This is a short guide on setting up the system and environment dependencies required for the MFlix application to run.
Downloading the mflix-js.zip handout may take a few minutes. Unzipping the file should create a new directory called mflix-js.
Most of your work will be implementing methods in the dao directory, which contains all database interfacing methods. The API will make calls to Data Access Objects (DAOs) that interact directly with MongoDB.
The unit tests in test will test these database access methods directly, without going through the API. The UI will run these methods in integration tests, and therefore requires the full application to be running.
The lesson handouts can be found in the test/lessons directory. These files
will look like .spec.js, and can be run with npm test -t <lesson-name>.
The API layer is fully implemented, as is the UI. The application is programmed to run on port 5000 by default - if you need to run on a port other than 5000, you can edit the dotenv_win (if on Windows) or the dotenv_unix file (if on Linux or Mac) in the root directory to modify the value of PORT.
Please do not modify the API layer in any way, under the mflix-js/src/api directory. This may result in the front-end application failing to validate some of the labs.
The dependencies for the MFlix application should be downloaded using the
npm command-line tool. You can get this tool by downloading Node.js <https://nodejs.org/en/download/>_. Make sure to choose the correct option for
your operating system.
Once the installation is complete, you may need to restart your computer before using the command line tools. You can test that it's installed by running the following command:
node -v
This should print out the version of node you currently have - we recommend
using version 10 or later, so this command should print something like
v10.x.
Once npm is installed, you can install the MFlix dependencies by running the
following command from the mflix-js directory:
npm install
You must run this from the top level of the project, so npm has access to
the package.json file where the dependencies are.
You may see warnings depending on your operating system from fsevents or Husky warning about git missing. These are informational only and do not impact the functionality of the application. You can safely ignore them.
It is recommended to connect MFlix with MongoDB Atlas, so you do not need to have a MongoDB server running on your host machine. The lectures and labs in this course will assume that you are using an Atlas cluster instead of a local instance.
That said, you are still required to have the MongoDB server installed, in order to be able to use two server tool dependencies:
-
mongorestore- A utility for importing binary data into MongoDB.
-
mongo- The MongoDB shell
To download these command line tools, please visit the
MongoDB download center <https://www.mongodb.com/download-center#enterprise>_
and choose the appropriate platform.
All of these tools are free to use. MongoDB Enterprise is also free to use for testing and evaluation purposes.
MFlix uses MongoDB to persist all of its data.
One of the easiest ways to get up and running with MongoDB is to use MongoDB Atlas, a hosted and fully-managed database solution.
If you have taken other MongoDB University courses like M001 or M121, you may already have an account - feel free to reuse that cluster for this course.
Note: Be advised that some of the UI aspects of Atlas may have changed since the inception of this README, therefore some of the screenshots in this file may be different from the actual Atlas UI interface.
Using an existing MongoDB Atlas Account:
If you already have a previous Atlas account created, perhaps because you've taken one of our other MongoDB university courses, you can repurpose it for this course.
Log-in to your Atlas account and create a new project named M220 by clicking on the Context dropdown menu:
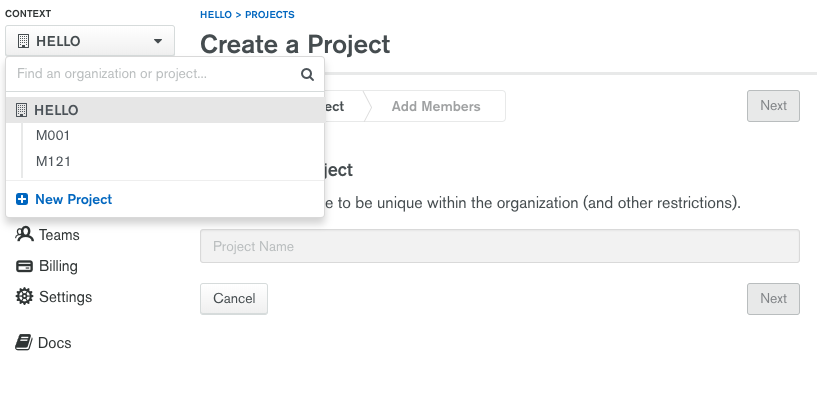
After creating a new project, you need to create an mflix free tier cluster.
