Working group on the data model for Mezanno
- pour chaque annotation, il y a une entrée (potentiellement vide mais cliquable dans la liste des annotations)
- si la target a un sélecteur et que le canevas pointé est affichée, le sélecteur est affiché sur le canevas, et mis en surbrillance si on sélectionne l'annotation
- si le body contient un TextualBody, le contenu textuel est affiché dans la liste d'annotations
- target = lien à la source (input du process)
- body = nouvelle connaissance produite (output du process)
Un modèle simple pour découpler le modèle physique du document (fragments de texte) et le modèle métier (restructuration & sémantisation)

Expérimentation 'manifest_chained_annotations.json'

 https://excalidraw.com/#json=hmCT9HwlfaPGdMPliOjj0,wJXVYF86aaXtw6zwYoJUDg
Note: la vue "texte" est également un canvas IIIF + on peut imaginer avoir un affichage du texte par dessus la vue document (non représentée) en réutilisant l'extension TextOverlay de Mirador. Démo ici.
https://excalidraw.com/#json=hmCT9HwlfaPGdMPliOjj0,wJXVYF86aaXtw6zwYoJUDg
Note: la vue "texte" est également un canvas IIIF + on peut imaginer avoir un affichage du texte par dessus la vue document (non représentée) en réutilisant l'extension TextOverlay de Mirador. Démo ici.
🤔 Si l'on veut positionner le texte & les annotations type NER, etc sur l'image du document cela nécessite de conserver une information géométrique issue de la première étape d'extraction, et de la maintenir lors de la correction/modification du contenu extrait.
- quelles annotations doivent porter l'information géométrique ? Les régions OCR "mots", "lignes" ?
- peut-on construire des selecteurs SVG à partir de textselector qui soient correctement positionnés à l'intérieur de l'image du document.
Except from SODUCO data https://directory.geohistoricaldata.org/?manifest=https://raw.githubusercontent.com/mezanno/WG-data_model/main/annotations_experiments/manifest_soduco.json
Chained annotation https://directory.geohistoricaldata.org/?manifest=https://raw.githubusercontent.com/mezanno/WG-data_model/main/annotations_experiments/manifest_chained_annotations.json
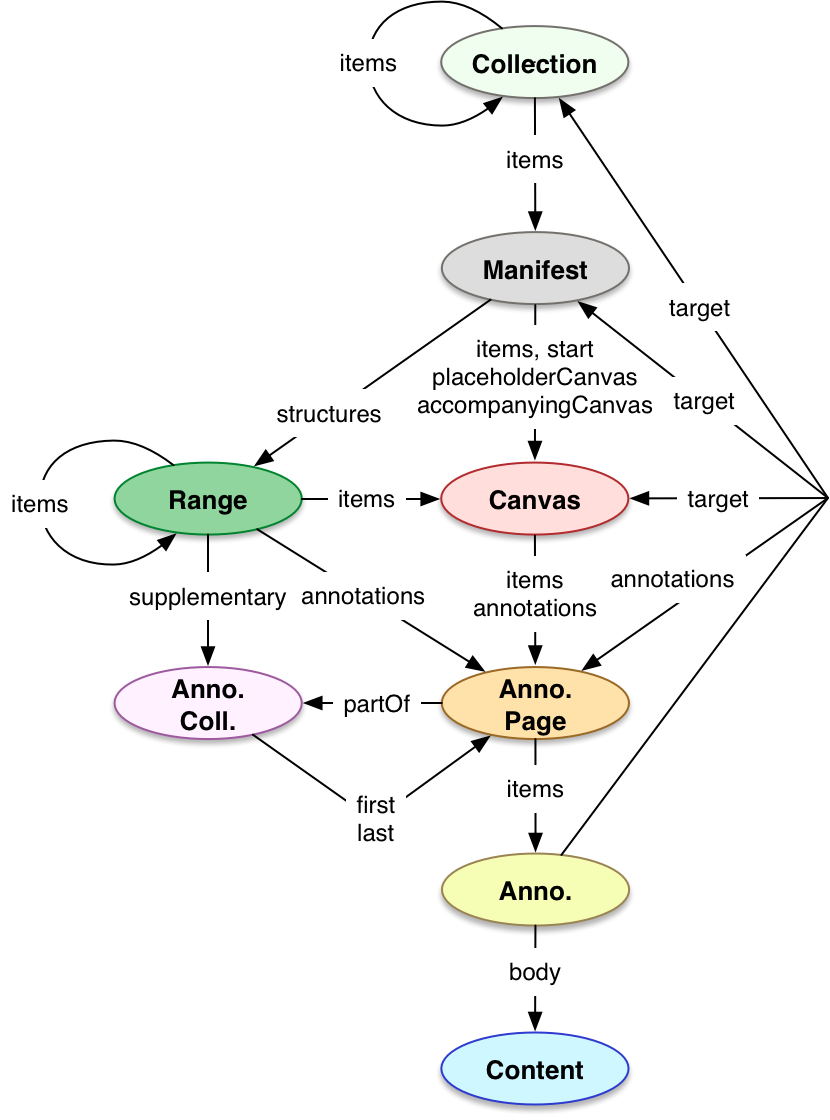
Web Annotation Data Model : https://www.w3.org/TR/annotation-model/ IIIF Presentation specification : https://iiif.io/api/presentation/3.0/
- https://iiif.io/api/presentation/3.0/#values-for-motivation
- https://www.w3.org/TR/annotation-model/#motivation-and-purpose
- https://www.w3.org/TR/annotation-vocab
- https://github.com/dbmdz/mirador-textoverlay (Mirador TextOverlay)
- https://mirador-textoverlay.netlify.app/ (Démo Mirador TextOverlay) 
{kind=link}