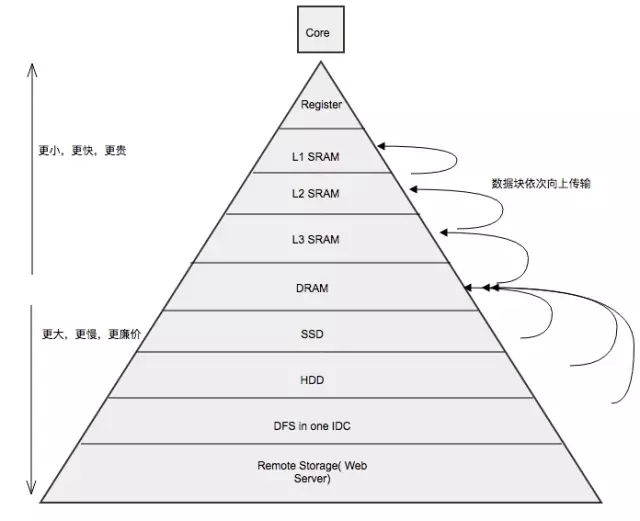
存储器山是 Randal Bryant 在《深入理解计算机系统》一书中提出的概念。
基于成本、效率**的考量,计算机存储器被设计成多级金字塔结构,塔顶是速度最快、成本最高的 CPU 内部的寄存器(一般几 KB)与高速缓存,塔底是成本最低、速度最慢的广域网云存储(如百度云免费 2T )
存储器山的指导意义在于揭示了良好设计程序的必要条件是需要有优秀的局部性:
时间局部性:相同时间内,访问同一地址次数越多,则时间局部性表现越佳;
空间局部性:下一次访问的存储器地址与上一次的访问过的存储器地址位置邻近
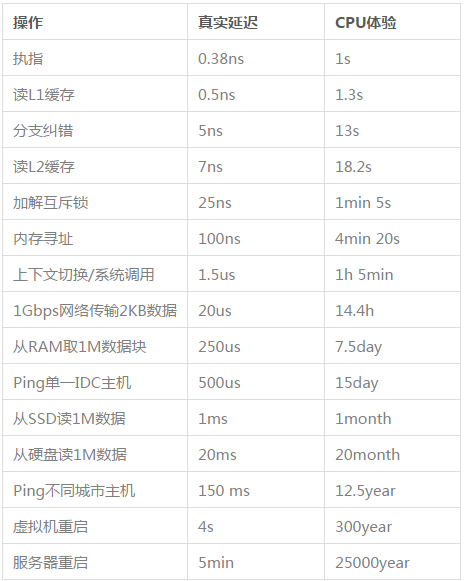
我们将一个普通的 2.6GHz 的 CPU 的延迟时间放大到人能体验的尺度上(数据来自微信公众号 驹说码事):在存储器顶层执行单条寄存器指令的时间为1秒钟;从第五层磁盘读 1MB 数据却需要一年半;ping 不同的城域网主机,网络包需要走 12.5 年。
如果程序发送了一个 HTTP 包后便阻塞在同步等待响应的过程上,计算机不得不傻等 12 年后的那个响应再处理别的事情,低下的硬件利用率必然导致低下的程序效率。
For now let's think of concurrency as the perception of having tasks that run at the same time, while true parallelism as tasks that literally run at the same time.
Parallelism is a subset of concurrency.
_

The central processing unit (CPU) in your computer does the hard work of running programs. It is made of several parts, the main one being the so-called core: that's where computations are actually performed. A core is capable of running only one operation at a time.
This is of course a major drawback. For this reason operating systems have developed advanced techniques to give the user the ability to running multiple processes (or threads) at once, especially on graphical environments, even on a single core machine. The most important one is called preemptive multitasking, where preemption is the ability of interrupting a task, switching to another one and then resuming the first task at a later time.
So if your CPU has only one core, part of a operating system's job is to spread that single core computing power across multiple processes or threads, which are executed one after the other in a loop. This operation gives you the illusion of having more than one program running in parallel, or a single program doing multiple things at the same time (if multithreaded). Concurrency is met, but true parallelism — the ability to run processes simultaneously — is still missing.
Today modern CPUs have more than one core under the hood, where each one performs an independent operation at a time. This means that with two or more cores true parallelism is possible. For example, my Intel Core i7 has four cores: it can run four different processes or threads at the same time, simultaneously.
Operating systems are able to detect the number of CPU cores and assign processes or threads to each one of them. A thread may be allocated to whatever core the operating system likes, and this kind of scheduling is completely transparent for the program being run. Additionally, preemptive multitasking might kick in in case all cores are busy. This gives you the ability to run more processes and threads than the actual number or cores available in your machine.
