项目地址:https://github.com/gl-stars/word-of-pdf.git
注意:项目我是在国内写的,所以一切资源都是保存在国内。由于GitHub网站访问不多国内的原因,所以你可能看到的这个文档照片可能无法显示,你可以参考博客:https://blog.csdn.net/qq_41853447/article/details/107715704
相关案例:
https://github.com/aspose-words/Aspose.Words-for-Java.git
https://github.com/aspose-pdf/Aspose.PDF-for-Java.git
这是在GitHub上的,拉去非常慢。建议在gitee上创建项目哪里,点击创建项目,下面有一个导入已有的项目。将GitHub上的地址给他就可以克隆一个项目过来,拉去速度就快了。但是这两个项目在gitee上是有地址的。
这两个jar包是收费的,我这里特意准备是说明这两个jar包已经破解开了。
需要使用的jar
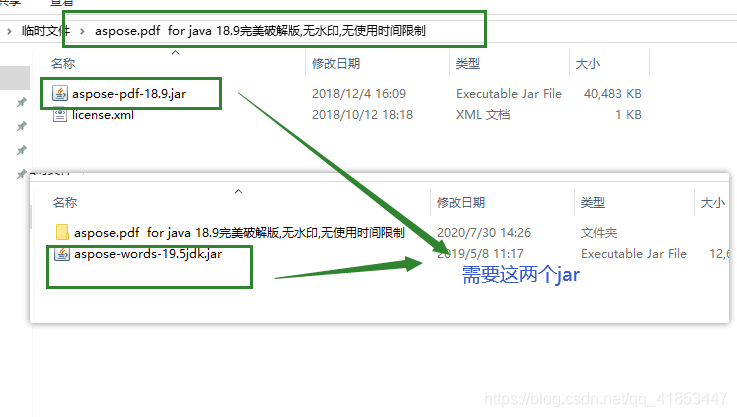
这给你个jar在文档管理里面有,百度网盘也有。将两个jar安装到本地仓库里面,项目中就可以直接调用。
aspose-pdf-18.9.jar 最好放到外面来安装到本地仓库,因为这个所在的
aspose.pdf for java 18.9完美破解版,无水印,无使用时间限制目录中有空格,安装不到本地仓库中。
安装jar到本地仓库,参考:https://blog.csdn.net/u010393325/article/details/84314543
- 命令
mvn install:install-file -DgroupId=groupId引用的名字 -DartifactId=aspose-artifactId引用的名字 -Dversion=版本号 -Dpackaging=jar -Dfile=jar所在的地址
版本号在jar的末尾有写到。
- 我安装的命令
需要更改jar所在的目录。
mvn install:install-file -DgroupId=com.aspose -DartifactId=aspose-words -Dversion=19.5 -Dpackaging=jar -Dfile=E:\临时文件\aspose-words-19.5jdk.jar
mvn install:install-file -DgroupId=com.aspose -DartifactId=aspose-pdf -Dversion=18.9 -Dpackaging=jar -Dfile=E:\临时文件\aspose-pdf-18.9.jar
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-pdf</artifactId>
<version>18.9</version>
</dependency>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-words</artifactId>
<version>19.5</version>
</dependency>word的.doc和 .docx格式都可以转换。
- 全部代码
贴全部代码的目的是为了将所在的包也显示。
package com.word.pdf;
import com.aspose.words.*;
/**
* @author: stars
* @date: 2020年 07月 30日 13:58
**/
public class TestDemo {
public static void main(String[] args) throws Exception {
String inputPath = "C:\\Users\\stars\\Desktop\\powerdesigner使用.doc" ;
String outPath = "C:\\Users\\stars\\Desktop";
String fileName = "powerdesigner使用";
setShowInBalloons(inputPath,outPath,fileName);
}
/**
* 将word文档转为PDF文档
*
* @param inputPath word文档所在的地址
* @param outPath 生成pdf输出的地址
* @param fileName 生成后PDF的名字<b>注意:名字不要带后缀,下面自动封装了。</b>
* @throws Exception
*/
private static void setShowInBalloons(String inputPath,String outPath,String fileName) throws Exception {
Document doc = new Document(inputPath);
// 获取控制修订外观的RevisionOptions对象
RevisionOptions revisionOptions = doc.getLayoutOptions().getRevisionOptions();
// 在引出序号中显示删除修订
revisionOptions.setShowInBalloons(ShowInBalloons.FORMAT_AND_DELETE);
// 输出
doc.save(outPath + "\\" + fileName+ ".pdf");
}
}效果就不展示了,反正这样就能转换。
import com.aspose.words.Document;
import com.aspose.words.ImportFormatMode;
import com.aspose.words.RevisionOptions;
import com.aspose.words.ShowInBalloons;/**
* word文件追加
*/
public static void AppendDocuments(){
// 文件路径
String dataDir = "C:\\Users\\stars\\Desktop\\" ;
// 源文件
Document dstDoc = new Document(dataDir + "powerdesigner使用.doc");
// 需要追加的文件(将srcDoc文件追加在dstDoc后面)
Document srcDoc = new Document(dataDir + "ZS-1000质量手册.docx");
// Append the source document to the destination document while keeping the original formatting of the source document.
