| 功能 | 实现 |
|---|---|
| http框架 | gozero |
| rpc框架 | gozero |
| orm框架 | gorm |
| 数据库 | Innodb-cluster,redis-cluster |
| 对象存储 | 腾讯云cos,minio集群 |
| 服务发现与配置中心 | etcd |
| 链路追踪 | jaeger |
| 服务监控 | prometheus,grafana |
| 消息队列 | kafka |
| 日志搜集 | filebeat,go-stash,elasticsearch,kibana |
| 网关 | traefik |
| 部署 | Docker,docer-compose |
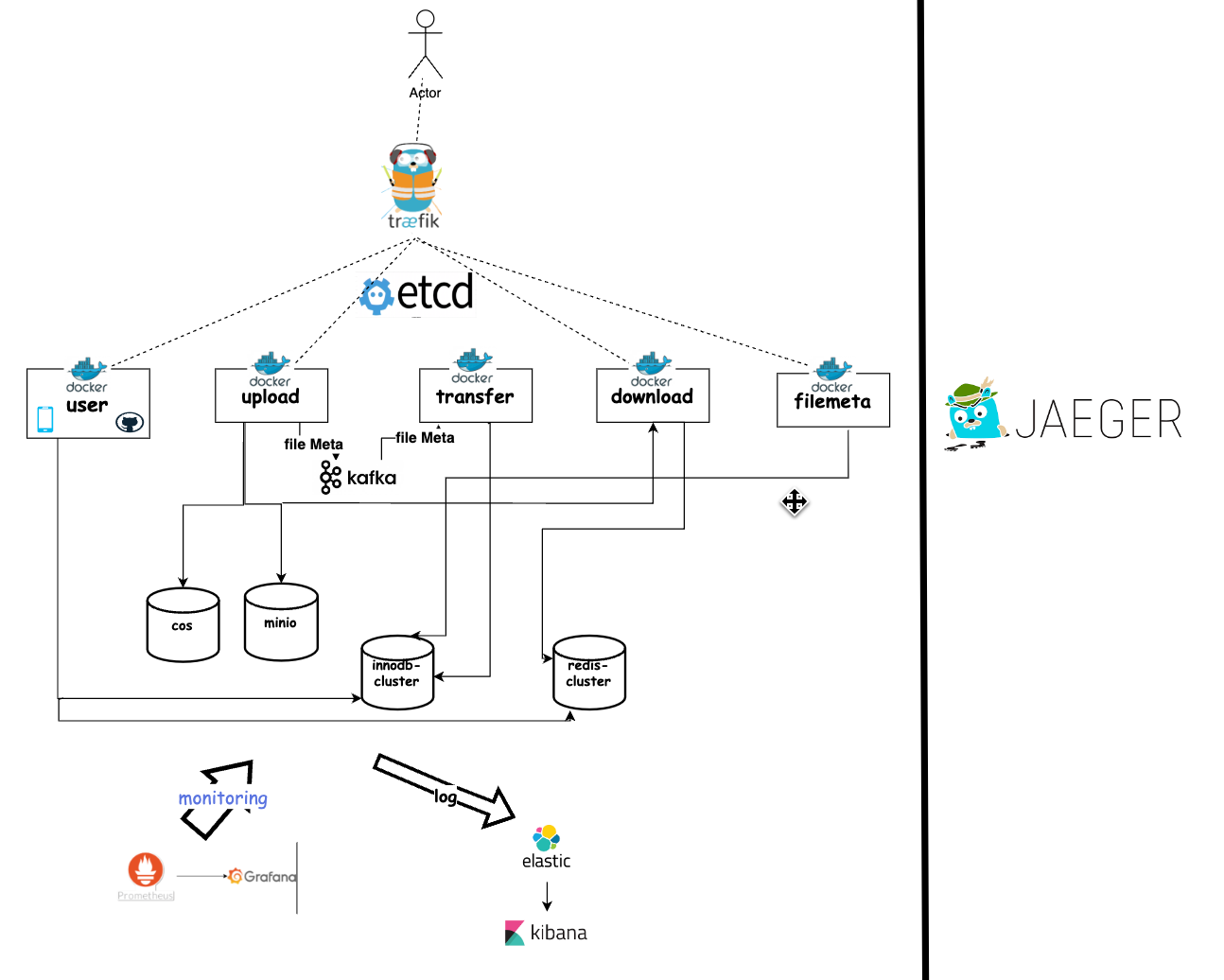
使用go-zero框架,将整个项目拆封为五个服务

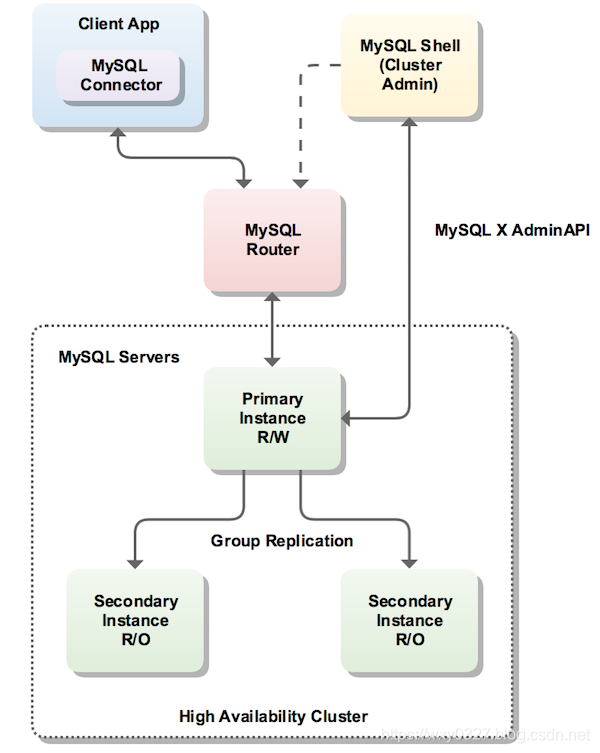
InnoDB 集群至少由三个 MySQL 服务器实例组成,并提供高可用性和可扩展性功能。将使用到以下 MySQL 技术:
