This project provides a tool for learning English vocabulary, designed specifically for English learners, by expanding their vocabulary through reading English or bilingual articles. Users can automatically extract words from the learning articles, analyze word frequency, filter words, and track and record their mastery level.
- Vocabulary Learning Tool! Enter the URL of an English or bilingual article, and this tool will automatically extract all words and their corresponding sentences from the article, deduplicate and summarize the words in the article. You can filter to display only the words you don't know.
- This tool supports custom dictionary libraries, allowing users to add their own dictionary libraries for referencing word meanings during the learning process.
- 20040324: Important: v2.0.0 adds the web version, supporting local deployment or cloud deployment.
- Word Extraction and Recording: Enter a URL, and the tool automatically retrieves and extracts all words and their contextual sentences from the web article. Additionally, it calculates and displays the vocabulary size of the article.
- Intelligent Management and Filtering: Avoid redundant learning of words you already know by utilizing deduplication and excluding options for mastered vocabulary, allowing you to focus on learning new words.
- Learning Progress Tracking: Words can be marked with different cognitive levels, including "0: Unknown," "1: Recognized", "2: Familiar", "3: Proficient". This helps customize the learning path while enhancing memory retention.
- Filtered Browsing Functionality: Filter out words of specific cognitive levels, for example, selecting the "0" tag displays all the words you are yet to understand.
- Synchronization and Platform Compatibility: Developed using Go and Flutter for cross-platform applications, supports usage on Android, Linux, and Windows, with data synchronization between devices, enabling convenient learning without constraints.
- Web Version Support: Supports local or cloud deployment, enabling access to the web application via a browser, offering a consistent user experience with desktop and mobile applications.
- Local Data Storage: No reliance on backend servers, ensuring all data is securely stored locally, with support for local backups and restoration.
-
This tool is developed with a focus on cross-platform compatibility and user convenience. It not only utilizes the high-performance Go language for core logic but also employs Flutter to ensure a smooth user interface experience and consistency across platforms. Whether users are learning on any device, they can ensure seamless synchronization of their learning progress.
-
With a focus on English learning needs, our goal is to create a simple, efficient, and user-friendly vocabulary learning aid. We welcome you to use this tool to accelerate your language learning journey.
Reading English articles is widely recognized as an effective way to expand vocabulary. According to data analysis, about 50% to 70% of the vocabulary in each English article is considered effective. Please note that punctuation marks, articles, prepositions, and other simple vocabulary (such as "a," "in," "on," "the," "I," "than," "you," "he," etc.) have been automatically excluded from the articles. We suggest you:
- Consistently Read Daily: Develop a habit of reading English articles daily, whether it's news, academic papers, or novels.
- Record New Vocabulary: When encountering new words, use this tool to record them and classify their cognitive levels.
Continuous reading practice will directly reflect in the growth of your vocabulary. Over time, you will notice:
- Reduction in "0-level Unknown Words": The number of completely unfamiliar words encountered when reading each new article will gradually decrease.
- Improved Reading Speed: You will read articles faster and with a significant increase in comprehension depth and speed. Consistently practicing reading and using tools to assist you in recording and reviewing these new words is key to improving your English proficiency. As your vocabulary grows, you will not only read more fluently but also enhance your writing and conversational skills.
To effectively use this tool and enhance your English proficiency, this project recommends the following English reading resources. They provide rich bilingual content covering a wide range of topics suitable for learners of all levels:
-
The New York Times (Chinese-English Edition):Visit The New York Times Chinese-English Edition for high-quality bilingual reading materials. This will help improve your English comprehension and vocabulary.

-
The Economist China: The Economist China: English content tailored for Chinese readers, covering politics, economics, technology, and more. It's very beneficial for learners who want to gain in-depth understanding of global topics.
By utilizing these resources, you can not only expand your vocabulary in a targeted manner but also gain insights into different topics and background knowledge, comprehensively enhancing your English proficiency.
Please choose the correct compilation command according to your platform for compiling operations. You can select the Android, Linux, Windows, or Web version for installation.
- Prerequisites:
- Ensure that you have installed the
golanguage environment andflutterdevelopment environment on your device. - Make sure that tools such as
makeandzipare installed on your device. - For
Windowsenvironment, support forCGOis required- If the corresponding CGO runtime environment is not installed, you will encounter the following error when running:
exec: “gcc”: executable file not found in %PATH%
- Windows Go Language CGO Runtime Environment Configuration - https://www.expoli.tech/articles/2022/10/18/1666087321618
- Make for Windows
- https://gnuwin32.sourceforge.net/packages/make.htm
- Complete package, except sources
- If the corresponding CGO runtime environment is not installed, you will encounter the following error when running:
- Ensure that you have installed the
-
Installation Guide:
- For
Androidusers: Executemake build-androidin the terminal. - For
Linuxusers: Executemake build-linuxin the terminal. - For
Windowsusers: Executemake build-windowsin the terminal.
