The Azure Storage blob inventory feature provides an overview of your containers, blobs, snapshots, and blob versions within a storage account. The inventory report can be used to understand various attributes of blobs and containers such as total data size, age, encryption status, immutability policy, legal hold and so on.
Inventory provides information on Containers and blobs within the storage account. This project demonstrates how to bring up Inventory reports in Azure Synapse and run queries to derive insights. Additionally, the project also describes how to visualize the analytics data in Power BI. Such an analysis will be helpful in understanding the characteristics of Storage Accounts in terms of their usage, the data stored in them etc. Further, the information can be used to optimize for cost using Lifecycle policies.
- Overview
- Overall growth in data over time
- Amount of data added to the storage account over time
- Number of files modified
- Blob snapshot size Blob snapshots - Azure Storage | Microsoft Docs
- Detailed analysis
- Data access patterns in different tiers of Storage (Hot, Cool, Archive)
- Distribution of data across tiers
- Distribution of data across blob types
- Data profile
- Distribution of blob in blob types
- Distribution of data in containers
- Distribution of blobs in access tiers
- Distribution of data by file types



- Enable inventory reports
- Create resources
- Import the PySpark notebook that has analytics queries
- Run the PySpark notebook
- Visualize the results of the above queries in PowerBI reports
The first step is to enable blob inventory reports on your storage account. After the inventory reports are generated, please process to the next steps. You may have to wait upto 24 hours after enabling inventory reports for your first report to be generated.
An Azyre Synapse workspace can be created either via manual steps or via the ARM templates provided.
- Create an Azure Synapse workspace
- Create an Azure Synapse workspace where you will execute a PySpark notebook to analyze the inventory report files.
- Grant Storage Blob Data Contributor access to Synapse workspace’s Managed Service Identity (MSI).
- Create Apache Spark pool in Synapse workspace created above. This Apache Spark pool will be used to execute PySpark notebook that will process the reports generated by Azure Blob Storage Inventory.
Deploy SynapseArmTemplate.json from Azure portal using Deploy a custom template.
Grant yourself and other users who will require access to data visualization the following roles:
- Storage Blob Data Contributor role on Storage account used while creating the Synapse workspace
- Contributor role on Synapse workspace
- Synapse Administrator role on Synapse studio
Please note that this step needs to be repeated for each user that will run the PySpark notebook used later in this documentation and also for users who will visualize the data using PowerBI
Download BlobInventoryStorageAccountConfiguration.json and update the placeholders inside it in following manner:
- storageAccountName: Name of the storage account for which inventory has been run
- destinationContainer: Name of the container where inventory reports are stored
- blobInventoryRuleName: Name of the inventory rule whose results should be analyzed
- accessKey: Access keys for the storage account in which inventory reports are stored.
After updating the above placeholders, upload the configuration file in the storage container used while creating Synapse workspace.
After you create the above resources and assign the permissions, perform the following steps:
- Download ReportAnalysis.ipynb
- Navigate to https://web.azuresynapse.net
- Select the Develop tab on the left edge
- Select the large plus sign (+) to add an item
- Select Import
- This will open a select file dialog. Upload the ReportAnalysis.ipynb downloaded above
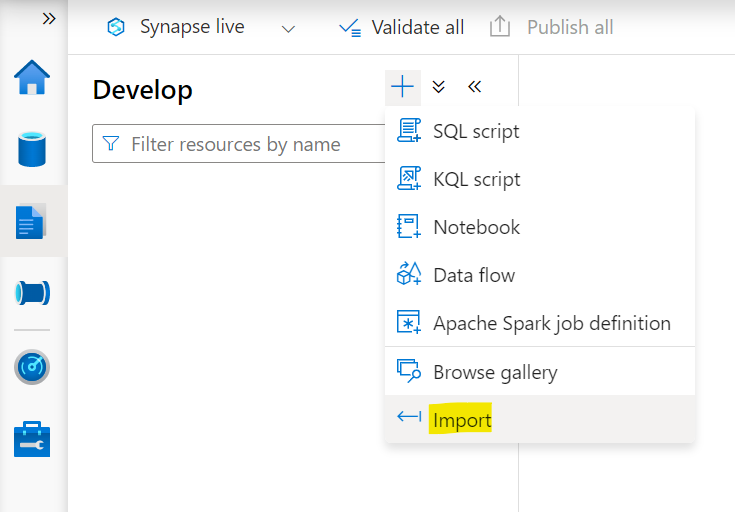
- This will open a Properties tab on the right. Select Configure Session
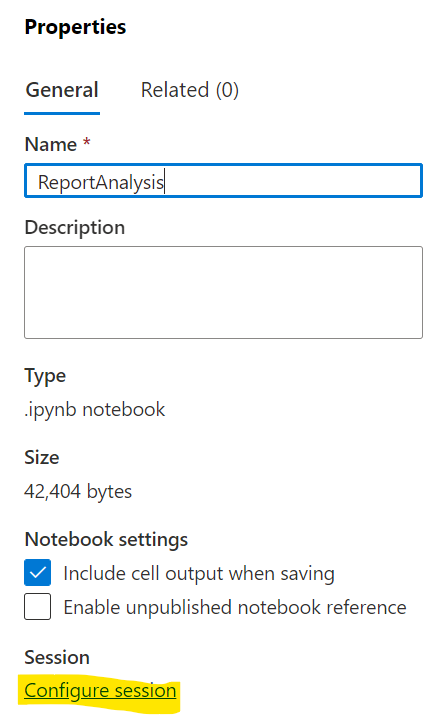
- Select the Apache Spark pool created earlier in the Attach to dropdown and click Apply
- In the first cell of Python notebook, update the value of storage_account and container_name variables to the names of the storage account and container specified while creating the synapse workspace
- Click on "Publish" button in order to save the notebook in Azure Synapse studio and to avoid uploading it next time you run the notebook


- In the PySpark notebook imported above and click on Run all
- It will take 3-4 minutes to start the Spark session and another couple of minutes to process the Inventory reports
- Do remember to publish the notebook again if you made any changes in the notebook while running it
Please note that the first run could take a while if there are a lot of Inventory reports to process. Subsequent runs will only process the new inventory reports created since the last run
Open ReportAnalysis.pbit file using PowerBI desktop application. Please note that this file may not render correctly with the web version of PowerBI application and hence we recommend that you use the Desktop version of PowerBI. When the report is opened, a popup will open like the one shown below. In this popup, enter the name of the Synapse workspace in synapse_workspace_name and database_name as reportdata.

If you see any error/warning in opening the PowerBI report, including but not limited to:
- The key did not match any row in the table
- Access to the resource is forbidden
The above errors are generic errors displayed by PowerBI. Please ensure that you have provided the input correctly to PowerBI template. Additionally, the following actions can be taken to handle the most frequently occurring errors:
- Missing permissions: Please make sure the user logged into PowerBI has the required access mentioned in Configure permissions to allow Azure Synapse to store files in a Storage Account step.
- Inventory reports not yet generated: Verify that the inventory run has succeeded at least once for the rule provided to PySpark notebook. Also verify the destination container provided to the PySpark notebook. An alternate way to also verify this is by going to Azure synapse studio in which you ran the PySpark notebook and ensure that a database named "reportdata" is present in Data -> Workspace -> Lake Database.
- Use Azure Storage blob inventory to manage blob data
- Optimize costs by automatically managing the data lifecycle
- Created data trigger to automatically process inventory reports
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.