- MySQL Shell,它是
MySQL官方提供的高级客户端和代码编辑器。 - MySQL Server 和 Group Replication(组复制),它们配合工作可以使一组MySQL实例对外提供高可能性。InnoDB Cluster提供了另一种易于使用的编程方式来使用Group Replication(组复制)功能。
- MySQL Router,一个能在应用程序和InnoDB集群之间提供透明路由的轻量级中间件,是官方提供的MySQL实例负载均衡器(不再需要借助类似HAProxy的第三方负载均衡器了)。
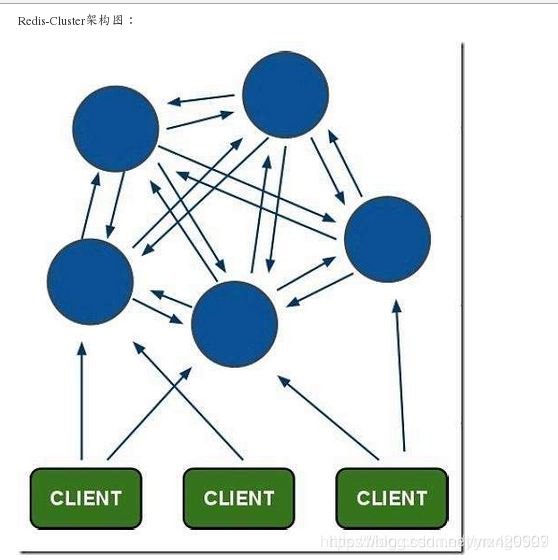
Redis-Cluster采用无中心结构,其结构特点:
- 每个节点都和其它节点通过互ping保持连接,每个节点保存整个集群的状态信息,可以通过连接任意节点读取或者写入数据(甚至是没有数据的空节点)。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- Redis集群预分好16384个哈希槽,当需要在
