

Empower your AI apps with clean data from any website. Featuring advanced scraping, crawling, and data extraction capabilities.
This repository is in development, and we’re still integrating custom modules into the mono repo. It's not fully ready for self-hosted deployment yet, but you can run it locally.
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown or structured data. We crawl all accessible subpages and give you clean data for each. No sitemap required. Check out our documentation.
Pst. hey, you, join our stargazers :)

We provide an easy to use API with our hosted version. You can find the playground and documentation here. You can also self host the backend if you'd like.
Check out the following resources to get started:
- API: Documentation
- SDKs: Python, Node, Go, Rust
- LLM Frameworks: Langchain (python), Langchain (js), Llama Index, Crew.ai, Composio, PraisonAI
- Low-code Frameworks: Dify, Langflow, Flowise AI, Cargo, Pipedream
- Others: Zapier, Pabbly Connect
- Want an SDK or Integration? Let us know by opening an issue.
To run locally, refer to guide here.
To use the API, you need to sign up on Firecrawl and get an API key.
- Scrape: scrapes a URL and get its content in LLM-ready format (markdown, structured data via LLM Extract, screenshot, html)
- Crawl: scrapes all the URLs of a web page and return content in LLM-ready format
- Map: input a website and get all the website urls - extremely fast
- LLM-ready formats: markdown, structured data, screenshot, HTML, links, metadata
- The hard stuff: proxies, anti-bot mechanisms, dynamic content (js-rendered), output parsing, orchestration
- Customizability: exclude tags, crawl behind auth walls with custom headers, max crawl depth, etc...
- Media parsing: pdfs, docx, images.
- Reliability first: designed to get the data you need - no matter how hard it is.
- Actions: click, scroll, input, wait and more before extracting data
- Batching (New): scrape thousands of URLs at the same time with a new async endpoint
You can find all of Firecrawl's capabilities and how to use them in our documentation
Used to crawl a URL and all accessible subpages. This submits a crawl job and returns a job ID to check the status of the crawl.
curl -X POST https://api.firecrawl.dev/v1/crawl \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer fc-YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"limit": 100,
"scrapeOptions": {
"formats": ["markdown", "html"]
}
}'Returns a crawl job id and the url to check the status of the crawl.
{
"success": true,
"id": "123-456-789",
"url": "https://api.firecrawl.dev/v1/crawl/123-456-789"
}Used to check the status of a crawl job and get its result.
curl -X GET https://api.firecrawl.dev/v1/crawl/123-456-789 \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY'{
"status": "completed",
"total": 36,
"creditsUsed": 36,
"expiresAt": "2024-00-00T00:00:00.000Z",
"data": [
{
"markdown": "[Firecrawl Docs home page!...",
"html": "<!DOCTYPE html><html lang=\"en\" class=\"js-focus-visible lg:[--scroll-mt:9.5rem]\" data-js-focus-visible=\"\">...",
"metadata": {
"title": "Build a 'Chat with website' using Groq Llama 3 | Firecrawl",
"language": "en",
"sourceURL": "https://docs.firecrawl.dev/learn/rag-llama3",
"description": "Learn how to use Firecrawl, Groq Llama 3, and Langchain to build a 'Chat with your website' bot.",
"ogLocaleAlternate": [],
"statusCode": 200
}
}
]
}Used to scrape a URL and get its content in the specified formats.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"formats" : ["markdown", "html"]
}'Response:
{
"success": true,
"data": {
"markdown": "Launch Week I is here! [See our Day 2 Release 🚀](https://www.firecrawl.dev/blog/launch-week-i-day-2-doubled-rate-limits)[💥 Get 2 months free...",
"html": "<!DOCTYPE html><html lang=\"en\" class=\"light\" style=\"color-scheme: light;\"><body class=\"__variable_36bd41 __variable_d7dc5d font-inter ...",
"metadata": {
"title": "Home - Firecrawl",
"description": "Firecrawl crawls and converts any website into clean markdown.",
"language": "en",
"keywords": "Firecrawl,Markdown,Data,Mendable,Langchain",
"robots": "follow, index",
"ogTitle": "Firecrawl",
"ogDescription": "Turn any website into LLM-ready data.",
"ogUrl": "https://www.firecrawl.dev/",
"ogImage": "https://www.firecrawl.dev/og.png?123",
"ogLocaleAlternate": [],
"ogSiteName": "Firecrawl",
"sourceURL": "https://firecrawl.dev",
"statusCode": 200
}
}
}Used to map a URL and get urls of the website. This returns most links present on the website.
curl -X POST https://api.firecrawl.dev/v1/map \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev"
}'Response:
{
"status": "success",
"links": [
"https://firecrawl.dev",
"https://www.firecrawl.dev/pricing",
"https://www.firecrawl.dev/blog",
"https://www.firecrawl.dev/playground",
"https://www.firecrawl.dev/smart-crawl",
]
}Map with search param allows you to search for specific urls inside a website.
curl -X POST https://api.firecrawl.dev/v1/map \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev",
"search": "docs"
}'Response will be an ordered list from the most relevant to the least relevant.