- For
-
Package Location: After compilation, the corresponding installation package files will be located in the "bin" folder of the project. Follow the standard installation process on your device to start using.
- Web Version:
The web desktop version is a standalone web application that can be run in a browser without installation. Simply execute the binary file in the command line to open the web application in your browser.
It supports usage on platforms such as Linux, Windows, and macOS. You can deploy the web version to your local computer device or deploy it on a cloud server for use on any device.
- Execute
make build-web-platformin the terminal. - Execute the compiled binary file in the command line, for example:
- Execute
./bin/mywords-web-linuxon Linux. - Execute
./bin/mywords-web-windows.exeon Windows. - Execute
./bin/mywords-web-macoson MacOS.
- Execute
- After execution, the browser will automatically open and access http://127.0.0.1:18960 or the specified port number.
├── bin # Directory for compiled project files, .apk for Android, .deb for Linux, .zip for Windows, binary files for Web version (e.g., mywords-web-linux, mywords-web-windows.exe, mywords-web-macos)
├── mywords-go # Directory for Go core logic source code used to compile .so library
├── mywords-flutter # Directory for Flutter source code used to compile installation packages
├── makefile # Makefile for the project
├── readme.md # Project documentation
To fully utilize the word learning and lookup features of this tool, you may need to add dictionary libraries with detailed word definitions. As dictionary database files can be large, please follow these steps to add them:
- Download Dictionary Database:
- Visit the provided non-permanent download link
http://vitogo.tpddns.cn:9081/_download/dict-ox10-v3.zipand copy the link to your browser to download the dictionary data file.。
- Contact and Support:
- If you encounter any issues while using this tool or adding dictionaries, or if you want to share your learning experiences and progress with us, please contact us via:
- WeChat:
vitogo-chat - Email:
[email protected]
- WeChat:
- You can also join our WeChat study and sharing group to exchange English learning experiences with other students and progress together. Scan the QR code below to join the WeChat group:
-

- Dictionary Library Format Description:
-
The dictionary library should be a zip compressed file containing the following contents:
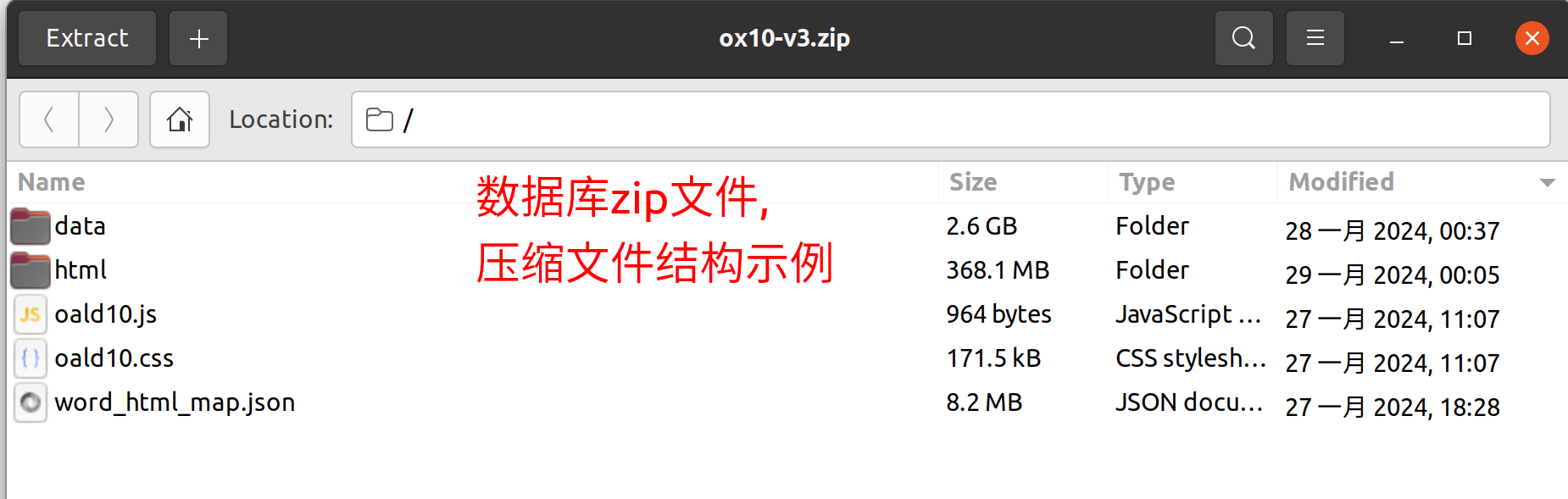
-
Structure Description:
data/: Folder containing dictionary resource files such as images, sounds, etc.html/: Folder containing html page files for word definitions, with filenames including the.htmlsuffix.*.css,*.js: Static resource files, can be placed in the root directory of the zip file or in the data folder.word_html_map.json: JSON file containing the mapping between words and html filenames, in key-value pairs ("key" is the word, "value" is the html filename without the.htmlsuffix).