Redis集群中放置一个 key-value 时,根据公式HASH_SLOT=CRC16(key) mod 16384的值,决定将一个key放到哪个槽中。
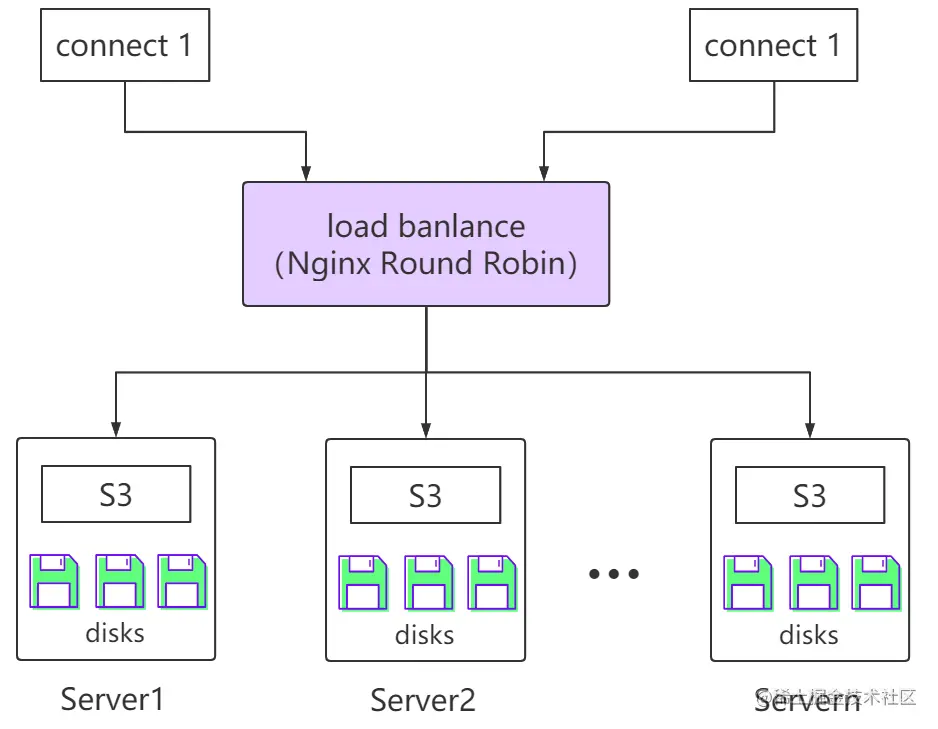
MinIO集群采用去中心化无共享架构,各节点间为对等关系,连接至任一节点均可实现对集群的访问。在我们的方案中还选择了Nginx的轮询实现各个节点的负载均衡。
数据对象在MinIO集群中进行存储时,先进行纠删分片,后打散存储在各硬盘上。具体为:
- MinIO自动在集群内生成若干纠删组,每个纠删组包含一组硬盘,其数量通常为4至16块;
- 对数据对象进行分片,默认策略是得到相同数量的数据分片和校验分片;
- 而后通过哈希算法计算出该数据对象对应的纠删组,并将数据和校验分片存储至纠删组内的硬盘上。
使用kafka+gorountie+batchers进行文件元信息的高并发处理
使用Traefik对服务进行反向代理和负载均衡
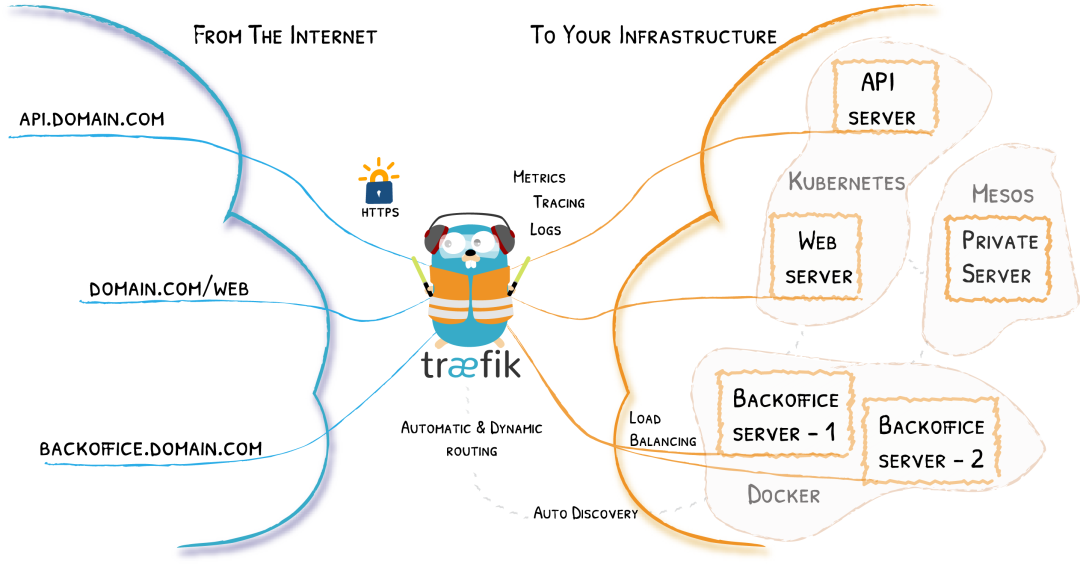
