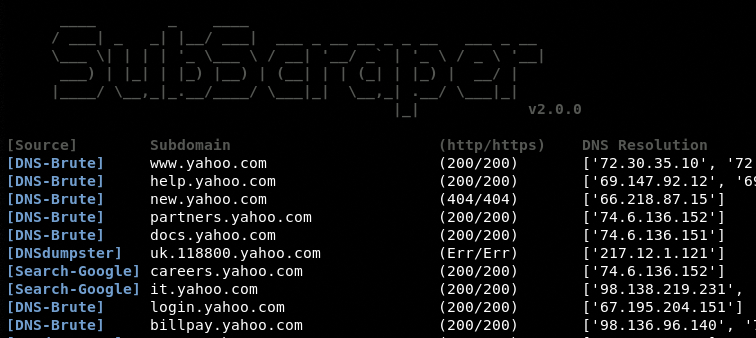
SubScraper uses DNS brute force, Google & Bing scraping, and DNSdumpster to enumerate subdomains of a given host. Written in Python3, SubScraper performs HTTP(S) requests and DNS "A" record lookups during the enumeration process to validate discovered subdomains. This provides further information to help prioritize targets and aid in potential next steps. Post-Enumeration, "CNAME" lookups are displayed to identify subdomain takeover opportunities.
Users also have the option of adding their Censys.io API Key & Secret in the command line arguments. This will allow subdomain enumeration using the Censys.io SSL Cert database. Create an account to get a free API key here: https://censys.io/register.
git clone https://github.com/m8r0wn/subscraper
cd subscraper
python3 setup.py install- Subdomain Enumeration
subscraper example.com
subscraper -r subdomains.txt example.com
subscraper -r subdomains.csv --report-type csv example.com- Subdomain Takeover Check
subscraper --takeover subdomains.txt example.comHave a new subdomain enumeration technique you would like to see in SubScraper? Why not add it!
SubScraper's enumeration methods have been modified to allow for a more modular approach. This means new techniques can easily be added to the subscraper/modules directory and tie directly into SubScraper's verbose output.
See subscraper/modules/example_module.py for more information.
SubScraper Options:
-T MAX_THREADS Max threads
-t TIMEOUT Timeout [seconds] for search threads (Default: 25)
target Target domain (Positional)
Subdomain Enumeration Options:
-s Only use internet to find subdomains
-b Only use DNS brute forcing to find subdomains
-w SUBLIST Custom subdomain wordlist
--censys-api CENSYS_API Add Censys.io API Key
--censys-secret CENSYS_SECRET Add Censys.io Secret
Subdomain Enumeration: Reporting:
-r REPORT, --report REPORT Write subdomains to txt file
--report-type {txt,csv} Output file types: txt, csv
Subdomain TakeOver:
--takeover TAKEOVER Perform takeover check on list of subs