
![]()
mbrl is a toolbox for facilitating development of
Model-Based Reinforcement Learning algorithms. It provides easily interchangeable
modeling and planning components, and a set of utility functions that allow writing
model-based RL algorithms with only a few lines of code.
See also our companion paper.
mbrl requires Python 3.7+ library and PyTorch (>= 1.7).
To install the latest stable version, run
pip install mbrl
If you are interested in modifying the library, clone the repository and set up a development environment as follows
git clone https://github.com/facebookresearch/mbrl-lib.git
pip install -e ".[dev]"
And test it by running the following from the root folder of the repository
python -m pytest tests/core
python -m pytest tests/algorithms
As a starting point, check out our tutorial notebook on how to write the PETS algorithm (Chua et al., NeurIPS 2018) using our toolbox, and running it on a continuous version of the cartpole environment.
MBRL-Lib provides implementations of popular MBRL algorithms as examples of how to use this library. You can find them in the mbrl/algorithms folder. Currently, we have implemented PETS, MBPO, PlaNet, we plan to keep increasing this list in the future.
The implementations rely on Hydra to handle configuration. You can see the configuration files in this folder. The overrides subfolder contains environment specific configurations for each environment, overriding the default configurations with the best hyperparameter values we have found so far for each combination of algorithm and environment. You can run training by passing the desired override option via command line. For example, to run MBPO on the gym version of HalfCheetah, you should call
python -m mbrl.examples.main algorithm=mbpo overrides=mbpo_halfcheetah By default, all algorithms will save results in a csv file called results.csv,
inside a folder whose path looks like
./exp/mbpo/default/gym___HalfCheetah-v2/yyyy.mm.dd/hhmmss;
you can change the root directory (./exp) by passing
root_dir=path-to-your-dir, and the experiment sub-folder (default) by
passing experiment=your-name. The logger will also save a file called
model_train.csv with training information for the dynamics model.
Beyond the override defaults, You can also change other configuration options,
such as the type of dynamics model
(e.g., dynamics_model=basic_ensemble), or the number of models in the ensemble
(e.g., dynamics_model.model.ensemble_size=some-number). To learn more about
all the available options, take a look at the provided
configuration files.
Our example configurations are largely based on Mujoco, but
our library components (and algorithms) are compatible with any environment that follows
the standard gym syntax. You can try our utilities in other environments
by creating your own entry script and Hydra configuration, using our default entry
main.py as guiding template.
See also the example override
configurations.
Without any modifications, our provided main.py can be used to launch experiments with the following environments:
mujoco-py(up to version 2.0)dm_controlpybullet-gym(thanks to dtch1997) for the contribution!
You can test your Mujoco and PyBullet installations by running
python -m pytest tests/mujoco
python -m pytest tests/pybullet
To specify the environment to use for main.py, there are two possibilities:
- Preferred way: Use a Hydra dictionary to specify arguments for your env constructor. See example.
- Less flexible alternative: A single string with the following syntax:
mujoco-gym:"gym___<env-name>", whereenv-nameis the name of the environment in gym (e.g., "HalfCheetah-v2").dm_control:"dmcontrol___<domain>--<task>, where domain/task are defined as in DMControl (e.g., "cheetah--run").pybullet-gym:"pybulletgym___<env-name>", whereenv-nameis the name of the environment in pybullet gym (e.g., "HopperPyBulletEnv-v0")
Our library also contains a set of diagnostics tools, meant to facilitate development and debugging of models and controllers. With the exception of the CPU-controller, which also supports PyBullet, these currently require a Mujoco installation, but we are planning to add support for other environments and extensions in the future. Currently, the following tools are provided:
-
Visualizer: Creates a video to qualitatively assess model predictions over a rolling horizon. Specifically, it runs a user specified policy in a given environment, and at each time step, computes the model's predicted observation/rewards over a lookahead horizon for the same policy. The predictions are plotted as line plots, one for each observation dimension (blue lines) and reward (red line), along with the result of applying the same policy to the real environment (black lines). The model's uncertainty is visualized by plotting lines the maximum and minimum predictions at each time step. The model and policy are specified by passing directories containing configuration files for each; they can be trained independently. The following gif shows an example of 200 steps of pre-trained MBPO policy on Inverted Pendulum environment.