Traefik是一个为了让部署微服务更加便捷而诞生的现代HTTP反向代理、负载均衡工具。 它可以支持多种后端 (Docker, Swarm, Kubernetes, Marathon, Mesos, Consul, Etcd, Zookeeper, BoltDB, Rest API, file…) 来自动化、动态的应用它的配置文件设置

随着微服务生态的盛行,在基于不同的业务场景中,一个简单的请求往往可能会涉及到多个不同服务类型,此时,若某个服务所提供的业务出现异常,从而可能会导致整个业务处理链路中的问题跟踪、定位及其分析较为困难,服务之间的依赖梳理、组件排查就变得尤为复杂。
受Dapper和OpenZipkin启发的Jaeger是由Uber Technologies作为开源发布的分布式跟踪系统。它用于监视和诊断基于微服务的分布式系统
使用prometheus来作为监控工具
然后使用grafana来显示

filebeat收集业务日志,然后将日志输出到kafka中,go-stash拉取kafka中日志根据配置过滤字段,然后将过滤后的字段输出到elasticsearch中,最后由kibana负责呈现日志
外接腾讯云SMS服务,填写验证码后自动进行注册或者登录判断,免得先注册才能再登录,提高用户体验
使用valiata包进行校验,并且加上中文翻译器,这样也不必进行繁琐的格式或者边界校验,自动返回翻译后的错误
使用GitHub OAuth进行第三方登录
- 可以选择本地或者minio存储或者腾讯云COS进行存储
异步处理,可以让用户不用等待文件元信息存入mysql的所需的时间,提高用户体验。针对高并发场景,提高吞吐量。
- 使用批量消息聚合提升kafka性能
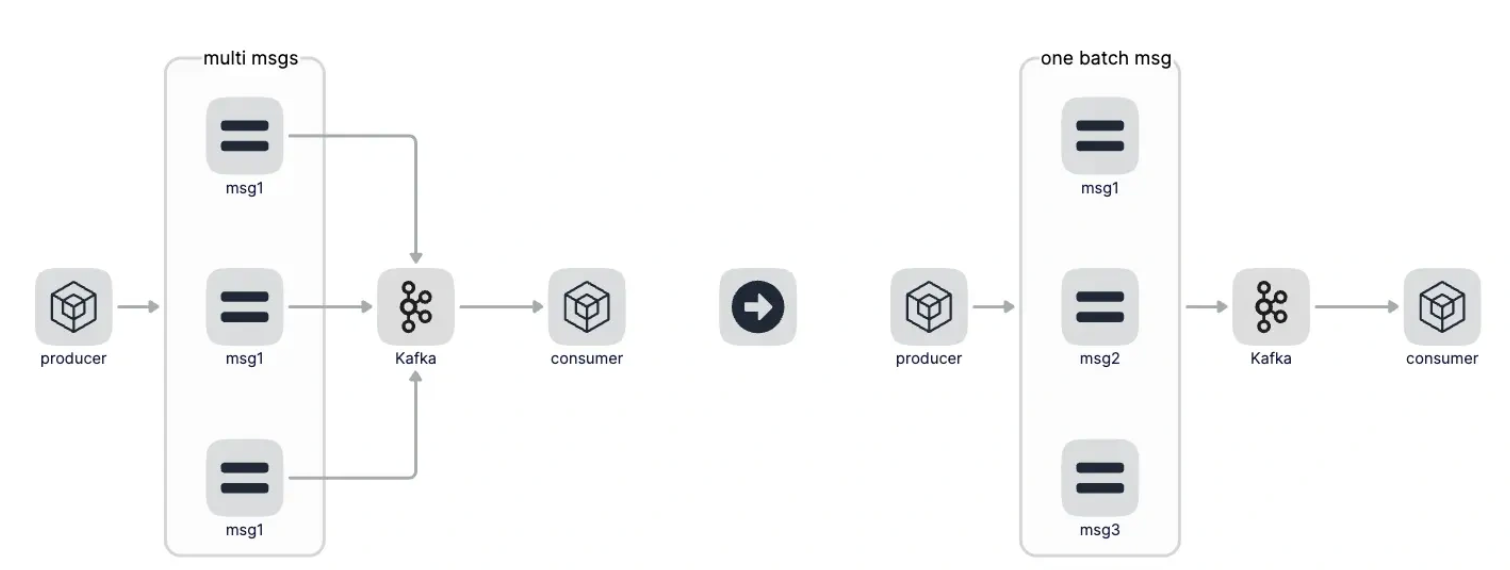
之前每向kafka发送一条消息就会产生一次网络 IO 和一次磁盘 IO,做消息聚合后,比如聚合 100 条消息后再发送给 Kafka,这个时候 100 条消息才会产生一次网络 IO 和磁盘 IO,这样大大提高 Kafka 的吞吐和性能。并且有聚合时间兜底,就算消息数量达不到聚合要求,超过聚合最大时间也会聚合当前所有消息发送给Kafka
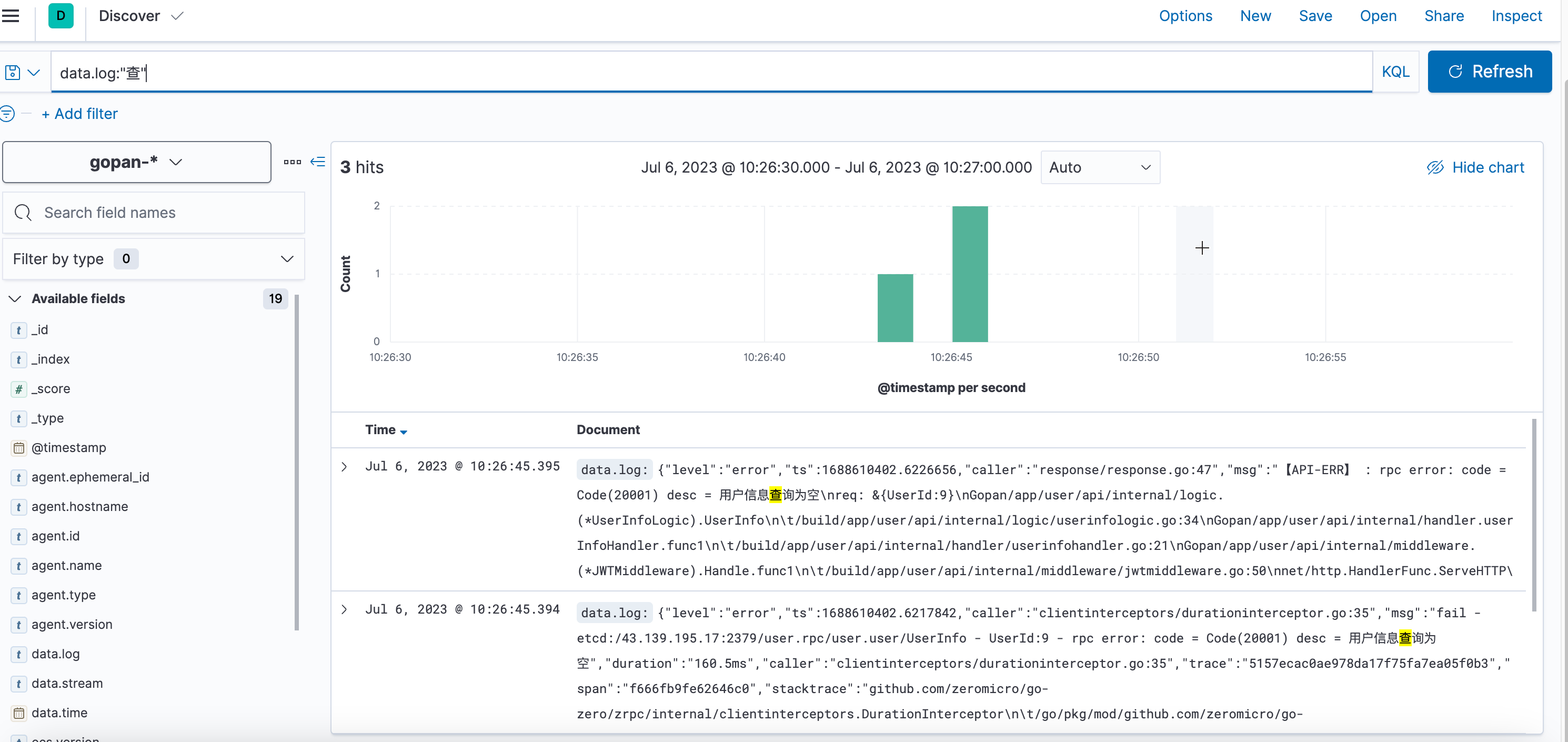
根据文件的sha1值判断,先从file表里面查出是否有该sha1值,如果有就只需要将file表里的file添加到对应userfile表里面就可以了,这样就实现了秒传的功能
客户端将文件分成几份,每次一都上传一份,然后服务端接受客户端上传的分块文件存入本地,在redis中记录分块文件信息,等客户端上传完后调用服务端的接口,服务端校验文件分块已经上传成功后进行合并文件再上传到对应的存储,之后也使用kafka来异步处理文件元信息。断点续传就是查询之前上传过的分块,从未上传的分块开始继续传
利用官方SDK进行分块下载到本地,然后返回文件给客户端
实现了并发从minio下载分块文件,下载所有分块后进行合并分块返回合并后的文件给客户端
通过将消息随机发到多个 goroutine中来并发消费数据,再将消费的文件元信息写入mysql。
提供文件元数据相关操作
- 从docker-compose部署迁移到k8s集群部署
- 使用GitHub Action/gitlab jenkins 进行 CI/CD
- 分布式引入,mapreduce思想
- 用户文件的移动操作
- ....
gopan 在 MIT 许可证下开源,请在遵循 MIT 开源证书 规则的前提下使用