- Creating Custom Dictionary Data:
- You can download mdx/mdd format dictionary files, for example, 牛津高阶英汉双解词典(第10版)V3
- Obtain and use related Python code for extracting and converting mdx/mdd resources:
- Resource conversion code link: https://bitbucket.org/xwang/mdict-analysis/src/master/
After downloading the MDX/MDD format dictionary files and extracting the code files for dictionary resources, you need to follow these steps to create the dictionary database file:
- Extract and create HTML files and
word_html_map.json::# coding: utf-8 import json import os from readmdict import MDX import os import sys def makeHtml(mdxPath): mdx = MDX(mdxPath) base_dir=os.path.dirname(mdxPath) all_words_path=os.path.join(base_dir,"word_html_map.json") html_dir=os.path.join(base_dir,"html") print("html directory is: "+html_dir) print("all words json file path: "+all_words_path) os.makedirs(html_dir,exist_ok=True) i=1 allWordsMap={} items=mdx.items() for key,value in items: word=key.decode(encoding='utf-8') # ### Fix the issue where some image tags are incorrectly placed within span tags in certain dictionary HTML files. If there are no such issues, you can comment out the replacement logic below. htmlContent=value.decode().strip() if htmlContent.startswith("<span id=")and htmlContent.endswith("</span>") and 'src="data:image/' in htmlContent: htmlContent=htmlContent.replace("<span id=","<img id=") htmlContent=htmlContent.replace("</span>","</img>") htmlContent=htmlContent.replace('style="display:none"','style="max-width: 100%"') value=htmlContent.encode() # ############## work_html_name = str(i) allWordsMap[word]=work_html_name html_path=os.path.join(html_dir,work_html_name+".html") df = open(html_path, 'wb') df.write(value) df.close() i+=1 b = json.dumps(allWordsMap,sort_keys=True,separators=None,indent=" ",ensure_ascii=False,) f2 = open(all_words_path, 'w') f2.write(b) f2.close() print(i,"exit with 0") if __name__ == '__main__': # python extract_html.py <mdx_path> mdx_path=sys.argv[1] makeHtml(mdx_path)
-
- Extract image and sound resource files (data folder):
python readmdict.py -x <.mdd file>
-
- Create a zip dictionary database compression file:
zip -q -r -9 mydict.zip data/ html/ *.css *.js word_html_map.json
- If the compression file contains other files, such as .ini files, you can add the corresponding file names in the zip command.
-
- Set the above dictionary database files as the dictionary database files
-
Load local dictionary database file -- start parsing
-

Please follow the above steps to ensure that the dictionary data is correctly added to your learning tool, so that you can refer to detailed definitions of words and phrases during your learning process, thereby effectively improving your language skills.
- Dark theme color
- Support for IOS and MacOS platforms
- Web version support, supporting local deployment and cloud deployment
- README.md of English version
We sincerely thank the following individuals and organizations for their support and contributions to this project:
- Thanks to The New York Times Chinese and English Edition for providing us with high-quality bilingual reading materials, which are very helpful for English learners.
- Thanks to The Economist China for providing us with high-quality English reading materials, enriching our learning with abundant content.
- Special thanks to Bitbucket.org/xwangfor providing the Python dictionary parsing tool, which is crucial for us to build the vocabulary database.
- Special thanks to louischeung.top for providing the Oxford Advanced English-Chinese bilingual dictionary, which is highly valuable for English learners.
- We express our deep gratitude to all users who have actively provided feedback and suggestions through WeChat or Email.
- Thanks to all contributors, testers, and users who have supported and used our tool. It is your support that drives the continuous improvement of this project.
Additionally, we would like to thank all friends who have quietly supported this project behind the scenes. Your encouragement and feedback are the sources of the project's continuous development.