dstDoc.appendDocument(srcDoc, ImportFormatMode.KEEP_SOURCE_FORMATTING);
// 追加后的文件
dstDoc.save(dataDir + "TestFile Out.docx");
//ExEnd:
System.out.println("Documents appended successfully.");
}import com.aspose.words.*;
import java.util.regex.Pattern;/**
* 查找并替换
* @param replaceMark 替换表示符
* @param replaceAfter 替换的数据
* @throws Exception
*/
public static void FindAndReplace(String replaceMark,String replaceAfter) throws Exception {
// 文件路径
String dataDir = "C:\\Users\\stars\\Desktop\\" ;
// 源文件
Document doc = new Document(dataDir + "powerdesigner使用.doc");
// 检查文档的文本
System.out.println("Original document text: " + doc.getRange().getText());
Pattern regex = Pattern.compile(replaceMark, Pattern.CASE_INSENSITIVE);
// Replace the text in the document.
doc.getRange().replace(regex, replaceAfter, new FindReplaceOptions());
// Check the replacement was made.
System.out.println("Document text after replace: " + doc.getRange().getText());
// 替换后的文件
doc.save(dataDir + "ReplaceSimpleOut.doc");
}替换是应该需要注意
如果替换符为 name和 namea。那么 name替换符先执行,那么 namea的地方就会将 name也替换了,后面剩下 a。但是这个a又没有替换的地方,所以就保存了下来。这样会造成替换上的失误,所以建议替换符使用UUID去掉横线或者生成分布式id来充当。
这种方式有些页面不能获取,推荐使用另一个jar包完整,第六章会详细讲解。
import com.aspose.pdf.Document;
import com.aspose.pdf.Page;
import java.io.IOException;/**
* 获取PDF指定页面
* <p>如果获取所有PDF,就直接使用 pdfDocument。如果获取指定页数就是使用 newDocument。如果返回所有pdfDocument.save(response.getOutputStream());
* 如果返回指定页,newDocument.save(response.getOutputStream());
* </p>
* @param page 获取的页数
* @return pdf总页数
*/
public static Integer GetPageCountWithoutSavingPDF(Integer page) throws IOException {
// Open a document
Document pdfDocument = new Document("C:\\Users\\stars\\Desktop\\a.pdf");
// 获取指定页面
Page pdfPage = pdfDocument.getPages().getUnrestricted(page);
// 创建Document 对象,将指定页面写入
Document newDocument = new Document();
// Add the page to the Pages collection of new document object
newDocument.getPages().add(pdfPage);
// Save the new file
newDocument.save("C:\\Users\\stars\\Desktop\\page_" + pdfPage.getNumber() + ".pdf");
// 返回总页数
return pdfDocument.getPages().size();
}第五章节提到的这种方式,有些页面会获取不多,所以换一个jar包获取。
<dependency>
<groupId>net.sf.cssbox</groupId>
<artifactId>pdf2dom</artifactId>
<version>1.7</version>
</dependency>如果只完成获取指定页面的PDF文档,那么这个jar包已经足够了,但是配套的还有两个jar包。这些都是开源的,不需要特意准备,直接拉去就OK。下面这两个具体用途可以自己去参考。
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.12</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.12</version>
</dependency>import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.IOException;
import java.util.List;/**
*
* @param fileName 文件名称
* @param pageNum 读取的页数
* @param filePath 文件路径
* @return
*/
public void splitPdf(HttpServletResponse response, int pageNum, String filePath) {
// 这是对应文件名
File indexFile = new File(filePath);
PDDocument document = null;
try {
document = PDDocument.load(indexFile);
// 获取总页数
int numberOfPages = document.getNumberOfPages();
System.out.println("总页数告诉你哦:"+numberOfPages);
Splitter splitter = new Splitter();
// 开始页
splitter.setStartPage(pageNum);
// 结束页
splitter.setEndPage(pageNum);
List<PDDocument> pages = splitter.split(document);
for (PDDocument pdDocument : pages){
