
![]()







![]()
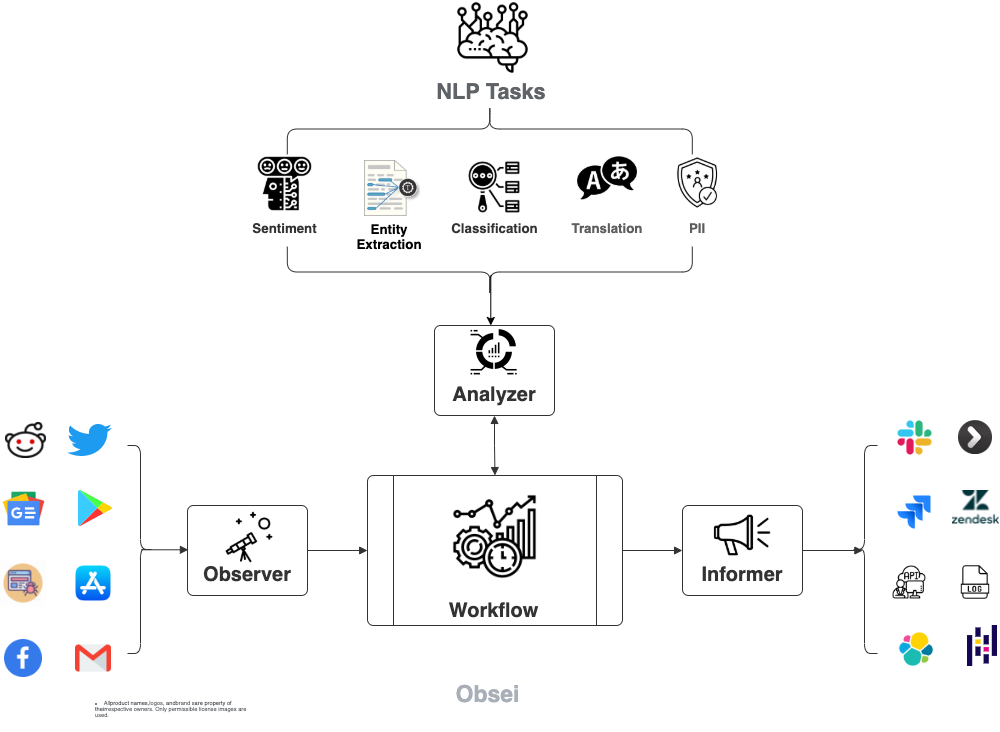
Obsei is intended to be an automation tool for text analysis need. Obsei consist of -
- Observer, observes platform like Twitter, Facebook, App Stores, Google reviews, Amazon reviews, News, Website etc and feed that information to,
- Analyzer, which perform text analysis like classification, sentiment, translation, PII etc and feed that information to,
- Informer, which send it to ticketing system, data store, dataframe etc for further action and analysis.