Creating a new MongoDB Atlas Account:
If you do not have an existing Atlas account, go ahead and create an Atlas Account <https://cloud.mongodb.com/links/registerForAtlas>_ by filling in the
required fields:
Creating a free tier cluster called "mflix":
Note: You will need to do this step even if you are reusing an Atlas account.
- After creating a new project, you will be prompted to create the first cluster in that project:
- Choose AWS as the cloud provider, in a Region that has the label Free Tier Available:
- Select Cluster Tier M0:
- Set Cluster Name to mflix and click Create Cluster. It may take 7-10 minutes to successfully create your Atlas cluster:
- Once you press Create Cluster, you will be redirected to the account dashboard. In this dashboard, make sure you set your project name to M220. Go to Settings menu item and change the project name from the default Project 0 to M220:
- Next, configure the security settings of this cluster, by enabling the IP Whitelist and MongoDB Users:
Update your IP Whitelist so that your app can talk to the cluster. Click the Security tab from the Clusters page. Then click IP Whitelist followed by Add IP Address. Finally, click Allow Access from Anywhere and click Confirm.
- Then create the application MongoDB database user required for this course:
- username: m220student
- password: m220password
You can create new users through Security -> Add New User.
Allow this user the privilege to Read and write to any database:
- When the user is created, and the cluster deployed, you can test the setup by connecting via the Mongo shell. You can find instructions to connect in the Connect Your Application section of the cluster dashboard:
Go to your cluster Overview -> Connect -> Connect Your Application.
Select the option corresponding to your local MongoDB version and copy the
mongo connection command.
The below example connects to Atlas as the user you created before, with username m220student and password m220password. You can run this command from your command line:
mongo "mongodb+srv://m220student:m220password@<YOUR_CLUSTER_URI>"
By connecting to the server from your host machine, you have validated that the cluster is configured and reachable from your local workstation.
You may see the following message when you connect::
Error while trying to show server startup warnings: user is not allowed to do action [getLog] on [admin.]
This is a log message, not an error - feel free to ignore it.
The mongorestore command necessary to import the data is located below. Copy
the command and use an Atlas SRV string to import the data (including username
and password credentials).
Replace the SRV string below with your own:
navigate to mflix-js directory
cd mflix-js
mongorestore --drop --gzip --uri \ "mongodb+srv://m220student:m220password@<YOUR_CLUSTER_URI>" data
The entire dataset contains almost 200,000 documents, so importing this data may take 5-10 minutes.
In order for the application to use Atlas, you will need a file called .env to contain the connection information. In the mflix-js directory you can find two files, dotenv_unix (for Unix users) and dotenv_win (for Windows users).
Open the file for your chosen operating system and enter your Atlas SRV connection string as directed in the comment. This is the information the driver will use to connect. Make sure not to wrap your Atlas SRV connection between quotes::
MFLIX_DB_URI = mongodb+srv://...
It's highly suggested you also change the SECRET_KEY to some very long, very random string. While this application is only meant for local use during this course, software has a strange habit of living a long time.
When you've edited the file, rename it to .env with the following command:
mv dotenv_unix .env # on Unix
ren dotenv_win .env # on Windows
Note: Once you rename this file to .env, it will no longer be visible in Finder or File Explorer. However, it will be visible from Command Prompt or Terminal, so if you need to edit it again, you can open it from there:
vi .env # on Unix
notepad .env # on Windows
In the mflix-js directory, run the following commands:
install MFlix dependencies
npm install
start the MFlix application
npm start
This will start the application. You can then access the MFlix application at
http://localhost:5000/ <http://localhost:5000/>_.
To run the unit tests for this course, you will use Jest <https://jestjs.io/docs/en/getting-started>_. Jest has been included in this
project's dependencies, so npm install should install everything you need.
Each course lab contains a module of unit tests that you can call individually
with npm test. For example, to run the test connection-pooling.test.js,
run the command:
npm test -t connection-pooling
Each ticket will contain the exact command to run that ticket's specific unit tests. You can run these commands from anywhere in the mflix-js project.
