[AZURE.SELECTOR]
The Get started with Azure Data Factory tutorial shows you how to create and monitor an Azure data factory using the Azure Portal. In this tutorial, you will create and monitor an Azure data factory by using Azure PowerShell cmdlets. The pipeline in the data factory you create in this tutorial uses a Copy Activity to copy data from an Azure blob to an Azure SQL database.
The Copy Activity performs the data movement in Azure Data Factory and the activity is powered by a globally available service that can copy data between various data stores in a secure, reliable, and scalable way. See Data Movement Activities article for details about the Copy Activity.
[AZURE.IMPORTANT] Please go through the Tutorial Overview article and complete the pre-requisite steps before performing this tutorial.
This article does not cover all the Data Factory cmdlets. See Data Factory Cmdlet Reference for comprehensive documentation on Data Factory cmdlets.
##Prerequisites Apart from prerequisites listed in the Tutorial Overview topic, you need to install the following:
- Azure PowerShell. Follow instructions in How to install and configure Azure PowerShell article to install Azure PowerShell on your computer.
If you are using Azure PowerShell of version < 1.0, You will need to use cmdlets that are documented here. You also will need to run the following commands before using the Data Factory cmdlets:
- Start Azure PowerShell and run the following commands. Keep Azure PowerShell open until the end of this tutorial. If you close and reopen, you need to run these commands again.
- Run Add-AzureAccount and enter the user name and password that you use to sign in to the Azure Portal.
- Run Get-AzureSubscription to view all the subscriptions for this account.
- Run Select-AzureSubscription to select the subscription that you want to work with. This subscription should be the same as the one you used in the Azure portal.
- Switch to AzureResourceManager mode as the Azure Data Factory cmdlets are available in this mode: Switch-AzureMode AzureResourceManager.
##In this tutorial The following table lists the steps you will perform as part of the tutorial and their descriptions.
| Step | Description |
|---|---|
| Step 1: Create an Azure Data Factory | In this step, you will create an Azure data factory named ADFTutorialDataFactoryPSH. |
| Step 2: Create linked services | In this step, you will create two linked services: StorageLinkedService and AzureSqlLinkedService. The StorageLinkedService links an Azure storage and AzureSqlLinkedService links an Azure SQL database to the ADFTutorialDataFactoryPSH. |
| Step 3: Create input and output datasets | In this step, you will define two data sets (EmpTableFromBlob and EmpSQLTable) that are used as input and output tables for the Copy Activity in the ADFTutorialPipeline that you will create in the next step. |
| Step 4: Create and run a pipeline | In this step, you will create a pipeline named ADFTutorialPipeline in the data factory: ADFTutorialDataFactoryPSH. . The pipeline will have a Copy Activity that copies data from an Azure blob to an output Azure database table. |
| Step 5: Monitor data sets and pipeline | In this step, you will monitor the datasets and the pipeline using Azure PowerShell in this step. |
In this step, you use the Azure PowerShell to create an Azure data factory named ADFTutorialDataFactoryPSH.
-
Start Azure PowerShell and run the following command. Keep Azure PowerShell open until the end of this tutorial. If you close and reopen, you need to run these commands again.
- Run Login-AzureRmAccount and enter the user name and password that you use to sign in to the Azure Portal.
- Run Get-AzureSubscription to view all the subscriptions for this account.
- Run Select-AzureSubscription to select the subscription that you want to work with. This subscription should be the same as the one you used in the Azure portal.
-
Create an Azure resource group named: ADFTutorialResourceGroup by running the following command.
New-AzureRmResourceGroup -Name ADFTutorialResourceGroup -Location "West US"Some of the steps in this tutorial assume that you use the resource group named ADFTutorialResourceGroup. If you use a different resource group, you will need to use it in place of ADFTutorialResourceGroup in this tutorial.
-
Run the New-AzureRmDataFactory cmdlet to create a data factory named: ADFTutorialDataFactoryPSH.
New-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name ADFTutorialDataFactoryPSH –Location "West US"The name of the Azure data factory must be globally unique. If you receive the error: Data factory name “ADFTutorialDataFactoryPSH” is not available, change the name (for example, yournameADFTutorialDataFactoryPSH). Use this name in place of ADFTutorialFactoryPSH while performing steps in this tutorial. See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
[AZURE.NOTE] The name of the data factory may be registered as a DNS name in the future and hence become publically visible.
Linked services link data stores or compute services to an Azure data factory. A data store can be an Azure Storage, Azure SQL Database or an on-premises SQL Server database that contains input data or stores output data for a Data Factory pipeline. A compute service is the service that processes input data and produces output data.