pdDocument.save(response.getOutputStream());
pdDocument.close();
}
document.close();
} catch (IOException e) {
e.printStackTrace();
}
}如果是一个大文档,我们给前端渲染的时候不会全部给他,而是一次一页一页的给。那么我们是一个大文档模板怎么办。将这个大文档存为PDF格式,每次一页一页的获取,因为PDF不能更改,属于最终文本。那么我们就可以将pdf转为word替换为最终文档,然后在将word转为PDF给前端显示。
- 优点
pdf支持读取指定的页面,前端页支持直接渲染pdf格式的文本。所以大文档就不用全部读取,只需要读取指定页面就好。
- 缺点
pdf不支持更改
- 优点
支持更改和替换
- 缺点
不支持获取指定页的文档,前端不支持显示。
这种方式只支持转换 4 页
import com.aspose.pdf.*;
import java.io.IOException;/**
* pdf转为doc
*/
public static void savingToDoc(){
// 读取pdf文档
Document pdfDocument = new Document("C:\\Users\\stars\\Desktop\\abc.pdf");
// 转换为doc文档
pdfDocument.save("C:\\Users\\stars\\Desktop\\TableHeightIssue.doc", SaveFormat.Doc);
}这种方式只支持转换 4 页
这种方式转为doc也可以,只需要将文件后缀换一下就行。
import com.aspose.pdf.*;
import java.io.IOException;/**
* pdf转为docx
*/
public static void savingToDOCX() {
// Load source PDF file
Document doc = new Document("C:\\Users\\stars\\Desktop\\abc.pdf");
// Instantiate Doc SaveOptions instance
DocSaveOptions saveOptions = new DocSaveOptions();
// Set output file format as DOCX
saveOptions.setFormat(DocSaveOptions.DocFormat.DocX);
// Save resultant DOCX file
doc.save("C:\\Users\\stars\\Desktop\\TableHeightIssue.docx", saveOptions);
}import com.aspose.pdf.*;
import java.io.IOException;/**
* 将PDF转为ppt
*/
public static void ConvertPDFToPPTX(){
// Load PDF document
Document doc =new Document("C:\\Users\\stars\\Desktop\\t.pdf");
// Instantiate PptxSaveOptions instance
PptxSaveOptions pptx_save = new PptxSaveOptions();
// Save the output in PPTX format
doc.save("C:\\Users\\stars\\Desktop\\output.pptx", pptx_save);
}import com.aspose.pdf.*;
import java.io.IOException;/**
* 将pdf转为SVG图片
*/
public static void ConvertPDFToSVGFormat(){
// load PDF document
Document doc = new Document("C:\\Users\\stars\\Desktop\\t.pdf");
// instantiate an object of SvgSaveOptions
SvgSaveOptions saveOptions = new SvgSaveOptions();
// do not compress SVG image to Zip archive
saveOptions.CompressOutputToZipArchive = false;
// resultant file name
String outFileName ="C:\\Users\\stars\\Desktop\\Output.svg";
// save the output in SVG files
doc.save(outFileName, saveOptions);
}import com.aspose.pdf.*;
import java.io.IOException;/**
* 将SVG转为PDF
*/
public static void ConvertSVGFileToPDFFormat(){
String file = "C:\\Users\\stars\\Desktop\\Output.svg";
// Instantiate LoadOption object using SVG load option
LoadOptions options = new SvgLoadOptions();
// Create Document object
Document document = new Document(file, options);
// Save the resultant PDF document
document.save("C:\\Users\\stars\\Desktop\\Result.pdf");
}显示大文档模板思路
完成大文本显示那种,就可以将大文档存放成PDF的格式。获取PDF指定页的文档模板,在转为HTML替换为真正的文档就可以个前端显示。
效果还可以
import com.aspose.pdf.*;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/**
* pdf转为HTML格式
*/
public static void EscapeHTMLTagsAndSpecialCharacters(){
// Load existing PDf file
Document pdfDoc = new Document("C:\\Users\\stars\\Desktop\\abc.pdf");
final Map names = new HashMap();
/*pdfDoc.FontSubstitution.add(new Document.FontSubstitutionHandler() {
public void invoke(Font font, Font newFont) {
// add substituted FontNames into map.
