js (try) | ★ 8.7k | 29.4KB | 1704ms | 996ms | 380MB | 123MB | 166ms |
| Orama (formerly Lyra) (try) | ★ 6.4k | 41.5KB | 2650ms | 225ms | 313MB | 192MB | 180ms |
| MiniSearch (try) | ★ 3.4k | 29.1KB | 504ms | 1453ms | 438MB | 67MB | 105ms |
| match-sorter (try) | ★ 3.4k | 7.3KB | 0.1ms | 6245ms | 71MB | 7.3MB | 12ms |
| fuzzysort (try) | ★ 3.4k | 6.2KB | 50ms | 1321ms | 175MB | 84MB | 63ms |
| Wade (try) | ★ 3k | 4KB | 781ms | 194ms | 438MB | 42MB | 130ms |
| fuzzysearch (try) | ★ 2.7k | 0.2KB | 0.1ms | 529ms | 26.2MB | 7.3MB | 18ms |
| js-search (try) | ★ 2.1k | 17.1KB | 5620ms | 1190ms | 1740MB | 734MB | 2600ms |
| Elasticlunr.js (try) | ★ 2k | 18.1KB | 933ms | 1330ms | 196MB | 70MB | 135ms |
| Fuzzyset (try) | ★ 1.4k | 2.8KB | 2962ms | 606ms | 654MB | 238MB | 239ms |
| search-index (try) | ★ 1.4k | 168KB | RangeError: Maximum call stack size exceeded | ||||
| sifter.js (try) | ★ 1.1k | 7.5KB | 3ms | 1070ms | 46.2MB | 10.6MB | 18ms |
| fzf-for-js (try) | ★ 831 | 15.4KB | 50ms | 6290ms | 153MB | 25MB | 18ms |
| fuzzy (try) | ★ 819 | 1.4KB | 0.1ms | 5427ms | 72MB | 7.3MB | 14ms |
| fast-fuzzy (try) | ★ 346 | 18.2KB | 790ms | 19266ms | 550MB | 165MB | 140ms |
| ItemsJS (try) | ★ 305 | 109KB | 2400ms | 11304ms | 320MB | 88MB | 163ms |
| LiquidMetal (try) | ★ 292 | 4.2KB | (crash) | ||||
| FuzzySearch (try) | ★ 209 | 3.5KB | 2ms | 3948ms | 84MB | 10.5MB | 18ms |
| FuzzySearch2 (try) | ★ 186 | 19.4KB | 93ms | 4189ms | 117MB | 40.3MB | 40ms |
| QuickScore (try) | ★ 153 | 9.5KB | 10ms | 6915ms | 133MB | 12.1MB | 18ms |
| ndx (try) | ★ 142 | 2.9KB | 300ms | 581ms | 308MB | 137MB | 262ms |
| fzy (try) | ★ 133 | 1.5KB | 0.1ms | 3932ms | 34MB | 7.3MB | 10ms |
| fuzzy-tools (try) | ★ 13 | 3KB | 0.1ms | 5138ms | 164MB | 7.5MB | 18ms |
| fuzzyMatch (try) | ★ 0 | 1KB | 0.1ms | 2415ms | 83.5MB | 7.3MB | 13ms |