Current flow
Future concept (Coming Soon! 🙂)
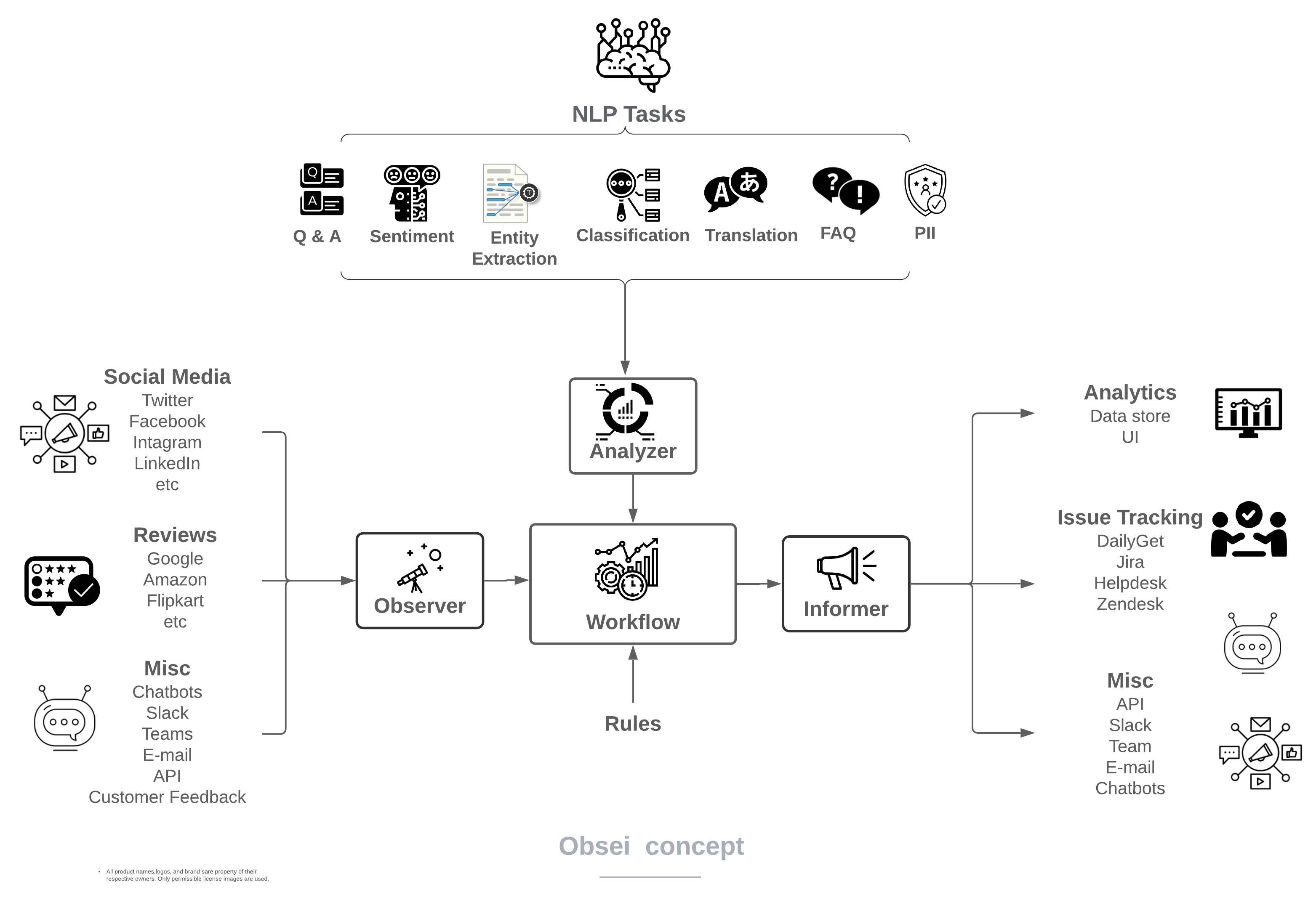
Obsei use cases are following, but not limited to -
- Automatic customer issue creation based on sentiment analysis (reduction of MTTD)
- Proper tagging of ticket based for example login issue, signup issue, delivery issue etc (reduction of MTTR)
- Checking effectiveness of social media marketing campaign
- Extraction of deeper insight from feedbacks on various platforms
- Research purpose
We have a minimal streamlit based UI that you can use to test Obsei.