names.put(font.getFontName(), newFont.getFontName());
// or print the message into console
System.out.println("Warning: Font " + font.getFontName() + " was substituted with another font -> " + newFont.getFontName());
}
});*/
// instantiate HTMLSave option to save output in HTML
HtmlSaveOptions htmlSaveOps = new HtmlSaveOptions();
// save resultant file
pdfDoc.save("C:\\Users\\stars\\Desktop\\output.html", htmlSaveOps);
}这种方式转换的效果不好
import com.aspose.pdf.*;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;/**
* pdf转为HTML
* @throws Exception
*/
public static void DefaultFontWhenSpecificFontMissing() throws Exception {
String myDir = "C:\\Users\\stars\\Desktop\\";
Document pdf = new Document(myDir + "t.pdf");
// configure font substitution
CustomSubst1 subst1 = new CustomSubst1();
FontRepository.getSubstitutions().add(subst1);
// Configure notifier to console
pdf.FontSubstitution.add(new Document.FontSubstitutionHandler() {
public void invoke(Font font, Font newFont) {
// print substituted FontNames into console
System.out.println("Warning: Font " + font.getFontName() + " was substituted with another font -> " + newFont.getFontName());
}
});
HtmlSaveOptions htmlSaveOps = new HtmlSaveOptions();
pdf.save(myDir + "Redis_1150_substitutedWithMSGothic_release.html", htmlSaveOps);
}
private static class CustomSubst1 extends CustomFontSubstitutionBase {
public boolean trySubstitute(OriginalFontSpecification originalFontSpecification, /* out */com.aspose.pdf.Font[] substitutionFont) {
substitutionFont[0] = FontRepository.findFont("MSGothic");
return true;
}
}只能转换一页
import com.aspose.pdf.*;
import com.aspose.pdf.devices.EmfDevice;
import com.aspose.pdf.devices.Resolution;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/**
* pdf转为emf文件,只能转换一页
*/
public static void PDFToEMF(){
// instantiate EmfDevice object
EmfDevice device = new EmfDevice(new Resolution(96));
// load existing PDF file
Document doc = new Document("C:\\Users\\stars\\Desktop\\abc.pdf");
// save first page of PDF file as Emf image
device.process(doc.getPages().get_Item(1), "C:\\Users\\stars\\Desktop\\output.emf");
}import com.aspose.pdf.*;
import com.aspose.pdf.devices.EmfDevice;
import com.aspose.pdf.devices.Resolution;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/**
* 在现有的PDF 文档中添加数据
* <p>指定页添加表格</p>
*/
public static void addTableInExistingPDFDocument(){
// Load source PDF document
Document doc = new Document("C:\\Users\\stars\\Desktop\\abc.pdf");
// 初始化表的新实例
Table table = new Table();
// 将表格边框颜色设置为浅灰色
table.setBorder(new BorderInfo(BorderSide.All, .5f, Color.getLightGray()));
// 设置表格单元格的边框
table.setDefaultCellBorder(new BorderInfo(BorderSide.All, .5f, Color.getLightGray()));
// 添加三列十行的数据
for (int row_count = 1; row_count < 10; row_count++) {
// 向表中添加行
Row row = table.getRows().add();
// 添加表格的行数据
row.getCells().add("Column (" + row_count + ", 1)");
row.getCells().add("Column (" + row_count + ", 2)");
row.getCells().add("Column (" + row_count + ", 3)");
}
// 在PDF文档的第二页添加 table 这个表格
doc.getPages().getUnrestricted(2).getParagraphs().add(table);
doc.save( "C:\\Users\\stars\\Desktop\\Annotation_output.pdf");
}import com.aspose.pdf.*;
import com.aspose.pdf.devices.EmfDevice;
import com.aspose.pdf.devices.Resolution;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/**
* 创建PDF文档,并添加表格
*/
public static void setAutoFitToWindowPropertyInColumnAdjustmentTypeEnumeration(){
//Instantiate the PDF object by calling its empty constructor
Document doc = new Document();
//Create the section in the PDF object
Page page = doc.getPages().add();
//Instantiate a table object
Table tab = new Table();
//Add the table in paragraphs collection of the desired section
page.getParagraphs().add(tab);
//Set with column widths of the table
tab.setColumnWidths("50 50 50");
tab.setColumnAdjustment(ColumnAdjustment.AutoFitToWindow);
//Set default cell border using BorderInfo object