In this step, you will create two linked services: StorageLinkedService and AzureSqlLinkedService. StorageLinkedService linked service links an Azure Storage Account and AzureSqlLinkedService links an Azure SQL database to the data factory: ADFTutorialDataFactoryPSH. You will create a pipeline later in this tutorial that copies data from a blob container in StorageLinkedService to a SQL table in AzureSqlLinkedService.
-
Create a JSON file named StorageLinkedService.json in the C:\ADFGetStartedPSH with the following content. Create the folder ADFGetStartedPSH if it does not already exist.
{ "name": "StorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>" } } }Replace accountname with the name of your storage account and accountkey with the key for your Azure storage account.
-
In the Azure PowerShell, switch to the ADFGetStartedPSH folder.
-
You can use the New-AzureRmDataFactoryLinkedService cmdlet to create a linked service. This cmdlet and other Data Factory cmdlets you use in this tutorial require you to pass values for the ResourceGroupName and DataFactoryName parameters. Alternatively, you can use Get-AzureRmDataFactory to get a DataFactory object and pass the object without typing ResourceGroupName and DataFactoryName each time you run a cmdlet. Run the following command to assign the output of the Get-AzureRmDataFactory cmdlet to a variable: $df.
$df=Get-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name ADFTutorialDataFactoryPSH -
Now, run the New-AzureRmDataFactoryLinkedService cmdlet to create the linked service: StorageLinkedService.
New-AzureRmDataFactoryLinkedService $df -File .\StorageLinkedService.jsonIf you hadn't run the Get-AzureRmDataFactory cmdlet and assigned the output to $df variable, you would have to specify values for the ResourceGroupName and DataFactoryName parameters as follows.
New-AzureRmDataFactoryLinkedService -ResourceGroupName ADFTutorialResourceGroup -DataFactoryName ADFTutorialDataFactoryPSH -File .\StorageLinkedService.jsonIf you close the Azure PowerShell in the middle of the tutorial, you will have run the Get-AzureRmDataFactory cmdlet next time you launch Azure PowerShell to complete the tutorial.
-
Create a JSON file named AzureSqlLinkedService.json with the following content.
{ "name": "AzureSqlLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<server>.database.windows.net,1433;Database=<databasename>;User ID=user@server;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30" } } }Replace servername, databasename, username@servername, and password with names of your Azure SQL server, database, user account, and password.
-
Run the following command to create a linked service.
New-AzureRmDataFactoryLinkedService $df -File .\AzureSqlLinkedService.jsonConfirm that the Allow access to Azure services setting is turned ON for your Azure SQL server. To verify and turn it on, do the following:
- Click BROWSE hub on the left and click SQL servers.
- Select your server, and click SETTINGS on the SQL SERVER blade.
- In the SETTINGS blade, click Firewall.
- In the Firewalll settings blade, click ON for Allow access to Azure services.
- Click ACTIVE hub on the left to switch to the Data Factory blade you were on.
In the previous step, you created linked services StorageLinkedService and AzureSqlLinkedService to link an Azure Storage account and Azure SQL database to the data factory: ADFTutorialDataFactoryPSH. In this step, you will create datasets that represent the input and output data for the Copy Activity in the pipeline you will be creating in the next step.
A table is a rectangular dataset and it is the only type of dataset that is supported at this time. The input table in this tutorial refers to a blob container in the Azure Storage that StorageLinkedService points to and the output table refers to a SQL table in the Azure SQL database that AzureSqlLinkedService points to.
Skip this step if you have gone through the tutorial from Get started with Azure Data Factory article.
You need to perform the following steps to prepare the Azure blob storage and Azure SQL database for this tutorial.
- Create a blob container named adftutorial in the Azure blob storage that StorageLinkedService points to.
- Create and upload a text file, emp.txt, as a blob to the adftutorial container.
- Create a table named emp in the Azure SQL Database in the Azure SQL database that AzureSqlLinkedService points to.
-
Launch Notepad, paste the following text, and save it as emp.txt to C:\ADFGetStartedPSH folder on your hard drive.
John, Doe Jane, Doe -
Use tools such as Azure Storage Explorer to create the adftutorial container and to upload the emp.txt file to the container.