Ticket: Connection
The exact connection string will depend on your Atlas cluster. After you correctly assign it, your .env file should look similar to the following (this was what our .env file looked like during development):
SECRET_KEY=everyone_is_a_critic
MFLIX_DB_URI=mongodb+srv://m220student:m220password@mflix-zux0z.mongodb.net/mflix
MFLIX_NS=mflix
PORT=50005a9026003a466d5ac6497a9d
Ticket: Projection
Here's a possible implementation of the getMoviesByCountry method:
let cursor
try {
// here's the find query with query predicate and field projection
cursor = await movies
.find({ countries: { $in: countries } })
.project({ title: 1 })
} catch (e) {
console.error(`Unable to issue find command, ${e}`)
return []
}5a94762f949291c47fa6474d
Ticket: Text and Subfield Search
Here's a possible implementation for this ticket:
static genreSearchQuery(genre) {
// here's how the genres query is implemented
const query = { genres: { $in: searchGenre } }
const project = {}
const sort = DEFAULT_SORT
return { query, project, sort }
}5a96a6a29c453a40d04922cc
Ticket: Paging
A Note About Performance
It is actually not ideal to implementing paging using .skip() and .limit(). This is because .skip() still requires iteration over the documents it's skipping. For more information (and a more performant implementation of paging), please visit the MongoDB docs.
Here's a possible implementation of getMovies using .skip() and .limit():
try {
cursor = await movies
.find(query)
.project(project)
.sort(sort)
} catch (e) {
console.error(`Unable to issue find command, ${e}`)
return { moviesList: [], totalNumMovies: 0 }
}
`5a9824d057adff467fb1f526`
// here's where paging is implemented
const displayCursor = cursor.skip(moviesPerPage * page).limit(moviesPerPage)Ticket: Faceted Search
Here is a possible implementation of facetedSearch:
static async facetedSearch({
filters = null,
page = 0,
moviesPerPage = 20,
} = {}) {
if (!filters || !filters.cast) {
throw new Error("Must specify cast members to filter by.")
}
const matchStage = { $match: filters }
const sortStage = { $sort: { "tomatoes.viewer.rating": -1 } }
const countingPipeline = [matchStage, sortStage, { $count: "count" }]
const skipStage = { $skip: moviesPerPage * page }
const limitStage = { $limit: moviesPerPage }
const facetStage = {
$facet: {
runtime: [
{
$bucket: {
groupBy: "$runtime",
boundaries: [0, 60, 90, 120, 180],
default: "other",
output: {
count: { $sum: 1 },
},
},
},
],
rating: [
{
$bucket: {
groupBy: "$metacritic",
boundaries: [0, 50, 70, 90, 100],
default: "other",
output: {
count: { $sum: 1 },
},
},
},
],
movies: [
{
$addFields: {
title: "$title",
},
},
],
},
}
const queryPipeline = [
matchStage,
sortStage,
// here's where the three new stages are added
skipStage,
limitStage,
facetStage,
]
try {
const results = await (await movies.aggregate(queryPipeline)).next()
const count = await (await movies.aggregate(countingPipeline)).next()
return {
...results,
...count,
}
} catch (e) {
return { error: "Results too large, be more restrictive in filter" }
}
}5aa7d3948adcc3fb770f06fb
Ticket: User Management
Here are possible implementations for the methods required by this ticket:
static async getUser(email) {
return await users.findOne({ email })
}
static async addUser(userInfo) {
try {
await users.insertOne({ ...userInfo })
return { success: true }
} catch (e) {
if (String(e).startsWith("MongoError: E11000 duplicate key error")) {
return { error: "A user with the given email already exists." }
}
console.error(`Error occurred while adding new user, ${e}.`)
return { error: e }
}
}
static async loginUser(email, jwt) {
try {
await sessions.updateOne(
{ user_id: email },
{ $set: { jwt } },
{ upsert: true },
)
return { success: true }
} catch (e) {
console.error(`Error occurred while logging in user, ${e}`)
return { error: e }
}
}
static async logoutUser(email) {
try {
await sessions.deleteOne({ user_id: email })
return { success: true }
} catch (e) {
console.error(`Error occurred while logging out user, ${e}`)
return { error: e }
}
}
static async getUserSession(email) {
try {
return await sessions.findOne({ user_id: email })
} catch (e) {
console.error(`Error occurred while retrieving user session, ${e}`)
return null
}
}5a8d8ee2f9588ca2701894be
Ticket: Durable Writes
Correct answers:
w: 2, w: "majority"
In a 3-node replica set, these two Write Concerns will both wait until 2 nodes have applied a write. This is because 2 out of 3 nodes is a majority, and waiting for 2 nodes to apply a write is more durable than only waiting for 1 node to apply it.