{
"status": "success",
"links": [
"https://docs.firecrawl.dev",
"https://docs.firecrawl.dev/sdks/python",
"https://docs.firecrawl.dev/learn/rag-llama3",
]
}Used to extract structured data from scraped pages.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://www.mendable.ai/",
"formats": ["extract"],
"extract": {
"schema": {
"type": "object",
"properties": {
"company_mission": {
"type": "string"
},
"supports_sso": {
"type": "boolean"
},
"is_open_source": {
"type": "boolean"
},
"is_in_yc": {
"type": "boolean"
}
},
"required": [
"company_mission",
"supports_sso",
"is_open_source",
"is_in_yc"
]
}
}
}'{
"success": true,
"data": {
"content": "Raw Content",
"metadata": {
"title": "Mendable",
"description": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"robots": "follow, index",
"ogTitle": "Mendable",
"ogDescription": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"ogUrl": "https://mendable.ai/",
"ogImage": "https://mendable.ai/mendable_new_og1.png",
"ogLocaleAlternate": [],
"ogSiteName": "Mendable",
"sourceURL": "https://mendable.ai/"
},
"llm_extraction": {
"company_mission": "Train a secure AI on your technical resources that answers customer and employee questions so your team doesn't have to",
"supports_sso": true,
"is_open_source": false,
"is_in_yc": true
}
}
}You can now extract without a schema by just passing a prompt to the endpoint. The llm chooses the structure of the data.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev/",
"formats": ["extract"],
"extract": {
"prompt": "Extract the company mission from the page."
}
}'Firecrawl allows you to perform various actions on a web page before scraping its content. This is particularly useful for interacting with dynamic content, navigating through pages, or accessing content that requires user interaction.
Here is an example of how to use actions to navigate to google.com, search for Firecrawl, click on the first result, and take a screenshot.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "google.com",
"formats": ["markdown"],
"actions": [
{"type": "wait", "milliseconds": 2000},
{"type": "click", "selector": "textarea[title=\"Search\"]"},
{"type": "wait", "milliseconds": 2000},
{"type": "write", "text": "firecrawl"},
{"type": "wait", "milliseconds": 2000},
{"type": "press", "key": "ENTER"},
{"type": "wait", "milliseconds": 3000},
{"type": "click", "selector": "h3"},
{"type": "wait", "milliseconds": 3000},
{"type": "screenshot"}
]
}'You can now batch scrape multiple URLs at the same time. It is very similar to how the /crawl endpoint works. It submits a batch scrape job and returns a job ID to check the status of the batch scrape.
curl -X POST https://api.firecrawl.dev/v1/batch/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"urls": ["https://docs.firecrawl.dev", "https://docs.firecrawl.dev/sdks/overview"],
"formats" : ["markdown", "html"]
}'Used to search the web, get the most relevant results, scrape each page and return the markdown.
curl -X POST https://api.firecrawl.dev/v0/search \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"query": "firecrawl",
"pageOptions": {
"fetchPageContent": true // false for a fast serp api
}
}'{
"success": true,
"data": [
{
"url": "https://mendable.ai",
"markdown": "# Markdown Content",
"provider": "web-scraper",
"metadata": {
"title": "Mendable | AI for CX and Sales",
"description": "AI for CX and Sales",
"language": null,
"sourceURL": "https://www.mendable.ai/"
}
}
]
}pip install firecrawl-pyfrom firecrawl.firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Scrape a website:
scrape_status = app.scrape_url(
'https://firecrawl.dev',
params={'formats': ['markdown', 'html']}
)
print(scrape_status)
# Crawl a website:
crawl_status = app.crawl_url(
'https://firecrawl.dev',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
print(crawl_status)With LLM extraction, you can easily extract structured data from any URL. We support pydantic schemas to make it easier for you too. Here is how you to use it:
from firecrawl.firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
class ArticleSchema(BaseModel):
title: str
points: int
by: str
commentsURL: str
class TopArticlesSchema(BaseModel):
top: List[ArticleSchema] = Field(..., max_items=5, description="Top 5 stories")
data = app.scrape_url('https://news.ycombinator.com', {
'formats': ['extract'],
'extract': {
'schema': TopArticlesSchema.model_json_schema()
}
})
print(data["extract"])To install the Firecrawl Node SDK, you can use npm:
npm install @mendable/firecrawl-js- Get an API key from firecrawl.dev
- Set the API key as an environment variable named
FIRECRAWL_API_KEYor pass it as a parameter to theFirecrawlAppclass.