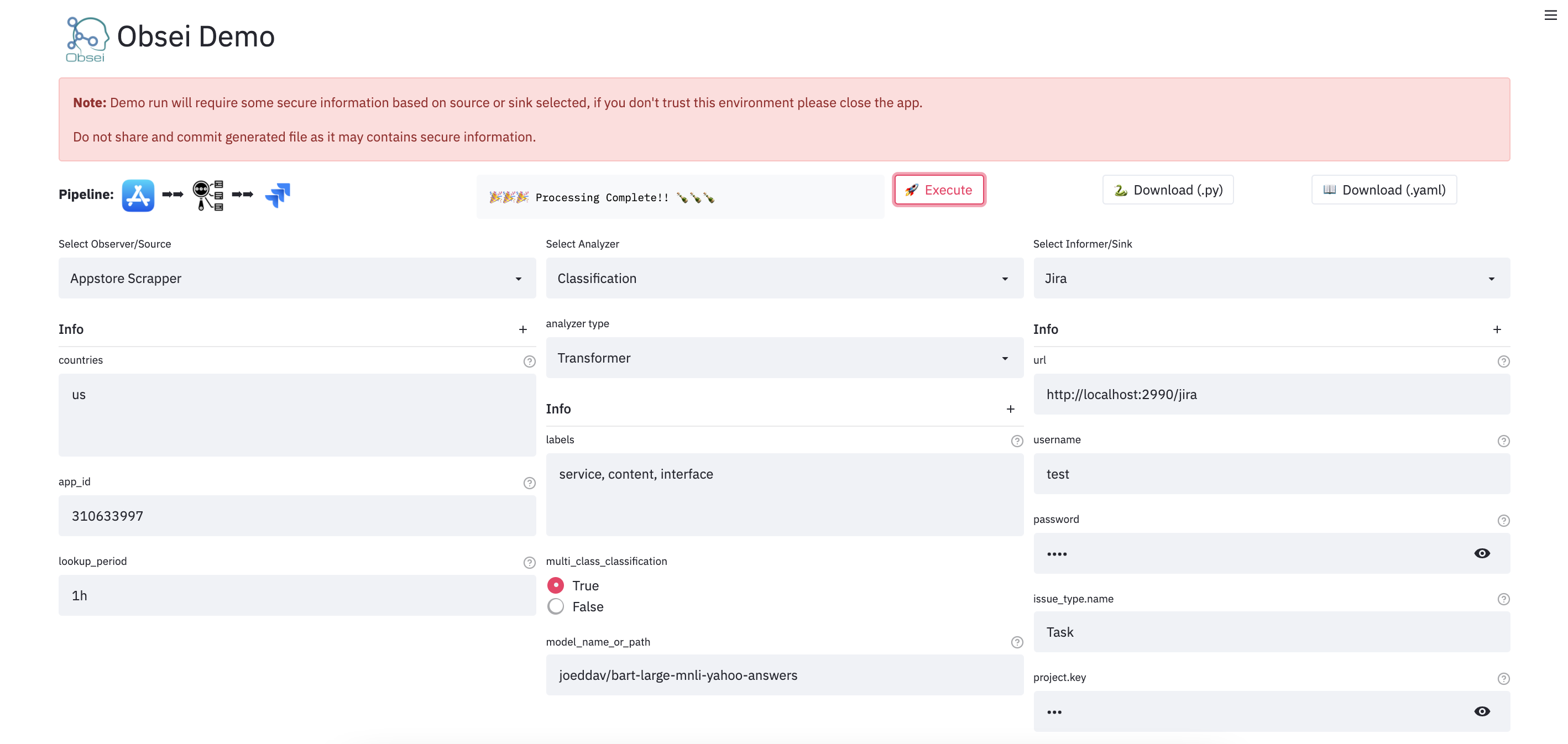
Watch: Obsei UI Demo
To test remotely, just open: Obsei Demo Link (Note: Due to rate limit sometime Streamlit demo might not work, hence please use docker image locally.)
