forked from elastic/examples
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Uses Kibana API to directly import dashboard
Using the Kibana APIs, we can directly import a dashboard and all dependent objects including index patterns and visualizations. This saves the user from a bunch of steps and manually copying around the UUID of the index pattern.
- Loading branch information
1 parent
885d06b
commit d3699c2
Showing
8 changed files
with
765 additions
and
63 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -6,11 +6,6 @@ For a high-level introduction, please see the accompanying blog post, [Exploring | |
|
|
||
|  | ||
|
|
||
| **TODO**: | ||
|
|
||
| - Fix link to blog post once it's available | ||
| - Kibana import scripts to support Kibana API | ||
|
|
||
| ## Contents | ||
|
|
||
| - [Online Search Relevance Metrics](#online-search-relevance-metrics) | ||
|
|
@@ -84,23 +79,18 @@ Use the `-h` or `--help` arguments to explore more functionality and arguments. | |
|
|
||
| ### Kibana visualizations | ||
|
|
||
| **WIP**: This section is being renewed to support a single command to do all of this behind the scenes. | ||
|
|
||
| To recreate the visualisations in Kibana, you need to first make sure you have data in your Elasticsearch instance using the above `simulate` command. | ||
| To recreate the visualisations in Kibana, you need to first make sure you have data in your Elasticsearch instance using the above `simulate` command. Then you just need to run `kibana` to create the dashboard, index pattern and visualizations. | ||
|
|
||
| Once you have data in Kibana, [create an index pattern](https://www.elastic.co/guide/en/kibana/current/index-patterns.html) with the same name as the metrics index: `ecs-search-metrics_transform_queryid`. When creating the index pattern, use the `query_event.@timestamp` field as the timestamp field of the index pattern. Once the index pattern has been created, click on the link to the index pattern and find the index pattern ID in the URL of the page. It'll be the long UUID almost at the end of the URL, that looks something like this: `d84e0c50-8aec-11ea-aa75-e59eded2bd43`. | ||
| ```bash | ||
| bin/kibana | ||
| ``` | ||
|
|
||
| With the Kibana saved objects template as input, a location for the saved object output file, and the index pattern ID, you can use the `bin/kibana` script to generate a valid set of Kibana visualizations linked to the correct index pattern. Here's an example invocation: | ||
| As with `simulate`, if you are running on Cloud, ensure that your credentials are set and the correct Kibana URL is used (don't use the Elasticsearch URL!). You can find your Kibana endpoint just below where you found the Elasticsearch endpoint, and your credentials should be the same as with Elasticsearch. | ||
|
|
||
| ```bash | ||
| bin/kibana \ | ||
| --input config/kibana/saved_objects.template.ndjson \ | ||
| --output tmp/kibana.ndjson \ | ||
| d84e0c50-8aec-11ea-aa75-e59eded2bd43 | ||
| bin/kibana --url https://elastic:[email protected]:9243 | ||
| ``` | ||
|
|
||
| Open up Kibana again and select the "Saved Objects" page from "Stack Management", and Import (top right corner). Drag the newly created `kibana.ndjson` file with the saved objects in it and drop it into the "Import saved objects" dialog, and hit "Import". | ||
|
|
||
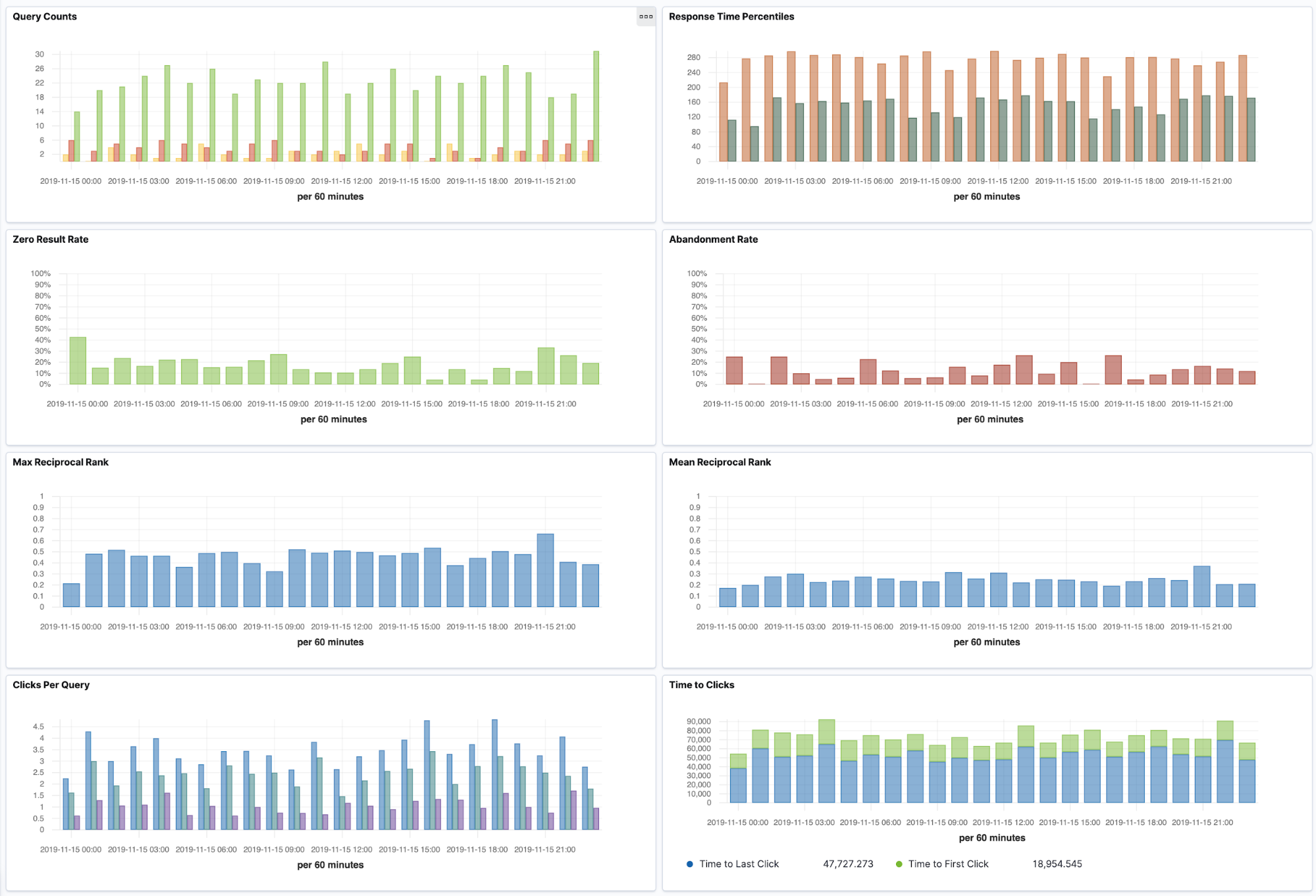
| You're all set! Have a look at the Dashboard and Visualizations pages now and you should see a large set of ready-made visualizations. Make sure that your time range is set to the entire day of 15 Nov 2019 UTC. | ||
|
|
||
| ## Implementation details | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
33 changes: 21 additions & 12 deletions
33
Machine Learning/Online Search Relevance Metrics/bin/kibana
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.