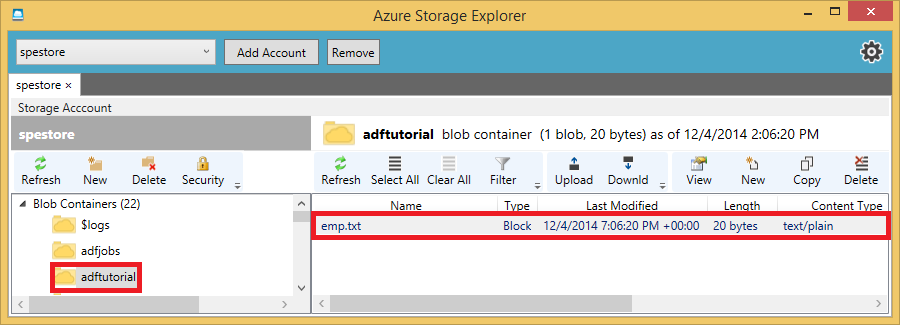
-
Use the following SQL script to create the emp table in your Azure SQL Database.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50), ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);If you have SQL Server 2014 installed on your computer: follow instructions from Step 2: Connect to SQL Database of the Managing Azure SQL Database using SQL Server Management Studio article to connect to your Azure SQL server and run the SQL script.
If you have Visual Studio 2013 installed on your computer: in the Azure Portal (http://portal.azure.com), click BROWSE hub on the left, click SQL servers, select your database, and click Open in Visual Studio button on toolbar to connect to your Azure SQL server and run the script. If your client is not allowed to access the Azure SQL server, you will need to configure firewall for your Azure SQL server to allow access from your machine (IP Address). See the article above for steps to configure the firewall for your Azure SQL server.

A table is a rectangular dataset and has a schema. In this step, you will create a table named EmpBlobTable that points to a blob container in the Azure Storage represented by the StorageLinkedService linked service. This blob container (adftutorial) contains the input data in the file: emp.txt.
-
Create a JSON file named EmpBlobTable.json in the C:\ADFGetStartedPSH folder with the following content:
{ "name": "EmpTableFromBlob", "properties": { "structure": [ { "name": "FirstName", "type": "String" }, { "name": "LastName", "type": "String" } ], "type": "AzureBlob", "linkedServiceName": "StorageLinkedService", "typeProperties": { "fileName": "emp.txt", "folderPath": "adftutorial/", "format": { "type": "TextFormat", "columnDelimiter": "," } }, "external": true, "availability": { "frequency": "Hour", "interval": 1 } } }Note the following:
- dataset type is set to AzureBlob.
- linkedServiceName is set to StorageLinkedService.
- folderPath is set to the adftutorial container.
- fileName is set to emp.txt. If you do not specify the name of the blob, data from all blobs in the container is considered as an input data.
- format type is set to TextFormat
- There are two fields in the text file – FirstName and LastName – separated by a comma character (columnDelimiter)
- The availability is set to hourly (frequency is set to hour and interval is set to 1 ), so the Data Factory service will look for input data every hour in the root folder in the blob container (adftutorial) you specified.
if you don't specify a fileName for an input table, all files/blobs from the input folder (folderPath) are considered as inputs. If you specify a fileName in the JSON, only the specified file/blob is considered asn input. See the sample files in the tutorial for examples.
If you do not specify a fileName for an output table, the generated files in the folderPath are named in the following format: Data.<Guid>.txt (example: Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.).
To set folderPath and fileName dynamically based on the SliceStart time, use the partitionedBy property. In the following example, folderPath uses Year, Month, and Day from from the SliceStart (start time of the slice being processed) and fileName uses Hour from the SliceStart. For example, if a slice is being produced for 2014-10-20T08:00:00, the folderName is set to wikidatagateway/wikisampledataout/2014/10/20 and the fileName is set to 08.csv.
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}", "fileName": "{Hour}.csv", "partitionedBy": [ { "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } }, { "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } }, { "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } }, { "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } } ],See JSON Scripting Reference for details about JSON properties.
-
Run the following command to create the Data Factory dataset.
New-AzureRmDataFactoryDataset $df -File .\EmpBlobTable.json
In this part of the step, you will create an output table named EmpSQLTable that points to a SQL table (emp) in the Azure SQL database that is represented by the AzureSqlLinkedService linked service. The pipeline copies data from the input blob to the emp table.
-
Create a JSON file named EmpSQLTable.json in the C:\ADFGetStartedPSH folder with the following content.
{ "name": "EmpSQLTable", "properties": { "structure": [ { "name": "FirstName", "type": "String" }, { "name": "LastName", "type": "String" } ], "type": "AzureSqlTable", "linkedServiceName": "AzureSqlLinkedService", "typeProperties": { "tableName": "emp" }, "availability": { "frequency": "Hour", "interval": 1 } } }Note the following:
- dataset type is set to AzureSqlTable.
- linkedServiceName is set to AzureSqlLinkedService.
- tablename is set to emp.
- There are three columns – ID, FirstName, and LastName – in the emp table in the database, but ID is an identity column, so you need to specify only FirstName and LastName here.
- The availability is set to hourly (frequency set to hour and interval set to 1). The Data Factory service will generate an output data slice every hour in the emp table in the Azure SQL database.