Updated addUser method (using w: majority ):
static async addUser(userInfo) {
try {
// here's where the new Write Concern is specified
await users.insertOne({ ...userInfo }, { w: "majority" })
return { success: true }
} catch (e) {
if (String(e).startsWith("MongoError: E11000 duplicate key error")) {
return { error: "A user with the given email already exists." }
}
console.error(`Error occurred while adding new user, ${e}.`)
return { error: e }
}
}Ticket: User Preferences
This is a possible implementation for this ticket:
static async updatePreferences(email, preferences) {
try {
// here's how the update statement is implemented
const updateResponse = await users.updateOne(
{ email },
{ $set: { preferences } },
)
if (updateResponse.matchedCount === 0) {
return { error: "No user found with that email" }
}
return updateResponse
} catch (e) {
return {
error: "An error occurred while updating this user's preferences.",
}
}
}Ticket: Get Comments
Here's a possible implementation of the getMovieByID method:
static async getMovieByID(id) {
try {
const pipeline = [
{
// find the current movie in the "movies" collection
$match: {
_id: ObjectId(id),
},
},
{
// lookup comments from the "comments" collection
$lookup: {
from: "comments",
let: { id: "$_id" },
pipeline: [
{
// only join comments with a match movie_id
$match: {
$expr: {
$eq: ["$movie_id", "$$id"],
},
},
},
{
// sort by date in descending order
$sort: {
date: -1,
},
},
],
// call embedded field comments
as: "comments",
},
},
]
return await movies.aggregate(pipeline).next()
} catch (e) {
console.error(`Something went wrong in getMovieByID, ${e}`)
return null
}
}Ticket: Create/Update Comments
Here are possible implementations of addComment and updateComment:
static async addComment(movieId, user, comment, date) {
try {
// here's how the commentDoc is constructed
const commentDoc = {
name: user.name,
email: user.email,
movie_id: ObjectId(movieId),
text: comment,
date: date,
}
return await comments.insertOne(commentDoc)
} catch (e) {
console.error(`Unable to post comment: ${e}`)
return { error: e }
}
}
static async updateComment(commentId, userEmail, text, date) {
try {
// here's how the update is performed
const updateResponse = await comments.updateOne(
{ _id: ObjectId(commentId), email: userEmail },
{ $set: { text, date } },
)
return updateResponse
} catch (e) {
console.error(`Unable to update comment: ${e}`)
return { error: e }
}
}Ticket: Delete Comments
Here's a possible implementation of deleteComment:
static async deleteComment(commentId, userEmail) {
const deleteResponse = await comments.deleteOne({
_id: ObjectId(commentId),
// the user's email is passed here to make sure they own the comment
email: userEmail,
})
return deleteResponse
}Ticket: User Report
Here's a possible implementation. We added the $sort and $limit stages to the pipeline before issuing the aggregation to ensure we get 20 results in the correct order.
static async mostActiveCommenters() {
try {
// here's how the pipeline stages are assembled
const groupStage = { $group: { _id: "$email", count: { $sum: 1 } } }
const sortStage = { $sort: { count: -1 } }
const limitStage = { $limit: 20 }
const pipeline = [groupStage, sortStage, limitStage]
// here's how the Read Concern durability is increased
const readConcern = { level: "majority" }
const aggregateResult = await comments.aggregate(pipeline, {
readConcern,
})
return await aggregateResult.toArray()
} catch (e) {
console.error(`Unable to delete comment: ${e}`)
return { error: e }
}
}Ticket: Migration
Here's a possible implementation for this ticket:
const MongoClient = require("mongodb").MongoClient
const ObjectId = require("mongodb").ObjectId
const MongoError = require("mongodb").MongoError
// This syntax is called an Immediately Invoked Function Executioin (IIFE)
// It's useful for proper scoping, and in this case allowing us to use
// async/await syntax
;(async () => {
try {
const host = "mongodb://localhost:27017"
const client = await MongoClient.connect(
host,
{ useNewUrlParser: true },
)
const mflix = client.db("mflix")
const predicate = { lastupdated: { $exists: true, $type: "string" } }
// we use the projection here to only return the _id and lastupdated fields
const projection = { lastupdated: 1 }
const cursor = await mflix
.collection("movies")
.find(predicate, projection)
.toArray()
const moviesToMigrate = cursor.map(({ _id, lastupdated }) => ({
updateOne: {
filter: { _id: ObjectId(_id) },
update: {
$set: { lastupdated: Date.parse(lastupdated) },
},
},
}))
// What's the strange "\x1b[32m"? It's coloring. 31 is red, 32 is green
console.log(
"\x1b[32m",
`Found ${moviesToMigrate.length} documents to update`,
)
// Here's where we dispatch the bulk update. We destructure the
// modifiedCount key out of the result
const { modifiedCount } = await mflix
.collection("movies")
.bulkWrite(moviesToMigrate)
console.log("\x1b[32m", `${modifiedCount} documents updated`)
client.close()
process.exit(0)
} catch (e) {
// check to see if the error was a MongoError and specifically a
// Invalid Operation error, meaning no documents to update
if (
e instanceof MongoError &&
e.message.slice(0, "Invalid Operation".length) === "Invalid Operation"
) {
console.log("\x1b[32m", "No documents to update")
} else {
console.error("\x1b[31m", `Error during migration, ${e}`)
}
process.exit(1)
}
})()Ticket: Connection Pooling
Here's an initialization of the MongoClient, with a larger connection pool:
MongoClient.connect(
process.env.MFLIX_DB_URI,
{ poolSize: 50, useNewUrlParser: true },
)5ad4f4f58d4b377bcf55d742
Ticket: Timeouts
Here's our implementation, providing the optional keyword argument wtimeout to the MongoClient connection.