True parallelism on a single-core machine is impossible to achieve. Nevertheless it still makes sense to write a multithreaded program, if your application can benefit from it. When a process employs multiple threads, preemptive multitasking can keep the app running even if one of those threads performs a slow or blocking task.
Say for example you are working on a desktop app that reads some data from a very slow disk. If you write the program with just one thread, the whole app would freeze until the disk operation is finished: the CPU power assigned to the only thread is wasted while waiting for the disk to wake up. Of course the operating system is running many other processes besides this one, but your specific application will not be making any progress.
Let's rethink your app in a multithreaded way. Thread A is responsible for the disk access, while thread B takes care of the main interface. If thread A gets stuck waiting because the device is slow, thread B can still run the main interface, keeping your program responsive. This is possible because, having two threads, the operating system can switch the CPU resources between them without getting stuck on the slower one.
The Thread Analyzer detects data-races that occur during the execution of a multi-threaded process. A data race occurs when:
- two or more threads in a single process access the same memory location concurrently, and
- at least one of the accesses is for writing, and
- the threads are not using any exclusive locks to control their accesses to that memory.
When these three conditions hold, the order of accesses is non-deterministic, and the computation may give different results from run to run depending on that order. Some data-races may be benign (for example, when the memory access is used for a busy-wait), but many data-races are bugs in the program.
CPU is the heart and/or the brain of a computer. It executes the instructions that are provided to them. Its main job is to perform arithmetic and logical operations and orchestrate the instructions together.
- Control unit — CU
- Arithmetic and logical unit — ALU
Control unit CU is the part of CPU that helps orchestrate the execution of instructions. It tells what to do. According to the instruction, it helps activate the wires connecting the CPU to different other parts of the computer including the ALU. The control unit is the first component of the CPU to receive the instruction for processing.
There are two types of control unit:
- hardwired control units.
- micro programmable (microprogrammed) control units.
Arithmetic and logical unit ALU as the name suggests does all the arithmetic and logical computations. ALU performs operations like addition, subtraction. ALU consists of logic circuitry or logic gates that perform these operations.
The main job of CPU is to execute the instructions provided to it. To process these instructions most of the time, it needs data. Some data are intermediate data, some of them are inputs and other is the output. These data along with the instructions are stored in the following storage:
A Register is a small set of places where the data can be stored. A register is a combination of latches. **Latches also known as flip-flops **are combinations of logic gates which stores 1 bit of information.
CPU has registers to store the data of output. Sending to main memory(RAM) would be slow as it is the intermediate data. This data is sent to other registers which are connected by a BUS. A register can store instruction, output data, storage address or any kind of data.
Ram is a collection of register arranged and compact together in an optimized way so that it can store a higher number of data. RAM(Random Access Memory) is volatile and it’s data gets lost when we turn off the power. As RAM is a collection of registers to read/write data a RAM takes input of 8bit address, data input for the actual data to be stored and finally read and write enabler which works as it is for the latches.
Instruction is the granular level computation a computer can perform. There are various types of instruction a CPU can process.
Instructions include:
- Arithmetic such as add and subtract
- Logic instructions such as and, or, and not
- Data instructions such as move, input, output, load, and store
- Control Flow instructions such as goto, if … goto, call and return
- Notify CPU that the program has ended Halt
Instructions are provided to a computer using assembly language or are generated by a compiler or are interpreted in some high-level languages.
These instructions are hardwired inside the CPU. ALU contains the arithmetic and logical whereas the control flow is managed by CU.
In one clock cycle computers can perform one instruction but modern computers can perform more than one.
A group of instructions a computer can perform is called an instruction set.
Clock cycle
The speed of a computer is determined by its clock cycle. It is the number of **clock periods **per second a computer works on. Single clock cycles are very small like around 250 * 10 *-12 sec. Higher the clock cycle faster the processor is.
A CPU clock cycle is measured in GHz(Gigahertz). 1gHz is equal to 10 ⁹ Hz(hertz). A hertz means a second. So 1Gigahertz means 10 ⁹ cycles per second.
The faster the clock cycle, the more instructions the CPU can execute. Clock cycle = 1/clock rate CPU Time = number of clock cycle / clock rate
This means to improve CPU time we can increase clock rate or decrease number of clock cycle by optimizing the instruction we provide to CPU. Some processor provides the ability to increase the clock cycle but since it is physical changes there might be overheating and even smokes/fires.
Instructions are stored on the **RAM **in sequential order. For a hypothetical CPU Instruction consists of OP code(operational code) and memory or register address.