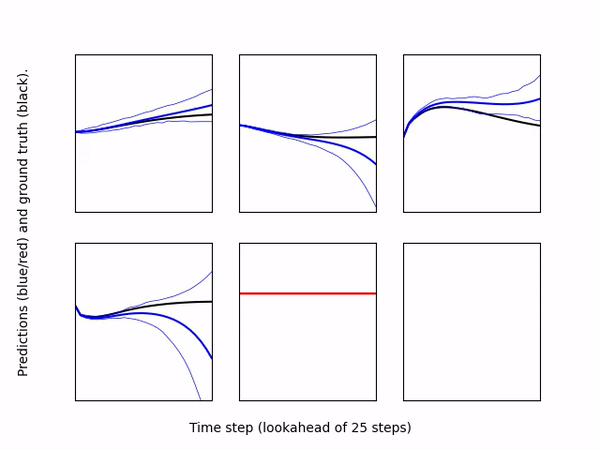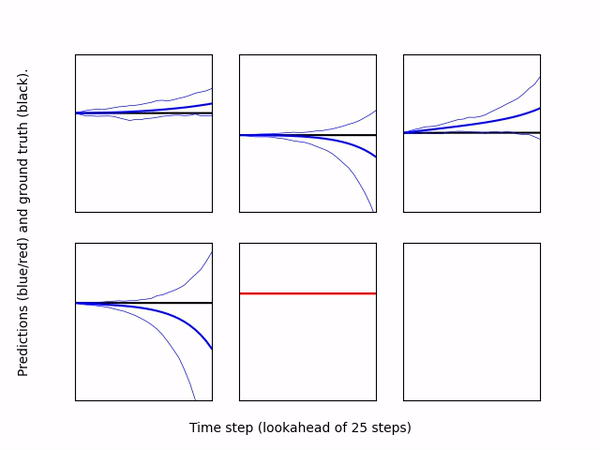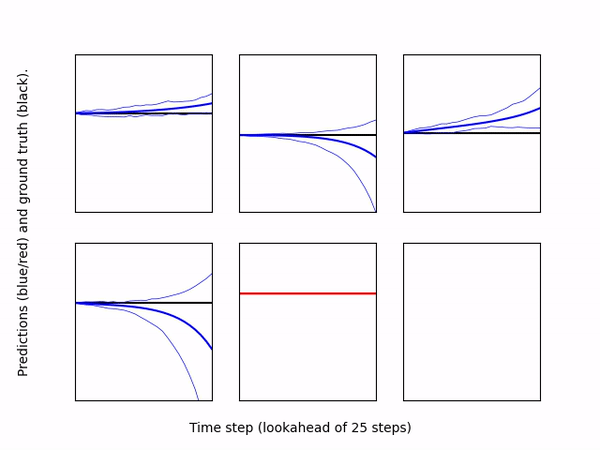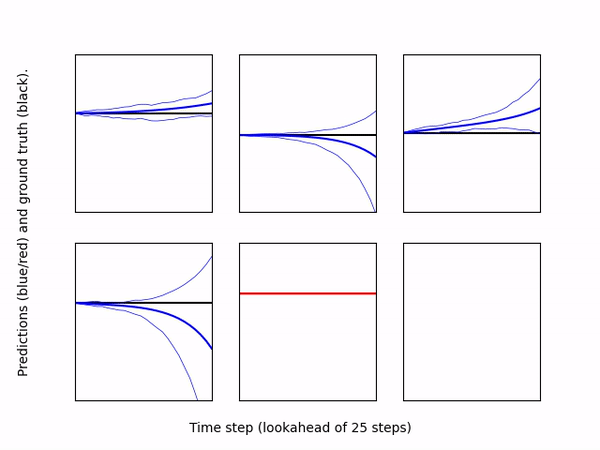
-
DatasetEvaluator: Loads a pre-trained model and a dataset (can be loaded from separate directories), and computes predictions of the model for each output dimension. The evaluator then creates a scatter plot for each dimension comparing the ground truth output vs. the model's prediction. If the model is an ensemble, the plot shows the mean prediction as well as the individual predictions of each ensemble member.