tab.setDefaultCellBorder(new com.aspose.pdf.BorderInfo(com.aspose.pdf.BorderSide.All, 0.1F));
//Set table border using another customized BorderInfo object
tab.setBorder(new com.aspose.pdf.BorderInfo(com.aspose.pdf.BorderSide.All, 1F));
//Create MarginInfo object and set its left, bottom, right and top margins
com.aspose.pdf.MarginInfo margin = new com.aspose.pdf.MarginInfo();
margin.setTop(5f);
margin.setLeft(5f);
margin.setRight(5f);
margin.setBottom(5f);
//Set the default cell padding to the MarginInfo object
tab.setDefaultCellPadding(margin);
//Create rows in the table and then cells in the rows
com.aspose.pdf.Row row1 = tab.getRows().add();
row1.getCells().add("col1");
row1.getCells().add("col2");
row1.getCells().add("col3");
com.aspose.pdf.Row row2 = tab.getRows().add();
row2.getCells().add("item1");
row2.getCells().add("item2");
row2.getCells().add("item3");
//Save the PDF
doc.save( "C:\\Users\\stars\\Desktop\\Annotation_output.pdf");
}import com.aspose.pdf.*;
import com.aspose.pdf.devices.EmfDevice;
import com.aspose.pdf.devices.Resolution;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/**
* 新建PDF添加数据
*/
public static void ForceTableRenderingOnNewPage(){
// Added document
Document doc = new Document();
PageInfo pageInfo = doc.getPageInfo();
MarginInfo marginInfo = pageInfo.getMargin();
marginInfo.setLeft(37);
marginInfo.setRight(37);
marginInfo.setTop(37);
marginInfo.setBottom(37);
pageInfo.setLandscape(true);
Table table = new Table();
table.setColumnWidths("50 100");
// Added page.
Page curPage = doc.getPages().add();
for (int i = 1; i <= 120; i++) {
Row row = table.getRows().add();
row.setFixedRowHeight(15);
Cell cell1 = row.getCells().add();
cell1.getParagraphs().add(new TextFragment("Content 1"));
Cell cell2 = row.getCells().add();
cell2.getParagraphs().add(new TextFragment("HHHHH"));
}
Paragraphs paragraphs = curPage.getParagraphs();
paragraphs.add(table);
/********************************************/
Table table1 = new Table();
table.setColumnWidths("100 100");
for (int i = 1; i <= 10; i++) {
Row row = table1.getRows().add();
Cell cell1 = row.getCells().add();
cell1.getParagraphs().add(new TextFragment("LAAAAAAA"));
Cell cell2 = row.getCells().add();
cell2.getParagraphs().add(new TextFragment("LAAGGGGGG"));
}
table1.setInNewPage(true);
// I want to keep table 1 to next page please...
paragraphs.add(table1);
//Save the PDF
doc.save( "C:\\Users\\stars\\Desktop\\Annotation_output.pdf");
}这种最好是一个字符替换为一个字符的那种,如果你一个字符替换很多字符。那么会出现有些内容显示不出来,因为其他文本不会让出空间来的。建议:将PDF转为word文档,替换完了再将word转为PDF文档。
pdf替换只支持前三页
import com.aspose.pdf.*;
import com.aspose.pdf.devices.EmfDevice;
import com.aspose.pdf.devices.Resolution;
import com.aspose.pdf.text.CustomFontSubstitutionBase;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/**
* 替换文本
* <b>如果一个文字替换一个文字,还行,因为其他格式是不变话的。只能替换前三页</b>
* @param BeforeReplacement 替换前
* @param AfterReplacement 替换后
*/
public static void replaceTextOnAllPages(String BeforeReplacement,String AfterReplacement){
// 需要替换的文本
Document doc = new Document("C:\\Users\\stars\\Desktop\\abc.pdf");
// 需要替换的字符
TextFragmentAbsorber textFragmentAbsorber = new TextFragmentAbsorber(BeforeReplacement);
// Accept the absorber for first page of document
doc.getPages().accept(textFragmentAbsorber);
// Get the extracted text fragments into collection
TextFragmentCollection textFragmentCollection = textFragmentAbsorber.getTextFragments();
// Loop through the fragments
for (TextFragment textFragment : (Iterable<TextFragment>) textFragmentCollection) {
// Update text and other properties
textFragment.setText(AfterReplacement);
// 字体大小
textFragment.getTextState().setFontSize(10);
textFragment.getTextState().setForegroundColor(Color.getBlack());
// 背景色,现在是白色
textFragment.getTextState().setBackgroundColor(Color.getWhite());
}
// 替换后的文本
doc.save( "C:\\Users\\stars\\Desktop\\Annotation_output.pdf");
}