import FirecrawlApp, { CrawlParams, CrawlStatusResponse } from '@mendable/firecrawl-js';
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
// Scrape a website
const scrapeResponse = await app.scrapeUrl('https://firecrawl.dev', {
formats: ['markdown', 'html'],
});
if (scrapeResponse) {
console.log(scrapeResponse)
}
// Crawl a website
const crawlResponse = await app.crawlUrl('https://firecrawl.dev', {
limit: 100,
scrapeOptions: {
formats: ['markdown', 'html'],
}
} satisfies CrawlParams, true, 30) satisfies CrawlStatusResponse;
if (crawlResponse) {
console.log(crawlResponse)
}With LLM extraction, you can easily extract structured data from any URL. We support zod schema to make it easier for you too. Here is how you to use it:
import FirecrawlApp from "@mendable/firecrawl-js";
import { z } from "zod";
const app = new FirecrawlApp({
apiKey: "fc-YOUR_API_KEY"
});
// Define schema to extract contents into
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe("Top 5 stories on Hacker News"),
});
const scrapeResult = await app.scrapeUrl("https://news.ycombinator.com", {
extractorOptions: { extractionSchema: schema },
});
console.log(scrapeResult.data["llm_extraction"]);Firecrawl is open source available under the AGPL-3.0 license.
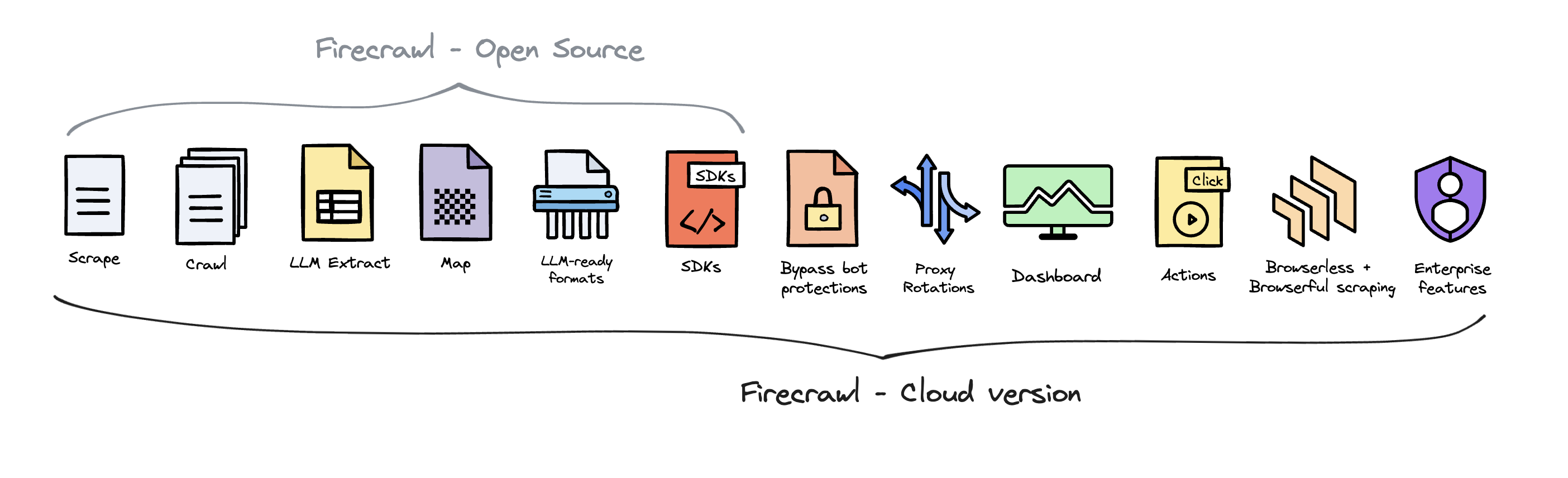
To deliver the best possible product, we offer a hosted version of Firecrawl alongside our open-source offering. The cloud solution allows us to continuously innovate and maintain a high-quality, sustainable service for all users.
Firecrawl Cloud is available at firecrawl.dev and offers a range of features that are not available in the open source version:
We love contributions! Please read our contributing guide before submitting a pull request. If you'd like to self-host, refer to the self-hosting guide.
It is the sole responsibility of the end users to respect websites' policies when scraping, searching and crawling with Firecrawl. Users are advised to adhere to the applicable privacy policies and terms of use of the websites prior to initiating any scraping activities. By default, Firecrawl respects the directives specified in the websites' robots.txt files when crawling. By utilizing Firecrawl, you expressly agree to comply with these conditions.
This project is primarily licensed under the GNU Affero General Public License v3.0 (AGPL-3.0), as specified in the LICENSE file in the root directory of this repository. However, certain components of this project are licensed under the MIT License. Refer to the LICENSE files in these specific directories for details.
Please note:
- The AGPL-3.0 license applies to all parts of the project unless otherwise specified.
- The SDKs and some UI components are licensed under the MIT License. Refer to the LICENSE files in these specific directories for details.
- When using or contributing to this project, ensure you comply with the appropriate license terms for the specific component you are working with.
For more details on the licensing of specific components, please refer to the LICENSE files in the respective directories or contact the project maintainers.