There are two registers inside a Control Unit **Instruction register(IR) **which loads the OP code of the instruction and instruction address register which loads the address of the currently executing instruction. There are other registers inside a CPU that stores the value stored in the address of the last 4 bits of an instruction.
Let’s take an example of a set of instructions which adds two numbers. The following are the instructions along with there description:
STEP 1 — LOAD_A 8:
The instruction is saved in RAM initially as let’s say <1100 1000>. The first 4 bit is the op-code. This determines the instruction. This instruction is **fetched **into the **IR **of the control unit. The instruction is decoded to be load_A which means it needs to load the data in the address 1000 which is the last 4 bit of the instruction to register A.
STEP 2 — LOAD_B 2
Similar to above this loads the data in memory address 2 (0010) to CPU register B.
STEP 3 — ADD B A
Now the next instruction is to add these two numbers. Here the CU tells ALU to perform the add operation and save the result back to register A.
STEP 4 — STORE_A 23
This is a very simple set of instructions that helps add two numbers.
We have successfully added two numbers!
All the data between CPU, register, memory and IO devise are transferred via bus. To load the data to memory that it has just added, the CPU puts the memory address to address-bus and the result of the sum to the data-bus and enables the right signal in the control-bus. In this way, the data is loaded to memory with the help of the bus.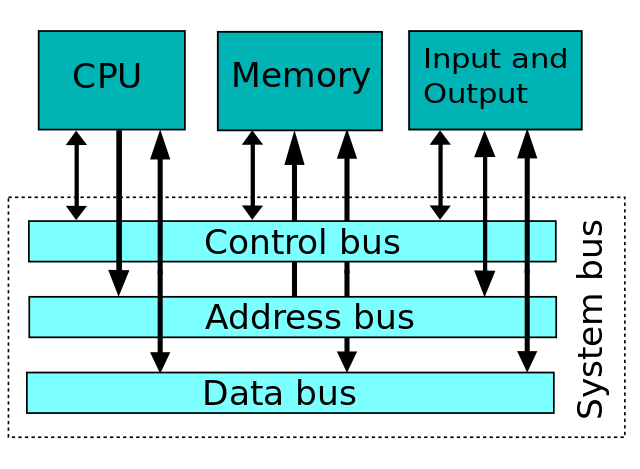
CPU also has a mechanism to prefetch the instruction to its cached. As we know there are millions of instructions a processor can complete within a second. This means that there will be more time spent in fetching the instruction from RAM than executing them. So the CPU cache prefetches some of the instruction and also data so that the execution gets fast.
If the data in the cache and operating memory is different the data is marked as a dirty bit.
Modern CPU uses **Instruction pipelining for **parallelization in instruction execution. Fetch, Decode, Execute. When one instruction is in the decode phase the CPU can process another instruction for the fetch phase.
This has one problem when one instruction is dependent on another. So processors execute the instruction that is not dependent and in a different order.
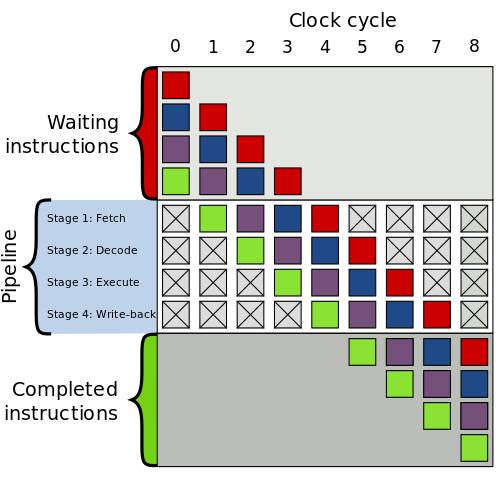
It is basically the different CPU but has some shared resources like the cache.
The Performance of CPU is determined by it’s execution time. Performance = 1/execution time
let’s say it takes 20ms for a program to execute. The performance of CPU is 1/20 = 0.05msRelative performance = execution time 1/ execution time 2
The factor that comes under consideration for a CPU performance is the instruction execution time and the CPU clock speed. So to increase the performance of a program we either need to increase the clock speed or decrease the number of instruction in a program. The processor speed is limited and modern computers with multi-core can support millions of instructions a second. But if the program we have written has a lot of instructions this will decrease the overall performance.
**Big O notation **determines with the given input on how the performance will be affected.
There is a lot of optimizations done in the CPU to make it faster and perform as much as it can. While writing any program we need to consider how reducing the number of instruction we provide to CPU will increase the performance of the computer program.