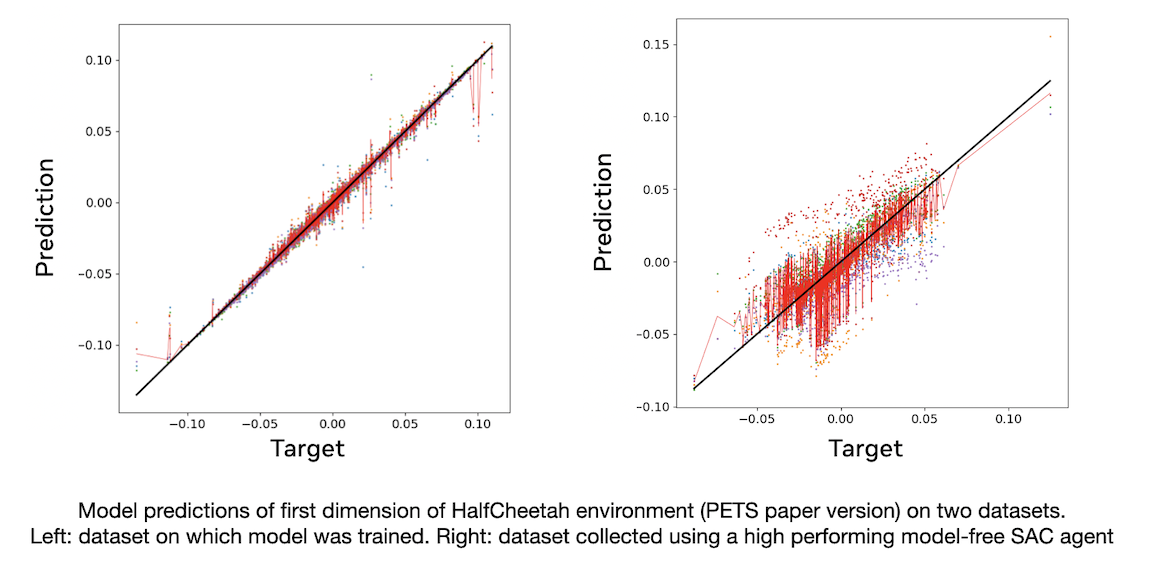
-
FineTuner: Can be used to train a model on a dataset produced by a given agent/controller. The model and agent can be loaded from separate directories, and the fine tuner will roll the environment for some number of steps using actions obtained from the controller. The final model and dataset will then be saved under directory "model_dir/diagnostics/subdir", wheresubdiris provided by the user.
-
True Dynamics Multi-CPU Controller: This script can run a trajectory optimizer agent on the true environment using Python's multiprocessing. Each environment runs in its own CPU, which can significantly speed up costly sampling algorithm such as CEM. The controller will also save a video if therenderargument is passed. Below is an example on HalfCheetah-v2 using CEM for trajectory optimization. To specify the environment, follow the single string syntax described here.