MongoClient.connect(
process.env.MFLIX_DB_URI,
{ wtimeout: 2500, poolSize: 50, useNewUrlParser: true },
)5addf035498efdeb55e90b01
Ticket: Handling Errors
Here's an implementation of getMovieByID(), with the InvalidId error handled:
static async getMovieByID(id) {
try {
const pipeline = [
{
$match: {
_id: ObjectId(id),
},
},
{
$lookup: {
from: "comments",
let: { id: "$_id" },
pipeline: [
{
$match: {
$expr: {
$eq: ["$movie_id", "$$id"],
},
},
},
{
$sort: {
date: -1,
},
},
],
as: "comments",
},
},
]
return await movies.aggregate(pipeline).next()
} catch (e) {
// here's how the InvalidId error is identified and handled
if (
e
.toString()
.startsWith(
"Error: Argument passed in must be a single String of 12 bytes or a string of 24 hex characters",
)
) {
return null
}
console.error(`Something went wrong in getMovieByID: ${e}`)
throw e
}
}5ae9b76a703c7c603202ef22
Ticket: Principle of Least Privilege
To complete this ticket, you had to create a user that only has readWrite access to the mflix database only.
Then replace the authentication credentials, with this new user ones, in the MongoDB URI SRV string in your configuration file:
mongodb+srv://mflixAppUser:mflixAppPwd@<YOUR_CLUSTER_HOST>/admin5b61be29094dbae03bf30616
Correct Answer:
elections.find( { winner_party: "Republican",
winner_electoral_votes: { "$gte": 160 } } )This will find the documents whose winner_party is Republican, and whose winner_electoral_votes is greater than or equal to 160.
Correct Answer:
phones.updateMany( { software_version: { "$lt": 4.0 } },
{ "$set": { needs_to_update: true } } )This will find all phones with a software_version below 4.0, and set the needs_to_update field to True for those documents.
Correct Answers:
expect(clientOptions.authSource).toBe("admin")By default, MongoClient objects will authenticate against the admin database. To use the login credentials stored on another database., we can add authSource=<some-other-DB> at the end of the URI string.
expect(clientOptions.retryWrites).toBe(true)Because we passed retryWrites: true to our MongoClient.connect() statement, this variable is set to true for any query issued using this connection.
The answer is w: majority.
Sending a write with w: majority will cause MongoDB to wait for the write to be applied by a majority of nodes in the set. In a 3-node replica set, a majority is constituted by 2 nodes, so MongoDB will send an acknowledgement back to the client when 2 nodes have applied the write.
Correct Answers:
Inserts #1, #2, and #3 will succeed.
These writes do not conflict with each other, and they should all succeed if there are no network errors.
Correct Answer:
A Timeout error, resolved by wrapping the call in a try/catch block.
This error is best handled in the backend by wrapping the database call in a try/catch block. This way, the error can be handled somewhere in the catch block, instead of the error bubbling up to other layers of the software.
Correct Answer
people_heights.find().sort({ height: -1 }).skip(3).limit(2)This will sort on height, and then skip the top 3 tallest people to get the 4th- and 5th-tallest people.