To test locally, just run
docker run -d --name obesi-ui -p 8501:8501 obsei/obsei-ui-demo
# You can find the UI at http://localhost:8501
For detailed installation instructions, usages and example refer documentation.
| Linux | Mac | Windows1 | Remark | |
|---|---|---|---|---|
| Tests | ✅ | ✅ | ✅ | Low Coverage as difficult to test 3rd party libs |
| PIP | ✅ | ✅ | ✅ | Fully Supported |
| Conda2 | ✅ | ✅ | ✅ | Partially Supported |
1 On Windows you have to install pytorch manually. Refer Pytorch official instruction. ↩
2 Conda channel missing few dependencies, hence install missing dependencies manually - ↩
Missing Conda dependencies -
pip install presidio-analyzer
pip install presidio-anonymizer
pip install zenpy
pip install searchtweets-v2
pip install google-play-scraper
pip install tweet-preprocessor
pip install gnews
pip install trafilatura
pip install python-facebook-apiTo try in Colab Notebook click:
To try in Binder click:
Expend following steps and create your workflow -
Step 1: Prerequisite
Install following if system do not have -
- Install Python 3.7+
- Install PIP (Optional if you prefer Conda)
- Install Conda (Optional if you prefer PIP)
Step 2: Install Obsei
You can install Obsei either via PIP or Conda based on your preference.
NOTE: On Windows you have to install pytorch manually. Refer https://pytorch.org/get-started/locally/
To install latest released version -
pip install obseiInstall from master branch (if you want to try the latest features):
git clone https://github.com/obsei/obsei.git
cd obsei
pip install --editable .To install latest released version -
conda install -c lalitpagaria obseiInstall from master branch (if you want to try the latest features):
git clone https://github.com/obsei/obsei.git
cd obsei
conda env create -f conda/environment.ymlFor GPU based local environment -
git clone https://github.com/obsei/obsei.git
cd obsei
conda env create -f conda/gpu-environment.ymlStep 3: Configure Source/Observer
|
|
|
|
|
|
|
|
|
Step 4: Configure Analyzer
Note: To run transformers in an offline mode, check transformers offline mode.
Some analyzer support GPU and to utilize pass device parameter. List of possible values of device parameter (default value auto):
- auto: GPU (cuda:0) will be used if available otherwise CPU will be used
- cpu: CPU will be used
- cuda:{id} - GPU will be used with provided CUDA device id
|
|
|
|
|
|
Step 5: Configure Sink/Informer
|
|
|
|
|
|
|
Step 6: Join and create workflow
source will fetch data from selected the source, then feed that to analyzer for processing, whose output we feed into sink to get notified at that sink.
# Uncomment if you want logger
# import logging
# import sys
# logger = logging.getLogger(__name__)
# logging.basicConfig(stream=sys.stdout, level=logging.INFO)
# This will fetch information from configured source ie twitter, app store etc
source_response_list = source.lookup(source_config)
# Uncomment if you want to log source response
# for idx, source_response in enumerate(source_response_list):
# logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
# This will execute analyzer (Sentiment, classification etc) on source data with provided analyzer_config
analyzer_response_list = text_analyzer.analyze_input(
source_response_list=source_response_list,
analyzer_config=analyzer_config
)
# Uncomment if you want to log analyzer response
# for idx, an_response in enumerate(analyzer_response_list):
# logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
# Analyzer output added to segmented_data
# Uncomment inorder to log it
# for idx, an_response in enumerate(analyzer_response_list):
# logger.info(f"analyzed_data#'{idx}'='{an_response.segmented_data.__dict__}'")
# This will send analyzed output to configure sink ie Slack, Zendesk etc
sink_response_list = sink.send_data(analyzer_response_list, sink_config)
# Uncomment if you want to log sink response
# for sink_response in sink_response_list:
# if sink_response is not None:
# logger.info(f"sink_response='{sink_response}'")Step 7: Execute workflow
Copy code snippets from Step 3 to Step 6 into python file for exampleexample.py and execute following command -
python example.pyUpcoming release plan and progress can be tracked at link (Suggestions are welcome).
Discussion about Obsei can be done at community forum
First off, thank you for even considering contributing to this package, every contribution big or small is greatly appreciated. Please refer our Contribution Guideline and Code of Conduct.
For any security issue please contact us via email

This could not have been possible without these open source software.
We would like to thank DailyGet for continuous support and encouragement. Please check DailyGet out. it is a platform which can easily be configured to solve any business process automation requirements.