-
TrainingBrowser: This script launches a lightweight training browser for plotting rewards obtained after training runs (as long as the runs use our logger). The browser allows aggregating multiple runs and displaying mean/std, and also lets the user save the image to hard drive. The legend and axes labels can be edited in the pane at the bottom left. Requires installingPyQt5. Thanks to a3ahmad for the contribution!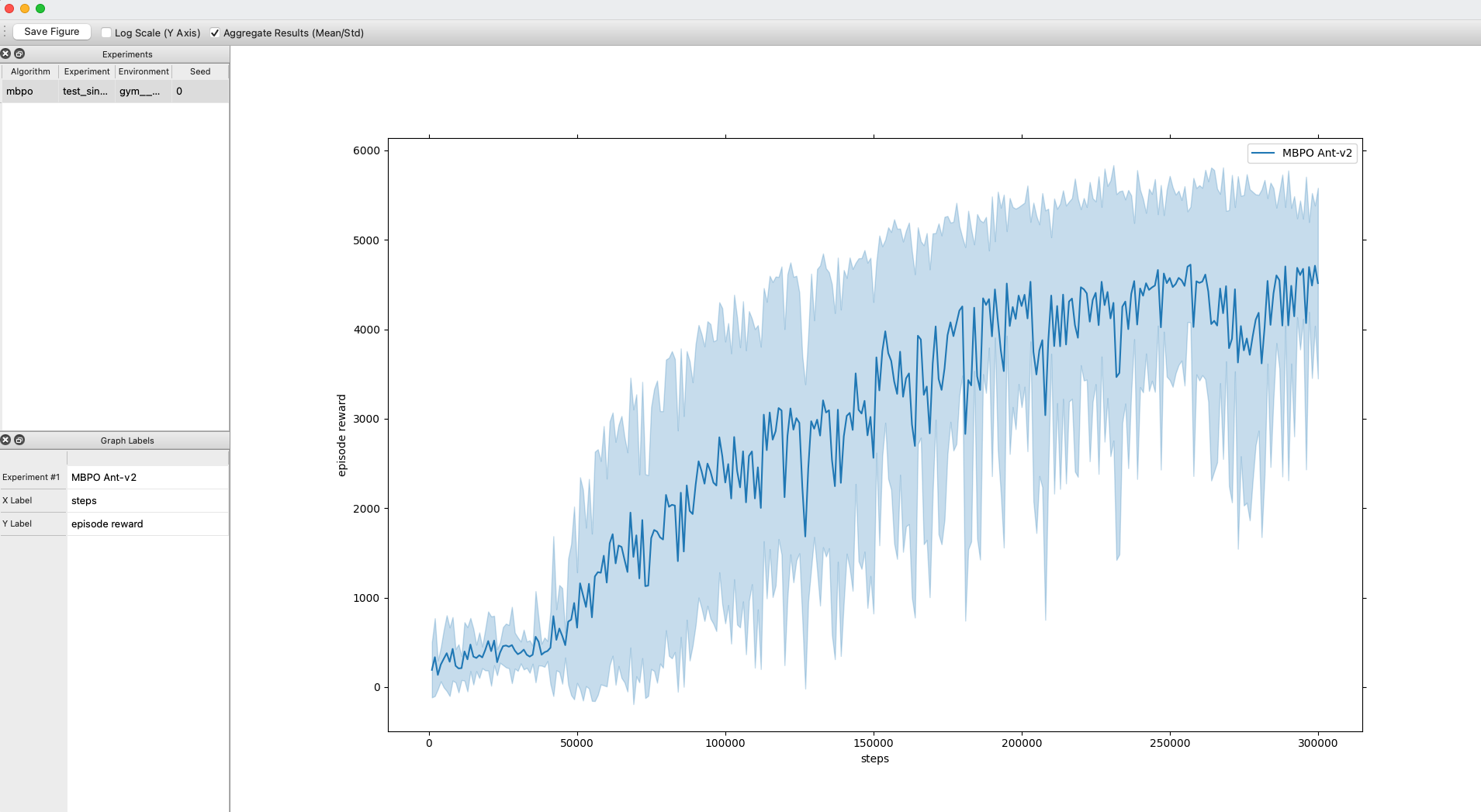
Note that, except for the training browser, all the tools above require Mujoco
installation and are specific to models of type
OneDimTransitionRewardModel.
We are planning to extend this in the future; if you have useful suggestions
don't hesitate to raise an issue or submit a pull request!
Please check out our documentation and don't hesitate to raise issues or contribute if anything is unclear!
mbrl is released under the MIT license. See LICENSE for
additional details about it. See also our
Terms of Use and
Privacy Policy.
If you use this project in your research, please cite:
@Article{Pineda2021MBRL,
author = {Luis Pineda and Brandon Amos and Amy Zhang and Nathan O. Lambert and Roberto Calandra},
journal = {Arxiv},
title = {MBRL-Lib: A Modular Library for Model-based Reinforcement Learning},
year = {2021},
url = {https://arxiv.org/abs/2104.10159},
}