目标网址:http://weixin.sogou.com/weixin?type=2&query=python&ie=utf8
实现:关于python文章的抓取,抓取标题、标题链接、描述。如下图所示。
数据:数据我就没有保存,此实战主要是为了学习IP和用户代理池的设定,推荐一个开源项目关于搜狗微信公众号:基于搜狗微信的公众号文章爬虫
图1
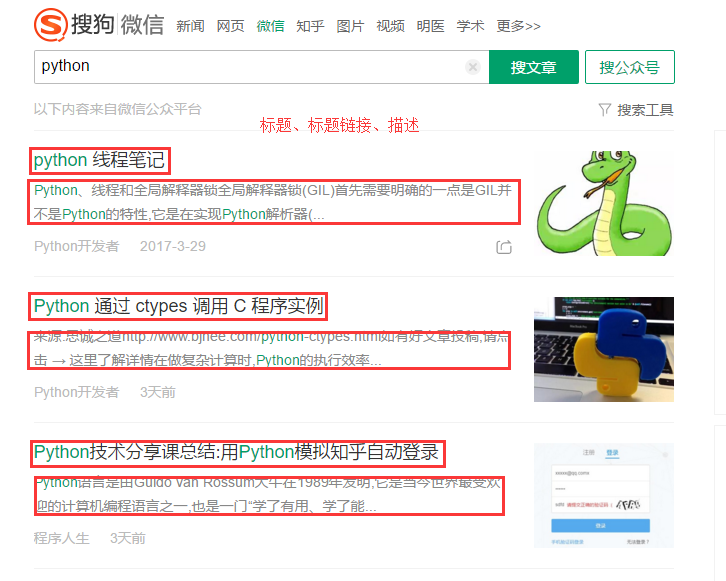
- key是要搜索关键字,可以改变。
- 设置好代理IP和User-Agent,运行main.py即可。
声明:此项目主要是学习IP代理池的设定
1.我所用的ip是免费网站上找的,现在免费可用的ip真的是少,尤其实在搜狗微信端,很难找了。我用本地ip可以爬取,但是用代理ip,会出现xpath取到空值的情况,难道ip质量不好还是什么的,猜测是没有加载缓慢(待解决)如下所示
2017-04-04 16:57:40 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36
2017-04-04 16:57:40 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://sogou.com/> (referer: None)
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3
当前使用的IP是124.65.238.166:80
当前使用的user-agent是Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3
2017-04-04 16:57:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://weixin.sogou.com/weixin?query=python&type=2&page=10> (referer: http://sogou.com/)
2017-04-04 16:57:41 [scrapy.core.scraper] DEBUG: Scraped from <200 http://weixin.sogou.com/weixin?query=python&type=2&page=10>
{'dec': [], 'link': [], 'title': []}
2017-04-04 16:57:42 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://weixin.sogou.com/weixin?query=python&type=2&page=9> (referer: http://sogou.com/)
2017-04-04 16:57:42 [scrapy.core.scraper] DEBUG: Scraped from <200 http://weixin.sogou.com/weixin?query=python&type=2&page=9>
{'dec': [], 'link': [], 'title': []}
2017-04-04 16:57:44 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://weixin.sogou.com/weixin?query=python&type=2&page=8> (referer: http://sogou.com/)
欢迎有兴趣的小伙伴帮我优化,找出问题,之后我将合并你的代码,作为贡献者,共同成长。
一.反爬虫机制处理思路:
- 浏览器伪装、用户代理池;
- IP限制--------IP代理池;
- ajax、js异步-------抓包;
- 验证码-------打码平台。
二.散点知识:
1.def process_request(): #处理请求
request.meta["proxy"]=.... #添加代理ip
2.scrapy中如果请求2次就会放弃,说明该代理ip不行。
如果本项目对你有用请给我一颗star,万分感谢。