-
Run the following command to create the Data Factory dataset.
New-AzureRmDataFactoryDataset $df -File .\EmpSQLTable.json
In this step, you create a pipeline with a Copy Activity that uses EmpTableFromBlob as input and EmpSQLTable as output.
-
Create a JSON file named ADFTutorialPipeline.json in the C:\ADFGetStartedPSH folder with the following content:
{ "name": "ADFTutorialPipeline", "properties": { "description": "Copy data from a blob to Azure SQL table", "activities": [ { "name": "CopyFromBlobToSQL", "description": "Push Regional Effectiveness Campaign data to Azure SQL database", "type": "Copy", "inputs": [ { "name": "EmpTableFromBlob" } ], "outputs": [ { "name": "EmpSQLTable" } ], "typeProperties": { "source": { "type": "BlobSource" }, "sink": { "type": "SqlSink" } }, "Policy": { "concurrency": 1, "executionPriorityOrder": "NewestFirst", "style": "StartOfInterval", "retry": 0, "timeout": "01:00:00" } } ], "start": "2015-12-09T00:00:00Z", "end": "2015-12-10T00:00:00Z", "isPaused": false } }Note the following:
- In the activities section, there is only one activity whose type is set to Copy.
- Input for the activity is set to EmpTableFromBlob and output for the activity is set to EmpSQLTable.
- In the transformation section, BlobSource is specified as the source type and SqlSink is specified as the sink type.
Replace the value of the start property with the current day and end value with the next day. Both start and end datetimes must be in ISO format. For example: 2014-10-14T16:32:41Z. The end time is optional, but we will use it in this tutorial.
If you do not specify value for the end property, it is calculated as "start + 48 hours". To run the pipeline indefinitely, specify 9/9/9999 as the value for the end property.
In the example above, there will be 24 data slices as each data slice is produced hourly.
See JSON Scripting Reference for details about JSON properties.
-
Run the following command to create the Data Factory table.
New-AzureRmDataFactoryPipeline $df -File .\ADFTutorialPipeline.json
Congratulations! You have successfully created an Azure data factory, linked services, tables, and a pipeline and scheduled the pipeline.
In this step, you will use the Azure PowerShell to monitor what’s going on in an Azure data factory.
-
Run Get-AzureRmDataFactory and assign the output to a variable $df.
$df=Get-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name ADFTutorialDataFactoryPSH -
Run Get-AzureRmDataFactorySlice to get details about all slices of the EmpSQLTable, which is the output table of the pipeline.
Get-AzureRmDataFactorySlice $df -DatasetName EmpSQLTable -StartDateTime 2015-03-03T00:00:00Replace year, month, and date part of the StartDateTime parameter with the current year, month, and date. This should match the Start value in the pipeline JSON.
You should see 24 slices, one for each hour from 12 AM of the current day to 12 AM of the next day.
First slice:
ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : ADFTutorialDataFactoryPSH TableName : EmpSQLTable Start : 3/3/2015 12:00:00 AM End : 3/3/2015 1:00:00 AM RetryCount : 0 Status : Waiting LatencyStatus : LongRetryCount : 0Last slice:
ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : ADFTutorialDataFactoryPSH TableName : EmpSQLTable Start : 3/4/2015 11:00:00 PM End : 3/4/2015 12:00:00 AM RetryCount : 0 Status : Waiting LatencyStatus : LongRetryCount : 0 -
Run Get-AzureRmDataFactoryRun to get the details of activity runs for a specific slice. Change the value of the StartDateTime parameter to match the Start time of the slice from the output above. The value of the StartDateTime must be in ISO format. For example: 2014-03-03T22:00:00Z.
Get-AzureRmDataFactoryRun $df -DatasetName EmpSQLTable -StartDateTime 2015-03-03T22:00:00You should see output similar to the following:
Id : 3404c187-c889-4f88-933b-2a2f5cd84e90_635614488000000000_635614524000000000_EmpSQLTable ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : ADFTutorialDataFactoryPSH TableName : EmpSQLTable ProcessingStartTime : 3/3/2015 11:03:28 PM ProcessingEndTime : 3/3/2015 11:04:36 PM PercentComplete : 100 DataSliceStart : 3/8/2015 10:00:00 PM DataSliceEnd : 3/8/2015 11:00:00 PM Status : Succeeded Timestamp : 3/8/2015 11:03:28 PM RetryAttempt : 0 Properties : {} ErrorMessage : ActivityName : CopyFromBlobToSQL PipelineName : ADFTutorialPipeline Type : Copy
See Data Factory Cmdlet Reference for comprehensive documentation on Data Factory cmdlets.
See Data Movement Activities article for detailed information about the Copy Activity in Azure Data Factory.